
Curso
Engenharia rápida com a API OpenAI
4 h
47.9K
O ajuste fino de preferências (PFT) é uma técnica usada há muito tempo para ajustar os LLMs. A OpenAI o apresentou recentemente como parte de seus 12 dias de lançamento de recursos.
Juntamente com o ajuste fino supervisionado (SFT) e o ajuste fino de reforço (RFT)o PFT é outra maneira de alinhar grandes modelos de linguagem com as preferências do usuário.
Neste artigo, explicarei rapidamente o ajuste fino de preferências e mostrarei a você como usá-lo com o mínimo de esforço no painel do desenvolvedor da OpenAI.
Enquanto o objetivo do ajuste fino supervisionado padrão é fazer com que o modelo retorne determinados resultados com determinadas entradas, o foco do ajuste fino de preferências (PFT) é direcionar o modelo para produzir as respostas de que gostamos e ficar longe das respostas que não gostamos.
Otimização direta de preferências (DPO) é a técnica padrão em PFT e ganhou popularidade como uma técnica de alinhamento forte por sua simplicidade e eficácia.
Diferente de aprendizado por reforço a partir de feedback humano (RLHF)o DPO não exige um modelo de recompensa complexo para alinhar o modelo de linguagem grande (LLM), mas, em vez disso, trata o problema de alinhamento como uma otimização "direta" de uma função de perda. Isso torna o DPO mais fácil de implementar e mais eficiente do ponto de vista computacional.
O conjunto de dados necessário para o OPD, assim como outros métodos de alinhamento, inclui um par de respostas "preferidas" e "não preferidas" para um determinado prompt. No caso do PFT da OpenAI, semelhante a outros métodos de ajuste fino, o conjunto de dados deve estar noformato JSONL e ter a seguinte estrutura:
{
"input": {
"messages": [
{
"role": "user",
"content": "Hello, can you tell me how cold San Francisco is today?"
}
],
"tools": [],
"parallel_tool_calls": true
},
"preferred_output": [
{
"role": "assistant",
"content": "Today in San Francisco, it is not quite cold as expected. Morning clouds will give away to sunshine, with a high near 68°F (20°C) and a low around 57°F (14°C)."
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": "It is not particularly cold in San Francisco today."
}
]
}A documentação oficial da OpenAI oficial da OpenAI para o PFT recomenda que você combine o SFT e o PFT para obter um melhor alinhamento. As técnicas de alinhamento, como o PFT, são comumente usadas após o ajuste fino do modelo em um conjunto de dados supervisionado. A combinação de SFT com PFT é considerada um padrão do setor e também é defendida pela OpenAI.
Antes de qualquer coisa, precisamos garantir que nosso conjunto de dados esteja no formato necessário para o ajuste fino das preferências da OpenAI.
Há várias maneiras de criar um conjunto de dados de preferências. Um método é recuperar pares de saídas do LLM com diferentes temperaturas, top_k ou solicitações do sistema e, em seguida, usar outro LLM, de preferência um mais capaz, para escolher uma saída como "preferida" e a outra como "não preferida".
Para a demonstração deste tutorial, farei o download de um conjunto de dados de preferências do Hugging Face e o reestruturarei. Eu usarei argilla/ultrafeedback-binarized-preferencesque é um conjunto de dados de preferências, mas obterei apenas as primeiras 50 linhas.
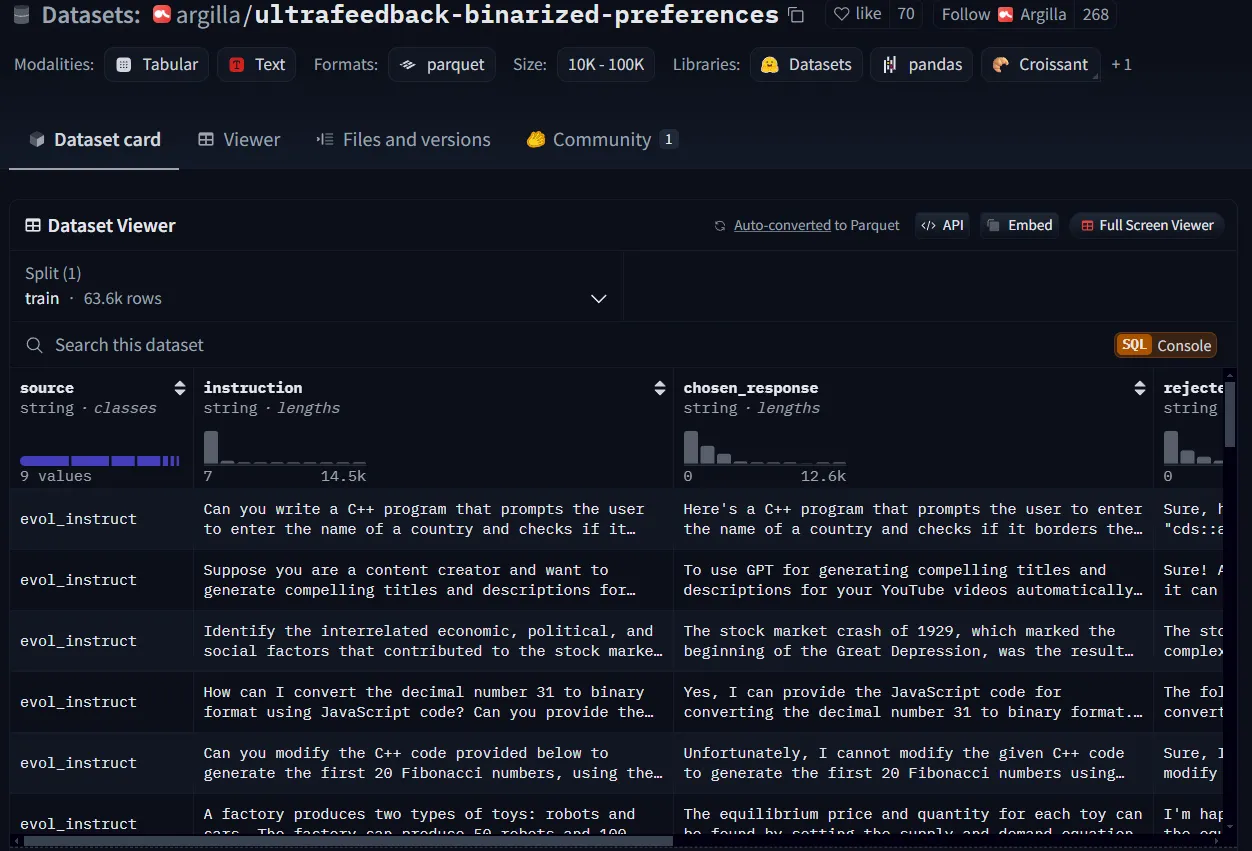
Um exemplo de um conjunto de dados de preferências do Hugging Face.
Um script Python seria suficiente para converter a estrutura do conjunto de dados para os requisitos de ajuste fino da OpenAI, mas você pode decidir seguir outra abordagem com base no seu aplicativo.
import datasets
import copy
import json
instance_structure = {
"input": {
"messages": [
{
"role": "user",
"content": ""
}
],
"tools": [],
"parallel_tool_calls": True
},
"preferred_output": [
{
"role": "assistant",
"content": ""
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": ""
}
]
}
ds = datasets.load_dataset("argilla/ultrafeedback-binarized-preferences", trust_remote_code=True, split="train")
ds_sample = ds.select(range(50)) #select the first 50 rows
ds_list = []
for sample in ds_sample:
instance = copy.deepcopy(instance_structure)
instance["input"]["messages"][0]["content"] = sample["instruction"]
instance["preferred_output"][0]["content"] = sample["chosen_response"]
instance["non_preferred_output"][0]["content"] = sample["rejected_response"]
ds_list.append(instance)
with open("preference_dataset.jsonl", 'w') as out:
for json_line in ds_list:
jout = json.dumps(json_line) + '\\n'
out.write(jout)Certifique-se de que o formato do seu conjunto de dados seja jsonl e não json. Você provavelmente terá uma linha vazia no final do arquivo, portanto, certifique-se de removê-la.
Com o conjunto de dados preparado, você pode seguir estas etapas para executar o ajuste fino de preferências:
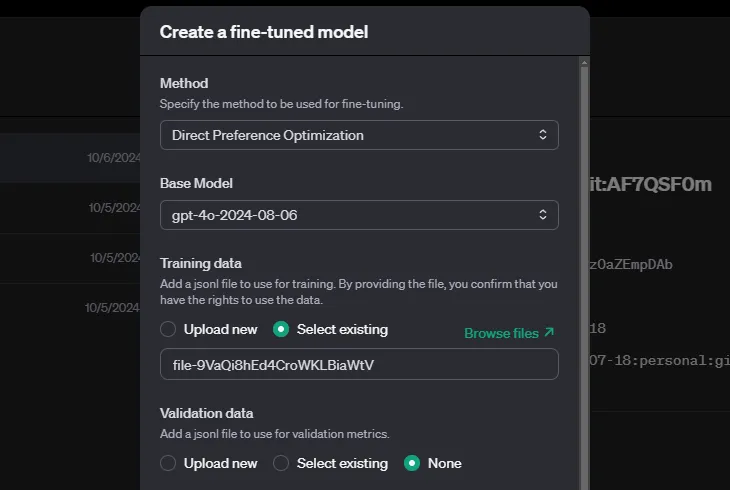
O OpenAI permite que você especifique hiperparâmetros, mas também pode deixá-los vazios, e o sistema decidirá automaticamente. Dependendo do tamanho do conjunto de dados, o treinamento pode demorar um pouco.
A otimização direta de preferências é um novo recurso útil na caixa de ferramentas de ajuste fino da OpenAI que permite que você controle explicitamente o tom e o estilo da resposta do seu modelo e o torne mais alinhado com a preferência do usuário.
Assim como acontece com a destilação, o ajuste fino de reforço e o ajuste fino supervisionado da OpenAI, sua principal contribuição no ajuste fino de preferência seria preparar o conjunto de dados de acordo com o formato e a estrutura da OpenAI, e as ferramentas deles cuidarão do resto:
Para saber mais, recomendo estes recursos:
Aprenda IA com estes cursos!
Curso
Curso
Curso
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze


