Programa
Engenheiro associado de IA para cientistas de dados
40 h
Para começar, vamos dividir isso em algumas etapas. Primeiro, falaremos sobre como acessar o Llama 3.3 usando o Hugging Face, configurar sua conta e obter as permissões necessárias. Em seguida, criaremos o ambiente do projeto e instalaremos as dependências necessárias.
Uma maneira de acessar o Llama 3.3 é por meio do Hugging Face, uma das plataformas mais populares para hospedar modelos de aprendizado de máquina. Para usar o Llama 3.3 por meio da API de inferência do Hugging Face, você precisará:
Com o acesso ao modelo garantido, vamos configurar o ambiente do aplicativo. Primeiro, vamos criar uma pasta para este projeto. Abra o terminal, navegue até o local onde você deseja criar a pasta do projeto e execute:
mkdir multilingual-code-explanation
cd multilingual-code-explanationEm seguida, criaremos um arquivo chamado app.py para manter o código: touch app.pyAgora, criamos um ambiente e o ativamos:
python3 -m venv venv
source venv/bin/activate’Agora que o ambiente está pronto, vamos instalar as bibliotecas necessárias. Certifique-se de que você esteja executando o Python 3.8+. No terminal, execute o seguinte comando para instalar as bibliotecas Streamlit, Requests e Hugging Face:
pip install streamlit requests transformers huggingface-hubA essa altura, você já deve ter percebido:
Agora que a configuração está concluída, estamos prontos para criar o aplicativo! Na próxima seção, começaremos a codificar o aplicativo de explicação de código multilíngue passo a passo.
O back-end se comunica com a API Hugging Face para enviar o trecho de código e receber a explicação.
Primeiro, precisamos importar a biblioteca requests. Essa biblioteca nos permite enviar solicitações HTTP para APIs. Na parte superior do arquivo app.py, escreva:
import requestsPara interagir com a API Llama 3.3 hospedada no Hugging Face, você precisa:
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}No código acima:
Agora, escreveremos uma função para enviar uma solicitação à API. A função irá:
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"O prompt diz ao Llama 3.3 para explicar o trecho de código na linguagem desejada.
Isenção de responsabilidade: Fiz experimentos com diferentes prompts para encontrar o que produzia o melhor resultado, portanto, houve definitivamente um elemento de engenharia de prompts de prompts!
Em seguida, a carga útil é definida. Para a entrada, especificamos que o prompt é enviado ao modelo. Nos parâmetros, max_new_tokens controla a duração da resposta, enquanto a temperatura ajusta o nível de criatividade da saída.
A função requests.post() envia os dados para o Hugging Face. Se a resposta for bem-sucedida (status_code == 200), o texto gerado será extraído. Se houver um erro, uma mensagem descritiva será retornada.
Por fim, há etapas para limpar e formatar a saída adequadamente. Isso garante que ele seja apresentado de forma organizada, o que melhora significativamente a experiência do usuário.
O front-end é onde os usuários interagem com o aplicativo. Streamlit é uma biblioteca que cria aplicativos interativos da Web apenas com código Python e torna esse processo simples e intuitivo. Isso é o que usaremos para criar o front-end do nosso aplicativo. Gosto muito do Streamlit para criar demonstrações e POC!
Na parte superior do arquivo app.py adicione:
import streamlit as stUsaremos o site set_page_config() para definir o título e o layout do aplicativo. No código abaixo:
page_title: Define o título da guia do navegador.layout="wide": Permite que o aplicativo use a largura total da tela.st.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")Para ajudar os usuários a entender como usar o aplicativo, adicionaremos instruções à barra lateral: No código abaixo:
st.sidebar.title(): Cria um título para a barra lateral.st.sidebar.markdown(): Adiciona texto com instruções simples.divider(): Adiciona uma separação visual limpa.st.sidebar.title("How to Use the App")
st.sidebar.markdown("""
1. Paste your code snippet into the input box.
2. Enter the language you want the explanation in (e.g., English, Spanish, French).
3. Click 'Generate Explanation' to see the results.
""")
st.sidebar.divider()
st.sidebar.markdown(
"""
<div style="text-align: center;color: grey;">
Made with ♡ by Ana
</div>
""",
unsafe_allow_html=True
)Vamos adicionar o título principal e o subtítulo à página:
st.title("Multilingual Code Explanation Assistant")
st.markdown("### Powered by Llama 3.3 from Hugging Face 🦙")Agora, para permitir que os usuários colem códigos e escolham o idioma preferido, precisamos de campos de entrada. Como o texto do código provavelmente será mais longo do que o nome do idioma, estamos escolhendo uma área de texto para o código e uma entrada de texto para o idioma:
text_area(): Cria uma caixa grande para você colar o código.text_input(): Permite que os usuários digitem o idioma.code_snippet = st.text_area("Paste your code snippet here:", height=200)
preferred_language = st.text_input("Enter your preferred language for explanation (e.g., English, Spanish):")Agora adicionamos um botão para gerar a explicação. Se o usuário inserir o código e o idioma e, em seguida, clicar no botão Generate Explanation (Gerar explicação), será gerada uma resposta.
if st.button("Generate Explanation"):
if code_snippet and preferred_language:
with st.spinner("Generating explanation... ⏳"):
explanation = query_llama3(code_snippet, preferred_language)
st.subheader("Generated Explanation:")
st.write(explanation)
else:
st.warning("⚠️ Please provide both the code snippet and preferred language.")
Quando o botão é clicado, o aplicativo:
Para finalizar, vamos adicionar um rodapé:
st.markdown("---")
st.markdown("🧠 **Note**: This app uses Llama 3.3 from Hugging Face for multilingual code explanations.")É hora de executar o aplicativo! Para iniciar seu aplicativo, execute este código no terminal:
streamlit run app.pyO aplicativo será aberto no seu navegador e você poderá começar a brincar com ele!

Agora que criamos nosso aplicativo de explicação de código multilíngue, é hora de testar se o modelo funciona bem. Nesta seção, usaremos o aplicativo para processar alguns trechos de código e avaliar as explicações geradas em diferentes idiomas.
Para o nosso primeiro teste, vamos começar com um script Python que calcula o fatorial de um número usando recursão. Aqui está o código que usaremos:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
num = 5
result = factorial(num)
print(f"The factorial of {num} is {result}")Esse script define uma função recursiva factorial(n) que calcula o fatorial de um determinado número. Para num = 5, a função calculará 5×4×3×2×1, resultando em 120. O resultado é impresso na tela usando a instrução print(). Aqui está o resultado quando geramos uma explicação em espanhol:
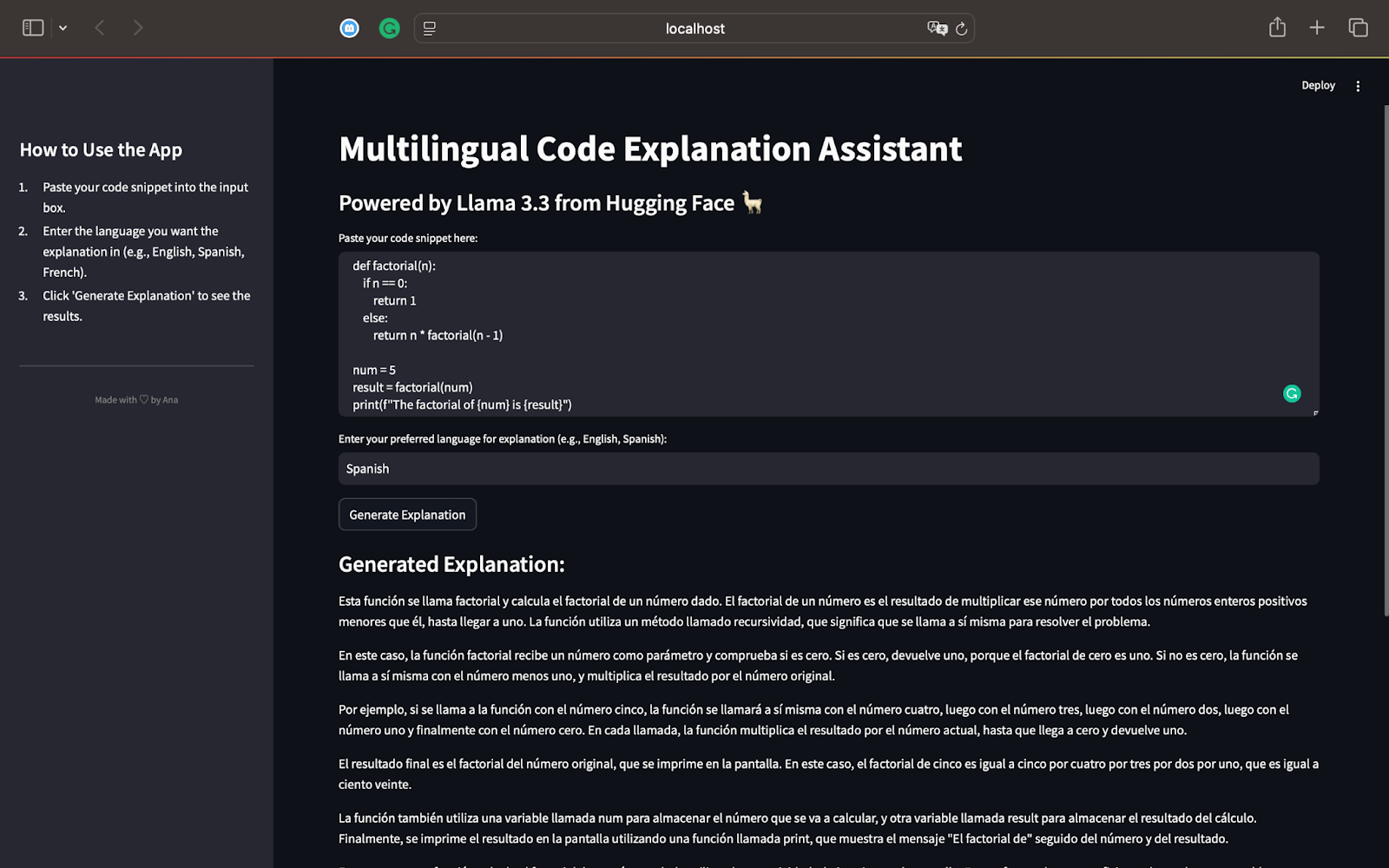

Como falante de espanhol, posso confirmar que a explicação identifica corretamente que o código calcula o fatorial de um número usando recursão. Você verá como a recursão funciona passo a passo, dividindo-a em termos simples.
O modelo explica o processo de recursão e mostra como a função chama a si mesma com valores decrescentes de n até chegar a 0.
A explicação está totalmente em espanhol, conforme solicitado, demonstrando os recursos multilíngues do Llama 3.3.
O uso de frases simples torna o conceito de recursão fácil de entender, mesmo para leitores não familiarizados com programação.
Ele resume e menciona como a recursão funciona para outras entradas, como 3, e a importância da recursão como um conceito eficiente de solução de problemas na programação.
Esse primeiro teste destaca o poder do Llama 3.3:
Agora que testamos um script Python, podemos passar para outras linguagens de programação, como JavaScript ou SQL. Isso nos ajudará a explorar melhor os recursos do Llama 3.3 em termos de raciocínio, codificação e suporte multilíngue.
Neste teste, avaliaremos como o aplicativo de explicação de código multilíngue lida com uma função JavaScript e gera uma explicação em francês.
Usamos o seguinte trecho de código JavaScript no qual escolhi intencionalmente variáveis ambíguas para ver se o modelo lida bem com isso:
function x(a) {
if (a === 1) return 1;
return a * x(a - 1);
}
const y = 6;
const z = x(y);
console.log("The result is: " + z);Esse trecho de código define uma função recursiva x(a) que calcula o fatorial de um determinado número a. A condição básica verifica se a === 1. Em caso afirmativo, ele retorna 1. Caso contrário, a função chama a si mesma com a - 1 e multiplica o resultado por a. A constante y está definida como 6, portanto, a função x calcula 6×5×4×3×2×1. Por fim, o resultado é armazenado na variável z e exibido usando console.log. Aqui está o resultado e a tradução em inglês:

Observação: Você pode ver que parece que a resposta foi subitamente cortada, mas isso ocorre porque limitamos a saída a 500 tokens!
Depois de traduzir isso, concluí que a explicação identifica corretamente que a função x(a) é recursiva. Ele detalha o funcionamento da recursão, explicando o caso básico (a === 1) e o caso recursivo (a * x(a - 1)). A explicação mostra explicitamente como a função calcula o fatorial de 6 e menciona os papéis de y (o valor de entrada) e z (o resultado). Ele também observa como o console.log é usado para exibir o resultado.
A explicação está totalmente em francês, conforme solicitado. Os termos técnicos como "récursive" (recursivo), "factorielle" (fatorial) e "produit" (produto) são usados corretamente. E não é só isso, ele identifica que esse código calcula o fatorial de um número de forma recursiva.
A explicação evita o jargão excessivamente técnico e simplifica a recursão, tornando-a acessível aos leitores iniciantes em programação.
Esse teste demonstra que o Llama 3.3:
Agora que testamos o aplicativo com Python e JavaScript, vamos testá-lo com uma consulta SQL para avaliar melhor seus recursos multilíngues e de raciocínio.
Neste último teste, avaliaremos como o aplicativo de explicação de código multilíngue lida com uma consulta SQL e gera uma explicação em alemão. Aqui está o snippet de SQL usado:
SELECT a.id, SUM(b.value) AS total_amount
FROM table_x AS a
JOIN table_y AS b ON a.ref_id = b.ref
WHERE b.flag = 1
GROUP BY a.id
HAVING SUM(b.value) > 1000
ORDER BY total_amount DESC;Essa consulta seleciona a coluna id e calcula o valor total (SUM(b.value)) para cada id. Ele lê dados de duas tabelas: table_x (com o pseudônimo a) e table_y (com o pseudônimo b). Em seguida, você usa uma condição JOIN para conectar as linhas em que a.ref_id = b.ref. Ele filtra as linhas onde b.flag = 1 e agrupa os dados por a.id. A cláusula HAVING filtra os grupos para incluir apenas aqueles em que a soma de b.value é maior que 1000. Por fim, ele ordena os resultados por total_amount em ordem decrescente.
Depois de pressionar o botão gerar explicação, é isso que você obtém:

A explicação gerada é concisa, precisa e bem estruturada. Cada cláusula SQL principal (SELECT, FROM, JOIN, WHERE, GROUP BY, HAVING e ORDER BY) é explicada claramente. Além disso, a descrição corresponde à ordem de execução no SQL, o que ajuda os leitores a seguir a lógica da consulta passo a passo.
A explicação está totalmente em alemão, conforme solicitado.
Os principais termos SQL (por exemplo, "filtert", "gruppiert", "sortiert") são usados com precisão no contexto. A explicação identifica que o HAVING é usado para filtrar resultados agrupados, o que é uma fonte comum de confusão para iniciantes. Ele também explica o uso de aliases (AS) para renomear tabelas e colunas para maior clareza.
A explicação evita terminologia excessivamente complexa e se concentra na função de cada cláusula. Isso facilita para os iniciantes entenderem como a consulta funciona.
Esse teste demonstra que o Llama 3.3:
Testamos o aplicativo com trechos de código em Python, JavaScript e SQL, gerando explicações em espanhol, francês e alemão. Em todos os testes:
Com esse teste, confirmamos que o aplicativo que criamos é versátil, confiável e eficaz para explicar códigos em diferentes linguagens de programação e idiomas naturais.
Parabéns! Você criou umassistente de explicação de código multilíngue totalmente funcional usando o Streamlit e o Llama 3.3 da Hugging Face.
Neste tutorial, você aprendeu:
Esse projeto é um excelente ponto de partida para explorar os recursos do Llama 3.3 em raciocínio de código, suporte multilíngue e conteúdo instrucional. Sinta-se à vontade para criar seu próprio aplicativo e continuar explorando os recursos avançados desse modelo!
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Nadia mhadhbi



