
Kurs
Prompt-Engineering mit der OpenAI-API
4 Std.
48K
Präferenz-Feinabstimmung (PFT) ist eine Technik, die seit langem zur Feinabstimmung von LLMs verwendet wird. OpenAI hat sie vor kurzem im Rahmen der 12 Tage des Feature-Rollouts eingeführt.
Zusammen mit der überwachten Feinabstimmung (SFT) und Reinforcement Fine-Tuning (RFT)ist PFT eine weitere Möglichkeit, große Sprachmodelle an die Präferenzen der Nutzer anzupassen.
In diesem Artikel erkläre ich kurz die Feinabstimmung der Präferenzen und zeige dir, wie du sie mit minimalem Aufwand im OpenAI-Entwickler-Dashboard nutzen kannst.
Während das Ziel der standardmäßigen überwachten Feinabstimmung darin besteht, dass das Modell bei bestimmten Eingaben bestimmte Ergebnisse liefert, liegt der Schwerpunkt bei der Präferenzfeinabstimmung (PFT) darauf, das Modell so zu steuern, dass es die Antworten ausgibt, die wir mögen, und die Antworten zu vermeiden, die wir nicht mögen.
Die direkte Präferenzoptimierung (DPO) Die direkte Präferenzoptimierung (DPO) ist die Standardtechnik in der PFT und hat sich aufgrund ihrer Einfachheit und Effektivität als starkes Ausrichtungsverfahren durchgesetzt.
Anders als Verstärkungslernen durch menschliches Feedback (RLHF)benötigt DPO kein komplexes Belohnungsmodell, um das große Sprachmodell (LLM) auszurichten, sondern behandelt das Ausrichtungsproblem als eine "direkte" Optimierung einer Verlustfunktion. Das macht DPO einfacher zu implementieren und rechnerisch effizienter.
Der Datensatz, der für DPO benötigt wird, enthält wie bei anderen Abgleichsmethoden ein Paar von "bevorzugten" und "nicht bevorzugten" Antworten für eine bestimmte Aufforderung. Im Fall von OpenAIs PFT muss der Datensatz, ähnlich wie bei anderen Feinabstimmungsmethoden, imFormat JSONL vorliegen und die folgende Struktur haben:
{
"input": {
"messages": [
{
"role": "user",
"content": "Hello, can you tell me how cold San Francisco is today?"
}
],
"tools": [],
"parallel_tool_calls": true
},
"preferred_output": [
{
"role": "assistant",
"content": "Today in San Francisco, it is not quite cold as expected. Morning clouds will give away to sunshine, with a high near 68°F (20°C) and a low around 57°F (14°C)."
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": "It is not particularly cold in San Francisco today."
}
]
}Die offizielle OpenAI Dokumentation für PFT empfiehlt die Kombination von SFT und PFT zur besseren Abstimmung. Abgleichtechniken wie PFT werden in der Regel nach der Feinabstimmung des Modells auf einem überwachten Datensatz verwendet. Die Kombination von SFT mit PFT gilt als Industriestandard und wird auch von OpenAI befürwortet.
Als Erstes müssen wir sicherstellen, dass unser Datensatz das erforderliche Format für die Feinabstimmung der OpenAI-Einstellungen hat.
Es gibt mehrere Möglichkeiten, einen Präferenzdatensatz zu erstellen. Eine Methode besteht darin, Paare von LLM-Ausgängen mit unterschiedlichen Temperaturen, top_k oder Systemaufforderungen abzurufen und dann einen anderen LLM, vorzugsweise einen leistungsfähigeren, zu verwenden, um einen Ausgang als "bevorzugt" und den anderen als "nicht bevorzugt" auszuwählen.
Für die Demo in diesem Lernprogramm lade ich einen Einstellungsdatensatz von Hugging Face herunter und strukturiere ihn neu. Ich werde verwenden argilla/ultrafeedback-binarized-preferencesverwenden, das ist ein Präferenzdatensatz, aber ich werde nur die ersten 50 Zeilen erhalten.
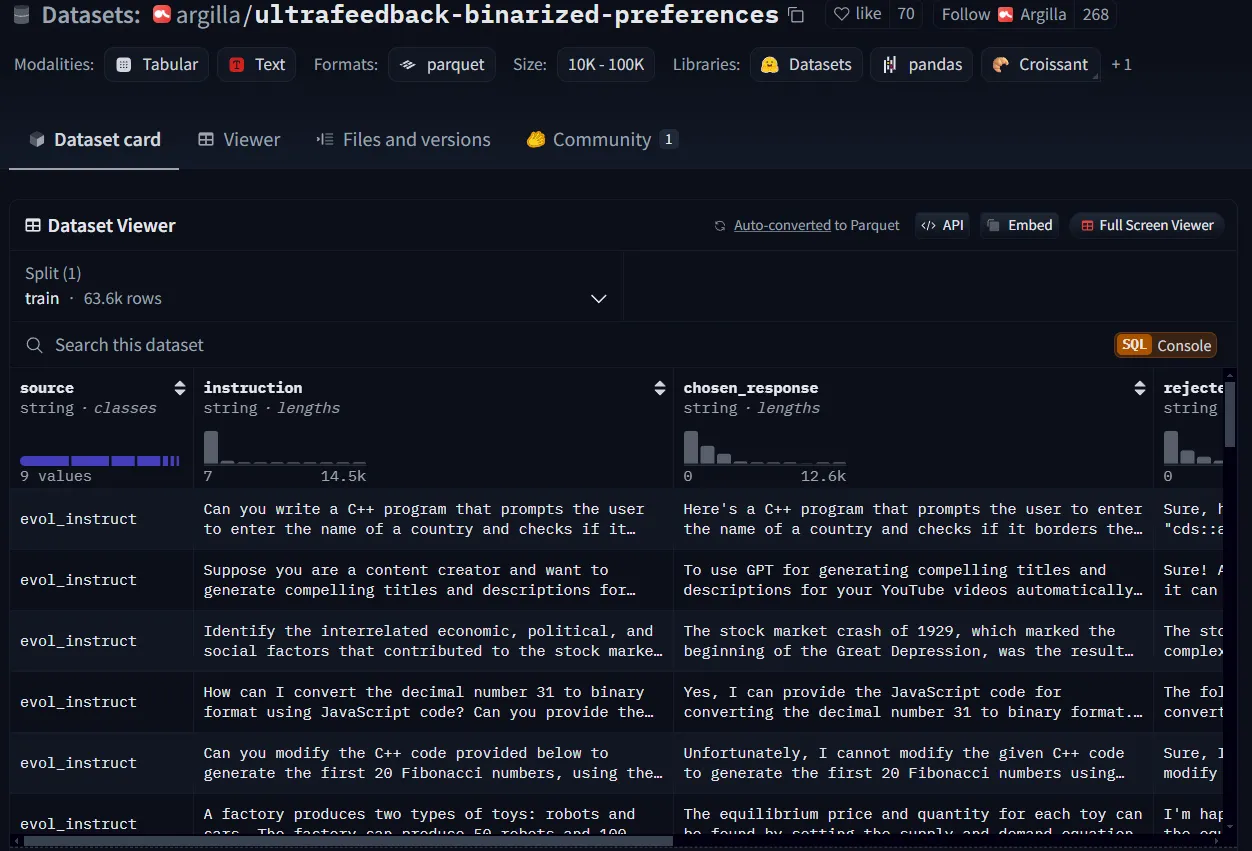
Ein Beispiel für einen Präferenzdatensatz von Hugging Face.
Ein Python-Skript würde ausreichen, um die Struktur des Datensatzes an die Anforderungen von OpenAI anzupassen, aber du kannst auch einen anderen Ansatz für deine Anwendung wählen.
import datasets
import copy
import json
instance_structure = {
"input": {
"messages": [
{
"role": "user",
"content": ""
}
],
"tools": [],
"parallel_tool_calls": True
},
"preferred_output": [
{
"role": "assistant",
"content": ""
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": ""
}
]
}
ds = datasets.load_dataset("argilla/ultrafeedback-binarized-preferences", trust_remote_code=True, split="train")
ds_sample = ds.select(range(50)) #select the first 50 rows
ds_list = []
for sample in ds_sample:
instance = copy.deepcopy(instance_structure)
instance["input"]["messages"][0]["content"] = sample["instruction"]
instance["preferred_output"][0]["content"] = sample["chosen_response"]
instance["non_preferred_output"][0]["content"] = sample["rejected_response"]
ds_list.append(instance)
with open("preference_dataset.jsonl", 'w') as out:
for json_line in ds_list:
jout = json.dumps(json_line) + '\\n'
out.write(jout)Achte darauf, dass das Format deines Datensatzes jsonl und nicht json ist. Du wirst wahrscheinlich eine leere Zeile am Ende deiner Datei haben, also stelle sicher, dass du sie entfernst.
Wenn du deinen Datensatz vorbereitet hast, kannst du die folgenden Schritte für die Feinabstimmung der Präferenzen ausführen:
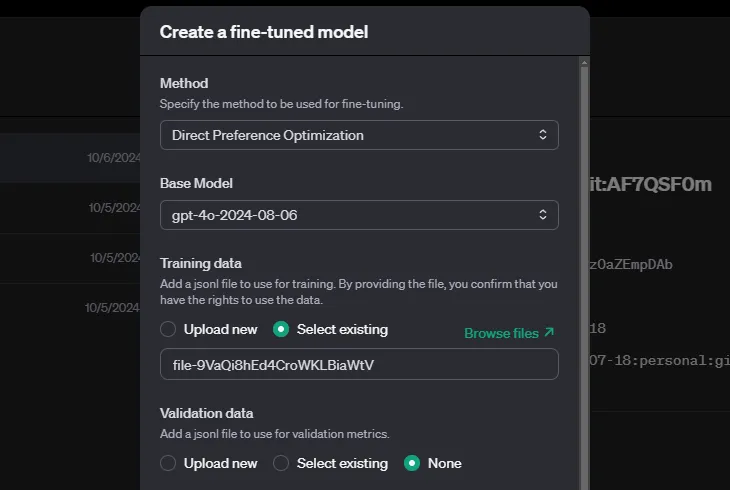
In OpenAI kannst du Hyperparameter angeben, aber du kannst sie auch leer lassen, dann entscheidet das System automatisch. Je nach Größe deines Datensatzes kann das Training eine Weile dauern.
Die direkte Präferenzoptimierung ist eine nützliche neue Funktion in OpenAIs Werkzeugkasten für die Feinabstimmung, mit der du den Ton und den Stil der Reaktion deines Modells explizit steuern kannst, um sie besser auf die Präferenzen der Nutzer/innen abzustimmen.
Wie bei der Destillation, der verstärkten Feinabstimmung und der überwachten Feinabstimmung von OpenAI besteht dein Hauptbeitrag bei der bevorzugten Feinabstimmung darin, den Datensatz entsprechend dem Format und der Struktur von OpenAI vorzubereiten, und die Tools von OpenAI kümmern sich um den Rest:
Um mehr darüber zu erfahren, empfehle ich diese Ressourcen:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs