
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Mistral Medium 3 bietet hohe Leistung zu einem deutlich niedrigeren Preis als viele Alternativen. Sie ist derzeit über die Mistral AI API zu einem Preis von nur $0,40 pro Million Input-Token und $2 pro Million Output-Token erhältlich. Dieser Preis übertrifft die Preise führender Wettbewerber wie DeepSeek v3egal, ob es sich um eine API oder ein selbst entwickeltes System handelt. Zusammenfassend kann man sagen, dass du bis zu 90% der Leistung von Claude Sonnet 3.7 bei verschiedenen Benchmarks erreichen und dabei erheblich Kosten sparen.
In diesem Tutorial lernen wir, wie wir die Mistral-API einrichten und den Python-Client für den Zugriff auf das Modell verwenden. Danach werden wir LangGraph nutzen, um eine agentenbasierte Anwendung zu erstellen, die die Websuche und das Python REPL-Tool nutzt, um Antworten zu generieren.
Bild vom Autor
In diesem Abschnitt erfährst du, wie du den API-Schlüssel generierst, ihn als Umgebungsvariable speicherst und dann den Python-Client verwendest, um auf Mistral Medium 3 zuzugreifen, um Texte zu erzeugen und Bilder zu verstehen.
Melde dich für die La Plateforme an: Mistral AI und gehen Sie dann auf die Abrechnung und lade das Guthaben von $5 mit deiner Kredit-/Debitkarte auf. Du brauchst nur ein paar Cent für dieses Projekt. Danach gehst du zu den API-Schlüssel um den neuen API-Schlüssel zu generieren.
Das Einrichten einer Umgebungsvariable in DataLab ist ganz einfach. Gehe einfach auf die Registerkarte "Umgebung", wähle die Option "Umgebungsvariablen" und füge eine neue Variable namens "MISTRAL_API_KEY" mit deinem API-Schlüssel hinzu. Nachdem du die Änderungen gespeichert hast, stelle sicher, dass du sie verbindest.

Erstelle in DataLab die neue Python-Zelle und installiere das Mistral AI Python-Paket.
!pip install -U mistralai Bevor du irgendeinen Code schreibst, musst du unbedingt die Namen der Mistral Medium 3 API-Schlüsselendpunkte finden, indem du die Seite Models Overview besuchst. Aus der Dokumentation geht hervor, dass der Endpunkt mistral-medium-latest heißt.
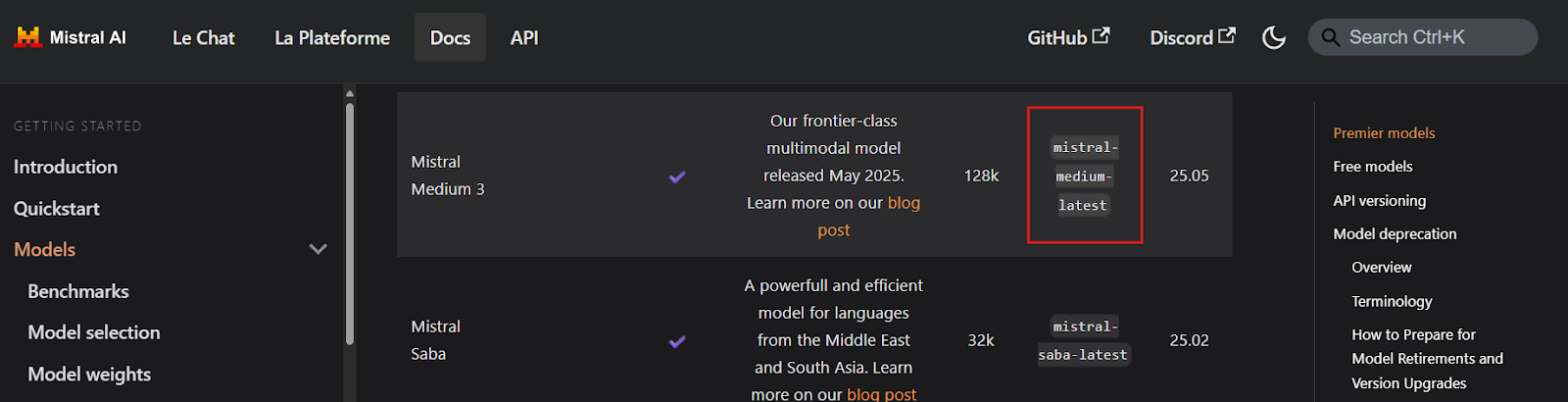
Quelle: Modelle Übersicht | Mistral AI Large Language Models
Als Nächstes erstellen wir einen Mistral-KI-Client mit dem API-Schlüssel und generieren eine Streaming-Antwort auf eine Benutzeranfrage.
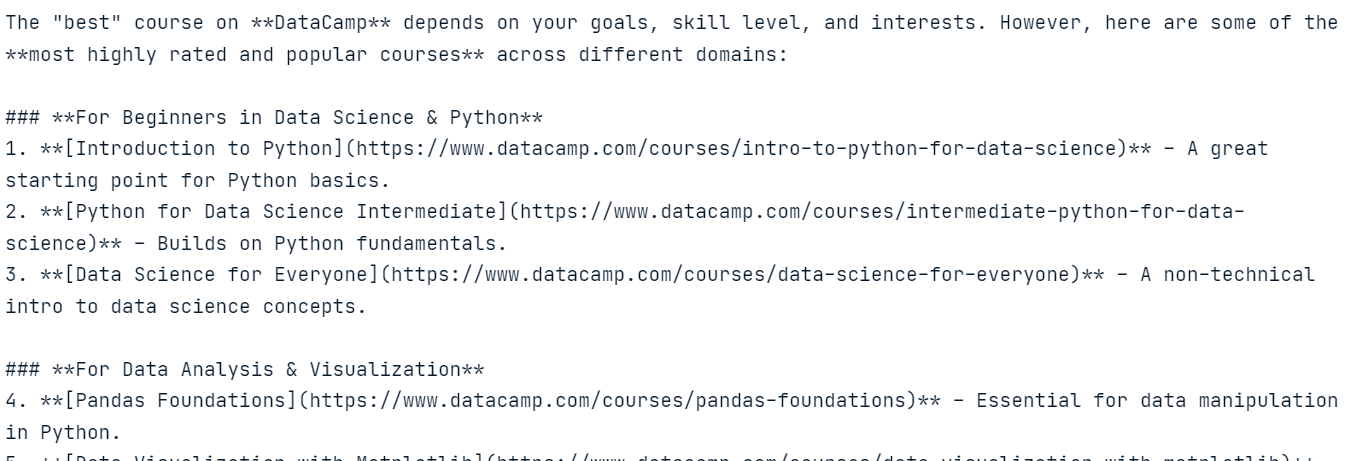
import osfrom mistralai import Mistralapi_key = os.environ["MISTRAL_API_KEY"]model = "mistral-medium-latest"client = Mistral(api_key=api_key)stream_response = client.chat.stream( model = model, messages = [ { "role": "user", "content": "What is the best course to take from DataCamp?", }, ])for chunk in stream_response: print(chunk.data.choices[0].delta.content, end="" )Die Antwort ist sehr genau und hat uns im Grunde nichts gekostet.
Um die multimodalen Fähigkeiten des Modells zu testen, nehmen wir einen Screenshot der Startseite des DataCamp-Blogs auf und übermitteln ihn zusammen mit einer Benutzerabfrage an das Modell.
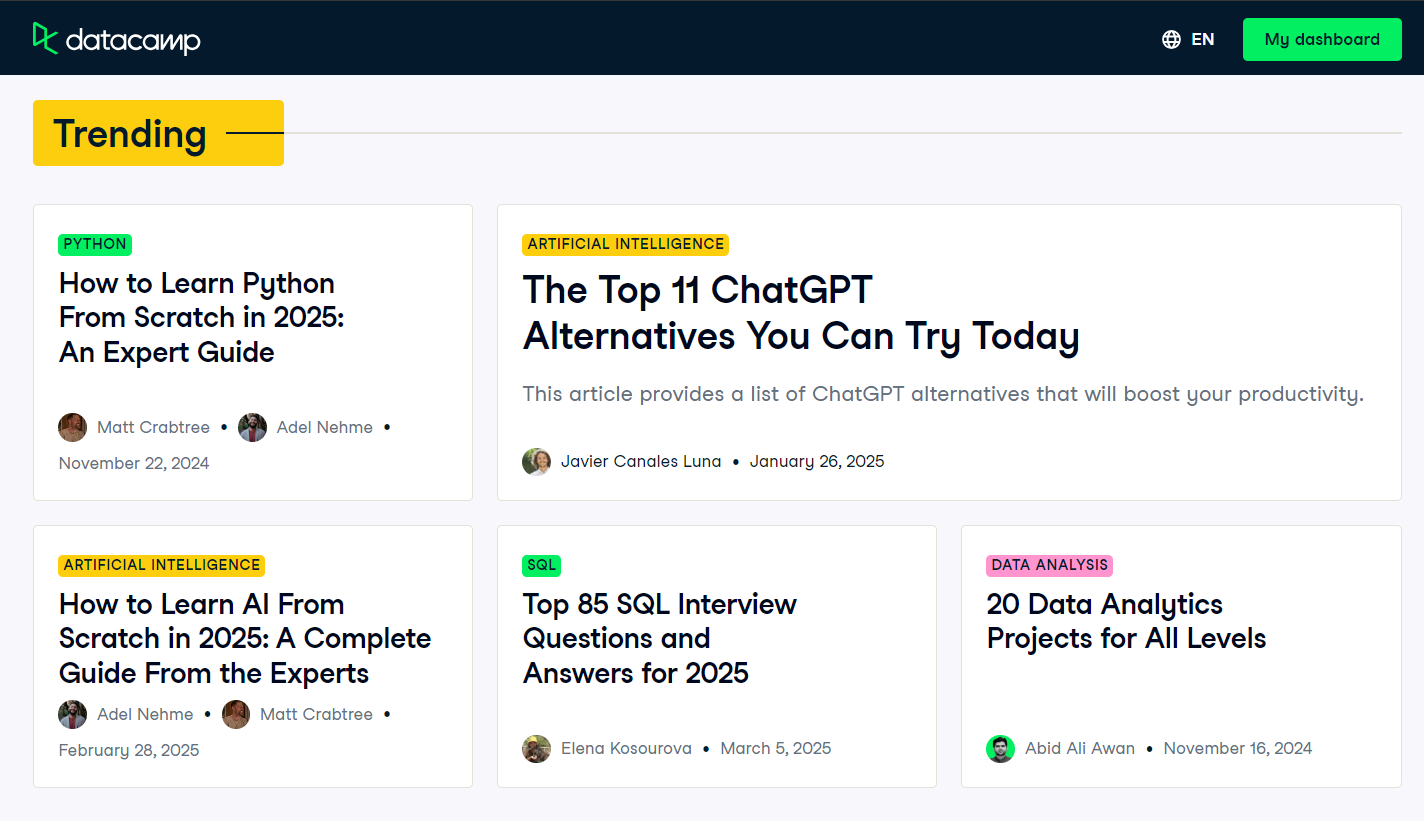
Quelle: Blog | Data Science Artikel | DataCamp
Da das Modell nicht direkt auf die Bilddatei zugreifen kann, müssen wir das Bild zuerst laden und in einen Base64-kodierten String umwandeln.
import base64import requestsdef encode_image(image_path): """Encode the image to base64.""" try: with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') except FileNotFoundError: print(f"Error: The file {image_path} was not found.") return None except Exception as e: # Added general exception handling print(f"Error: {e}") return None# Path to your imageimage_path = "datacamp_fp.png"# Getting the base64 stringbase64_image = encode_image(image_path)Wir senden nun das Base64-kodierte Bild zusammen mit einer Benutzeranfrage an den Mistral AI Chat Completion Client.
# Define the messages for the chatmessages = [ { "role": "user", "content": [ { "type": "text", "text": "Explain the image in a Donald Trump style." }, { "type": "image_url", "image_url": f"data:image/png;base64,{base64_image}" } ] }]stream_response = client.chat.stream( model = model, messages = messages)for chunk in stream_response: print(chunk.data.choices[0].delta.content, end="" )Das Modell interpretiert das Bild erfolgreich und generiert eine Antwort in Donald Trumps Stil, was seine multimodalen Verständnisfähigkeiten unter Beweis stellt.

In diesem Projekt werden wir Mistral Medium 3 mit LangGraph verwenden, um eine agentenbasierte Anwendung zu erstellen. Diese Anwendung wird die Tavily API für die Websuche und die Python REPL für die Ausführung von Code auf der Grundlage von Benutzeraufforderungen nutzen.
Bist du neu bei LangGraph? Kein Problem! Folge unserem LangGraph Tutorial und lerne alles, was du über das Framework wissen musst.
Bevor wir mit der Implementierung beginnen, müssen wir Tavily AI einrichten, indem wir ein Konto erstellen und einen API-Schlüssel generieren. Der Vorgang ist unkompliziert und du musst keine Zahlungsdaten oder eine Kreditkarte angeben.
Sobald du den API-Schlüssel hast, speicherst du ihn als Umgebungsvariable mit dem Namen TAVILY_API_KEY entweder lokal oder in deinem DataLab-Setup, wie im vorherigen Abschnitt gezeigt.
Als Nächstes werden wir die notwendigen Python-Pakete installieren, um Werkzeuge und Agenten zu erstellen, die das LangChain-Ökosystem nutzen.
%%capture!pip install -U \ mistralai \ langchain langchain-mistralai \ langchain-experimental \ langgraph \ tavily-pythonWir erstellen den LangChain-Client ChatMistralAI large language models (LLM), indem wir den Modellnamen und die Temperatur angeben und Streaming-Antworten aktivieren .
from langchain_mistralai import ChatMistralAIllm = ChatMistralAI( model="mistral-medium-latest", temperature=0.2, streaming=True )Jetzt werden wir die Werkzeuge für den Agenten einrichten. Anstatt Tools manuell zu erstellen, können wir vorgefertigte Tools wie Tavily Search und Python REPL aus dem LangChain-Ökosystem verwenden.
from langchain_community.tools import TavilySearchResultsfrom langchain_experimental.tools.python.tool import PythonREPLToolsearch_tool = TavilySearchResults(max_results=5, include_answer=True)code_tool = PythonREPLTool()tools = [search_tool, code_tool]Nachdem der LLM-Client und die Tools fertig sind, können wir jetzt den React Agent mit LangGraph erstellen.
from langgraph.prebuilt import create_react_agentagent = create_react_agent( model=llm, tools=tools, ) ``` 6. Extracting tool namesBefore executing the agent, we will define a Python function to extract the names of the tools used during the agent’s response generation. This function will help us identify which tools were invoked.```pythondef extract_tool_names(conversation: dict) -> list[str]: """ Given a conversation dict with a 'messages' list (where each message may be a dict or a Pydantic model), extract all unique tool names used in any tool call. """ tool_names = set() for msg in conversation.get('messages', []): # 1) Try direct attribute access (for Pydantic models) calls = [] if hasattr(msg, 'tool_calls'): calls = getattr(msg, 'tool_calls') or [] # 2) If that fails, the message might be a dict elif isinstance(msg, dict): calls = msg.get('tool_calls') # also check nested in additional_kwargs if not calls and isinstance(msg.get('additional_kwargs'), dict): calls = msg['additional_kwargs'].get('tool_calls') # 3) Finally, check additional_kwargs on objects else: ak = getattr(msg, 'additional_kwargs', None) if isinstance(ak, dict): calls = ak.get('tool_calls', []) # Normalize to list calls = calls or [] # Extract names for call in calls: # dict-style tool call if isinstance(call, dict): # top-level 'name' if 'name' in call: tool_names.add(call['name']) # nested under 'function' elif 'function' in call and isinstance(call['function'], dict): fn = call['function'] if 'name' in fn: tool_names.add(fn['name']) return sorted(tool_names)LangGraph Studio ist eine visuelle Entwicklungsumgebung für das LangGraph-Framework; folge dem LangGraph Studio Guide: Installation, Einrichtung, Anwendungsfälle um mehr darüber zu erfahren .
Testen wir den Agenten, indem wir ihm eine Frage zu aktuellen Nachrichten stellen.
question = "What are the top 5 breaking news stories?"def run_agent(question): result = agent.invoke( { "messages": [ {"role": "user", "content": question} ] } ) tool_name = extract_tool_names(result) # The LLM’s final answer is always in the last message raw_answer = result["messages"][-1].content clean_text = "".join(part for part in raw_answer if isinstance(part, str)) return tool_name, clean_texttool_name, clean_text = run_agent(question)print("Tool used ⫸", tool_name, "\n")print(clean_text)Der Agent hat die Tavily-Suche benutzt, um eine Antwort auf eine Eilmeldung zu erhalten.

Als Nächstes wollen wir das Python REPL-Tool testen, indem wir den Agenten bitten, Python-Code zu erzeugen und auszuführen.
question = "Write a code to display the stars in a triangle. Please execute the code too."tool_name, clean_text = run_agent(question)print("Tool used ⫸", tool_name, "\n")print(clean_text)Der Agent hat Mistral Medium 3 für die Codegenerierung und Python REPL für die Codeausführung verwendet.

Zum Schluss wollen wir eine Abfrage testen, bei der der Agent beide Tools nacheinander verwenden muss.
question = "Get the latest gold price data for the past 7 days and use it to generate a line plot"tool_name, clean_text = run_agent(question)print("Tool used ⫸", tool_name, "\n")print(clean_text)Der Agent nutzt Tavily Search, um Goldpreisdaten zu erhalten, Mistral Medium 3, um Code für die Datenvisualisierung zu erzeugen, und Python REPL, um diesen Code auszuführen. Das Ergebnis ist eine sehr genaue Tabelle mit einer Zusammenfassung der verwendeten Werkzeuge.
Tool used ⫸ ['Python_REPL', 'tavily_search_results_json'] The code generates a line plot showing the gold price per gram in USD over the last 7 days, with the x-axis representing dates and the y-axis representing the gold price. The plot includes markers for each data point, a title, labeled axes, a grid, and rotated x-axis labels for better readability.
Wenn du Probleme beim Ausführen des Codes hast, sieh in der Mistral Medium 3 - DataLab Notizbuch für zusätzliche Anleitungen.
Du kannst das Haystack-Ökosystem nutzen, um eine Agentenanwendung zu entwickeln, die leistungsfähiger und einfacher zu implementieren ist. Folge den Anleitungen, um mehr zu erfahren: Haystack AI Tutorial: Aufbau von agentenbasierten Arbeitsabläufen.
Nachdem ich mit der Mistral AI API experimentiert und Agenten gebaut habe, um verschiedene Anwendungen zu testen, ist einer der bemerkenswertesten Aspekte, dass es mich keinen einzigen Dollar gekostet hat - selbst nach dem Einsatz von 161.075 Token. Das Modell ist erschwinglich, schnell, genau und unglaublich einfach einzurichten. Sie ist eine gute Alternative zu anderen teuren APIs wie DeepSeek und bietet vergleichbare Funktionen.
Die KI-Landschaft bewegt sich eindeutig in Richtung kleinerer, schnellerer, genauerer und kostengünstigerer Modelle, was ein vielversprechender Trend ist, insbesondere für Start-ups und kleine und mittlere Unternehmen (KMU). Diese Organisationen sind oft stark von LLM-Anbietern abhängig, und da diese Modelle erschwinglicher werden, werden sie von höheren Gewinnspannen profitieren.
Nimm die Entwickeln großer Sprachmodelle Lernpfad, um mit PyTorch und Hugging Face und den neuesten Deep-Learning- und NLP-Techniken deine eigenen LLMs zu erstellen.
Top DataCamp Kurse
Lernpfad
Lernpfad
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
