
Kurs
Einführung in R
4 Std.
3M
Clustering-Modelle zielen darauf ab, Daten in verschiedene "Cluster" oder Gruppen einzuteilen. Dies kann als eigenständige Analyse oder als Merkmal in einem überwachten Lernalgorithmus verwendet werden.
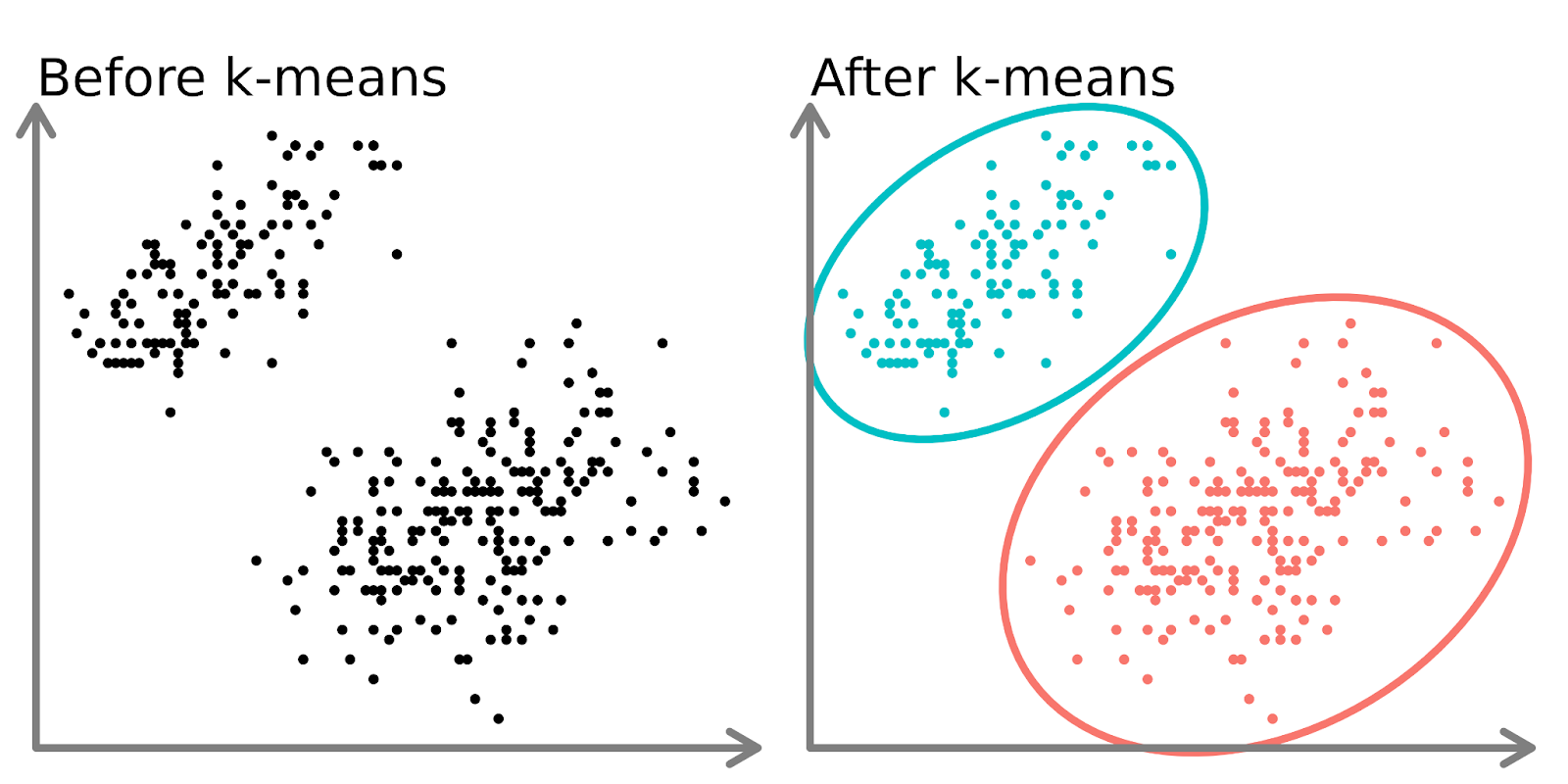
Auf der linken Seite des obigen Diagramms sehen wir 2 verschiedene Punktesätze, die nicht beschriftet und als ähnliche Datenpunkte eingefärbt sind. Wenn du ein K-Mittelwert-Modell auf diese Daten anpasst (rechte Seite), kannst du zwei verschiedene Gruppen erkennen (dargestellt durch unterschiedliche Kreise und Farben).
In zwei Dimensionen ist es für Menschen einfach, diese Cluster aufzuteilen, aber bei mehr Dimensionen musst du ein Modell verwenden.
Stell dir vor, du willst mehrere Obstsalate machen, die alle aus ähnlichen Früchten bestehen.
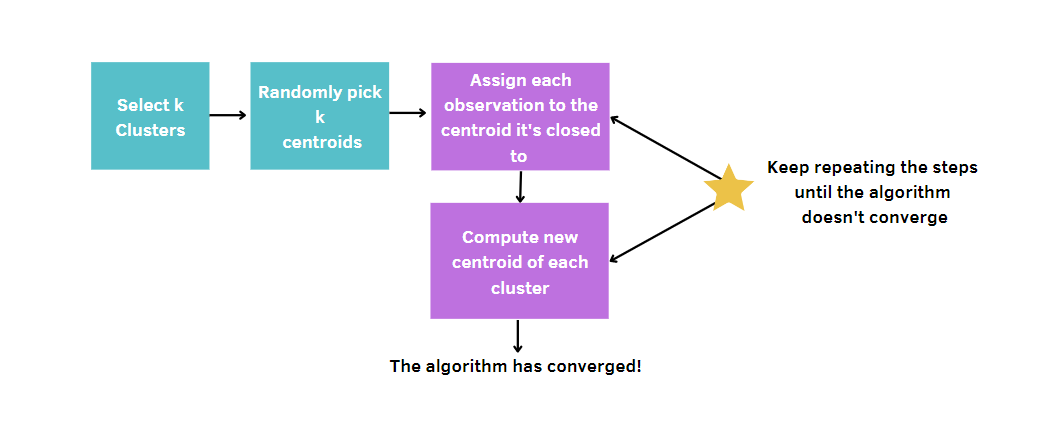
Allgemeiner ausgedrückt: Du:
Da k-means die Zentren der Cluster nach dem Zufallsprinzip auswählt, muss dieser Algorithmus eine bestimmte Anzahl von Durchläufen absolvieren, die vom Nutzer festgelegt wird. Auf diese Weise wird die beste Lösung erreicht, indem die Messung der Modellqualität minimiert wird. Dieses Maß wird als Gesamtsumme der Quadrate innerhalb eines Clusters (WCSS) bezeichnet, d. h. die Summe der Abstände zwischen den Datenpunkten und dem entsprechenden Schwerpunkt für jedes Cluster. Denn je kleiner unsere Modellqualitätsmessung ist, desto eher werden wir das Gewinnermodell erreichen.
Der gesamte Inhalt dieses Tutorials dreht sich um Airbnb-Mietangebote in Kapstadt, die auf DataLab verfügbar sind. Die Daten enthalten verschiedene Arten von Informationen, wie die Gastgeber, den Preis, die Anzahl der Bewertungen, die Koordinaten und so weiter.
Auch wenn der Datensatz tiefe Informationen über Ferienvermietungen zu liefern scheint, gibt es noch einige klare Fragen, die beantwortet werden können. Stellen wir uns zum Beispiel vor, Airbnb bittet seine Datenwissenschaftler, die Segmentierung der Angebote auf dieser Plattform in Kapstadt zu untersuchen.
Jede Stadt unterscheidet sich von der anderen und hat andere Anforderungen, je nach der Kultur der Menschen, die dort leben. Die Identifizierung von Clustern in dieser Stadt kann nützlich sein, um neue Erkenntnisse zu gewinnen, die die Zufriedenheit der aktuellen Kunden mit geeigneten Kundenbindungsstrategien erhöhen und die Abwanderung von Kunden verhindern können. Gleichzeitig ist es aber auch wichtig, neue Leute mit geeigneten Werbeaktionen anzulocken.
Bevor wir k-means anwenden, möchten wir die Beziehung zwischen den Variablen genauer untersuchen, indem wir einen Blick auf die Korrelationsmatrix werfen. Um die Anzeige zu vereinfachen, runden wir die Ziffern auf zwei Dezimalstellen.
library(dplyr)
airbnb |>
select(price, minimum_nights, number_of_reviews) |>
cor(use = "pairwise.complete.obs") |>
round(2)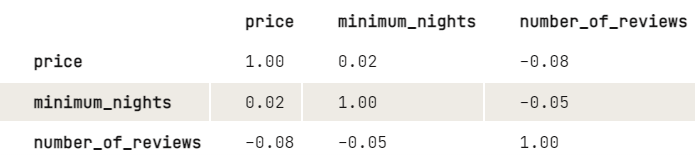
Aus den Ergebnissen geht hervor, dass es eine leicht negative Beziehung zwischen dem Preis und der Anzahl der Bewertungen gibt: Je höher der Preis, desto niedriger die Anzahl der Bewertungen. Das Gleiche gilt für Mindestnächte und eine Reihe von Bewertungen. Da die Mindestanzahl an Übernachtungen keinen großen Einfluss auf den Preis hat, würden wir gerne mehr darüber herausfinden, wie Preis und Anzahl der Bewertungen zusammenhängen:
library(ggplot2)
ggplot(data, aes(number_of_reviews, price, color = room_type, shape = room_type)) +
geom_point(alpha = 0.25) +
xlab("Number of reviews") +
ylab("Price")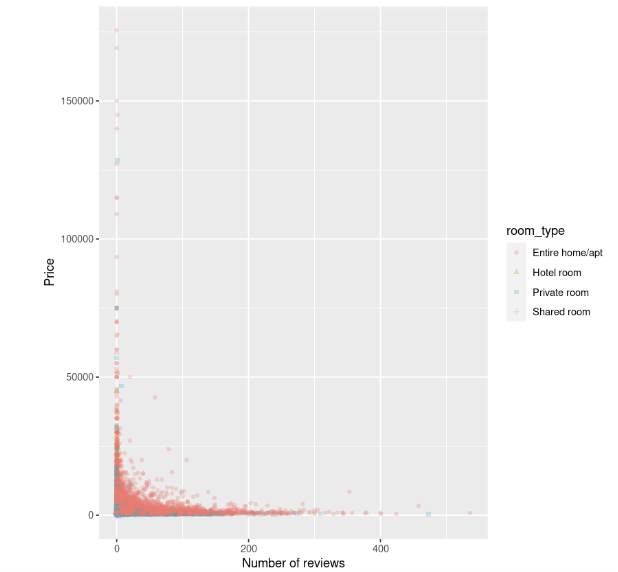
Das Streudiagramm zeigt, dass die Kosten für Unterkünfte, insbesondere für ganze Häuser, bei einer geringen Anzahl von Bewertungen höher sind und mit zunehmender Anzahl von Bewertungen zu sinken scheinen.
Bevor das Modell angepasst werden kann, ist noch ein weiterer Schritt erforderlich. k-means reagiert empfindlich auf Variablen mit unvergleichbaren Einheiten, was zu irreführenden Ergebnissen führt. In diesem Beispiel ist die Anzahl der Bewertungen zehn oder hundert, aber der Preis ist zehntausend. Ohne jegliche Datenverarbeitung würden die Preisunterschiede größer erscheinen als die Unterschiede bei den Bewertungen, aber wir wollen, dass diese Variablen gleich behandelt werden.
Um dieses Problem zu vermeiden, müssen die Variablen so transformiert werden, dass sie auf einer ähnlichen Skala liegen. Auf diese Weise können sie mithilfe der Distanzmetrik korrekt verglichen werden.
Es gibt verschiedene Methoden, um dieses Problem zu lösen. Die bekannteste und am häufigsten verwendete Methode ist die Standardisierung, bei der der Durchschnittswert vom Merkmalswert abgezogen und dann durch seine Standardabweichung geteilt wird. Mit dieser Technik lassen sich Merkmale mit einem Mittelwert von 0 und einer Abweichung von 1 ermitteln.
Du kannst die Variablen mit der Funktion scale() skalieren. Da dies eine Matrix zurückgibt, ist der Code sauberer, wenn du einen Base-R-Stil anstelle eines Tidyverse-Stils verwendest.
airbnb[, c("price", "number_of_reviews")] = scale(airbnb[, c("price", "number_of_reviews")])Schließlich können wir die Cluster der Angebote mit k-means identifizieren. Für den Anfang versuchen wir, k-means mit 3 Clustern und nstart gleich 20 durchzuführen. Dieser letzte Parameter wird benötigt, um k-means mit 20 verschiedenen zufälligen Startzuordnungen auszuführen. Dann wählt R automatisch die besten Ergebnisse aus, die sich aus der Summe der Quadrate innerhalb der Cluster ergeben. Wir setzen auch einen Seed, um jedes Mal, wenn wir den Code ausführen, die gleichen Ergebnisse zu erhalten.
# Get the two columns of interest
airbnb_2cols <- data[, c("price", "number_of_reviews")]
set.seed(123)
km.out <- kmeans(airbnb_2cols, centers = 3, nstart = 20)
km.outAusgabe:
K-means clustering with 3 clusters of sizes 785, 37, 16069
Cluster means:
price number_of_reviews
1 14264.102 5.9401274
2 83051.541 0.6756757
3 1589.879 18.2649200
Clustering vector:
[1] 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[37] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[73] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[109] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3
[145] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 1 3 3
...
[16777] 3 3 3 3 3 3 3 3 3 3 1 3 3 1 3 1 3 3 3 3 3 1 3 3 3 3 3 3 3 3 1 3 3 3 3 3
[16813] 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3
[16849] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3
[16885] 3 3 3 3 3 3 3
Within cluster sum of squares by cluster:
[1] 41529148852 49002793251 33286433394
(between_SS / total_SS = 74.5 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"Anhand der Ausgabe können wir feststellen, dass drei verschiedene Cluster mit den Größen 785, 37 und 16069 gefunden wurden. Für jeden Cluster werden die quadratischen Abstände zwischen den Beobachtungen und den Zentren berechnet. Jede Beobachtung wird also einem der drei Cluster zugeordnet.
Auch wenn es ein gutes Ergebnis zu sein scheint, ist der beste Weg, das beste Modell zu finden, verschiedene Modelle mit einer unterschiedlichen Anzahl von Clustern auszuprobieren. Wir müssen also mit einem Modell mit einem einzigen Cluster beginnen, danach ein Modell mit zwei Clustern ausprobieren und so weiter. All diese Vorgänge müssen mithilfe einer grafischen Darstellung, dem sogenannten Scree Plot, nachverfolgt werden, bei dem die Anzahl der Cluster auf der x-Achse und die WCSS auf der y-Achse aufgetragen wird.
In dieser Fallstudie erstellen wir 10 k-means-Modelle, von denen jedes eine andere Anzahl von Clustern hat, bis zu einem Maximum von 10 Clustern. Außerdem werden wir nur einen Teil des Datensatzes verwenden. Wir geben also nur den Preis und die Anzahl der Bewertungen an. Um den Scree Plot zu erstellen, müssen wir die Summe der Quadrate aller Modelle innerhalb eines Clusters in der Variable wss speichern.
# Decide how many clusters to look at
n_clusters <- 10
# Initialize total within sum of squares error: wss
wss <- numeric(n_clusters)
set.seed(123)
# Look over 1 to n possible clusters
for (i in 1:n) {
# Fit the model: km.out
km.out <- kmeans(airbnb_2cols, centers = i, nstart = 20)
# Save the within cluster sum of squares
wss[i] <- km.out$tot.withinss
}
# Produce a scree plot
wss_df <- tibble(clusters = 1:n, wss = wss)
scree_plot <- ggplot(wss_df, aes(x = clusters, y = wss, group = 1)) +
geom_point(size = 4)+
geom_line() +
scale_x_continuous(breaks = c(2, 4, 6, 8, 10)) +
xlab('Number of clusters')
scree_plot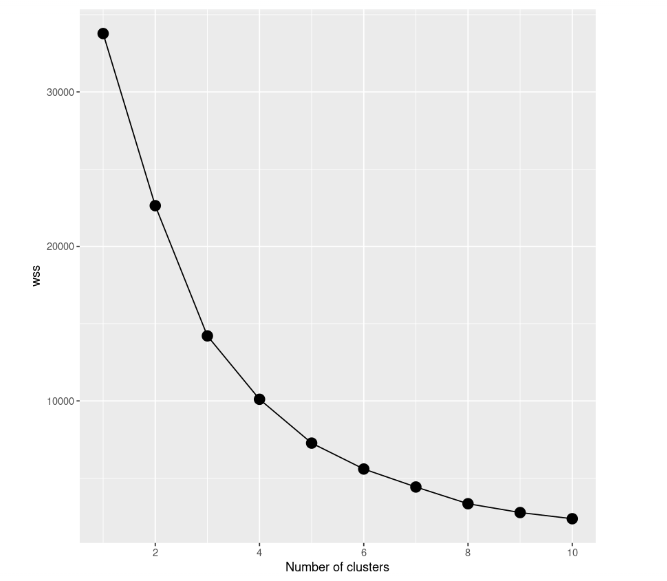
Ein Blick auf den Scree Plot zeigt, dass die Summe der Quadrate innerhalb der Cluster mit zunehmender Anzahl von Clustern abnimmt. Das Kriterium für die Auswahl der Anzahl von Clustern ist, dass du einen Punkt findest, an dem die WCSS nach Hinzufügen eines weiteren Clusters viel langsamer abnimmt. In diesem Fall ist es nicht so klar, also fügen wir horizontale Linien hinzu, um eine bessere Vorstellung zu bekommen:
scree_plot +
geom_hline(
yintercept = wss,
linetype = 'dashed',
col = c(rep('#000000',4),'#FF0000', rep('#000000', 5))
)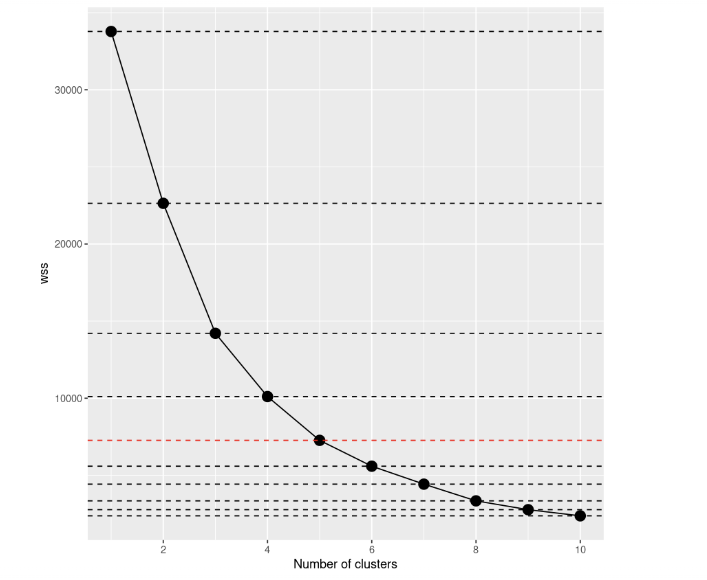
Wenn du es dir noch einmal ansiehst, scheint die Entscheidung, die du treffen musst, viel klarer zu sein als zuvor, meinst du nicht? Anhand dieser Visualisierung können wir sagen, dass die beste Wahl darin besteht, die Anzahl der Cluster auf 5 zu setzen. Nach k=5 scheinen sich die Verbesserungen der Modelle stark zu verringern.
# Select number of clusters
k <- 5
set.seed(123)
# Build model with k clusters: km.out
km.out <- kmeans(airbnb_2cols, centers = k, nstart = 20)Wir können noch einmal versuchen, das Streudiagramm zwischen dem Preis und der Anzahl der Bewertungen zu visualisieren. Wir färben die Punkte auch anhand der Cluster-ID ein:
data$cluster_id <- factor(km.out$cluster)
ggplot(data, aes(number_of_reviews, price, color = cluster_id)) +
geom_point(alpha = 0.25) +
xlab("Number of reviews") +
ylab("Price")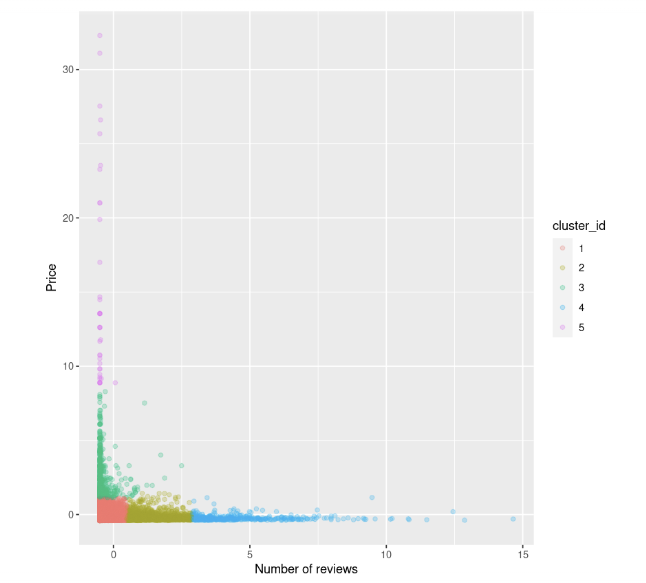
Das können wir beobachten:
Beachte, dass k-means einfach und leicht anzuwenden ist, aber es ist nicht immer die beste Wahl, um Daten in Gruppen aufzuteilen, da es versagen kann. Es wird davon ausgegangen, dass die Cluster kugelförmig sind, und in diesen Fällen leistet der Algorithmus gute Arbeit, während Gruppen mit unterschiedlichen Größen und Dichten von diesem Algorithmus nicht gut erfasst werden.
Wenn diese Bedingungen nicht erfüllt sind, ist es besser, alternative Ansätze wie DBSCAN und BIRCH zu wählen. Clustering beim maschinellen Lernen: 5 Essential Clustering Algorithms bietet einen guten Überblick über Clustering-Ansätze, falls du tiefer einsteigen willst.
Daraus können wir schließen, dass k-means nach wie vor einer der am häufigsten verwendeten Clustering-Algorithmen ist, um verschiedene Untergruppen zu identifizieren, auch wenn er nicht in allen Situationen perfekt ist. Jetzt hast du das Wissen, um es mit R in anderen Fallstudien anzuwenden
Wenn du dich eingehender mit dieser Methode beschäftigen willst, schau dir den Kurs Unüberwachtes Lernen in R an. Außerdem gibt es Cluster Analysis in R und An Introduction to Hierarchical Clustering in Python, um einen vollständigen Überblick über die verfügbaren Clustering-Ansätze zu erhalten, die nützlich sein können, wenn k-means nicht ausreicht, um aussagekräftige Erkenntnisse aus deinen Daten zu gewinnen. Wenn du auch überwachte Modelle mit R erforschen willst, ist dieser Kurs empfehlenswert!
Erfahre mehr über R
Kurs
Kurs
Kurs