Lernpfad
Associate AI Engineer für Datenwissenschaftler
40 Std.
Um loszulegen, unterteilen wir das Ganze in ein paar Schritte. Zuerst erklären wir dir, wie du mit Hugging Face auf Llama 3.3 zugreifst, dein Konto einrichtest und die nötigen Berechtigungen bekommst. Dann erstellen wir die Projektumgebung und installieren die erforderlichen Abhängigkeiten.
Eine Möglichkeit, auf Llama 3.3 zuzugreifen, ist über Hugging Face, eine der beliebtesten Plattformen für das Hosting von Machine Learning-Modellen. Um Llama 3.3 über die Inference API von Hugging Face zu nutzen, brauchst du:
Nachdem der Zugriff auf das Modell gesichert ist, können wir die Umgebung der App einrichten. Zuerst erstellen wir einen Ordner für dieses Projekt. Öffne dein Terminal, navigiere zu dem Ort, an dem du deinen Projektordner erstellen willst, und führe aus:
mkdir multilingual-code-explanation
cd multilingual-code-explanationDann erstellen wir eine Datei namens app.py, die den Code enthält: touch app.pyJetzt schaffen wir eine Umgebung und aktivieren sie:
python3 -m venv venv
source venv/bin/activate’Jetzt, wo die Umgebung fertig ist, können wir die notwendigen Bibliotheken installieren. Stelle sicher, dass du Python 3.8+ verwendest. Gib im Terminal den folgenden Befehl ein, um die Streamlit-, Requests- und Hugging Face-Bibliotheken zu installieren:
pip install streamlit requests transformers huggingface-hubDas solltest du inzwischen wissen:
Jetzt, da die Einrichtung abgeschlossen ist, können wir die App erstellen! Im nächsten Abschnitt fangen wir an, die mehrsprachige Code-Erklärungs-App Schritt für Schritt zu programmieren.
Das Backend kommuniziert mit der Hugging Face API um das Codeschnipsel zu senden und die Erklärung zu erhalten.
Zuerst müssen wir die Bibliothek requests importieren. Diese Bibliothek ermöglicht es uns, HTTP-Anfragen an APIs zu senden. Schreibe oben in deine app.py Datei:
import requestsUm mit der auf Hugging Face gehosteten Llama 3.3 API zu interagieren, brauchst du:
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}Im obigen Code:
Jetzt schreiben wir eine Funktion, um eine Anfrage an die API zu senden. Die Funktion wird:
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"Die Eingabeaufforderung sagt Llama 3.3, dass es den Codeschnipsel in der gewünschten Sprache erklären soll.
Haftungsausschluss: Ich habe mit verschiedenen Prompts experimentiert, um denjenigen zu finden, der das beste Ergebnis lieferte, also gab es definitiv ein Element der Prompt-Engineering beteiligt!
Als nächstes wird die Nutzlast definiert. Für die Eingabe legen wir fest, dass die Eingabeaufforderung an das Modell gesendet wird. Bei den Parametern steuert max_new_tokens die Länge der Reaktion, während die Temperatur den Kreativitätsgrad der Ausgabe anpasst.
Die Funktion requests.post() sendet die Daten an Hugging Face. Wenn die Antwort erfolgreich ist (status_code == 200), wird der erzeugte Text extrahiert. Wenn ein Fehler auftritt, wird eine beschreibende Meldung zurückgegeben.
Schließlich gibt es noch Schritte, um die Ausgabe zu bereinigen und richtig zu formatieren. Dadurch wird sichergestellt, dass sie übersichtlich dargestellt werden, was das Nutzererlebnis deutlich verbessert.
Das Frontend ist der Ort, an dem die Nutzer mit der App interagieren. Streamlit ist eine Bibliothek, die interaktive Webanwendungen nur mit Python-Code erstellt und diesen Prozess einfach und intuitiv macht. Damit werden wir das Frontend unserer App erstellen. Ich mag Streamlit sehr, um Demos und POCs zu erstellen!
Am Anfang deiner app.py Datei hinzu:
import streamlit as stWir werden set_page_config() verwenden, um den Titel und das Layout der App zu definieren. Im unten stehenden Code:
page_title: Legt den Titel der Browser-Registerkarte fest.layout="wide": Ermöglicht es der App, die volle Bildschirmbreite zu nutzen.st.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")Um den Nutzern zu helfen, die App zu verstehen, fügen wir in der Seitenleiste eine Anleitung hinzu: Im unten stehenden Code:
st.sidebar.title(): Erzeugt einen Titel für die Seitenleiste.st.sidebar.markdown(): Fügt Text mit einfachen Anweisungen hinzu.divider(): Sorgt für eine saubere optische Trennung.st.sidebar.title("How to Use the App")
st.sidebar.markdown("""
1. Paste your code snippet into the input box.
2. Enter the language you want the explanation in (e.g., English, Spanish, French).
3. Click 'Generate Explanation' to see the results.
""")
st.sidebar.divider()
st.sidebar.markdown(
"""
<div style="text-align: center;color: grey;">
Made with ♡ by Ana
</div>
""",
unsafe_allow_html=True
)Wir fügen der Seite den Haupttitel und den Untertitel hinzu:
st.title("Multilingual Code Explanation Assistant")
st.markdown("### Powered by Llama 3.3 from Hugging Face 🦙")Damit die Nutzer den Code einfügen und ihre bevorzugte Sprache auswählen können, brauchen wir Eingabefelder. Da der Text des Codes wahrscheinlich länger ist als der Name der Sprache, wählen wir einen Textbereich für den Code und eine Texteingabe für die Sprache:
text_area(): Erzeugt ein großes Feld zum Einfügen von Code.text_input(): Ermöglicht es den Nutzern, die Sprache einzugeben.code_snippet = st.text_area("Paste your code snippet here:", height=200)
preferred_language = st.text_input("Enter your preferred language for explanation (e.g., English, Spanish):")Wir fügen nun eine Schaltfläche hinzu, um die Erklärung zu erstellen. Wenn der Benutzer den Code und die Sprache eingibt und dann auf die Schaltfläche Erklärung generieren klickt, wird eine Antwort generiert.
if st.button("Generate Explanation"):
if code_snippet and preferred_language:
with st.spinner("Generating explanation... ⏳"):
explanation = query_llama3(code_snippet, preferred_language)
st.subheader("Generated Explanation:")
st.write(explanation)
else:
st.warning("⚠️ Please provide both the code snippet and preferred language.")
Wenn die Schaltfläche angeklickt wird, wird die App:
Zum Schluss fügen wir noch eine Fußzeile ein:
st.markdown("---")
st.markdown("🧠 **Note**: This app uses Llama 3.3 from Hugging Face for multilingual code explanations.")Es ist Zeit, die App zu starten! Um deine App zu starten, führe diesen Code im Terminal aus:
streamlit run app.pyDie App wird in deinem Browser geöffnet, und du kannst mit ihr spielen!

Jetzt, wo wir unsere mehrsprachige Code-Erklärungs-App gebaut haben, ist es an der Zeit zu testen, wie gut das Modell funktioniert. In diesem Abschnitt verwenden wir die App, um ein paar Codeschnipsel zu verarbeiten und die Erklärungen in verschiedenen Sprachen zu bewerten.
Für unseren ersten Test beginnen wir mit einem Python-Skript, das die Fakultät einer Zahl mithilfe einer Rekursion berechnet. Hier ist der Code, den wir verwenden werden:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
num = 5
result = factorial(num)
print(f"The factorial of {num} is {result}")Dieses Skript definiert eine rekursive Funktion factorial(n), die die Fakultät einer gegebenen Zahl errechnet. Für num = 5 wird die Funktion 5×4×3×2×1 berechnen, was 120 ergibt. Das Ergebnis wird mit der Anweisung print() auf dem Bildschirm ausgedruckt. Hier ist die Ausgabe, wenn wir eine Erklärung auf Spanisch erstellen:
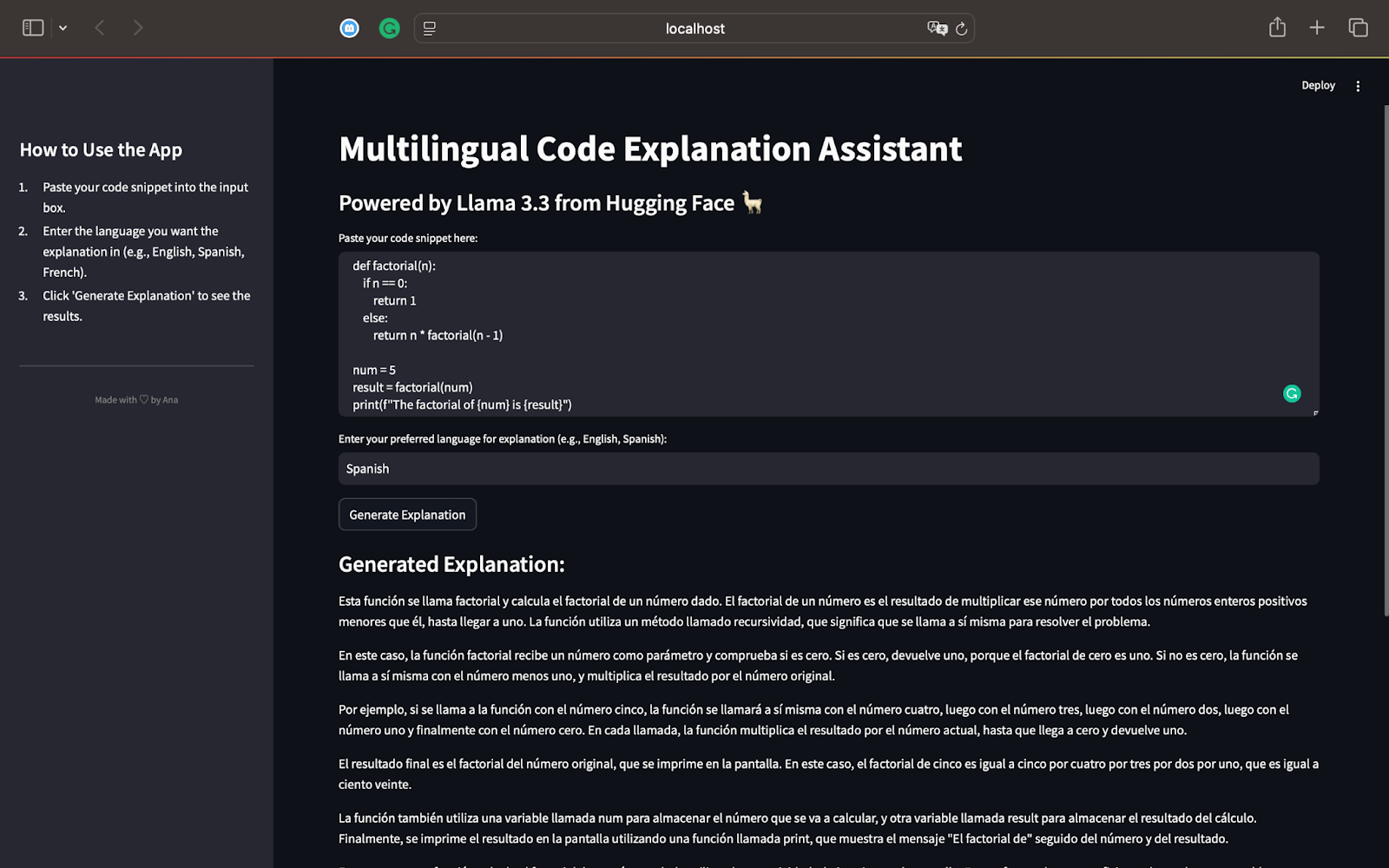

Als Spanischsprachige kann ich bestätigen, dass in der Erklärung korrekt angegeben ist, dass der Code die Fakultät einer Zahl mithilfe einer Rekursion berechnet. Er erklärt Schritt für Schritt, wie die Rekursion funktioniert, indem er sie in einfache Begriffe zerlegt.
Das Modell erklärt den Rekursionsprozess und zeigt, wie die Funktion sich selbst mit abnehmenden Werten von n aufruft, bis sie 0 erreicht.
Die Erklärung ist, wie gewünscht, komplett auf Spanisch, was die Mehrsprachigkeit von Llama 3.3 unterstreicht.
Durch die Verwendung einfacher Sätze ist das Konzept der Rekursion auch für Leser, die mit dem Programmieren nicht vertraut sind, leicht zu verstehen.
Er fasst zusammen und erwähnt, wie Rekursion für andere Eingaben wie 3 funktioniert und wie wichtig Rekursion als effizientes Problemlösungskonzept in der Programmierung ist.
Dieser erste Test zeigt die Leistungsfähigkeit von Llama 3.3:
Nachdem wir nun ein Python-Skript getestet haben, können wir zu anderen Programmiersprachen wie JavaScript oder SQL übergehen. Dies wird uns helfen, die Fähigkeiten von Llama 3.3 in den Bereichen Argumentation, Codierung und mehrsprachige Unterstützung weiter zu erforschen.
In diesem Test prüfen wir, wie gut die mehrsprachige Code-Erklärungs-App mit einer JavaScript-Funktion umgeht und eine Erklärung auf Französisch erstellt.
Wir verwenden den folgenden JavaScript-Codeausschnitt, in dem ich absichtlich mehrdeutige Variablen gewählt habe, um zu sehen, wie gut das Modell damit umgeht:
function x(a) {
if (a === 1) return 1;
return a * x(a - 1);
}
const y = 6;
const z = x(y);
console.log("The result is: " + z);Dieser Codeschnipsel definiert eine rekursive Funktion x(a), die die Fakultät einer gegebenen Zahl a berechnet. Die Grundbedingung prüft, ob a === 1. Wenn ja, gibt sie 1 zurück. Ansonsten ruft die Funktion sich selbst mit a - 1 auf und multipliziert das Ergebnis mit a. Die Konstante y ist auf 6 gesetzt, also berechnet die Funktion x 6×5×4×3×2×1. Schließlich wird das Ergebnis in der Variablen z gespeichert und mit console.log angezeigt. Hier ist die Ausgabe und die Übersetzung ins Englische:

Hinweis: Es sieht so aus, als ob die Antwort plötzlich abgeschnitten ist, aber das liegt daran, dass wir die Ausgabe auf 500 Token begrenzt haben!
Nachdem ich dies übersetzt hatte, kam ich zu dem Schluss, dass die Erklärung korrekt angibt, dass die Funktion x(a) rekursiv ist. Er erklärt, wie Rekursion funktioniert, den Basisfall (a === 1) und den rekursiven Fall (a * x(a - 1)). Die Erklärung zeigt explizit, wie die Funktion die Fakultät von 6 berechnet und erwähnt die Rollen von y (der Eingabewert) und z (das Ergebnis). Es wird auch darauf hingewiesen, wie console.log verwendet wird, um das Ergebnis anzuzeigen.
Die Erklärung ist, wie gewünscht, vollständig auf Französisch. Die Fachbegriffe wie "récursive" (rekursiv), "factorielle" (faktoriell) und "produit" (Produkt) werden korrekt verwendet. Und nicht nur das, er zeigt auch, dass dieser Code die Fakultät einer Zahl auf rekursive Weise berechnet.
Die Erklärung vermeidet übermäßigen Fachjargon und vereinfacht die Rekursion, so dass sie auch für Leser, die neu im Programmieren sind, zugänglich ist.
Dieser Test zeigt, dass Llama 3.3:
Nachdem wir die App mit Python und JavaScript getestet haben, wollen wir sie nun mit einer SQL-Abfrage testen, um ihre Mehrsprachigkeit und ihre Argumentationsfähigkeit weiter zu prüfen.
In diesem letzten Test testen wir, wie die mehrsprachige Code-Erklärungs-App mit einer SQL-Abfrage umgeht und eine Erklärung auf Deutsch erzeugt. Hier ist das verwendete SQL-Snippet:
SELECT a.id, SUM(b.value) AS total_amount
FROM table_x AS a
JOIN table_y AS b ON a.ref_id = b.ref
WHERE b.flag = 1
GROUP BY a.id
HAVING SUM(b.value) > 1000
ORDER BY total_amount DESC;Diese Abfrage wählt die Spalte id aus und berechnet den Gesamtwert (SUM(b.value)) für jede id. Sie liest Daten aus zwei Tabellen: table_x (alias a) und table_y (alias b). Verwendet dann eine JOIN Bedingung, um Zeilen zu verbinden, in denen a.ref_id = b.ref. Es filtert Zeilen, in denen b.flag = 1 und gruppiert die Daten nach a.id. Die HAVING Klausel filtert die Gruppen so, dass nur die Gruppen enthalten sind, bei denen die Summe von b.value größer als 1000 ist. Schließlich ordnet er die Ergebnisse nach total_amount in absteigender Reihenfolge.
Nachdem wir auf die Schaltfläche "Erklärung generieren" geklickt haben, sehen wir das hier:

Die erstellte Erklärung ist prägnant, genau und gut strukturiert. Jede wichtige SQL-Klausel (SELECT, FROM, JOIN, WHERE, GROUP BY, HAVING und ORDER BY) wird klar erklärt. Außerdem entspricht die Beschreibung der Reihenfolge der Ausführung in SQL, was den Lesern hilft, die Abfragelogik Schritt für Schritt nachzuvollziehen.
Die Erklärung ist, wie gewünscht, komplett auf Deutsch.
Wichtige SQL-Begriffe (z. B. "gefiltert", "gruppiert", "sortiert") werden im Kontext richtig verwendet. Die Erklärung zeigt, dass HAVING verwendet wird, um gruppierte Ergebnisse zu filtern, was bei Anfängern häufig zu Verwirrung führt. Außerdem wird die Verwendung von Aliasen (AS) erklärt, um Tabellen und Spalten zur besseren Übersichtlichkeit umzubenennen.
Die Erklärung vermeidet eine allzu komplexe Terminologie und konzentriert sich auf die Funktion der einzelnen Klauseln. Das macht es Anfängern leicht zu verstehen, wie die Abfrage funktioniert.
Dieser Test zeigt, dass Llama 3.3:
Wir haben die App mit Codeschnipseln in Python, JavaScript und SQL getestet und Erklärungen auf Spanisch, Französisch und Deutsch erstellt. In jedem Test:
Mit diesem Test haben wir bestätigt, dass die App, die wir entwickelt haben, vielseitig, zuverlässig und effektiv ist, um Code in verschiedenen Programmiersprachen und natürlichen Sprachen zu erklären.
Herzlichen Glückwunsch! Du hast einen voll funktionsfähigen mehrsprachigen Code-Erklärungsassistenten mit Streamlit und Llama 3.3 von Hugging Face gebaut.
In diesem Lernprogramm hast du gelernt:
Dieses Projekt ist ein großartiger Ausgangspunkt, um die Möglichkeiten von Llama 3.3 in Bezug auf Code Reasoning, mehrsprachige Unterstützung und Lehrinhalte zu erkunden. Du kannst deine eigene App erstellen, um die leistungsstarken Funktionen dieses Modells weiter zu erkunden!
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.