
Kurs
Einführung in Deep Learning mit Python
4 Std.
263.6K
In diesem Lernprogramm lernst du, wie du ein Zeitreihenmodell mit dem Namen Long Short-Term Memory verwendest. Wie du später sehen wirst, sind LSTM-Modelle besonders leistungsstark, wenn es darum geht, das Langzeitgedächtnis zu behalten. In diesem Lernprogramm behandelst du die folgenden Themen:
Wenn du mit Deep Learning oder neuronalen Netzen nicht vertraut bist, solltest du dir unseren Kurs Deep Learning in Python ansehen. Er deckt die Grundlagen ab und zeigt dir, wie du selbst ein neuronales Netzwerk in Keras erstellen kannst. Dieses Paket unterscheidet sich von TensorFlow, das in diesem Lernprogramm verwendet wird, aber die Idee ist die gleiche.
Du möchtest die Aktienkurse richtig modellieren, damit du als Aktienkäufer vernünftig entscheiden kannst, wann du Aktien kaufst und wann du sie verkaufst, um einen Gewinn zu erzielen. An dieser Stelle kommt die Zeitreihenmodellierung ins Spiel. Du brauchst gute maschinelle Lernmodelle, die sich den Verlauf einer Datenfolge ansehen und korrekt vorhersagen können, wie die zukünftigen Elemente der Folge aussehen werden.
Warnung: Die Börsenkurse sind sehr unberechenbar und volatil. Das bedeutet, dass es keine konsistenten Muster in den Daten gibt, die es dir erlauben, die Aktienkurse im Laufe der Zeit nahezu perfekt zu modellieren. Glaube nicht mir, sondern dem Wirtschaftswissenschaftler Burton Malkiel von der Princeton University, der in seinem Buch "A Random Walk Down Wall Street" aus dem Jahr 1973 argumentiert, dass, wenn der Markt wirklich effizient ist und ein Aktienkurs alle Faktoren sofort widerspiegelt, sobald sie veröffentlicht werden, ein Affe mit verbundenen Augen, der Darts auf eine Zeitungsnotiz wirft, genauso gut abschneiden sollte wie jeder Anlageprofi.
Aber wir sollten nicht glauben, dass dies nur ein stochastischer oder zufälliger Prozess ist und dass es keine Hoffnung für das maschinelle Lernen gibt. Mal sehen, ob du die Daten wenigstens so modellieren kannst, dass die Vorhersagen, die du machst, mit dem tatsächlichen Verhalten der Daten übereinstimmen. Mit anderen Worten: Du brauchst nicht die genauen Aktienwerte der Zukunft, sondern die Kursbewegungen (d.h. ob sie in naher Zukunft steigen oder fallen werden).
# Make sure that you have all these libaries available to run the code successfully
from pandas_datareader import data
import matplotlib.pyplot as plt
import pandas as pd
import datetime as dt
import urllib.request, json
import os
import numpy as np
import tensorflow as tf # This code has been tested with TensorFlow 1.6
from sklearn.preprocessing import MinMaxScalerDu wirst Daten aus den folgenden Quellen verwenden:
Alpha Vantage Stock API. Bevor du jedoch loslegst, brauchst du einen API-Schlüssel, den du hier kostenlos erhalten kannst. Danach kannst du diesen Schlüssel der Variablen api_key zuweisen. In diesem Tutorial werden 20 Jahre historische Daten für die American Airlines-Aktie abgerufen. Als optionale Lektüre kannst du diesen Aktien-API-Starter-Leitfaden lesen, der die besten Praktiken für die Arbeit mit historischen Marktdaten enthält.
Verwende die Daten von dieser Seite. Kopiere den Stocks-Ordner aus der Zip-Datei in den Home-Ordner deines Projekts.
Aktienkurse gibt es in vielen verschiedenen Varianten. Sie sind,
Zuerst lädst du die Daten aus Alpha Vantage. Da du die Börsenkurse von American Airlines für deine Vorhersagen nutzen wirst, stellst du den Ticker auf "AAL". Außerdem definierst du eine url_string, die eine JSON-Datei mit allen Börsendaten für American Airlines der letzten 20 Jahre zurückgibt, und eine file_to_save, die die Datei ist, in der du die Daten speicherst. Du verwendest die Variable ticker, die du zuvor definiert hast, um diese Datei zu benennen.
Als Nächstes gibst du eine Bedingung an: Wenn du die Daten noch nicht gespeichert hast, holst du dir die Daten von der URL, die du in url_string festgelegt hast. Du speicherst die Werte für Datum, Tiefst-, Höchst-, Volumen-, Schluss- und Eröffnungswert in einem Pandas DataFrame df und speicherst ihn unter file_to_save. Wenn die Daten jedoch bereits vorhanden sind, lädst du sie einfach aus der CSV-Datei.
Die Daten, die du auf Kaggle findest, sind eine Sammlung von CSV-Dateien. Du musst sie nicht vorverarbeiten und kannst sie direkt in ein Pandas DataFrame laden.
data_source = 'kaggle' # alphavantage or kaggle
if data_source == 'alphavantage':
# ====================== Loading Data from Alpha Vantage ==================================
api_key = '<your API key>'
# American Airlines stock market prices
ticker = "AAL"
# JSON file with all the stock market data for AAL from the last 20 years
url_string = "https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol=%s&outputsize=full&apikey=%s"%(ticker,api_key)
# Save data to this file
file_to_save = 'stock_market_data-%s.csv'%ticker
# If you haven't already saved data,
# Go ahead and grab the data from the url
# And store date, low, high, volume, close, open values to a Pandas DataFrame
if not os.path.exists(file_to_save):
with urllib.request.urlopen(url_string) as url:
data = json.loads(url.read().decode())
# extract stock market data
data = data['Time Series (Daily)']
df = pd.DataFrame(columns=['Date','Low','High','Close','Open'])
for k,v in data.items():
date = dt.datetime.strptime(k, '%Y-%m-%d')
data_row = [date.date(),float(v['3. low']),float(v['2. high']),
float(v['4. close']),float(v['1. open'])]
df.loc[-1,:] = data_row
df.index = df.index + 1
print('Data saved to : %s'%file_to_save)
df.to_csv(file_to_save)
# If the data is already there, just load it from the CSV
else:
print('File already exists. Loading data from CSV')
df = pd.read_csv(file_to_save)
else:
# ====================== Loading Data from Kaggle ==================================
# You will be using HP's data. Feel free to experiment with other data.
# But while doing so, be careful to have a large enough dataset and also pay attention to the data normalization
df = pd.read_csv(os.path.join('Stocks','hpq.us.txt'),delimiter=',',usecols=['Date','Open','High','Low','Close'])
print('Loaded data from the Kaggle repository')
Data saved to : stock_market_data-AAL.csv
Hier druckst du die Daten, die du gesammelt hast, in den DataFrame. Du solltest auch darauf achten, dass die Daten nach Datum sortiert sind, denn die Reihenfolge der Daten ist bei der Zeitreihenmodellierung entscheidend.
# Sort DataFrame by date
df = df.sort_values('Date')
# Double check the result
df.head()
| Datum | Öffnen Sie | Hoch | Niedrig | Schließen | |
|---|---|---|---|---|---|
| 0 | 1970-01-02 | 0.30627 | 0.30627 | 0.30627 | 0.30627 |
| 1 | 1970-01-05 | 0.30627 | 0.31768 | 0.30627 | 0.31385 |
| 2 | 1970-01-06 | 0.31385 | 0.31385 | 0.30996 | 0.30996 |
| 3 | 1970-01-07 | 0.31385 | 0.31385 | 0.31385 | 0.31385 |
| 4 | 1970-01-08 | 0.31385 | 0.31768 | 0.31385 | 0.31385 |
Jetzt wollen wir mal sehen, welche Daten du hast. Du willst Daten mit verschiedenen Mustern, die im Laufe der Zeit auftreten.
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),(df['Low']+df['High'])/2.0)
plt.xticks(range(0,df.shape[0],500),df['Date'].loc[::500],rotation=45)
plt.xlabel('Date',fontsize=18)
plt.ylabel('Mid Price',fontsize=18)
plt.show()
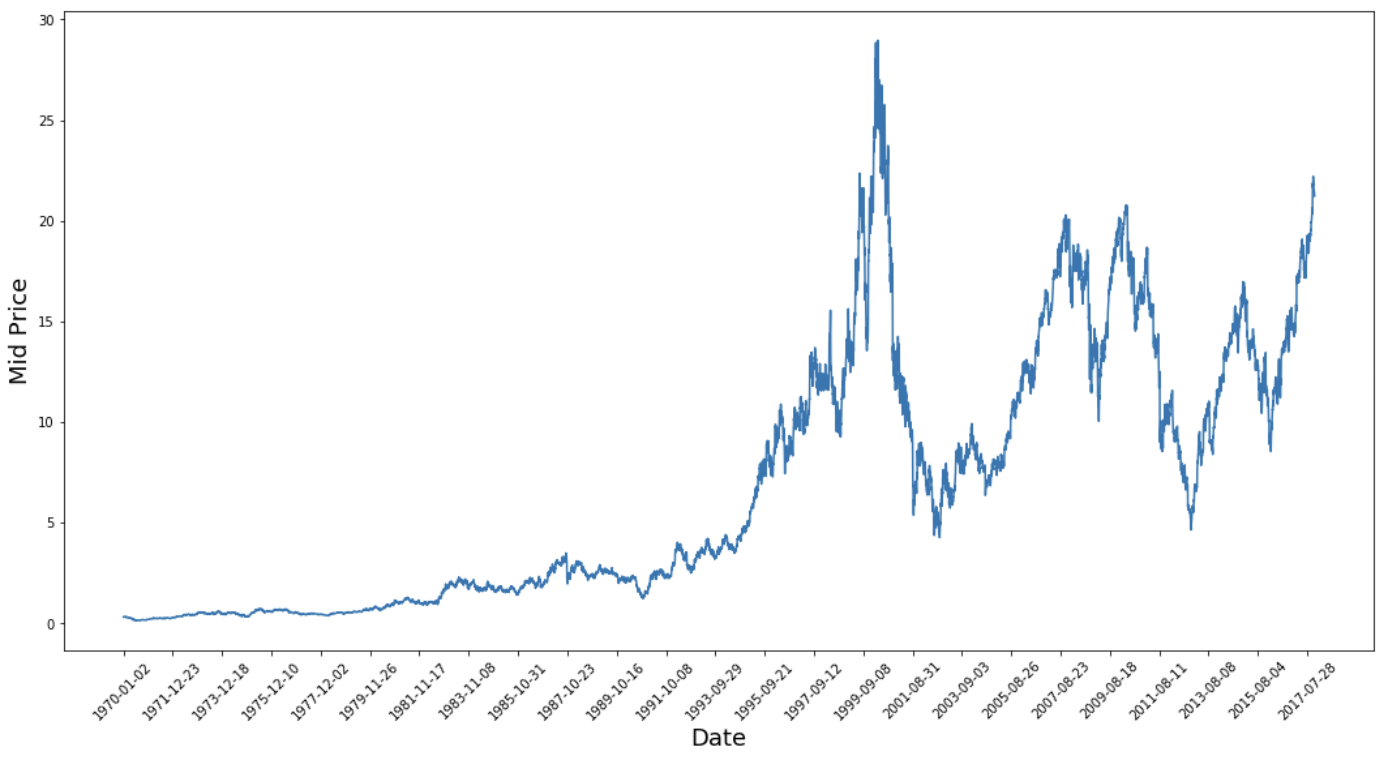
Diese Grafik sagt schon eine Menge aus. Der besondere Grund dafür, dass ich dieses Unternehmen anderen vorgezogen habe, ist, dass es im Laufe der Zeit mit unterschiedlichen Kursverläufen aufwartet. Das macht das Lernen robuster und gibt dir die Möglichkeit zu testen, wie gut die Vorhersagen für eine Vielzahl von Situationen sind.
Außerdem fällt auf, dass die Werte in der Nähe von 2017 viel höher sind und stärker schwanken als die Werte in der Nähe der 1970er Jahre. Deshalb musst du sicherstellen, dass sich die Daten im gesamten Zeitrahmen in ähnlichen Wertebereichen verhalten. Darum kümmerst du dich in der Phase der Datennormalisierung.
Du verwendest den mittleren Preis, der aus dem Durchschnitt der höchsten und niedrigsten aufgezeichneten Preise eines Tages berechnet wird.
# First calculate the mid prices from the highest and lowest
high_prices = df.loc[:,'High'].as_matrix()
low_prices = df.loc[:,'Low'].as_matrix()
mid_prices = (high_prices+low_prices)/2.0
Jetzt kannst du die Trainingsdaten und die Testdaten aufteilen. Die Trainingsdaten sind die ersten 11.000 Datenpunkte der Zeitreihe, der Rest sind Testdaten.
train_data = mid_prices[:11000]
test_data = mid_prices[11000:]
Jetzt musst du einen Skalierer definieren, um die Daten zu normalisieren. MinMaxScalar skaliert alle Daten so, dass sie im Bereich von 0 und 1 liegen. Du kannst die Trainings- und Testdaten auch so umformen, dass sie die Form [data_size, num_features] haben.
# Scale the data to be between 0 and 1
# When scaling remember! You normalize both test and train data with respect to training data
# Because you are not supposed to have access to test data
scaler = MinMaxScaler()
train_data = train_data.reshape(-1,1)
test_data = test_data.reshape(-1,1)
Aufgrund deiner früheren Beobachtung, dass verschiedene Zeiträume der Daten unterschiedliche Wertebereiche haben, normalisierst du die Daten, indem du die gesamte Reihe in Fenster aufteilst. Wenn du das nicht tust, liegen die früheren Daten nahe bei 0 und tragen nicht viel zum Lernprozess bei. Hier wählst du eine Fenstergröße von 2500.
Tipp: Achte bei der Wahl der Fenstergröße darauf, dass sie nicht zu klein ist. Wenn du eine fensterbasierte Normalisierung durchführst, kann es am Ende jedes Fensters zu einem Bruch kommen, da jedes Fenster unabhängig voneinander normalisiert wird.
In diesem Beispiel sind 4 Datenpunkte davon betroffen. Da du aber 11.000 Datenpunkte hast, werden 4 Punkte kein Problem darstellen.
# Train the Scaler with training data and smooth data
smoothing_window_size = 2500
for di in range(0,10000,smoothing_window_size):
scaler.fit(train_data[di:di+smoothing_window_size,:])
train_data[di:di+smoothing_window_size,:] = scaler.transform(train_data[di:di+smoothing_window_size,:])
# You normalize the last bit of remaining data
scaler.fit(train_data[di+smoothing_window_size:,:])
train_data[di+smoothing_window_size:,:] = scaler.transform(train_data[di+smoothing_window_size:,:])
Die Daten wieder in die Form von [data_size]
# Reshape both train and test data
train_data = train_data.reshape(-1)
# Normalize test data
test_data = scaler.transform(test_data).reshape(-1)
Du kannst die Daten jetzt mit dem exponentiellen gleitenden Durchschnitt glätten. Dies hilft, die den Aktienkursen innewohnenden Unregelmäßigkeiten zu beseitigen und eine glattere Kurve zu erstellen.
Beachte, dass du nur Trainingsdaten glätten solltest.
# Now perform exponential moving average smoothing
# So the data will have a smoother curve than the original ragged data
EMA = 0.0
gamma = 0.1
for ti in range(11000):
EMA = gamma*train_data[ti] + (1-gamma)*EMA
train_data[ti] = EMA
# Used for visualization and test purposes
all_mid_data = np.concatenate([train_data,test_data],axis=0)
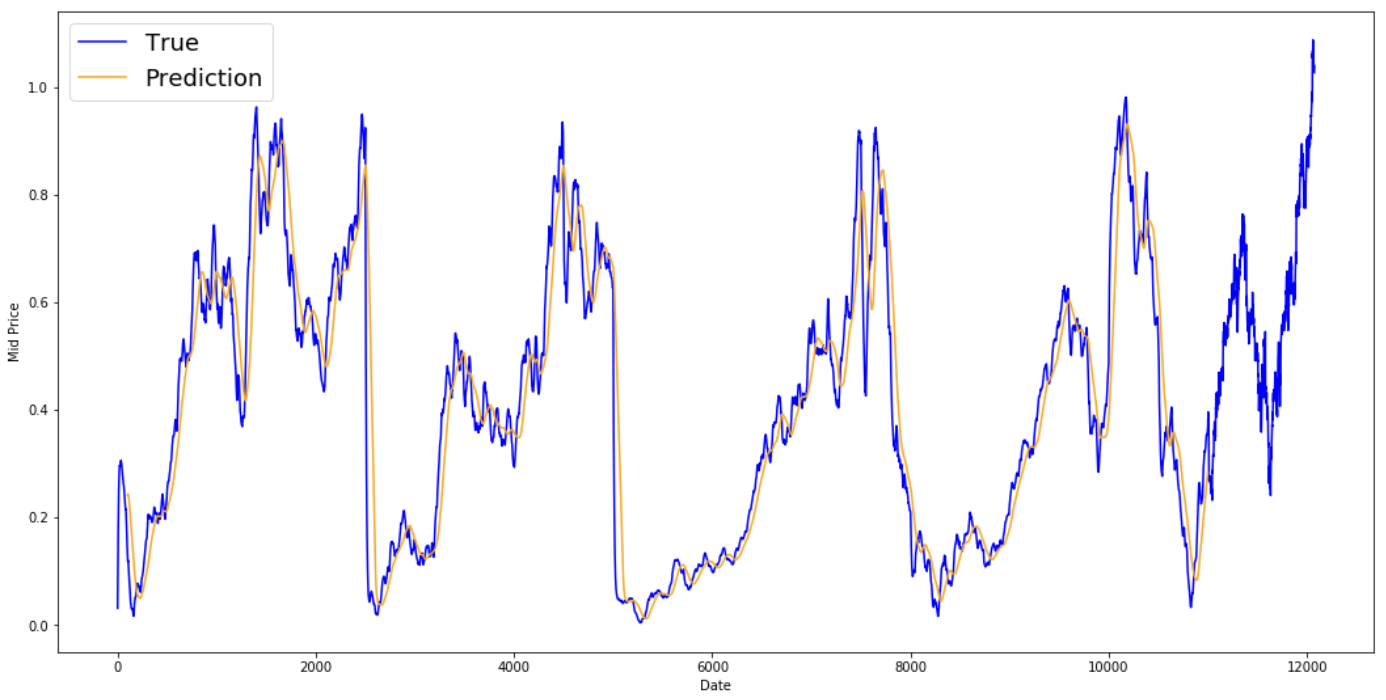
Mittelwertbildungsmechanismen ermöglichen es dir, Vorhersagen zu treffen (oft einen einmaligen Schritt voraus), indem du den zukünftigen Aktienkurs als Durchschnitt der zuvor beobachteten Aktienkurse darstellst. Wenn du dies für mehr als einen Zeitschritt tust, kann das zu ziemlich schlechten Ergebnissen führen. Du wirst dir zwei Mittelungstechniken ansehen: die untere Standard-Mittelung und den exponentiellen gleitenden Durchschnitt. Du wirst die Ergebnisse der beiden Algorithmen sowohl qualitativ (Sichtprüfung) als auch quantitativ (mittlerer quadratischer Fehler) bewerten.
Der mittlere quadratische Fehler (Mean Squared Error, MSE) kann berechnet werden, indem man den quadratischen Fehler zwischen dem wahren Wert bei einem Schritt vorwärts und dem vorhergesagten Wert nimmt und den Durchschnitt über alle Vorhersagen bildet.
Du kannst die Schwierigkeit dieses Problems verstehen, wenn du zunächst versuchst, es als Durchschnittsberechnungsproblem zu betrachten. Zunächst versuchst du, die zukünftigen Börsenkurse (z. B. xt+1 ) als Durchschnitt der zuvor beobachteten Börsenkurse innerhalb eines Fensters fester Größe (z. B. xt-N, ..., xt) (z. B. die letzten 100 Tage) vorherzusagen. Danach versuchst du eine etwas ausgefallenere Methode, den "exponentiellen gleitenden Durchschnitt", und schaust, wie gut das funktioniert. Dann gehst du zum "heiligen Gral" der Zeitreihenvorhersage über: Modelle für das Kurzzeitgedächtnis.
Zuerst wirst du sehen, wie die normale Mittelwertbildung funktioniert. Das heißt, du sagst,
Mit anderen Worten: Du sagst, die Vorhersage zu $t+1$ ist der Durchschnittswert aller Aktienkurse, die du innerhalb eines Zeitfensters von $t$ bis $t-N$ beobachtet hast.
window_size = 100
N = train_data.size
std_avg_predictions = []
std_avg_x = []
mse_errors = []
for pred_idx in range(window_size,N):
if pred_idx >= N:
date = dt.datetime.strptime(k, '%Y-%m-%d').date() + dt.timedelta(days=1)
else:
date = df.loc[pred_idx,'Date']
std_avg_predictions.append(np.mean(train_data[pred_idx-window_size:pred_idx]))
mse_errors.append((std_avg_predictions[-1]-train_data[pred_idx])**2)
std_avg_x.append(date)
print('MSE error for standard averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for standard averaging: 0.00418
Sieh dir die gemittelten Ergebnisse unten an. Sie folgen dem tatsächlichen Verhalten der Aktie recht genau. Als Nächstes wirst du eine genauere einstufige Vorhersagemethode untersuchen.
plt.figure(figsize = (18,9)) plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True') plt.plot(range(window_size,N),std_avg_predictions,color='orange',label='Prediction') #plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45) plt.xlabel('Date') plt.ylabel('Mid Price') plt.legend(fontsize=18) plt.show()
Was sagen die obigen Diagramme (und der MSE) aus?
Es scheint, dass das Modell für sehr kurze Vorhersagen (einen Tag im Voraus) nicht allzu schlecht ist. Dieses Verhalten ist sinnvoll, da sich die Aktienkurse nicht über Nacht von 0 auf 100 ändern. Als Nächstes wirst du dir eine ausgefeiltere Mittelungstechnik ansehen, den exponentiellen gleitenden Durchschnitt.
Du hast vielleicht schon einige Artikel im Internet gesehen, in denen sehr komplexe Modelle verwendet werden und die fast genau das Verhalten des Aktienmarktes vorhersagen. Aber pass auf! Das sind nur optische Täuschungen und nicht, weil du etwas Nützliches gelernt hast. Weiter unten wirst du sehen, wie du dieses Verhalten mit einer einfachen Mittelwertbildung nachbilden kannst.
Bei der Methode des exponentiellen gleitenden Durchschnitts berechnest du $x_{t+1}$ wie folgt,
Die obige Gleichung berechnet im Grunde den exponentiell gleitenden Durchschnitt aus $t+1$ Zeitschritten und verwendet diesen als Vorhersage für einen Schritt voraus. $\gamma$ bestimmt, wie hoch der Beitrag der letzten Vorhersage zum EMA ist. Ein $\gamma=0.1$ bringt zum Beispiel nur 10% des aktuellen Wertes in den EMA. Da du nur einen sehr kleinen Teil der jüngsten Werte nimmst, kannst du viel ältere Werte, die du sehr früh im Durchschnitt gesehen hast, erhalten. Sieh dir an, wie gut das aussieht, wenn man es benutzt, um einen Schritt vorauszusagen.
window_size = 100
N = train_data.size
run_avg_predictions = []
run_avg_x = []
mse_errors = []
running_mean = 0.0
run_avg_predictions.append(running_mean)
decay = 0.5
for pred_idx in range(1,N):
running_mean = running_mean*decay + (1.0-decay)*train_data[pred_idx-1]
run_avg_predictions.append(running_mean)
mse_errors.append((run_avg_predictions[-1]-train_data[pred_idx])**2)
run_avg_x.append(date)
print('MSE error for EMA averaging: %.5f'%(0.5*np.mean(mse_errors)))
MSE error for EMA averaging: 0.00003
plt.figure(figsize = (18,9))
plt.plot(range(df.shape[0]),all_mid_data,color='b',label='True')
plt.plot(range(0,N),run_avg_predictions,color='orange', label='Prediction')
#plt.xticks(range(0,df.shape[0],50),df['Date'].loc[::50],rotation=45)
plt.xlabel('Date')
plt.ylabel('Mid Price')
plt.legend(fontsize=18)
plt.show()
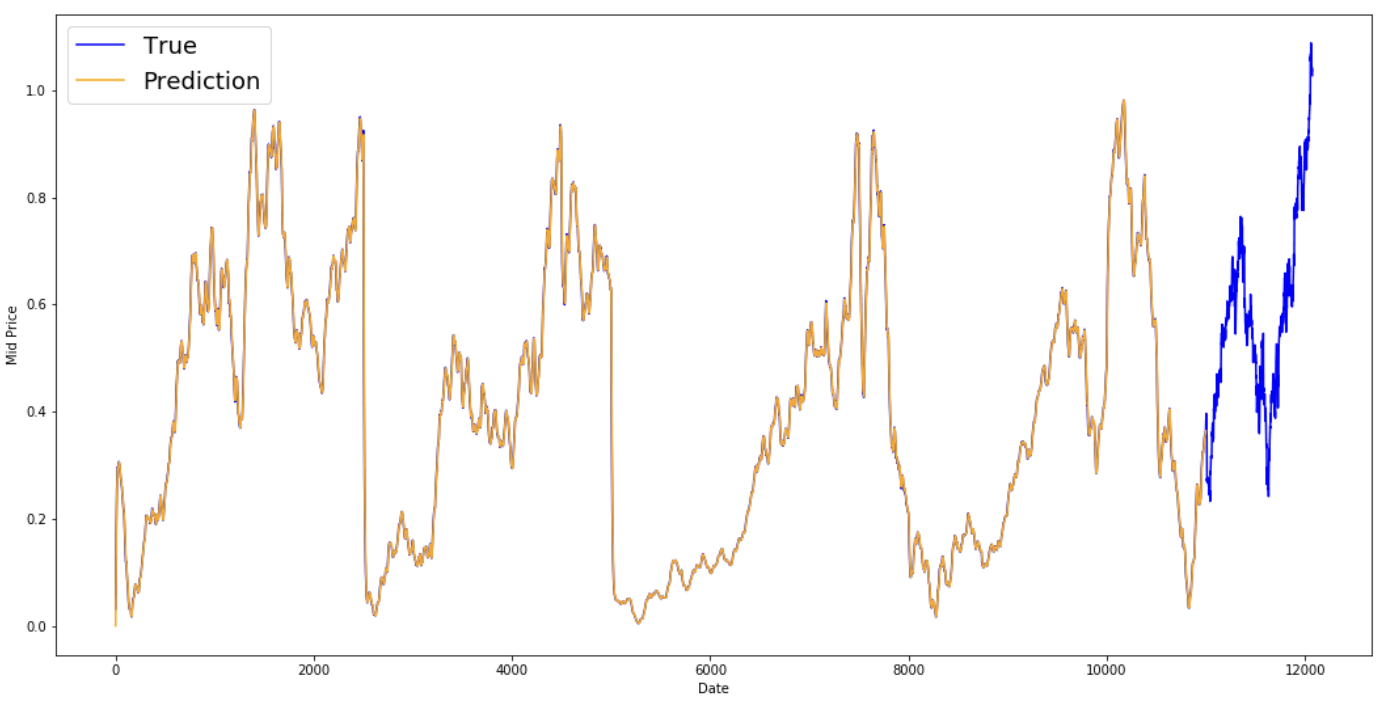
Du siehst, dass es eine perfekte Linie ist, die der True Verteilung folgt (und durch den sehr niedrigen MSE gerechtfertigt ist). Praktisch gesehen kannst du mit dem Börsenwert des nächsten Tages nicht viel anfangen. Ich persönlich möchte nicht den genauen Börsenkurs für den nächsten Tag wissen, sondern ob die Börsenkurse in den nächsten 30 Tagen steigen oder fallen werden. Wenn du das versuchst, wirst du die Unfähigkeit der EMA-Methode aufdecken.
Du wirst nun versuchen, Vorhersagen in Fenstern zu treffen (z.B. für die nächsten 2 Tage, statt nur für den nächsten Tag). Dann wirst du merken, wie falsch die EMA laufen kann. Hier ist ein Beispiel:
Um die Dinge zu konkretisieren, nehmen wir Werte an, sagen wir $x_t=0.4$, $EMA=0.5$ und $\gamma = 0.5$.
Egal, wie viele Schritte du in der Zukunft vorhersagst, du wirst immer die gleiche Antwort für alle zukünftigen Vorhersageschritte erhalten.
Eine Lösung, die dir nützliche Informationen liefert, ist ein Blick auf momentumbasierte Algorithmen. Sie machen Vorhersagen, die darauf basieren, ob die Werte in der jüngsten Vergangenheit gestiegen oder gefallen sind (nicht die genauen Werte). Sie werden zum Beispiel sagen, dass der Preis am nächsten Tag wahrscheinlich niedriger sein wird, wenn die Preise in den letzten Tagen gefallen sind, was vernünftig klingt. Du wirst jedoch ein komplexeres Modell verwenden: ein LSTM-Modell.
Diese Modelle haben den Bereich der Zeitreihenvorhersage im Sturm erobert, weil sie so gut darin sind, Zeitreihendaten zu modellieren. Du wirst sehen, ob sich in den Daten tatsächlich Muster verstecken, die du ausnutzen kannst.
Modelle für das Langzeitgedächtnis sind extrem leistungsfähige Zeitreihenmodelle. Sie können eine beliebige Anzahl von Schritten in die Zukunft vorhersagen. Ein LSTM-Modul (oder eine Zelle) hat 5 wesentliche Komponenten, die es ihm ermöglichen, sowohl langfristige als auch kurzfristige Daten zu modellieren.
Eine Zelle ist unten abgebildet:
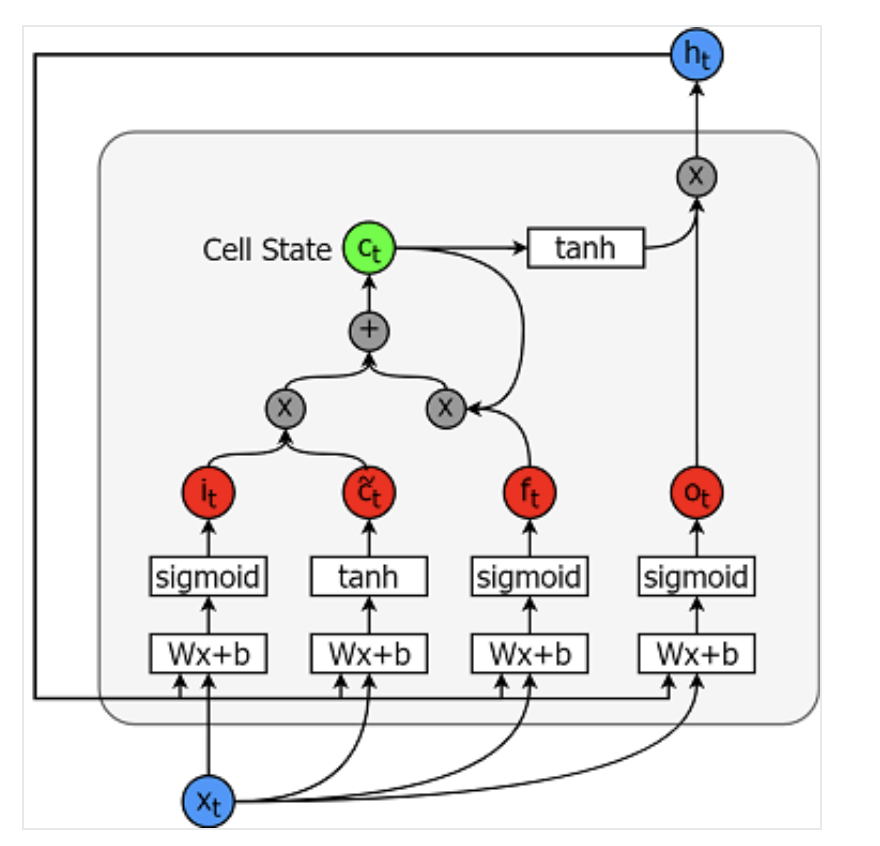
Die Gleichungen zur Berechnung jeder dieser Einheiten lauten wie folgt.
Für ein besseres (technischeres) Verständnis von LSTMs kannst du diesen Artikel lesen.
TensorFlow bietet eine schöne API (genannt RNN API) für die Implementierung von Zeitreihenmodellen. Du wirst sie für deine Umsetzungen verwenden.
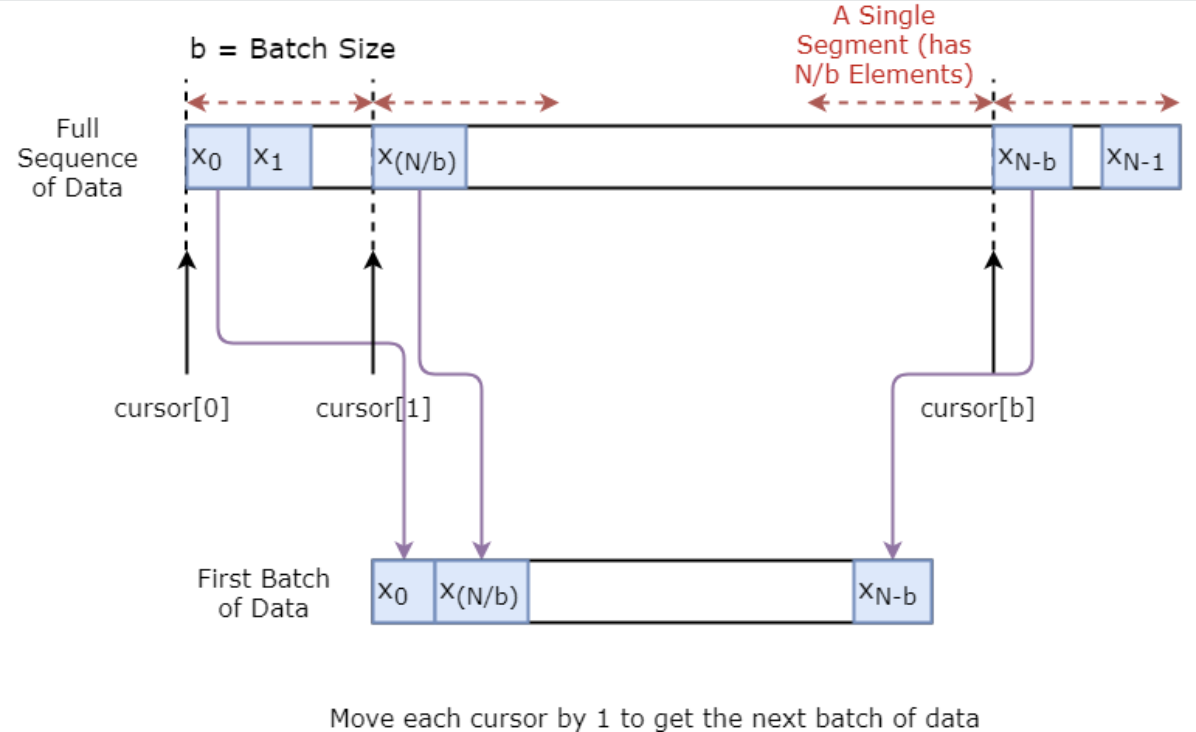
Du wirst zunächst einen Datengenerator implementieren, um dein Modell zu trainieren. Dieser Datengenerator hat eine Methode namens .unroll_batches(...), die einen Satz von num_unrollings Stapeln von Eingabedaten ausgibt, die nacheinander erhalten werden, wobei ein Stapel von Daten die Größe [batch_size, 1] hat. Dann hat jeder Stapel von Eingabedaten einen entsprechenden Ausgabestapel von Daten.
Wenn du zum Beispiel num_unrollings=3 und batch_size=4 aufrufst, könnte es so aussehen,
Um dein Modell robust zu machen, wirst du außerdem die Ausgabe für $x\_t$ nicht immer $x\_{t+1}$ machen. Vielmehr wirst du eine Zufallsstichprobe aus der Menge $x\_{t+1},x\_{t+2},\ldots,x_{t+N}$ ziehen, wobei $N$ eine kleine Fenstergröße ist.
Hier gehst du von der folgenden Annahme aus:
Ich persönlich denke, dass dies eine vernünftige Annahme für die Vorhersage von Aktienbewegungen ist.
Unten siehst du, wie ein Datenstapel visuell erstellt wird.
class DataGeneratorSeq(object):
def __init__(self,prices,batch_size,num_unroll):
self._prices = prices
self._prices_length = len(self._prices) - num_unroll
self._batch_size = batch_size
self._num_unroll = num_unroll
self._segments = self._prices_length //self._batch_size
self._cursor = [offset * self._segments for offset in range(self._batch_size)]
def next_batch(self):
batch_data = np.zeros((self._batch_size),dtype=np.float32)
batch_labels = np.zeros((self._batch_size),dtype=np.float32)
for b in range(self._batch_size):
if self._cursor[b]+1>=self._prices_length:
#self._cursor[b] = b * self._segments
self._cursor[b] = np.random.randint(0,(b+1)*self._segments)
batch_data[b] = self._prices[self._cursor[b]]
batch_labels[b]= self._prices[self._cursor[b]+np.random.randint(0,5)]
self._cursor[b] = (self._cursor[b]+1)%self._prices_length
return batch_data,batch_labels
def unroll_batches(self):
unroll_data,unroll_labels = [],[]
init_data, init_label = None,None
for ui in range(self._num_unroll):
data, labels = self.next_batch()
unroll_data.append(data)
unroll_labels.append(labels)
return unroll_data, unroll_labels
def reset_indices(self):
for b in range(self._batch_size):
self._cursor[b] = np.random.randint(0,min((b+1)*self._segments,self._prices_length-1))
dg = DataGeneratorSeq(train_data,5,5)
u_data, u_labels = dg.unroll_batches()
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
print('\n\nUnrolled index %d'%ui)
dat_ind = dat
lbl_ind = lbl
print('\tInputs: ',dat )
print('\n\tOutput:',lbl)
Unrolled index 0
Inputs: [0.03143791 0.6904868 0.82829314 0.32585657 0.11600105]
Output: [0.08698314 0.68685144 0.8329321 0.33355275 0.11785509]
Unrolled index 1
Inputs: [0.06067836 0.6890754 0.8325337 0.32857886 0.11785509]
Output: [0.15261841 0.68685144 0.8325337 0.33421066 0.12106793]
Unrolled index 2
Inputs: [0.08698314 0.68685144 0.8329321 0.33078218 0.11946969]
Output: [0.11098009 0.6848606 0.83387965 0.33421066 0.12106793]
Unrolled index 3
Inputs: [0.11098009 0.6858036 0.83294916 0.33219692 0.12106793]
Output: [0.132895 0.6836884 0.83294916 0.33219692 0.12288672]
Unrolled index 4
Inputs: [0.132895 0.6848606 0.833369 0.33355275 0.12158521]
Output: [0.15261841 0.6836884 0.83383167 0.33355275 0.12230608]
In diesem Abschnitt definierst du verschiedene Hyperparameter. D ist die Dimensionalität der Eingabe. Es ist ganz einfach, denn du nimmst den vorherigen Aktienkurs als Eingabe und sagst den nächsten voraus, der 1 sein sollte.
Dann gibt es noch num_unrollings, das ist ein Hyperparameter, der sich auf die Backpropagation durch Zeit (BPTT) bezieht, die zur Optimierung des LSTM-Modells verwendet wird. Dies gibt an, wie viele kontinuierliche Zeitschritte du für einen einzelnen Optimierungsschritt berücksichtigst. Du kannst dir das so vorstellen: Anstatt das Modell mit einem einzigen Zeitschritt zu optimieren, optimierst du das Netzwerk mit num_unrollings Zeitschritten. Je größer, desto besser.
Dann hast du die batch_size. Die Stapelgröße gibt an, wie viele Datenproben du in einem einzigen Zeitschritt berücksichtigst.
Als Nächstes legst du num_nodes fest, das die Anzahl der versteckten Neuronen in jeder Zelle angibt. Du kannst sehen, dass es in diesem Beispiel drei Schichten von LSTMs gibt.
D = 1 # Dimensionality of the data. Since your data is 1-D this would be 1
num_unrollings = 50 # Number of time steps you look into the future.
batch_size = 500 # Number of samples in a batch
num_nodes = [200,200,150] # Number of hidden nodes in each layer of the deep LSTM stack we're using
n_layers = len(num_nodes) # number of layers
dropout = 0.2 # dropout amount
tf.reset_default_graph() # This is important in case you run this multiple times
Als Nächstes definierst du Platzhalter für Trainingsinputs und Labels. Das ist ganz einfach, denn du hast eine Liste von Eingabeplatzhaltern, die jeweils einen einzelnen Datenstapel enthalten. Und die Liste hat num_unrollings Platzhalter, die auf einmal für einen einzigen Optimierungsschritt verwendet werden.
# Input data.
train_inputs, train_outputs = [],[]
# You unroll the input over time defining placeholders for each time step
for ui in range(num_unrollings):
train_inputs.append(tf.placeholder(tf.float32, shape=[batch_size,D],name='train_inputs_%d'%ui))
train_outputs.append(tf.placeholder(tf.float32, shape=[batch_size,1], name = 'train_outputs_%d'%ui))
Du hast drei Schichten von LSTMs und eine lineare Regressionsschicht, bezeichnet mit w und b, die die Ausgabe der letzten Long Short-Term Memory-Zelle nimmt und die Vorhersage für den nächsten Zeitschritt ausgibt. Du kannst die MultiRNNCell in TensorFlow verwenden, um die drei LSTMCell Objekte zu kapseln, die du erstellt hast. Außerdem kannst du die Dropout-implementierten LSTM-Zellen haben, da sie die Leistung verbessern und das Overfitting reduzieren.
lstm_cells = [
tf.contrib.rnn.LSTMCell(num_units=num_nodes[li],
state_is_tuple=True,
initializer= tf.contrib.layers.xavier_initializer()
)
for li in range(n_layers)]
drop_lstm_cells = [tf.contrib.rnn.DropoutWrapper(
lstm, input_keep_prob=1.0,output_keep_prob=1.0-dropout, state_keep_prob=1.0-dropout
) for lstm in lstm_cells]
drop_multi_cell = tf.contrib.rnn.MultiRNNCell(drop_lstm_cells)
multi_cell = tf.contrib.rnn.MultiRNNCell(lstm_cells)
w = tf.get_variable('w',shape=[num_nodes[-1], 1], initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b',initializer=tf.random_uniform([1],-0.1,0.1))
In diesem Abschnitt erstellst du zunächst TensorFlow-Variablen (c und h), die den Zustand der Zelle und den verborgenen Zustand der Zelle des Langzeitgedächtnisses enthalten. Dann wandelst du die Liste train_inputs in die Form [num_unrollings, batch_size, D] um, die du für die Berechnung der Ausgaben mit der Funktion tf.nn.dynamic_rnn brauchst. Anschließend berechnest du die LSTM-Ausgänge mit der Funktion tf.nn.dynamic_rnn und teilst den Ausgang wieder in eine Liste von num_unrolling Tensoren auf. den Verlust zwischen den Vorhersagen und den wahren Aktienkursen.
# Create cell state and hidden state variables to maintain the state of the LSTM
c, h = [],[]
initial_state = []
for li in range(n_layers):
c.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
h.append(tf.Variable(tf.zeros([batch_size, num_nodes[li]]), trainable=False))
initial_state.append(tf.contrib.rnn.LSTMStateTuple(c[li], h[li]))
# Do several tensor transofmations, because the function dynamic_rnn requires the output to be of
# a specific format. Read more at: https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn
all_inputs = tf.concat([tf.expand_dims(t,0) for t in train_inputs],axis=0)
# all_outputs is [seq_length, batch_size, num_nodes]
all_lstm_outputs, state = tf.nn.dynamic_rnn(
drop_multi_cell, all_inputs, initial_state=tuple(initial_state),
time_major = True, dtype=tf.float32)
all_lstm_outputs = tf.reshape(all_lstm_outputs, [batch_size*num_unrollings,num_nodes[-1]])
all_outputs = tf.nn.xw_plus_b(all_lstm_outputs,w,b)
split_outputs = tf.split(all_outputs,num_unrollings,axis=0)
Jetzt berechnest du den Verlust. Du solltest jedoch beachten, dass es bei der Berechnung des Verlusts eine Besonderheit gibt. Für jeden Stapel von Vorhersagen und wahren Ausgaben berechnest du den mittleren quadratischen Fehler. Und du addierst (nicht den Durchschnitt) all diese mittleren quadratischen Verluste zusammen. Schließlich legst du den Optimierer fest, den du zur Optimierung des neuronalen Netzes verwenden willst. In diesem Fall kannst du Adam verwenden, einen sehr aktuellen und gut funktionierenden Optimierer.
# When calculating the loss you need to be careful about the exact form, because you calculate
# loss of all the unrolled steps at the same time
# Therefore, take the mean error or each batch and get the sum of that over all the unrolled steps
print('Defining training Loss')
loss = 0.0
with tf.control_dependencies([tf.assign(c[li], state[li][0]) for li in range(n_layers)]+
[tf.assign(h[li], state[li][1]) for li in range(n_layers)]):
for ui in range(num_unrollings):
loss += tf.reduce_mean(0.5*(split_outputs[ui]-train_outputs[ui])**2)
print('Learning rate decay operations')
global_step = tf.Variable(0, trainable=False)
inc_gstep = tf.assign(global_step,global_step + 1)
tf_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
tf_min_learning_rate = tf.placeholder(shape=None,dtype=tf.float32)
learning_rate = tf.maximum(
tf.train.exponential_decay(tf_learning_rate, global_step, decay_steps=1, decay_rate=0.5, staircase=True),
tf_min_learning_rate)
# Optimizer.
print('TF Optimization operations')
optimizer = tf.train.AdamOptimizer(learning_rate)
gradients, v = zip(*optimizer.compute_gradients(loss))
gradients, _ = tf.clip_by_global_norm(gradients, 5.0)
optimizer = optimizer.apply_gradients(
zip(gradients, v))
print('\tAll done')
Defining training Loss
Learning rate decay operations
TF Optimization operations
All done
Hier definierst du die prädiktionsbezogenen TensorFlow-Operationen. Zuerst definierst du einen Platzhalter für die Eingabe (sample_inputs), dann definierst du, ähnlich wie in der Trainingsphase, Zustandsvariablen für die Vorhersage (sample_c und sample_h). Schließlich berechnest du die Vorhersage mit der Funktion tf.nn.dynamic_rnn und schickst dann die Ausgabe durch die Regressionsschicht (w und b). Du solltest auch die Operation reset_sample_state definieren, die den Zellenstatus und den verborgenen Status zurücksetzt. Du solltest diesen Vorgang zu Beginn ausführen, jedes Mal, wenn du eine Reihe von Vorhersagen machst.
print('Defining prediction related TF functions')
sample_inputs = tf.placeholder(tf.float32, shape=[1,D])
# Maintaining LSTM state for prediction stage
sample_c, sample_h, initial_sample_state = [],[],[]
for li in range(n_layers):
sample_c.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
sample_h.append(tf.Variable(tf.zeros([1, num_nodes[li]]), trainable=False))
initial_sample_state.append(tf.contrib.rnn.LSTMStateTuple(sample_c[li],sample_h[li]))
reset_sample_states = tf.group(*[tf.assign(sample_c[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)],
*[tf.assign(sample_h[li],tf.zeros([1, num_nodes[li]])) for li in range(n_layers)])
sample_outputs, sample_state = tf.nn.dynamic_rnn(multi_cell, tf.expand_dims(sample_inputs,0),
initial_state=tuple(initial_sample_state),
time_major = True,
dtype=tf.float32)
with tf.control_dependencies([tf.assign(sample_c[li],sample_state[li][0]) for li in range(n_layers)]+
[tf.assign(sample_h[li],sample_state[li][1]) for li in range(n_layers)]):
sample_prediction = tf.nn.xw_plus_b(tf.reshape(sample_outputs,[1,-1]), w, b)
print('\tAll done')
Defining prediction related TF functions
All done
Hier trainierst du und sagst Aktienkursbewegungen für mehrere Epochen voraus und siehst, ob die Vorhersagen im Laufe der Zeit besser oder schlechter werden. Du gehst wie folgt vor.
test_points_seq) auf der Zeitreihe, um das Modell zu bewertennum_unrollings Losennum_unrollings Datenpunkte iterierst, die vor dem Testpunkt gefunden wurden.n_predict_once Schritte, indem du die vorherige Vorhersage als aktuelle Eingabe verwendestn_predict_once Punkten und den tatsächlichen Aktienkursen zu diesen Zeitpunktenepochs = 30
valid_summary = 1 # Interval you make test predictions
n_predict_once = 50 # Number of steps you continously predict for
train_seq_length = train_data.size # Full length of the training data
train_mse_ot = [] # Accumulate Train losses
test_mse_ot = [] # Accumulate Test loss
predictions_over_time = [] # Accumulate predictions
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
# Used for decaying learning rate
loss_nondecrease_count = 0
loss_nondecrease_threshold = 2 # If the test error hasn't increased in this many steps, decrease learning rate
print('Initialized')
average_loss = 0
# Define data generator
data_gen = DataGeneratorSeq(train_data,batch_size,num_unrollings)
x_axis_seq = []
# Points you start your test predictions from
test_points_seq = np.arange(11000,12000,50).tolist()
for ep in range(epochs):
# ========================= Training =====================================
for step in range(train_seq_length//batch_size):
u_data, u_labels = data_gen.unroll_batches()
feed_dict = {}
for ui,(dat,lbl) in enumerate(zip(u_data,u_labels)):
feed_dict[train_inputs[ui]] = dat.reshape(-1,1)
feed_dict[train_outputs[ui]] = lbl.reshape(-1,1)
feed_dict.update({tf_learning_rate: 0.0001, tf_min_learning_rate:0.000001})
_, l = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += l
# ============================ Validation ==============================
if (ep+1) % valid_summary == 0:
average_loss = average_loss/(valid_summary*(train_seq_length//batch_size))
# The average loss
if (ep+1)%valid_summary==0:
print('Average loss at step %d: %f' % (ep+1, average_loss))
train_mse_ot.append(average_loss)
average_loss = 0 # reset loss
predictions_seq = []
mse_test_loss_seq = []
# ===================== Updating State and Making Predicitons ========================
for w_i in test_points_seq:
mse_test_loss = 0.0
our_predictions = []
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis=[]
# Feed in the recent past behavior of stock prices
# to make predictions from that point onwards
for tr_i in range(w_i-num_unrollings+1,w_i-1):
current_price = all_mid_data[tr_i]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
_ = session.run(sample_prediction,feed_dict=feed_dict)
feed_dict = {}
current_price = all_mid_data[w_i-1]
feed_dict[sample_inputs] = np.array(current_price).reshape(1,1)
# Make predictions for this many steps
# Each prediction uses previous prediciton as it's current input
for pred_i in range(n_predict_once):
pred = session.run(sample_prediction,feed_dict=feed_dict)
our_predictions.append(np.asscalar(pred))
feed_dict[sample_inputs] = np.asarray(pred).reshape(-1,1)
if (ep+1)-valid_summary==0:
# Only calculate x_axis values in the first validation epoch
x_axis.append(w_i+pred_i)
mse_test_loss += 0.5*(pred-all_mid_data[w_i+pred_i])**2
session.run(reset_sample_states)
predictions_seq.append(np.array(our_predictions))
mse_test_loss /= n_predict_once
mse_test_loss_seq.append(mse_test_loss)
if (ep+1)-valid_summary==0:
x_axis_seq.append(x_axis)
current_test_mse = np.mean(mse_test_loss_seq)
# Learning rate decay logic
if len(test_mse_ot)>0 and current_test_mse > min(test_mse_ot):
loss_nondecrease_count += 1
else:
loss_nondecrease_count = 0
if loss_nondecrease_count > loss_nondecrease_threshold :
session.run(inc_gstep)
loss_nondecrease_count = 0
print('\tDecreasing learning rate by 0.5')
test_mse_ot.append(current_test_mse)
print('\tTest MSE: %.5f'%np.mean(mse_test_loss_seq))
predictions_over_time.append(predictions_seq)
print('\tFinished Predictions')
Initialized
Average loss at step 1: 1.703350
Test MSE: 0.00318
Finished Predictions
...
...
...
Average loss at step 30: 0.033753
Test MSE: 0.00243
Finished Predictions
Du kannst sehen, wie der MSE-Verlust mit der Anzahl der Trainingseinheiten abnimmt. Das ist ein gutes Zeichen dafür, dass das Modell etwas Nützliches lernt. Um deine Ergebnisse zu quantifizieren, kannst du den MSE-Verlust des Netzwerks mit dem MSE-Verlust vergleichen, den du bei der Standard-Mittelwertbildung erhalten hast (0,004). Du kannst sehen, dass der LSTM besser abschneidet als die Standard-Mittelung. Und du weißt, dass die Standard-Durchschnittsbildung (auch wenn sie nicht perfekt ist) den wahren Aktienkursbewegungen einigermaßen folgt.
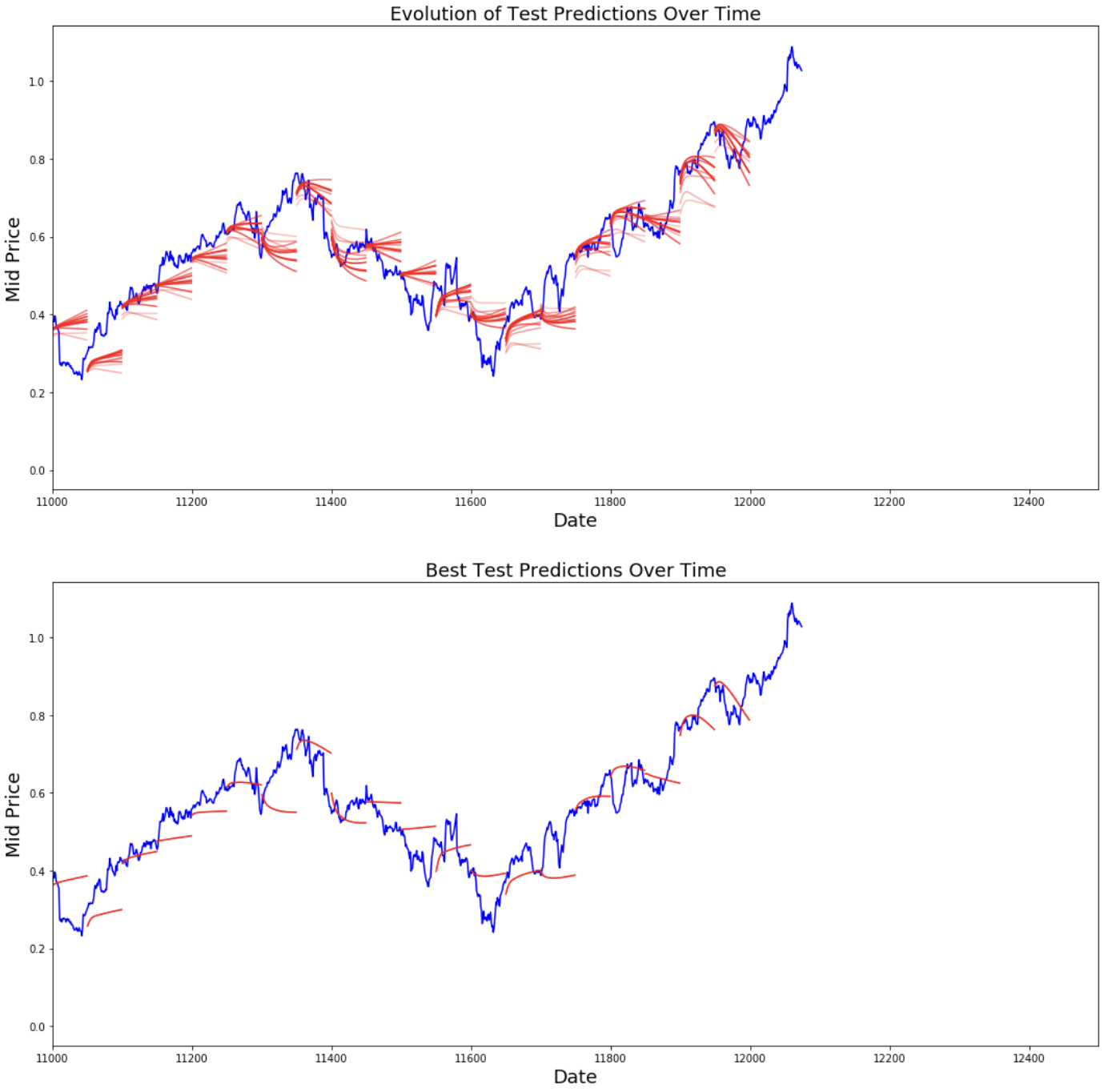
best_prediction_epoch = 28 # replace this with the epoch that you got the best results when running the plotting code plt.figure(figsize = (18,18)) plt.subplot(2,1,1) plt.plot(range(df.shape[0]),all_mid_data,color='b') # Plotting how the predictions change over time # Plot older predictions with low alpha and newer predictions with high alpha start_alpha = 0.25 alpha = np.arange(start_alpha,1.1,(1.0-start_alpha)/len(predictions_over_time[::3])) for p_i,p in enumerate(predictions_over_time[::3]): for xval,yval in zip(x_axis_seq,p): plt.plot(xval,yval,color='r',alpha=alpha[p_i]) plt.title('Evolution of Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.subplot(2,1,2) # Predicting the best test prediction you got plt.plot(range(df.shape[0]),all_mid_data,color='b') for xval,yval in zip(x_axis_seq,predictions_over_time[best_prediction_epoch]): plt.plot(xval,yval,color='r') plt.title('Best Test Predictions Over Time',fontsize=18) plt.xlabel('Date',fontsize=18) plt.ylabel('Mid Price',fontsize=18) plt.xlim(11000,12500) plt.show()
Auch wenn sie nicht perfekt sind, scheinen LSTMs das Verhalten von Aktienkursen meistens richtig vorhersagen zu können. Beachte, dass du Vorhersagen machst, die ungefähr im Bereich von 0 und 1,0 liegen (also nicht die wahren Aktienkurse). Das ist in Ordnung, denn du sagst die Entwicklung der Aktienkurse voraus, nicht die Kurse selbst.
Ich hoffe, dass du dieses Tutorial nützlich fandest. Ich sollte erwähnen, dass dies eine lohnende Erfahrung für mich war. In diesem Tutorium habe ich gelernt, wie schwierig es sein kann, ein Modell zu entwickeln, das Aktienkursbewegungen richtig vorhersagen kann. Du hast mit einer Begründung begonnen, warum du Aktienkurse modellieren musst. Es folgten eine Erklärung und ein Code zum Herunterladen der Daten. Dann hast du dir zwei Mittelwertbildungstechniken angesehen, mit denen du Vorhersagen einen Schritt in die Zukunft machen kannst. Du hast als Nächstes gesehen, dass diese Methoden nutzlos sind, wenn du mehr als einen Schritt in die Zukunft vorhersagen musst. Danach hast du besprochen, wie du LSTMs nutzen kannst, um Vorhersagen für viele Schritte in die Zukunft zu treffen. Schließlich hast du die Ergebnisse visualisiert und gesehen, dass dein Modell (wenn auch nicht perfekt) ziemlich gut darin ist, Aktienkursbewegungen korrekt vorherzusagen.
Wenn du mehr über Deep Learning erfahren möchtest, solltest du dir unseren Kurs Deep Learning in Python ansehen. Er deckt die Grundlagen ab und zeigt dir, wie du selbst ein neuronales Netzwerk in Keras erstellen kannst. Dies ist ein anderes Paket als TensorFlow, das in diesem Tutorial verwendet wird, aber die Idee ist die gleiche.
Hier nenne ich einige Erkenntnisse aus diesem Tutorial.
Die Vorhersage von Aktienkursen und -bewegungen ist eine äußerst schwierige Aufgabe. Ich persönlich glaube nicht, dass man sich blind auf eines der Aktienvorhersagemodelle verlassen sollte, die es gibt. Modelle können die Entwicklung der Aktienkurse zwar meistens richtig vorhersagen, aber nicht immer.
Lass dich nicht von Artikeln täuschen, die Vorhersagekurven zeigen, die sich perfekt mit den tatsächlichen Aktienkursen decken. Das lässt sich mit einer einfachen Mittelwertbildung nachbilden und ist in der Praxis nutzlos. Sinnvoller ist es, die Entwicklung der Aktienkurse vorherzusagen.
Die Hyperparameter des Modells sind extrem wichtig für die Ergebnisse, die du erzielst. Es wäre also eine gute Idee, die Hyperparameter mit Hilfe von Optimierungsverfahren (z.B. Rastersuche / Zufallssuche) zu überprüfen. Im Folgenden habe ich einige der wichtigsten Hyperparameter aufgelistet:
In diesem Tutorial hast du etwas falsch gemacht (aufgrund der geringen Datengröße)! Das heißt, du hast den Testverlust benutzt, um die Lernrate zu verringern. Dadurch fließen indirekt Informationen über die Testmenge in das Trainingsverfahren ein. Ein besserer Weg, damit umzugehen, ist, eine separate Validierungsmenge (neben der Testmenge) zu haben und die Lernrate in Bezug auf die Leistung der Validierungsmenge zu verringern.
Wenn du mit mir in Kontakt treten möchtest, kannst du mir eine E-Mail an thushv@gmail.com schreiben oder dich mit mir auf LinkedIn verbinden.
Ich habe auf dieses Repository verwiesen, um zu verstehen, wie man LSTMs für Aktienvorhersagen nutzt. Aber die Details können sich stark von der Umsetzung in der Referenz unterscheiden.
Erfahre mehr über Python und Deep Learning
Kurs
Kurs
Kurs
Tutorial
Laiba Siddiqui
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Allan Ouko
Tutorial
Matt Crabtree

