
Track
Associate AI Engineer for Data Scientists
40 hr
To get started, we’ll break this into a few steps. First, we’ll cover how to access Llama 3.3 using Hugging Face, set up your account, and get the necessary permissions. Then, we’ll create the project environment and install the required dependencies.
One way to access Llama 3.3 is via Hugging Face, one of the most popular platforms for hosting machine learning models. To use Llama 3.3 via Hugging Face’s Inference API, you’ll need:
With access to the model secured, let’s set up the app’s environment. First, we are going to create a folder for this project. Open your terminal, navigate to where you want to create your project folder, and run:
mkdir multilingual-code-explanation
cd multilingual-code-explanationThen, we’ll create a file called app.py to hold the code: touch app.pyNow, we create an environment, and we activate it:
python3 -m venv venv
source venv/bin/activate’Now that the environment is ready, let’s install the necessary libraries. Make sure that you are running Python 3.8+. In the terminal, run the following command to install Streamlit, Requests, and Hugging Face libraries:
pip install streamlit requests transformers huggingface-hubBy now, you should have:
Now that the setup is complete, we’re ready to build the app! In the next section, we’ll start coding the multilingual code explanation app step by step.
The backend communicates with the Hugging Face API to send the code snippet and receive the explanation.
First, we need to import the requests library. This library allows us to send HTTP requests to APIs. At the top of your app.py file, write:
import requestsTo interact with the Llama 3.3 API hosted on Hugging Face, you need:
HUGGINGFACE_API_KEY = "hf_your_api_key_here" # Replace with your actual API key
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Llama-3.3-70B-Instruct"
HEADERS = {"Authorization": f"Bearer {HUGGINGFACE_API_KEY}"}In the code above:
Now, we’ll write a function to send a request to the API. The function will:
def query_llama3(input_text, language):
# Create the prompt
prompt = (
f"Provide a simple explanation of this code in {language}:\n\n{input_text}\n"
f"Only output the explanation and nothing else. Make sure that the output is written in {language} and only in {language}"
)
# Payload for the API
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 500, "temperature": 0.3},
}
# Make the API request
response = requests.post(API_URL, headers=HEADERS, json=payload)
if response.status_code == 200:
result = response.json()
# Extract the response text
full_response = result[0]["generated_text"] if isinstance(result, list) else result.get("generated_text", "")
# Clean up: Remove the prompt itself from the response
clean_response = full_response.replace(prompt, "").strip()
# Further clean any leading colons or formatting
if ":" in clean_response:
clean_response = clean_response.split(":", 1)[-1].strip()
return clean_response or "No explanation available."
else:
return f"Error: {response.status_code} - {response.text}"The prompt tells Llama 3.3 to explain the code snippet in the desired language.
Disclaimer: I experimented with different prompts to find the one that produced the best output, so there was definitely an element of prompt engineering involved!
Next, the payload is defined. For the input, we specify that the prompt is sent to the model. In the parameters, max_new_tokens controls the response length, while temperature adjusts the output's creativity level.
The requests.post() function sends the data to Hugging Face. If the response is successful (status_code == 200), the generated text is extracted. If there’s an error, a descriptive message is returned.
Finally, there are steps to clean and format the output properly. This ensures it is presented neatly, which significantly improves the user experience.
The frontend is where users will interact with the app. Streamlit is a library that creates interactive web apps with just Python code and makes this process simple and intuitive. This is what we will use to build the frontend of our app. I really like Streamlit to build demos and POC!
At the top of your app.py file, add:
import streamlit as stWe will use set_page_config() to define the app title and layout. In the code below:
page_title: Sets the browser tab title.layout="wide": Allows the app to use the full screen width.st.set_page_config(page_title="Multilingual Code Explanation Assistant", layout="wide")To help users understand how to use the app, we are going to add instructions to the sidebar: In the code below:
st.sidebar.title(): Creates a title for the sidebar.st.sidebar.markdown(): Adds text with simple instructions.divider(): Adds a clean visual separation.st.sidebar.title("How to Use the App")
st.sidebar.markdown("""
1. Paste your code snippet into the input box.
2. Enter the language you want the explanation in (e.g., English, Spanish, French).
3. Click 'Generate Explanation' to see the results.
""")
st.sidebar.divider()
st.sidebar.markdown(
"""
<div style="text-align: center;color: grey;">
Made with ♡ by Ana
</div>
""",
unsafe_allow_html=True
)We are going to add the main title and subtitle to the page:
st.title("Multilingual Code Explanation Assistant")
st.markdown("### Powered by Llama 3.3 from Hugging Face 🦙")Now, to let users paste code and choose their preferred language, we need input fields. Because the code text is likely to be longer than the name of the language, we are choosing a text area for the code and a text input for the language:
text_area(): Creates a large box for pasting code.text_input(): Allows users to type in the language.code_snippet = st.text_area("Paste your code snippet here:", height=200)
preferred_language = st.text_input("Enter your preferred language for explanation (e.g., English, Spanish):")We now add a button to generate the explanation. If the user enters the code and the language and then clicks the Generate Explanation button, then an answer is generated.
if st.button("Generate Explanation"):
if code_snippet and preferred_language:
with st.spinner("Generating explanation... ⏳"):
explanation = query_llama3(code_snippet, preferred_language)
st.subheader("Generated Explanation:")
st.write(explanation)
else:
st.warning("⚠️ Please provide both the code snippet and preferred language.")
When the button is clicked, the app:
To wrap up, let’s add a footer:
st.markdown("---")
st.markdown("🧠 **Note**: This app uses Llama 3.3 from Hugging Face for multilingual code explanations.")It is time to run the app! To launch your app, run this code in the terminal:
streamlit run app.pyThe app will open in your browser, and you can start playing with it!

Now that we’ve built our multilingual code explanation app, it’s time to test how well the model works. In this section, we’ll use the app to process a couple of code snippets and evaluate the explanations generated in different languages.
For our first test, let’s start with a Python script that calculates the factorial of a number using recursion. Here’s the code we’ll use:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
num = 5
result = factorial(num)
print(f"The factorial of {num} is {result}")This script defines a recursive function factorial(n) that calculates the factorial of a given number. For num = 5, the function will compute 5×4×3×2×1, resulting in 120. The result is printed to the screen using the print() statement. Here is the output when we generate an explanation in Spanish:
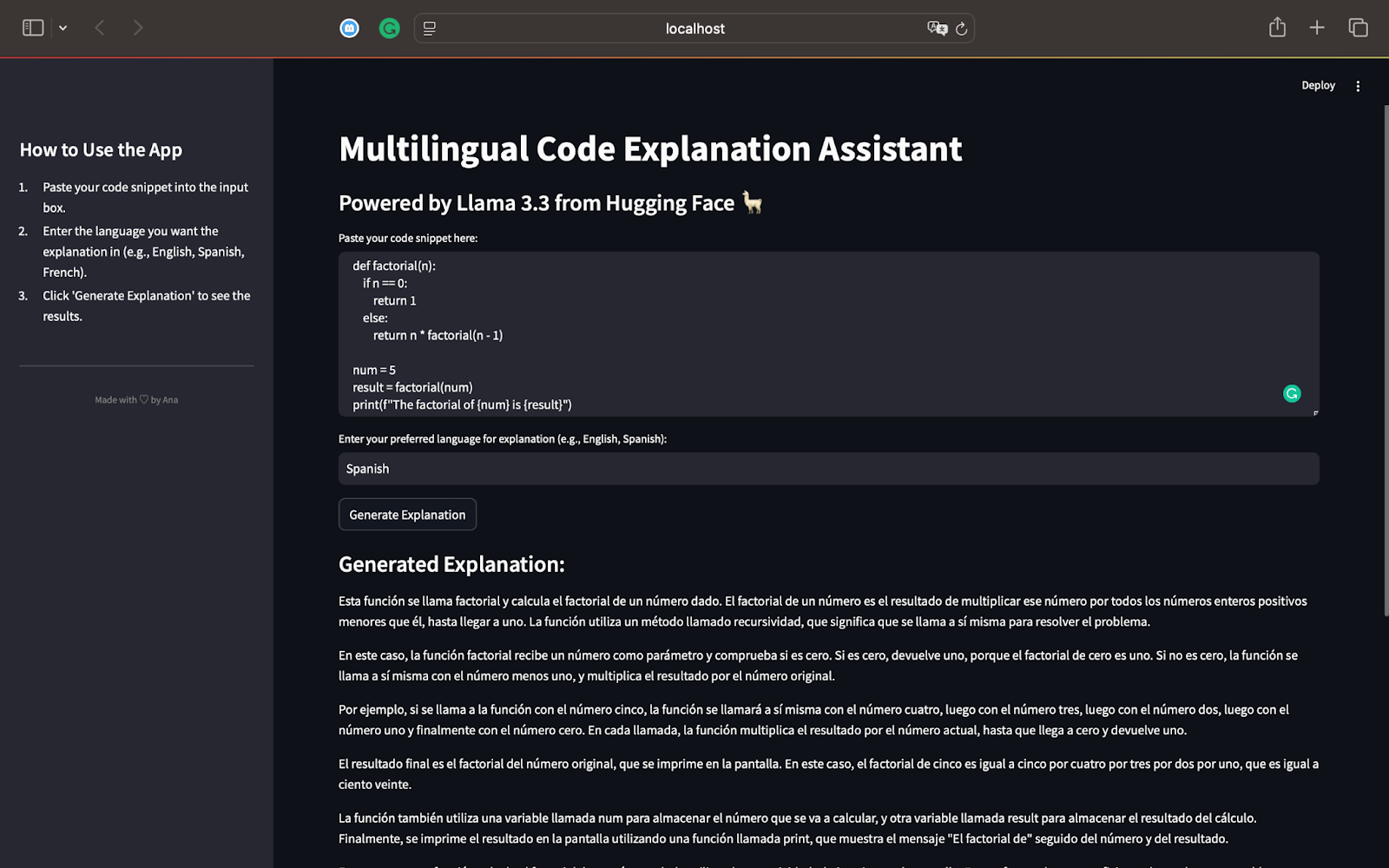

As a Spanish speaker, I can confirm that the explanation correctly identifies that the code calculates the factorial of a number using recursion. It walks through how the recursion works step by step, breaking it down into simple terms.
The model explains the recursion process and shows how the function calls itself with decreasing values of n until it reaches 0.
The explanation is entirely in Spanish, as requested, demonstrating Llama 3.3’s multilingual capabilities.
The use of simple phrases makes the concept of recursion easy to follow, even for readers unfamiliar with programming.
It summarizes and mentions how recursion works for other inputs like 3 and the importance of recursion as an efficient problem-solving concept in programming.
This first test highlights the power of Llama 3.3:
Now that we’ve tested a Python script, we can move on to other programming languages like JavaScript or SQL. This will help us further explore Llama 3.3’s capabilities across reasoning, coding, and multilingual support.
In this test, we’ll evaluate how well the multilingual code explanation app handles a JavaScript function and generates an explanation in French.
We use the following JavaScript code snippet in which I have intentionally chosen ambiguous variables to see how well the model handles this:
function x(a) {
if (a === 1) return 1;
return a * x(a - 1);
}
const y = 6;
const z = x(y);
console.log("The result is: " + z);This code snippet defines a recursive function x(a) that calculates the factorial of a given number a. The base condition checks if a === 1. If so, it returns 1. Otherwise, the function calls itself with a - 1 and multiplies the result by a. The constant y is set to 6, so the function x calculates 6×5×4×3×2×1. Fnally, the result is stored in the variable z and displayed using console.log. Here is the output and the translation in English:

Note: You can see that it looks like the response is suddenly cropped but it is because we have limited the output to 500 tokens!
After translating this, I concluded that the explanation correctly identifies that the function x(a) is recursive. It breaks down how recursion works, explaining the base case (a === 1) and the recursive case (a * x(a - 1)). The explanation explicitly shows how the function calculates the factorial of 6 and mentions the roles of y (the input value) and z (the result). It also notes how console.log is used to display the result.
The explanation is entirely in French, as requested. The technical terms like “récursive” (recursive), “factorielle” (factorial), and “produit” (product) are used correctly. And not just that, it identifies that this code calculates the factorial of a number in a recursive manner.
The explanation avoids overly technical jargon and simplifies recursion, making it accessible to readers new to programming.
This test demonstrates that Llama 3.3:
Now that we’ve tested the app with Python and JavaScript, let’s move on to testing it with a SQL query to further evaluate its multilingual and reasoning capabilities.
In this last test, we’ll evaluate how the multilingual code explanation App handles a SQL query and generates an explanation in German. Here’s the SQL snippet used:
SELECT a.id, SUM(b.value) AS total_amount
FROM table_x AS a
JOIN table_y AS b ON a.ref_id = b.ref
WHERE b.flag = 1
GROUP BY a.id
HAVING SUM(b.value) > 1000
ORDER BY total_amount DESC;This query selects the id column and calculates the total value (SUM(b.value)) for each id. It reads data from two tables: table_x (aliased as a) and table_y (aliased as b). Then, uses a JOIN condition to connect rows where a.ref_id = b.ref. It filters rows where b.flag = 1 and groups the data by a.id. The HAVING clause filters the groups to include only those where the sum of b.value is greater than 1000. Finally, it orders the results by total_amount in descending order.
After hitting the generate explanation button, this is what we get:

The generated explanation is concise, accurate, and well-structured. Each key SQL clause (SELECT, FROM, JOIN, WHERE, GROUP BY, HAVING, and ORDER BY) is clearly explained. Also, the description matches the order of execution in SQL, which helps readers follow the query logic step by step.
The explanation is entirely in German, as requested.
Key SQL terms (e.g., "filtert", "gruppiert", "sortiert") are used accurately in context. The explanation identifies that HAVING is used to filter grouped results, which is a common source of confusion for beginners. It also explains the use of aliases (AS) to rename tables and columns for clarity.
The explanation avoids overly complex terminology and focuses on the function of each clause. This makes it easy for beginners to understand how the query works.
This test demonstrates that Llama 3.3:
We’ve tested the app with code snippets in Python, JavaScript, and SQL, generating explanations in Spanish, French, and German. In every test:
With this test, we’ve confirmed that the app we have built is versatile, reliable, and effective for explaining code across different programming languages and natural languages.
Congratulations! You’ve built a fully functional multilingual code explanation assistant using Streamlit and Llama 3.3 from Hugging Face.
In this tutorial, you learned:
This project is a great starting point for exploring Llama 3.3’s capabilities in code reasoning, multilingual support, and instructional content. Feel free to create your own app to continue exploring this model's powerful features!
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
Tutorial
Aashi Dutt
Tutorial
Hesam Sheikh Hassani
Tutorial
François Aubry
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev


