Curso
Introducción a R
4 h
3M
K-means es una popular técnica de aprendizaje automático no supervisado que permite identificar clusters (grupos similares de puntos de datos) dentro de los datos. En este tutorial, usted aprenderá acerca de k-means clustering en R utilizando tidymodels, ggplot2 y ggmap. Cubriremos:
Antes de profundizar, te recomendamos que repases tus nociones básicas de programación en R, como vectores y marcos de datos. Si por el contrario estás preparado para este viaje, ¡sáltatelo y empecemos!
Los modelos de clustering pretenden agrupar los datos en "clusters" o grupos distintos. Puede utilizarse como análisis en sí mismo o como característica en un algoritmo de aprendizaje supervisado.
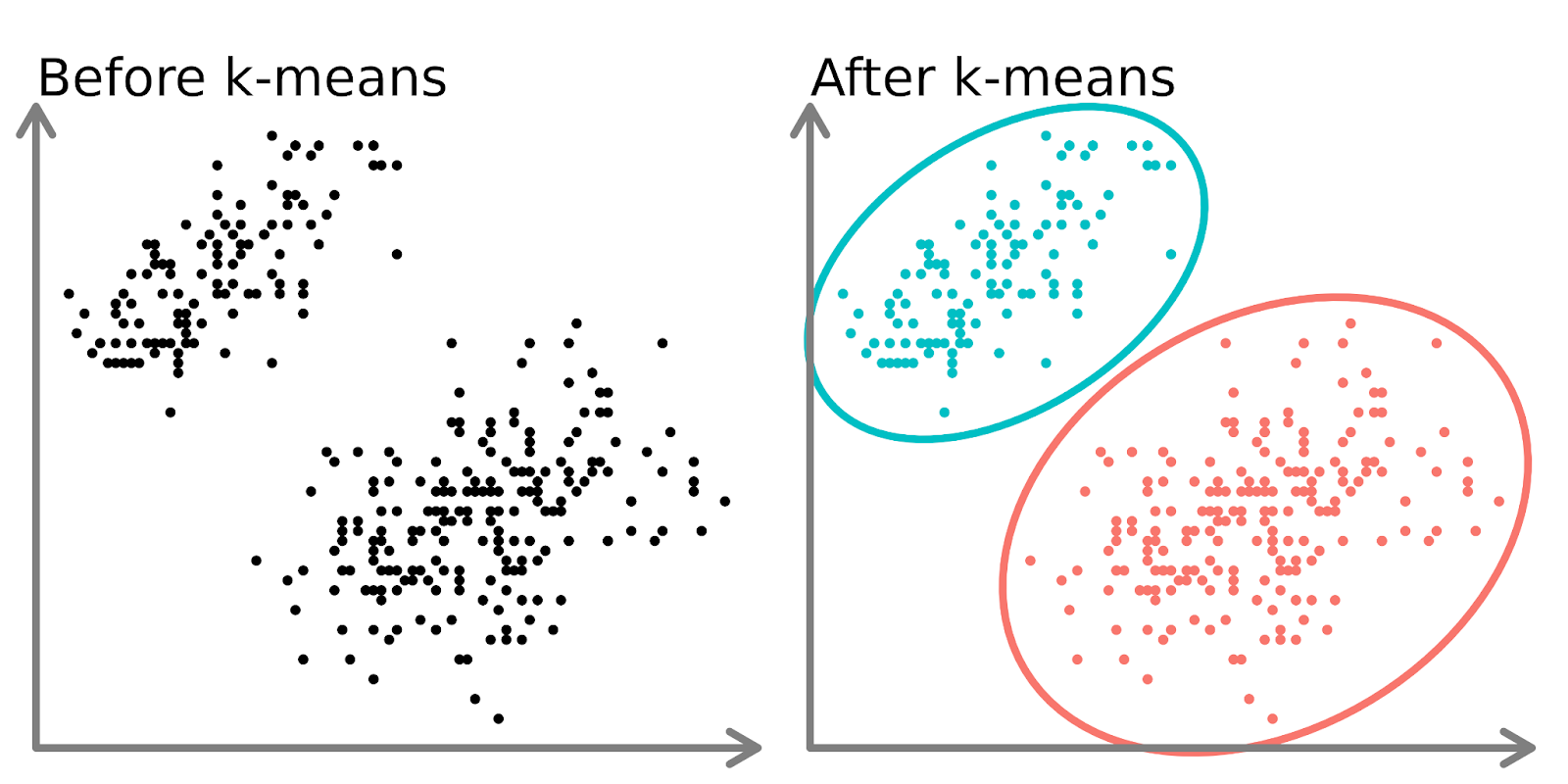
En la parte izquierda del diagrama anterior, podemos ver 2 conjuntos distintos de puntos sin etiquetar y coloreados como puntos de datos similares. El ajuste de un modelo k-means a estos datos (lado derecho) puede revelar 2 grupos distintos (mostrados en círculos y colores distintos).
En dos dimensiones, es fácil para los humanos dividir estos conglomerados, pero con más dimensiones, es necesario utilizar un modelo.
Imagina que quieres crear varias macedonias, cada una de ellas compuesta por frutas similares.
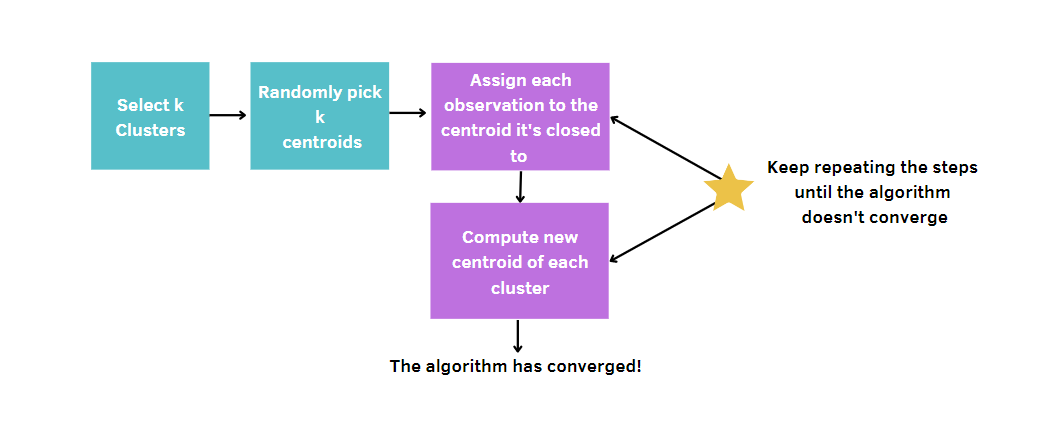
Más en general, tú:
Dado que k-means elige aleatoriamente los centros de los conglomerados, este algoritmo debe ejecutarse un número determinado de veces, fijado por el usuario. De este modo, se alcanzará la mejor solución, minimizando la medida de la calidad de un modelo. Esta medida se denomina suma total de cuadrados dentro del conglomerado (WCSS), es decir, la suma de las distancias entre los puntos de datos y el centroide correspondiente de cada conglomerado. De hecho, cuanto más pequeña sea la medida de la calidad de nuestro modelo, más llegaremos al modelo ganador.
Todo el contenido de este tutorial girará en torno a los listados de alquiler de Airbnb en Ciudad del Cabo, disponibles en DataLab. Los datos contienen distintos tipos de información, como los anfitriones, el precio, el número de reseñas, las coordenadas, etc.
Aunque el conjunto de datos parece proporcionar información exhaustiva sobre los alquileres vacacionales, aún quedan algunas preguntas claras que pueden responderse. Por ejemplo, imaginemos que Airbnb solicita a sus científicos de datos que investiguen la segmentación de los listados dentro de esta plataforma en Ciudad del Cabo.
Cada ciudad es diferente de las demás y tiene exigencias distintas según la cultura de sus habitantes. La identificación de clusters en esta ciudad puede ser útil para extraer nuevos conocimientos, que pueden aumentar la satisfacción de los clientes actuales con Estrategias de Fidelización de Clientes adecuadas, evitando la fuga de clientes. Al mismo tiempo, también es crucial atraer a gente nueva con promociones adecuadas.
Antes de aplicar k-means, nos gustaría investigar más sobre la relación entre las variables echando un vistazo a la matriz de correlaciones. Para facilitar la visualización, redondeamos los dígitos a dos decimales.
library(dplyr)
airbnb |>
select(price, minimum_nights, number_of_reviews) |>
cor(use = "pairwise.complete.obs") |>
round(2)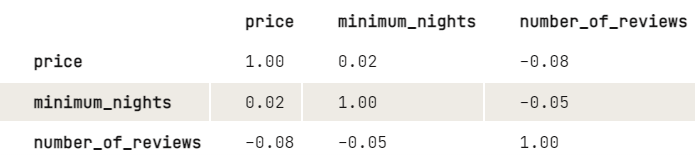
A partir de los resultados, parece existir una ligera relación negativa entre el precio y el número de opiniones: Cuanto mayor sea el precio, menor será el número de opiniones. Lo mismo para las noches mínimas y un número de revisiones. Dado que las noches mínimas no tienen un gran impacto en el precio, nos gustaría investigar más sobre cómo se relacionan el precio y el número de opiniones:
library(ggplot2)
ggplot(data, aes(number_of_reviews, price, color = room_type, shape = room_type)) +
geom_point(alpha = 0.25) +
xlab("Number of reviews") +
ylab("Price")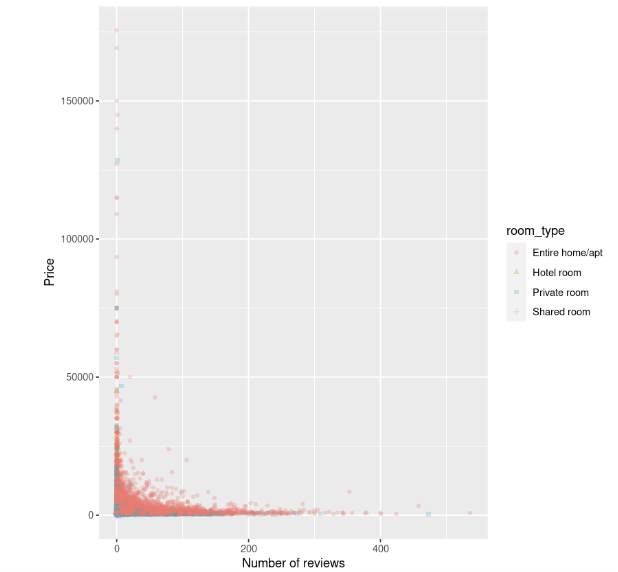
El diagrama de dispersión muestra que el coste de los alojamientos, en particular de las casas enteras, es mayor cuando el número de opiniones es pequeño, y parece disminuir a medida que aumenta el número de opiniones.
Antes de ajustar el modelo, hay que dar un paso más. k-means es sensible a las variables que tienen unidades incomparables, lo que lleva a resultados engañosos. En este ejemplo, el número de opiniones es de decenas o cientos, pero el precio es de decenas de miles. Sin ningún tratamiento de datos, las diferencias de precio parecerían mayores que las diferencias de reseñas, pero queremos que estas variables reciban el mismo trato.
Para evitar este problema, es necesario transformar las variables para que estén en una escala similar. De este modo, pueden compararse correctamente utilizando la métrica de la distancia.
Existen diferentes métodos para abordar este problema. La más conocida y utilizada es la normalización, que consiste en restar el valor medio del valor de la característica y, a continuación, dividirlo por su desviación típica. Esta técnica permitirá obtener características con una media de 0 y una desviación de 1.
Puede escalar las variables con la función scale(). Dado que esto devuelve una matriz, el código es más limpio utilizando un estilo base-R en lugar de un estilo tidyverse.
airbnb[, c("price", "number_of_reviews")] = scale(airbnb[, c("price", "number_of_reviews")])Por último, podemos identificar los grupos de listados con k-means. Para empezar, intentemos realizar k-means estableciendo 3 clusters y nstart igual a 20. Este último parámetro es necesario para ejecutar k-means con 20 asignaciones iniciales aleatorias diferentes y, a continuación, R elegirá automáticamente los mejores resultados suma total de cuadrados dentro del cluster. También establecemos una semilla para replicar los mismos resultados cada vez que ejecutemos el código.
# Get the two columns of interest
airbnb_2cols <- data[, c("price", "number_of_reviews")]
set.seed(123)
km.out <- kmeans(airbnb_2cols, centers = 3, nstart = 20)
km.outSalida:
K-means clustering with 3 clusters of sizes 785, 37, 16069
Cluster means:
price number_of_reviews
1 14264.102 5.9401274
2 83051.541 0.6756757
3 1589.879 18.2649200
Clustering vector:
[1] 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[37] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[73] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
[109] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3
[145] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 1 3 3
...
[16777] 3 3 3 3 3 3 3 3 3 3 1 3 3 1 3 1 3 3 3 3 3 1 3 3 3 3 3 3 3 3 1 3 3 3 3 3
[16813] 3 1 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3
[16849] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 1 3 3 3 3 3 3 3 3 3 3 3
[16885] 3 3 3 3 3 3 3
Within cluster sum of squares by cluster:
[1] 41529148852 49002793251 33286433394
(between_SS / total_SS = 74.5 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"A partir de la salida, podemos observar que se han encontrado tres clusters diferentes con tamaños de 785, 37 y 16069. Para cada conglomerado, se calculan las distancias al cuadrado entre las observaciones y los centroides. Así, cada observación se asignará a uno de los tres conglomerados.
Aunque parezca un buen resultado, la mejor manera de encontrar el mejor modelo es probar distintos modelos con un número diferente de conglomerados. Así pues, tenemos que partir de un modelo con un solo conglomerado, después probar un modelo con dos conglomerados y así sucesivamente. Todo este procedimiento debe seguirse mediante una representación gráfica, denominada scree plot, en la que el número de conglomerados se representa en el eje x, mientras que WCSS se representa en el eje y.
En este caso de estudio, construimos 10 modelos k-means, cada uno de los cuales tendrá un número diferente de clusters, llegando a un máximo de 10 clusters. Además, vamos a utilizar sólo una parte del conjunto de datos. Por lo tanto, sólo incluimos el precio y el número de opiniones. Para trazar el gráfico scree, necesitamos guardar la suma total de cuadrados dentro del cluster de todos los modelos en la variable wss.
# Decide how many clusters to look at
n_clusters <- 10
# Initialize total within sum of squares error: wss
wss <- numeric(n_clusters)
set.seed(123)
# Look over 1 to n possible clusters
for (i in 1:n) {
# Fit the model: km.out
km.out <- kmeans(airbnb_2cols, centers = i, nstart = 20)
# Save the within cluster sum of squares
wss[i] <- km.out$tot.withinss
}
# Produce a scree plot
wss_df <- tibble(clusters = 1:n, wss = wss)
scree_plot <- ggplot(wss_df, aes(x = clusters, y = wss, group = 1)) +
geom_point(size = 4)+
geom_line() +
scale_x_continuous(breaks = c(2, 4, 6, 8, 10)) +
xlab('Number of clusters')
scree_plot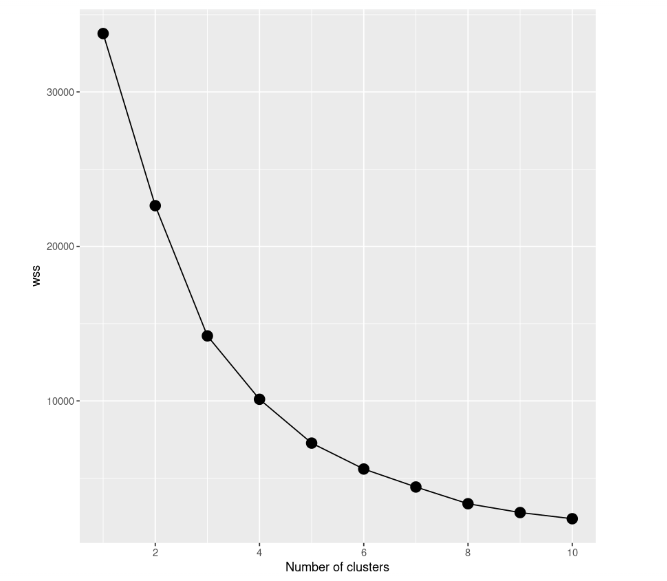
Si observamos el gráfico de dispersión, veremos que la suma total de cuadrados dentro de los conglomerados disminuye a medida que aumenta el número de conglomerados. El criterio para elegir el número de conglomerados es encontrar un codo tal que permita encontrar un punto en el que el WCSS disminuya mucho más lentamente después de añadir otro conglomerado. En este caso, no está tan claro, así que añadiremos líneas horizontales para hacernos una mejor idea:
scree_plot +
geom_hline(
yintercept = wss,
linetype = 'dashed',
col = c(rep('#000000',4),'#FF0000', rep('#000000', 5))
)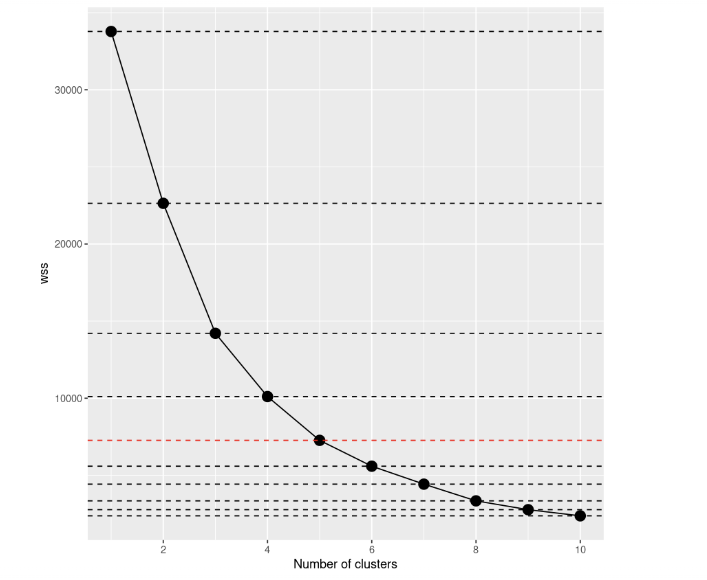
Si echas un vistazo de nuevo, la decisión a tomar parece mucho más clara que antes, ¿no crees? A partir de esta visualización, podemos decir que la mejor opción es establecer el número de clusters igual a 5. A partir de k=5, las mejoras de los modelos parecen reducirse bruscamente.
# Select number of clusters
k <- 5
set.seed(123)
# Build model with k clusters: km.out
km.out <- kmeans(airbnb_2cols, centers = k, nstart = 20)Podemos intentar de nuevo visualizar el diagrama de dispersión entre el precio y el número de reseñas. También coloreamos los puntos en función del identificador de clúster:
data$cluster_id <- factor(km.out$cluster)
ggplot(data, aes(number_of_reviews, price, color = cluster_id)) +
geom_point(alpha = 0.25) +
xlab("Number of reviews") +
ylab("Price")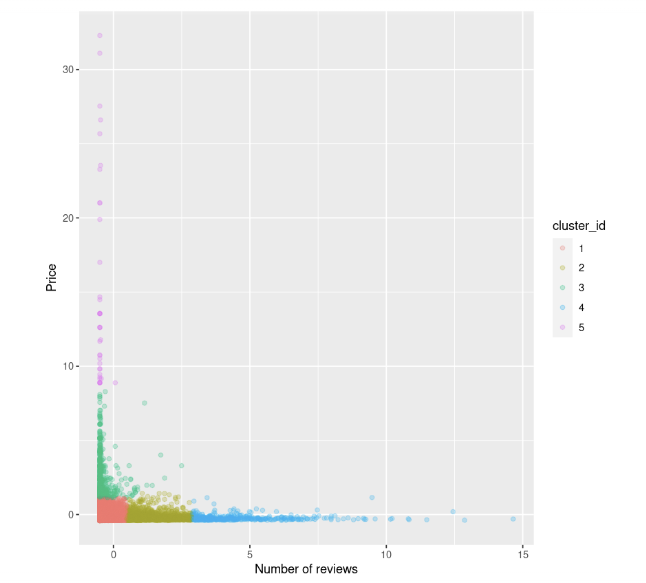
Podemos observar que:
Tenga en cuenta que k-means es simple y fácil de aplicar, pero no siempre es la mejor opción para segmentar datos en grupos, ya que puede fallar. Se supone que los conglomerados son esféricos y, entonces, hace un buen trabajo con estos casos, mientras que los grupos con diferentes tamaños y densidades tienden a no ser bien captados por este algoritmo.
Cuando no se respetan estas condiciones, es preferible buscar otros enfoques alternativos, como DBSCAN y BIRCH. Agrupación en el aprendizaje automático: 5 Essential Clustering Algorithms (5 algoritmos de clustering esenciales) proporciona una gran visión general de los enfoques de clustering en caso de que desee profundizar.
Podemos concluir que k-means sigue siendo uno de los algoritmos de agrupación más utilizados para identificar subgrupos distintos, aunque no siempre sea perfecto en todas las situaciones. Ahora, tienes los conocimientos para aplicarlo con R en otros casos prácticos
Si quieres profundizar más en este método, echa un vistazo al curso Unsupervised Learning in R. También hay Cluster Analysis in R y An Introduction to Hierarchical Clustering in Python para tener una visión completa de los enfoques de clustering disponibles, que pueden ser útiles cuando k-means no es suficiente para proporcionar una visión significativa de sus datos. En caso de que también desee explorar modelos supervisados con R, ¡este curso es recomendable!
Más información sobre R
Curso
Curso
Curso
blog
Zoumana Keita
14 min
Tutorial
Kevin Babitz
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Eladio Montero Porras
Tutorial
Zoumana Keita
