
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Reinforcement Fine-Tuning (RFT) ist eine Technik zur Verfeinerung des Wissens großer Sprachmodelle durch eine belohnungsgesteuerte Trainingsschleife.
Frontier-Modelle sind bemerkenswerte Allzweck-Sprachmodelle. Die besten von ihnen beherrschen ein breites Spektrum an Aufgaben, wie z.B. Übersetzung, Assistenz, Programmierung und mehr. Ein wichtiger Bereich der laufenden Forschung konzentriert sich jedoch auf Feinabstimmung diese Modelle effizient zu optimieren. Das Ziel ist es, sie so anzupassen, dass sie bestimmte Töne und Stile annehmen oder sich auf bestimmte Bereiche spezialisieren, wie z.B. medizinische Fachberatung oder domänenspezifische Klassifizierungsaufgaben.
Die Herausforderung besteht darin, diese Feinabstimmung effizient durchzuführen. Effizienz bedeutet, dass weniger Rechenleistung verbraucht wird und weniger markierte Datensätze benötigt werden, aber trotzdem hochwertige Ergebnisse erzielt werden. Hier kommt die RFT ins Spiel und bietet eine vielversprechende Lösung für dieses Problem.
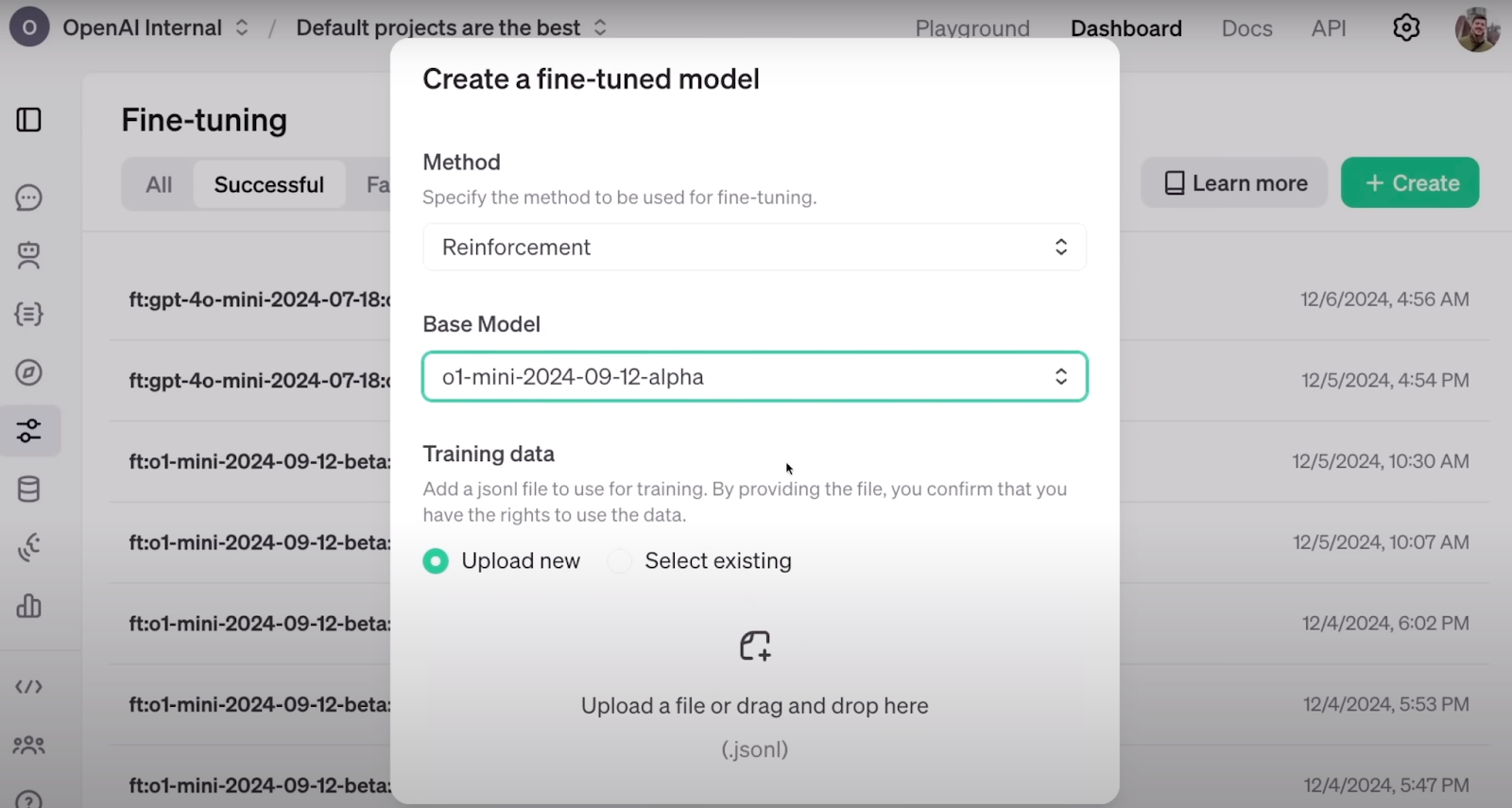
So sieht die Konfiguration von RFT auf dem Dashboard von OpenAI aus. Quelle: OpenAI
Laut der Ankündigung von OpenAI Ankündigungkann RFT ein Modell mit nur ein paar Dutzend Beispielen effektiv feinabstimmen . In vielen Bereichen, wie z.B. im medizinischen Sektor, wo Daten knapp und teuer sind, sind weniger Daten ein großer Vorteil.
RFT basiert auf dem Rückgrat des Verstärkungslernen (RL) auf, bei dem Agenten auf der Grundlage ihrer Handlungen positiv oder negativ belohnt werden, damit sie sich an das Verhalten anpassen, das wir von ihnen erwarten. Dies wird erreicht, indem dem Output des Agenten eine Punktzahl zugewiesen wird. Durch iteratives Training auf der Grundlage dieser Punkte lernen die Agenten, ohne dass sie die Regeln explizit verstehen oder sich vordefinierte Schritte zur Lösung des Problems einprägen müssen.
Kombiniert mit Bemühungen, LLMs für spezielle Aufgaben zu verbessern, entsteht RFT aus RL und Feinabstimmungstechniken. Die Idee ist, RFT in einer Reihe von Schritten durchzuführen:
1. Stelle einen beschrifteten, strukturierten Datensatz zur Verfügung, der das Modell mit dem Wissen ausstattet, das es lernen soll. Wie bei einer typischen Machine-Learning-Aufgabe sollte dieser Datensatz in einen Trainings- und einen Validierungssatz unterteilt werden.
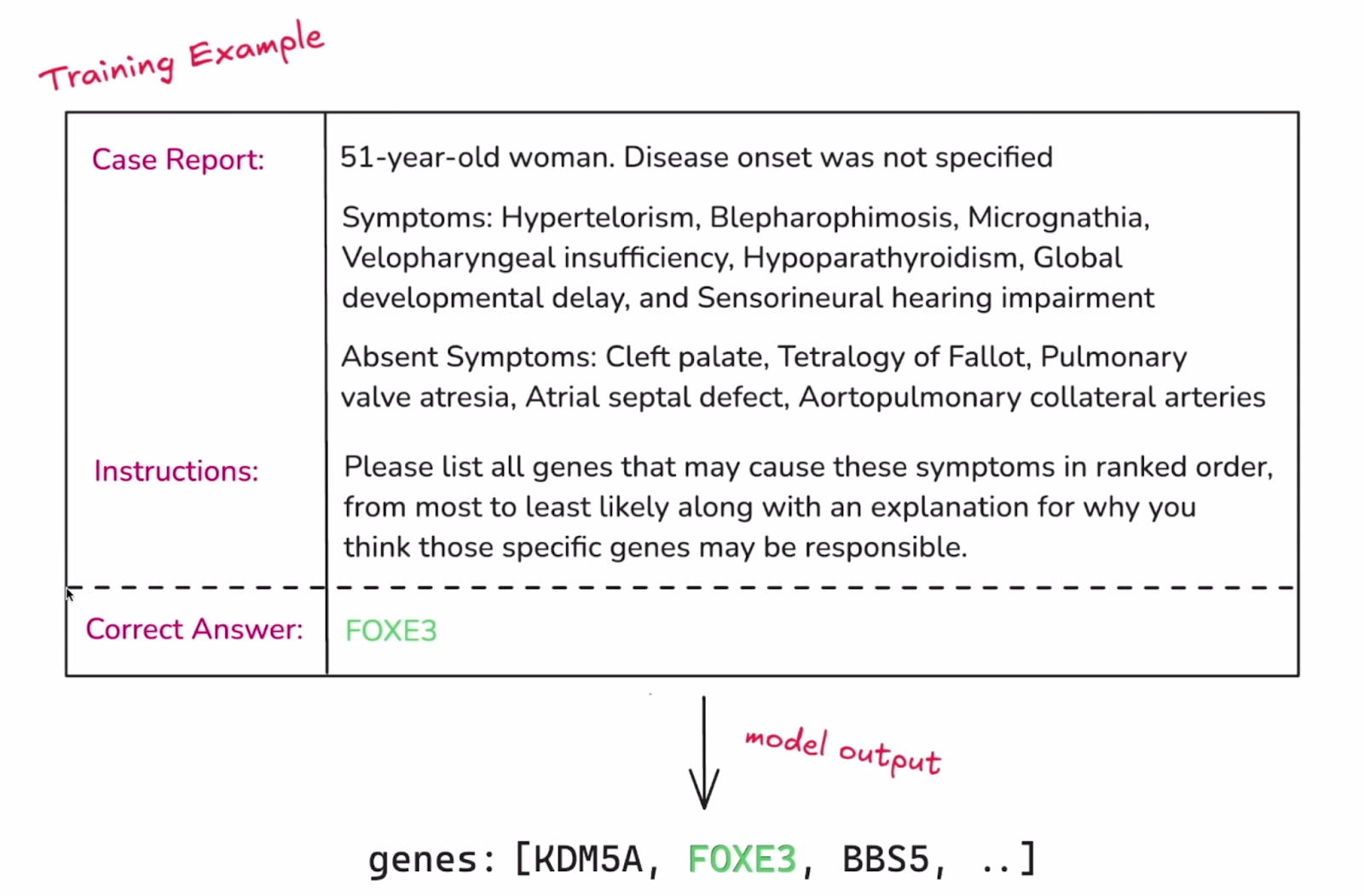
Beispiel für eine einzelne Instanz des Datensatzes. Quelle: OpenAI
2. Die nächste wichtige Komponente des RFT ist die Möglichkeit, die Ergebnisse des Modells zu bewerten. Bei einem typischen Feinabstimmungsprozess versucht das Modell einfach, die markierte Zielantwort zu reproduzieren. Im RFT sollte das Modell jedoch einen Denkprozess entwickeln, der zu diesen Antworten führt. Die Einstufung der Ergebnisse des Modells ist das, was es bei der Feinabstimmung leitet, und das geschieht mit den "Graders". Die Note kann von 0 bis 1 oder irgendwo dazwischen liegen, und es gibt viele Möglichkeiten, den Outputs eines Modells eine Note zuzuweisen. OpenAI kündigte Pläne an, weitere Grader einzuführen und möglicherweise eine Möglichkeit für Nutzer einzuführen, ihre eigenen benutzerdefinierten Grader zu implementieren.
3. Sobald das Modell auf die Eingaben aus der Trainingsmenge reagiert, wird seine Ausgabe vom Grader bewertet. Diese Punktzahl dient als "Belohnungssignal". Die Gewichte und Parameter des Modells werden dann so angepasst, dass die zukünftigen Gewinne maximiert werden.
4. Das Modell wird durch wiederholte Schritte feinabgestimmt. Mit jedem Zyklus verfeinert das Modell seine Strategie und die Validierungsmenge (getrennt vom Training) wird regelmäßig verwendet, um zu überprüfen, wie gut diese Verbesserungen auf neue Beispiele verallgemeinert werden. Wenn sich die Ergebnisse des Modells bei den Validierungsdaten verbessern, ist das ein gutes Zeichen dafür, dass das Modell wirklich sinnvolle Strategien lernt und nicht nur Lösungen auswendig lernt.
Diese Erklärung fasst das Wesentliche von RFT zusammen, aber die Umsetzung und die technischen Details können abweichen.
Wenn man sich die Bewertungsergebnisse von RFT ansieht, die ein fein abgestimmtes o1-mini-Modell mit einem Standard o1-mini und o1-Modell vergleichen, fällt auf, dass RFT bei einem Datensatz von nur 1.100 Beispielen eine höhere Genauigkeit als das o1-Modellobwohl letzteres größer und fortschrittlicher ist als das o1-mini-Modell.
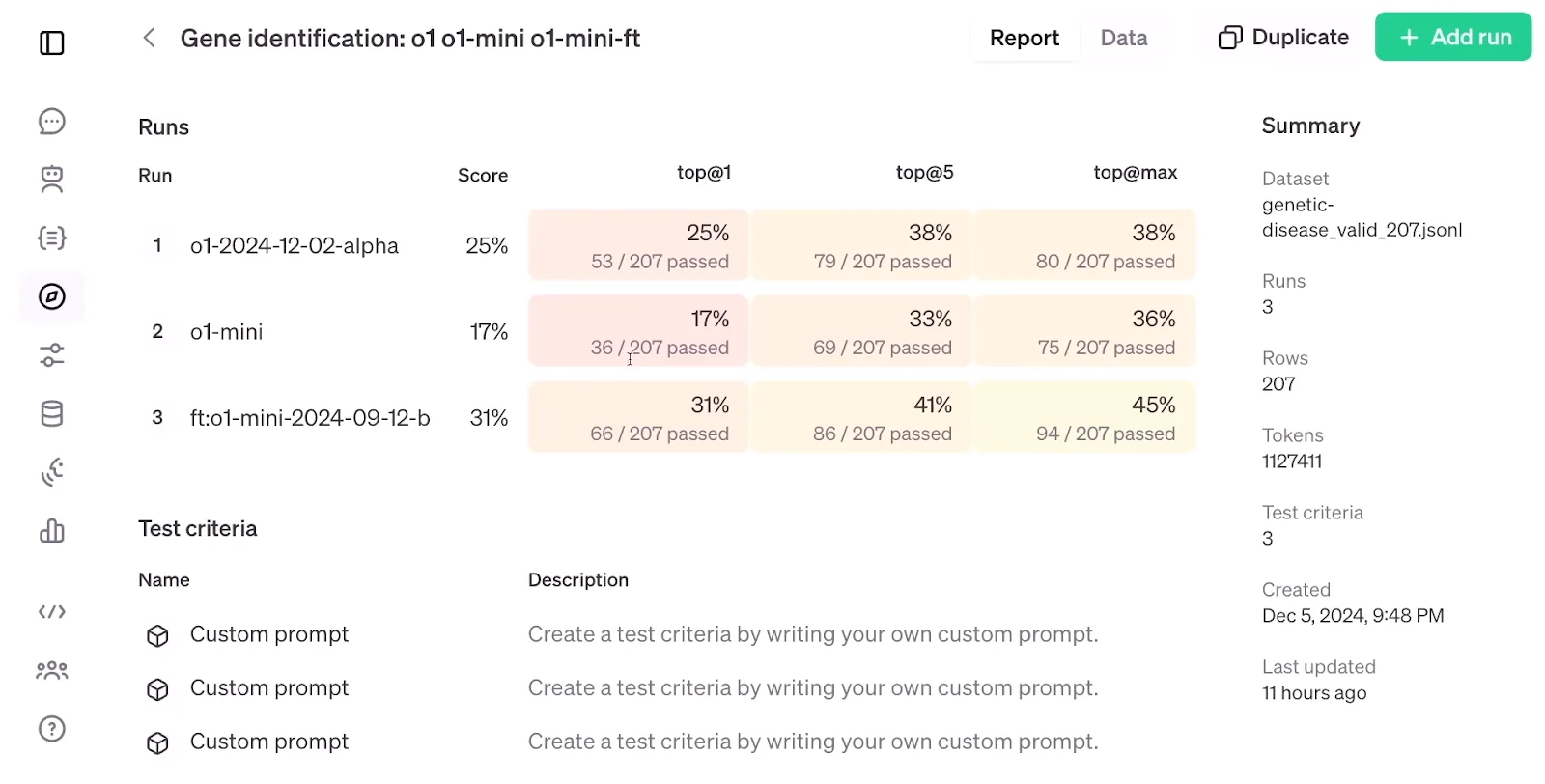
Bewertung des RFT. Quelle: OpenAI
Bei der überwachten Feinabstimmung (SFT) wird ein zuvor trainiertes Modell mit zusätzlichen Daten unter Verwendung überwachter Lerntechniken angepasst. In der Praxis funktioniert die SFT am besten, wenn das Ziel darin besteht, die Ausgabe oder das Format des Modells an einen bestimmten Datensatz anzupassen oder sicherzustellen, dass das Modell bestimmte Anweisungen befolgt.
Die überwachte Feinabstimmung und die verstärkte Feinabstimmung stützen sich zwar beide auf gelabelte Daten, nutzen diese aber unterschiedlich. Bei SFT werden die Aktualisierungen des Modells direkt von den beschrifteten Daten gesteuert. Das Modell sieht es als Zielausgabe und passt seine Parameter an, um die Differenz zwischen seiner vorhergesagten Ausgabe und der bekannten richtigen Antwort zu schließen.
Beim RFT ist das Modell dem Label nur indirekt ausgesetzt, da es hauptsächlich dazu dient, das Belohnungssignal zu erzeugen, und kein direktes Ziel darstellt. Aus diesem Grund wird erwartet, dass das Modell in RFT weniger beschriftete Daten benötigt - das Modell zielt darauf ab, Muster zu finden, um die gewünschte Ausgabe zu produzieren, anstatt direkt auf unsere Ausgaben zu zielen, und das verspricht mehr Tendenz zur Generalisierung.
Fassen wir die Unterschiedein dieser Tabelle zusammen:
|
Feature |
Überwachtes Fine-Tuning (SFT) |
Verstärkungs-Feinabstimmung (RFT) |
|
Kerngedanke |
Trainiere das Modell direkt auf gelabelten Daten, damit es dem gewünschten Ergebnis entspricht. |
Verwende einen "Grader", um das Modell zu belohnen, wenn es den gewünschten Output erzeugt. |
|
Verwendung des Etiketts |
Direktes Ziel, das das Modell nachahmen soll. |
Indirekt verwendet, um ein Belohnungssignal für das Modell zu erzeugen. |
|
Daten-Effizienz |
Benötigt mehr beschriftete Daten. |
Durch die Verallgemeinerung werden potenziell weniger markierte Daten benötigt. |
|
Menschliches Engagement |
Nur bei der ersten Datenbeschriftung. |
Nur bei der Gestaltung der Funktion "Grader". |
|
Verallgemeinerung |
Es kann zu einer Überanpassung an die Trainingsdaten kommen, was die Generalisierung einschränkt. |
Höheres Potenzial für Verallgemeinerungen aufgrund der Konzentration auf Muster und Belohnungen. |
|
Anpassung an menschliche Präferenzen |
Begrenzt, da es sich ausschließlich auf die Nachahmung der markierten Daten stützt. |
Kann besser angepasst werden, wenn der "Grader" die menschlichen Präferenzen genau widerspiegelt. |
|
Beispiele |
Feinabstimmung eines Sprachmodells, um bestimmte Arten von Textformaten (wie Gedichte oder Codes) zu erzeugen. |
Training eines Sprachmodells, um kreative Inhalte zu erstellen, die von einem "Grader" auf der Grundlage von Originalität und Kohärenz bewertet werden. |
Als ich über RFT las, musste ich unweigerlich an eine andere effektive und klassische Technik denken, die Verstärkungslernen durch menschliches Feedback (RLHF). In RLHF geben menschliche Kommentatoren Rückmeldung darüber, wie auf Aufforderungen zu reagieren ist, und ein Belohnungsmodell wird trainiert, um dieses Feedback in numerische Belohnungssignale umzuwandeln. Diese Signale werden dann zur Feinabstimmung der Parameter des vortrainierten Modells durch Proximale Politikoptimierung (PPO).
Während RFT das menschliche Feedback aus der Schleife herausnimmt und sich darauf verlässt, dass der Grader das Belohnungssignal der Antwort des Modells zuordnet, ist die Idee der Integration des Verstärkungslernens in die Feinabstimmung des LLM immer noch mit der von RLHF vereinbar.
Interessanterweise war RLHF die Methode, die sie zuvor verwendet hatten, um das Modell im ChatGPT-Trainingsprozess besser abzustimmen. Laut dem Ankündigungsvideo ist RFT die Methode, die OpenAI intern zum Trainieren seiner Grenzmodelle wie GPT-4o oder o1 pro Modus.
Verstärkungslernen wurde schon früher in die Feinabstimmung der LLMs integriert, aber OpenAIs Verstärkungsfeinabstimmung scheint das auf ein höheres Niveau zu heben.
Obwohl die genaue Funktionsweise von RFT, das Erscheinungsdatum und eine wissenschaftliche Bewertung seiner Wirksamkeit noch nicht bekannt gegeben wurden, können wir die Daumen drücken und hoffen, dass RFT bald verfügbar und so leistungsfähig sein wird wie versprochen.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.