Curso
Introdução ao R
4 h
3M
O K-means é uma técnica popular de aprendizado de máquina não supervisionado que permite a identificação de clusters (grupos semelhantes de pontos de dados) dentro dos dados. Neste tutorial, você aprenderá sobre o agrupamento k-means no R usando tidymodels, ggplot2 e ggmap. Abordaremos o assunto:
Antes de se aprofundar, recomendamos que você aprenda os conceitos básicos de programação em R, como vetores e quadros de dados. Se, em vez disso, você estiver pronto para essa jornada, pule essa parte e vamos começar!
Os modelos de agrupamento têm como objetivo agrupar os dados em "clusters" ou grupos distintos. Isso pode ser usado como uma análise por si só ou como um recurso em um algoritmo de aprendizado supervisionado.
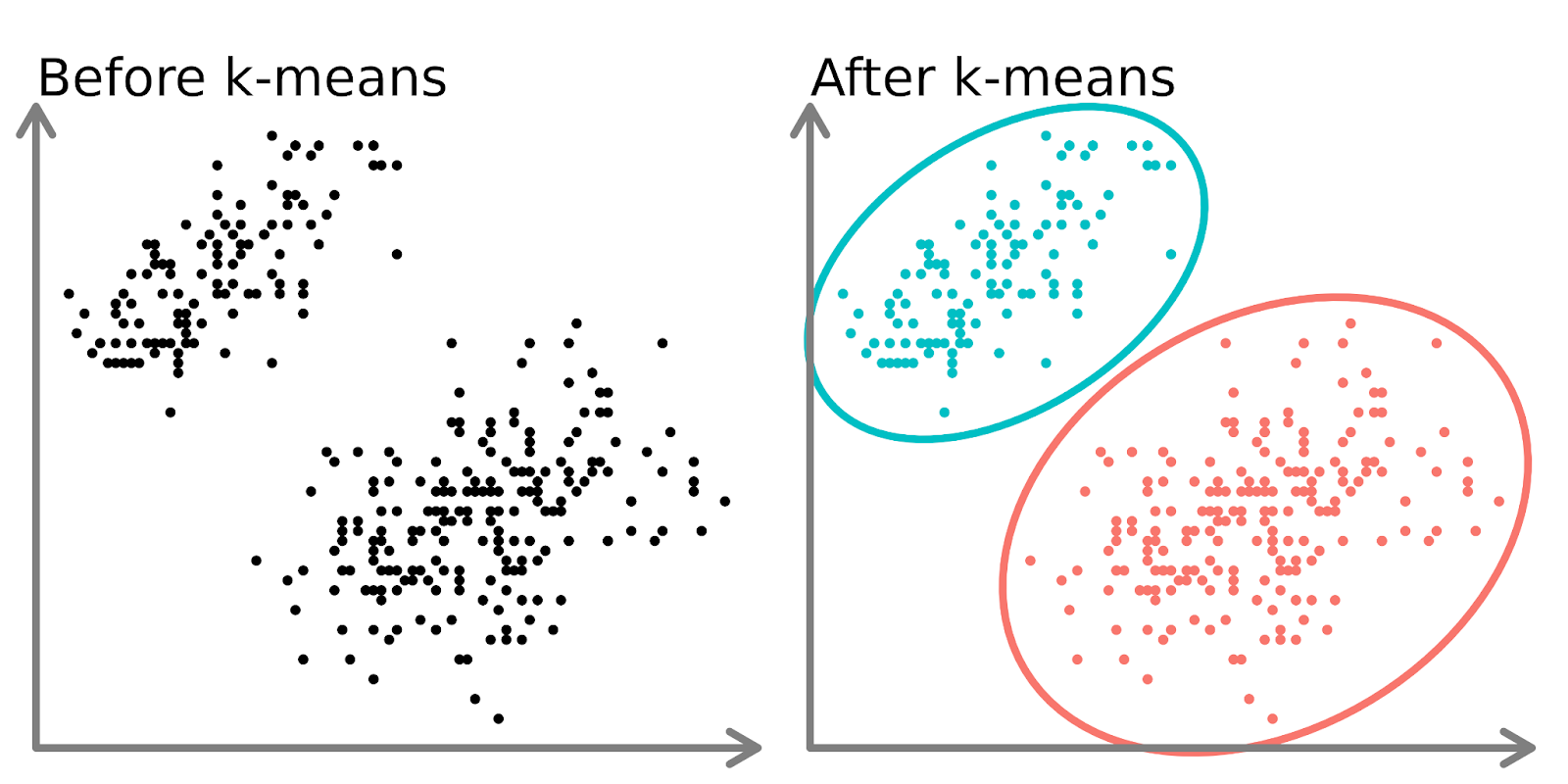
No lado esquerdo do diagrama acima, podemos ver dois conjuntos distintos de pontos que não são rotulados e são coloridos como pontos de dados semelhantes. O ajuste de um modelo k-means a esses dados (lado direito) pode revelar dois grupos distintos (mostrados em círculos e cores diferentes).
Em duas dimensões, é fácil para os humanos dividirem esses clusters, mas com mais dimensões, você precisa usar um modelo.
Imagine que você queira criar várias saladas de frutas, cada uma composta por frutas semelhantes.
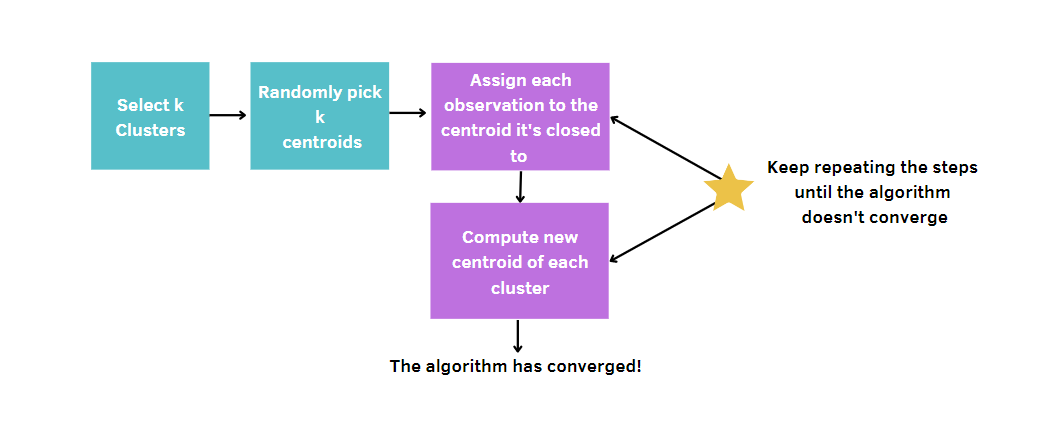
De modo mais geral, você:
Como o k-means escolhe aleatoriamente os centros dos clusters, esse algoritmo precisa ser executado um determinado número de vezes, que é fixado pelo usuário. Dessa forma, a melhor solução será alcançada, minimizando a medição da qualidade de um modelo. Essa medida é chamada de soma total de quadrados dentro do cluster (WCSS), que é a soma das distâncias entre os pontos de dados e o centroide correspondente de cada cluster. De fato, quanto mais a medição da qualidade do nosso modelo for pequena, mais chegaremos ao modelo vencedor.
Todo o conteúdo deste tutorial girará em torno dos anúncios de aluguel do Airbnb na Cidade do Cabo. Esse conjunto de dados está disponível no DataCamp Workspace. Os dados contêm diferentes tipos de informações, como os anfitriões, o preço, o número de avaliações, as coordenadas e assim por diante.
Mesmo que o conjunto de dados pareça fornecer informações detalhadas sobre aluguéis de temporada, ainda há algumas perguntas claras que podem ser respondidas. Por exemplo, vamos imaginar que o Airbnb solicite a seus cientistas de dados que investiguem a segmentação dos anúncios nessa plataforma na Cidade do Cabo.
Cada cidade é diferente da outra e tem exigências diferentes, dependendo da cultura das pessoas que vivem lá. A identificação de grupos nessa cidade pode ser útil para extrair novos insights, que podem aumentar a satisfação dos clientes reais com estratégias adequadas de fidelidade do cliente, evitando a rotatividade de clientes. Ao mesmo tempo, também é fundamental atrair novas pessoas com promoções adequadas.
Antes de aplicar o k-means, gostaríamos de investigar mais sobre a relação entre as variáveis, dando uma olhada na matriz de correlação. Para facilitar a exibição, arredondamos os dígitos para duas casas decimais.
library(dplyr)
airbnb |>
select(price, minimum_nights, number_of_reviews) |>
cor(use = "pairwise.complete.obs") |>
round(2)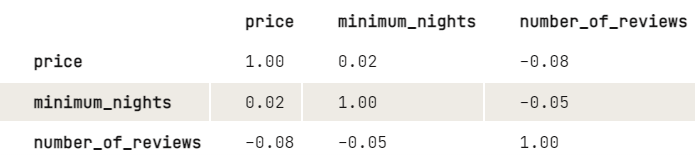
Com base nos resultados, parece haver uma leve relação negativa entre o preço e o número de avaliações: Quanto maior o preço, menor o número de avaliações. O mesmo vale para o mínimo de noites e várias avaliações. Como o mínimo de noites não tem um grande impacto sobre o preço, gostaríamos apenas de investigar mais sobre como o preço e o número de avaliações estão relacionados:
library(ggplot2)
ggplot(data, aes(number_of_reviews, price, color = room_type, shape = room_type)) +
geom_point(alpha = 0.25) +
xlab("Number of reviews") +
ylab("Price")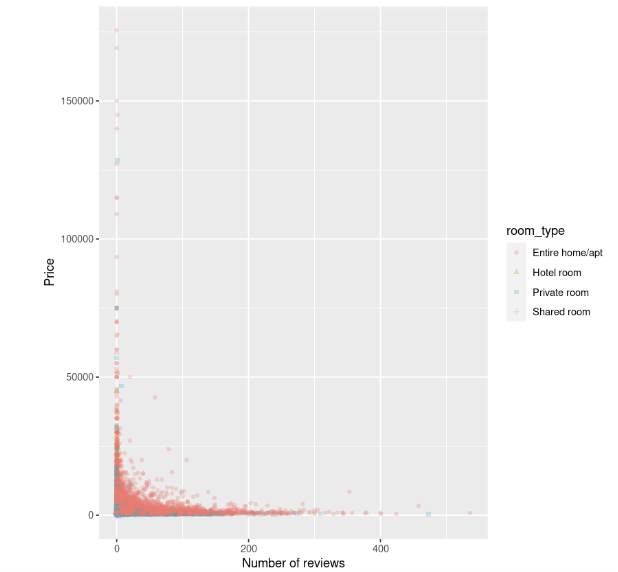
O gráfico de dispersão mostra que o custo das acomodações, em especial das casas inteiras, é mais alto quando há um pequeno número de avaliações e parece diminuir à medida que o número de avaliações aumenta.
Antes de ajustar o modelo, há uma outra etapa a ser executada. O k-means é sensível a variáveis que têm unidades incomparáveis, o que leva a resultados enganosos. Neste exemplo, o número de avaliações é de dezenas ou centenas, mas o preço é de dezenas de milhares. Sem nenhum processamento de dados, as diferenças de preço pareceriam ser maiores do que as diferenças nas avaliações, mas queremos que essas variáveis sejam tratadas igualmente.
Para evitar esse problema, as variáveis precisam ser transformadas para ficar em uma escala semelhante. Dessa forma, eles podem ser comparados corretamente usando a métrica de distância.
Há diferentes métodos para lidar com esse problema. A mais conhecida e usada é a padronização, que consiste em subtrair o valor médio do valor do recurso e, em seguida, dividi-lo pelo seu desvio padrão. Essa técnica permitirá a obtenção de recursos com uma média de 0 e um desvio de 1.
Você pode dimensionar as variáveis com a função scale(). Como isso retorna uma matriz, o código é mais limpo usando um estilo base-R em vez de um estilo tidyverse.
airbnb[, c("price", "number_of_reviews")] = scale(airbnb[, c("price", "number_of_reviews")])Por fim, podemos identificar os grupos de listagens com o k-means. Para começar, vamos tentar executar o k-means definindo 3 clusters e nstart igual a 20. Esse último parâmetro é necessário para executar o k-means com 20 atribuições iniciais aleatórias diferentes e, em seguida, o R escolherá automaticamente os melhores resultados da soma total de quadrados dentro do cluster. Também definimos uma semente para replicar os mesmos resultados sempre que executarmos o código.
# Get the two columns of interest
airbnb_2cols <- data[, c("price", "number_of_reviews")]
set.seed(123)
km.out <- kmeans(airbnb_2cols, centers = 3, nstart = 20)
km.outSaída:
K-means clustering with 3 clusters of sizes 785, 37, 16069
Cluster means:
price number_of_reviews
1 14264.102 5.9401274
2 83051.541 0.6756757
3 1589.879 18.2649200
Clustering vector:
[1] 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[37] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[73] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[109] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3
[145] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 1 3 3
...
[16777] 3 3 3 3 3 3 3 3 3 3 1 3 3 1 3 1 3 3 3 3 3 1 3 3 3 3 3 3 3 3 1 3 3 3 3 3
[16813] 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3
[16849] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3
[16885] 3 3 3 3 3 3 3
Within cluster sum of squares by cluster:
[1] 41529148852 49002793251 33286433394
(between_SS / total_SS = 74.5 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"Na saída, podemos observar que foram encontrados três clusters diferentes com tamanhos 785, 37 e 16069. Para cada cluster, são calculadas as distâncias quadradas entre as observações e os centroides. Portanto, cada observação será atribuída a um dos três clusters.
Mesmo que pareça um bom resultado, a melhor maneira de encontrar o melhor modelo é tentar modelos diferentes com um número diferente de clusters. Portanto, precisamos começar com um modelo com um único cluster, depois tentar um modelo com dois clusters e assim por diante. Todo esse procedimento precisa ser acompanhado por meio de uma representação gráfica, denominada scree plot, na qual o número de clusters é plotado no eixo x, enquanto o WCSS está no eixo y.
Neste estudo de caso, criamos 10 modelos k-means, cada um deles com um número diferente de clusters, chegando a um máximo de 10 clusters. Além disso, usaremos apenas uma parte do conjunto de dados. Portanto, incluímos apenas o preço e o número de avaliações. Para plotar o gráfico scree, precisamos salvar a soma total de quadrados dentro do cluster de todos os modelos na variável wss.
# Decide how many clusters to look at
n_clusters <- 10
# Initialize total within sum of squares error: wss
wss <- numeric(n_clusters)
set.seed(123)
# Look over 1 to n possible clusters
for (i in 1:n) {
# Fit the model: km.out
km.out <- kmeans(airbnb_2cols, centers = i, nstart = 20)
# Save the within cluster sum of squares
wss[i] <- km.out$tot.withinss
}
# Produce a scree plot
wss_df <- tibble(clusters = 1:n, wss = wss)
scree_plot <- ggplot(wss_df, aes(x = clusters, y = wss, group = 1)) +
geom_point(size = 4)+
geom_line() +
scale_x_continuous(breaks = c(2, 4, 6, 8, 10)) +
xlab('Number of clusters')
scree_plot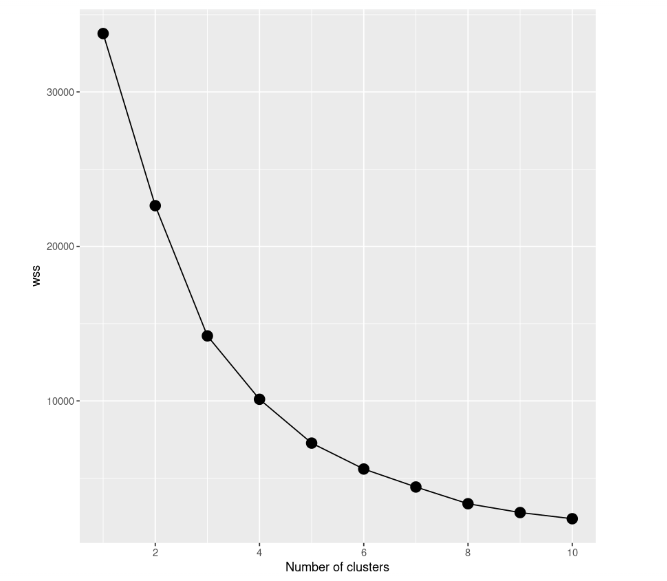
Dando uma olhada no gráfico scree, podemos notar como a soma total de quadrados dentro do cluster diminui à medida que o número de clusters aumenta. O critério para escolher o número de clusters é encontrar um cotovelo que permita encontrar um ponto em que o WCSS diminua muito mais lentamente após a adição de outro cluster. Nesse caso, não está tão claro, portanto, adicionaremos linhas horizontais para ter uma ideia melhor:
scree_plot +
geom_hline(
yintercept = wss,
linetype = 'dashed',
col = c(rep('#000000',4),'#FF0000', rep('#000000', 5))
)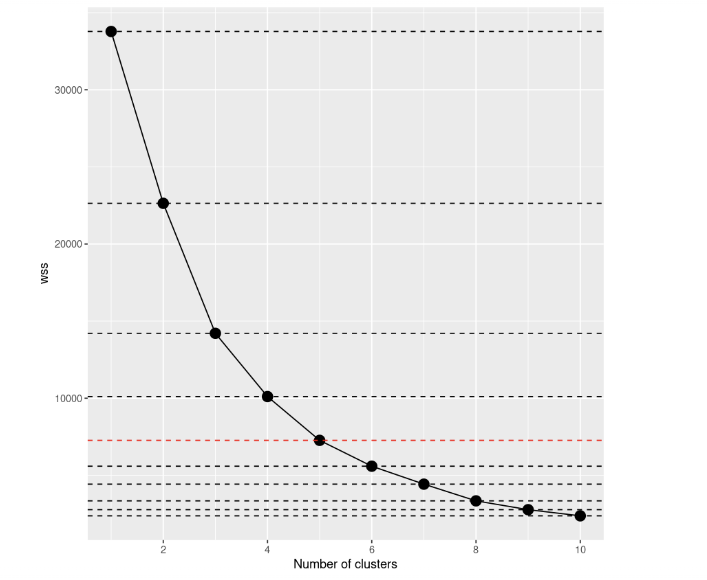
Se você der uma olhada novamente, a decisão a ser tomada parece muito mais clara do que antes, não acha? A partir dessa visualização, podemos dizer que a melhor opção é configurar o número de clusters igual a 5. Depois de k=5, os aprimoramentos dos modelos parecem se reduzir drasticamente.
# Select number of clusters
k <- 5
set.seed(123)
# Build model with k clusters: km.out
km.out <- kmeans(airbnb_2cols, centers = k, nstart = 20)Podemos tentar visualizar novamente o gráfico de dispersão entre o preço e o número de avaliações. Também colorimos os pontos com base na identificação do cluster:
data$cluster_id <- factor(km.out$cluster)
ggplot(data, aes(number_of_reviews, price, color = cluster_id)) +
geom_point(alpha = 0.25) +
xlab("Number of reviews") +
ylab("Price")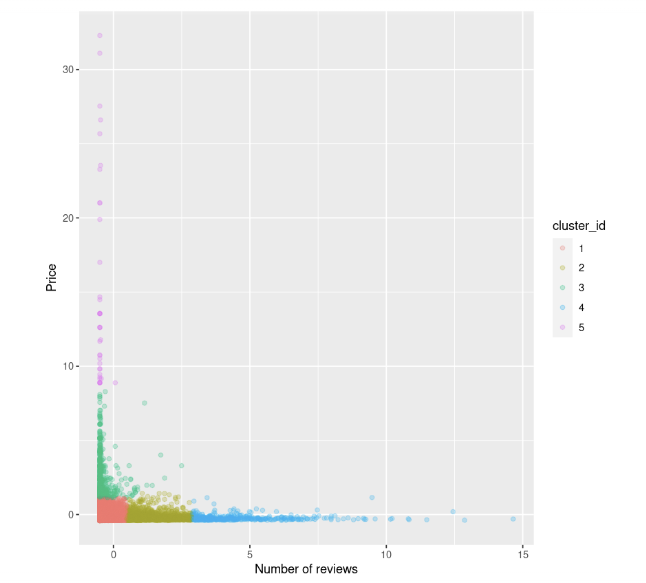
Podemos observar isso:
Observe que o k-means é simples e fácil de aplicar, mas nem sempre é a melhor opção para segmentar dados em grupos, pois pode falhar. Há a suposição de que os clusters são esféricos e, portanto, ele faz um bom trabalho com esses casos, enquanto grupos com diferentes tamanhos e densidades tendem a não ser bem capturados por esse algoritmo.
Quando essas condições não são respeitadas, é preferível encontrar outras abordagens alternativas, como DBSCAN e BIRCH. Agrupamento no aprendizado de máquina: 5 Essential Clustering Algorithms oferece uma excelente visão geral das abordagens de clustering, caso você queira se aprofundar no assunto.
Podemos concluir que o k-means continua sendo um dos algoritmos de agrupamento mais usados para identificar subgrupos distintos, mesmo que nem sempre seja perfeito em todas as situações. Agora, você tem o conhecimento necessário para aplicá-lo com o R em outros estudos de caso
Se quiser se aprofundar mais nesse método, dê uma olhada no curso Unsupervised Learning in R (Aprendizado não supervisionado em R). Há também Cluster Analysis in R e An Introduction to Hierarchical Clustering in Python para ter uma visão geral completa das abordagens de clustering disponíveis, que podem ser úteis quando o k-means não for suficiente para fornecer percepções significativas de seus dados. Caso você também queira explorar modelos supervisionados com o R, este curso é recomendado!
Saiba mais sobre o R
Curso
Curso
Curso
blog
Moez Ali
15 min
blog
Çağlar Uslu
12 min
Tutorial
Kevin Babitz
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Arunn Thevapalan

