
Kurs
Einführung in Deep Learning mit Python
4 Std.
263.5K
Der massive Einsatz von Tools wie ChatGPT und anderen generativen KI-Tools hat zu einer großen Debatte über die Vorteile und Herausforderungen von KI geführt und darüber, wie sie unsere Gesellschaft umgestalten wird. Um diese Fragen besser beurteilen zu können, ist es wichtig zu wissen, wie die sogenannten Large Language Models (LLMs) hinter den KI-Tools der nächsten Generation funktionieren.
Dieser Artikel gibt eine Einführung in das Reinforcement Learning from Human Feedback (RLHF), eine innovative Technik, die Reinforcement-Learning-Techniken und menschliche Anleitung kombiniert, um LLMS wie ChatGPT zu beeindruckenden Ergebnissen zu verhelfen. Wir werden uns damit beschäftigen, was RLHF ist, welche Vorteile und Grenzen es hat und welche Bedeutung es für die zukünftige Entwicklung des sich schnell entwickelnden Bereichs der generativen KI hat. Lies weiter!
Um die Rolle der RLHF zu verstehen, müssen wir zunächst über den Ausbildungsprozess von LLMs sprechen.
Die Technik, die den beliebtesten LLMs zugrunde liegt, ist ein Transformator. Seit ihrer Entwicklung durch Google-Forscher/innen sind Transformatoren zum modernsten Modell im Bereich der KI und des Deep Learning geworden, da sie eine effektivere Methode zur Verarbeitung von sequentiellen Daten, wie z. B. den Wörtern eines Satzes, bieten.
Eine detailliertere Einführung in LLMs und Transformatoren findest du in unserem Large Language Models (LLMs) Concepts Course.
Die Transformatoren werden mit einem riesigen Textkorpus aus dem Internet durch selbstüberwachtes Lernen trainiert, eine innovative Art des Trainings, bei der die Daten nicht von Menschenhand beschriftet werden müssen. Vortrainierte Transformatoren sind in der Lage, eine breite Palette von Problemen der natürlichen Sprachverarbeitung (NLP) zu lösen.
Damit ein KI-Tool wie ChatGPT ansprechende, genaue und menschenähnliche Antworten geben kann, reicht es jedoch nicht aus, eine vortrainierte LLM zu verwenden. Letztlich ist die menschliche Kommunikation ein kreativer und subjektiver Prozess. Was einen Text "gut" macht, wird stark von menschlichen Werten und Vorlieben beeinflusst und ist daher sehr schwer zu messen oder mit einer klaren, algorithmischen Lösung zu erfassen.
Die Idee hinter ELF ist, menschliches Feedback zu nutzen, um die Leistung des Modells zu messen und zu verbessern. Was RLHF im Vergleich zu anderen Verstärkungslerntechniken einzigartig macht, ist die Nutzung der menschlichen Beteiligung zur Optimierung des Modells anstelle einer statistisch vordefinierten Funktion zur Maximierung der Belohnung des Agenten.
Diese Strategie ermöglicht eine anpassungsfähigere und individuellere Lernerfahrung, so dass LLMs für alle Arten von branchenspezifischen Anwendungen geeignet sind, wie z.B. Code-Assistenz, juristische Recherche, das Schreiben von Aufsätzen und das Verfassen von Gedichten.
RLHF ist ein anspruchsvoller Prozess, der ein Training mit mehreren Modellen und verschiedene Einsatzphasen umfasst. Im Wesentlichen kann sie in drei verschiedene Schritte unterteilt werden.
In der ersten Phase wird eine vortrainierte LLM ausgewählt, die später mit RLHF feinabgestimmt wird.
Du könntest deinen LLM auch von Grund auf vorbereiten, aber das ist ein kostspieliger und zeitaufwändiger Prozess. Daher empfehlen wir dringend, einen der vielen vorbereiteten LLMs zu wählen, die für die Öffentlichkeit zugänglich sind.
Wenn du mehr darüber erfahren möchtest, wie man LLM trainiert, findest du in unserem Tutorial Wie man ein LLM mit PyTorch trainiert ein anschauliches Beispiel.
Beachte, dass du dein Modell auf zusätzliche Texte oder Bedingungen abstimmen kannst, bevor du mit der Feinabstimmung durch menschliches Feedback beginnst, um den spezifischen Anforderungen deines Modells gerecht zu werden.
Wenn du zum Beispiel einen KI-Rechtsassistenten entwickeln willst, könntest du dein Modell mit einem Korpus juristischer Texte verfeinern, damit dein LLM besonders vertraut mit juristischen Formulierungen und Begriffen wird.
Anstatt ein statistisch vordefiniertes Belohnungsmodell zu verwenden (das für die Kalibrierung der menschlichen Präferenzen sehr restriktiv wäre), nutzt RLHF das menschliche Feedback, um dem Modell zu helfen, ein subtileres Belohnungsmodell zu entwickeln. Das Verfahren läuft folgendermaßen ab:
Das folgende Bild veranschaulicht den gesamten Prozess:
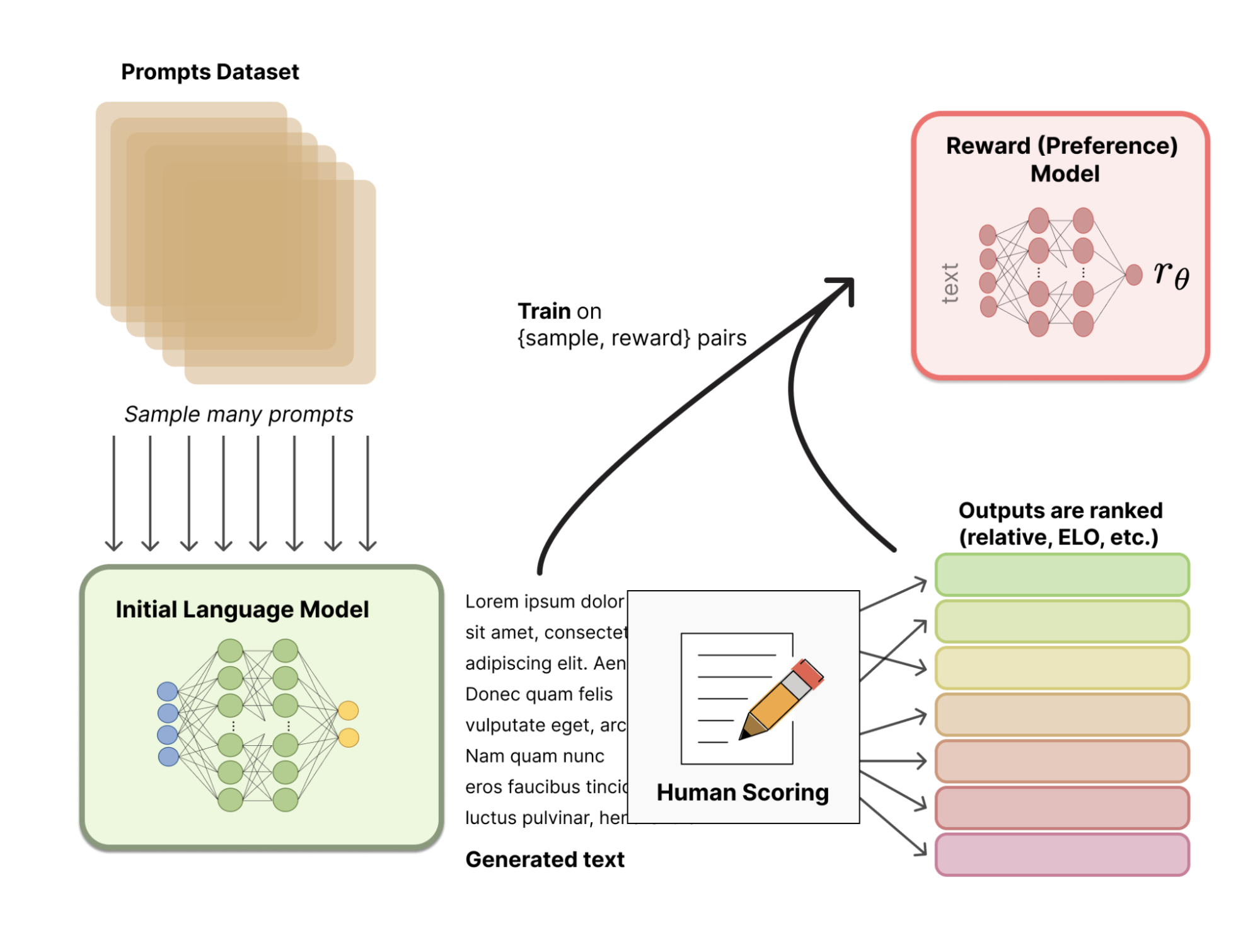
Quelle: Hugging Face
In der letzten Phase produziert der LLM neue Texte und verwendet sein auf menschlichem Feedback basierendes Belohnungsmodell, um eine Qualitätsbewertung zu erstellen. Die Punktzahl wird dann vom Modell verwendet, um seine Leistung bei nachfolgenden Aufforderungen zu verbessern.
Menschliches Feedback und Feinabstimmung mit Reinforcement-Learning-Techniken werden so in einem iterativen Prozess kombiniert, der fortgesetzt wird, bis ein bestimmter Grad an Genauigkeit erreicht ist.
RLHF ist eine moderne Technik zur Feinabstimmung von LLMs wie ChatGPT. RLHF ist jedoch ein beliebtes Thema, und es gibt immer mehr Literatur, die sich mit anderen Möglichkeiten als NLP-Problemen beschäftigt. Unten findest du eine Liste mit anderen Bereichen, in denen RLHF erfolgreich eingesetzt wurde:
RLHF ist eine leistungsstarke und vielversprechende Technik, ohne die die nächste Generation von KI-Tools nicht möglich wäre. Hier sind einige der Vorteile von RLHF:
RLHF ist jedoch nicht kugelsicher. Diese Technik birgt auch gewisse Risiken und Einschränkungen. Unten siehst du einige der wichtigsten:
RLHF ist eines der Rückgrate moderner generativer KI-Tools wie ChatGPT und GPT-4. Trotz der beeindruckenden Ergebnisse ist RLHF eine relativ neue Technik, und es gibt noch viel Spielraum für Verbesserungen. Zukünftige Forschung zu RLHF-Techniken ist entscheidend, um LLMs effizienter zu machen, ihren ökologischen Fußabdruck zu verringern und einige der Risiken und Einschränkungen von LLMs zu beseitigen.
Um über die neuesten Entwicklungen in den Bereichen generative KI, maschinelles Lernen und LLMs auf dem Laufenden zu bleiben, empfehlen wir dir unsere kuratierten Lernmaterialien:
Lerne die Themen, die in diesem Artikel erwähnt werden!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
