
Cours
Ingénierie des prompts avec l'API OpenAI
4 h
48K
Preference fine-tuning (PFT) is a technique that has been used for a long time to fine-tune LLMs. OpenAI recently introduced it as part of their 12 days of feature rollout.
Along with supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT), PFT is another way to align large language models with user preferences.
In this article, I will quickly explain preference fine-tuning and show you how to use it with minimal effort in OpenAI’s developer dashboard.
While the goal of the standard supervised fine-tuning is to have the model return certain outputs given certain inputs, the focus in preference fine-tuning (PFT) is to steer the model toward outputting the responses we like and stay away from the responses we don’t.
Direct preference optimization (DPO) is the standard technique in PFT and has gained popularity as a strong alignment technique for its simplicity and effectiveness.
Unlike reinforcement learning from human feedback (RLHF), DPO does not require a complex reward model to align the large language model (LLM) but instead treats the alignment problem as a “direct” optimization of a loss function. This makes DPO easier to implement and more computationally efficient.
The dataset required for DPO, like other alignment methods, includes a pair of “preferred” and “not preferred” responses for a given prompt. In the case of OpenAI’s PFT, similar to other fine-tuning methods, the dataset must be in JSONL format and have the following structure:
{
"input": {
"messages": [
{
"role": "user",
"content": "Hello, can you tell me how cold San Francisco is today?"
}
],
"tools": [],
"parallel_tool_calls": true
},
"preferred_output": [
{
"role": "assistant",
"content": "Today in San Francisco, it is not quite cold as expected. Morning clouds will give away to sunshine, with a high near 68°F (20°C) and a low around 57°F (14°C)."
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": "It is not particularly cold in San Francisco today."
}
]
}The official OpenAI documentation for PFT recommends combining SFT and PFT for better alignment. Alignment techniques such as PFT are commonly used after fine-tuning the model on a supervised dataset. Combining SFT with PFT is considered an industry standard and is also advocated by OpenAI.
Before anything, we need to ensure our dataset is in the required format for OpenAI’s preference fine-tuning.
There are multiple ways to create a preference dataset. One method is to retrieve pairs of LLM outputs given different temperatures, top_k, or system prompts and then use another LLM, preferably a more capable one, to choose one output as “preferred” and the other as “not preferred.”
For the demo in this tutorial, I will download a preference dataset from Hugging Face and re-structure it. I will use argilla/ultrafeedback-binarized-preferences, which is a preference dataset, but I will only get the first 50 rows.
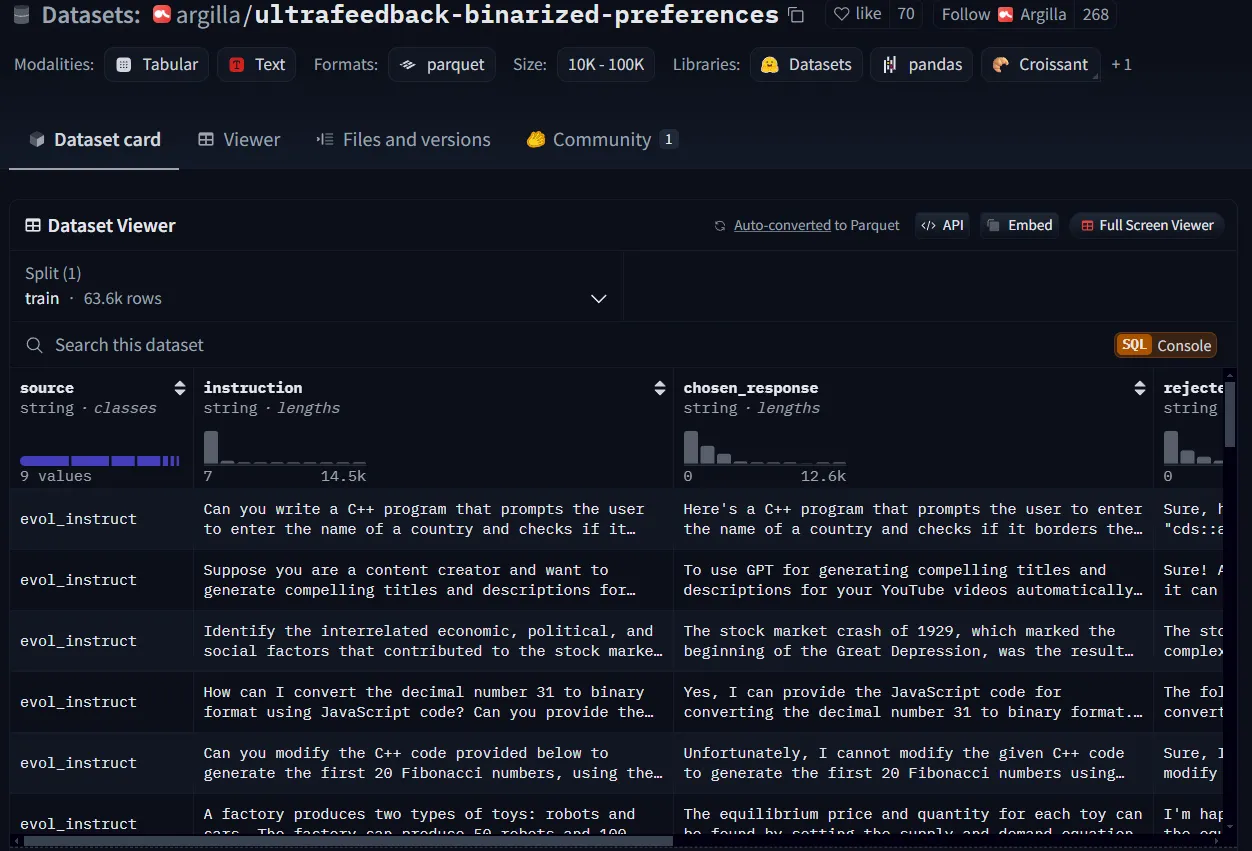
An example of a preference dataset from Hugging Face.
A Python script would suffice to convert the dataset's structure to OpenAI’s fine-tuning requirements, but you can decide to follow another approach based on your application.
import datasets
import copy
import json
instance_structure = {
"input": {
"messages": [
{
"role": "user",
"content": ""
}
],
"tools": [],
"parallel_tool_calls": True
},
"preferred_output": [
{
"role": "assistant",
"content": ""
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": ""
}
]
}
ds = datasets.load_dataset("argilla/ultrafeedback-binarized-preferences", trust_remote_code=True, split="train")
ds_sample = ds.select(range(50)) #select the first 50 rows
ds_list = []
for sample in ds_sample:
instance = copy.deepcopy(instance_structure)
instance["input"]["messages"][0]["content"] = sample["instruction"]
instance["preferred_output"][0]["content"] = sample["chosen_response"]
instance["non_preferred_output"][0]["content"] = sample["rejected_response"]
ds_list.append(instance)
with open("preference_dataset.jsonl", 'w') as out:
for json_line in ds_list:
jout = json.dumps(json_line) + '\\n'
out.write(jout)Make sure that your dataset's format is jsonl and not json. You will likely have an empty line at the end of your file, so make sure to remove it.
With your dataset prepared, you can follow these steps to run preference fine-tuning:
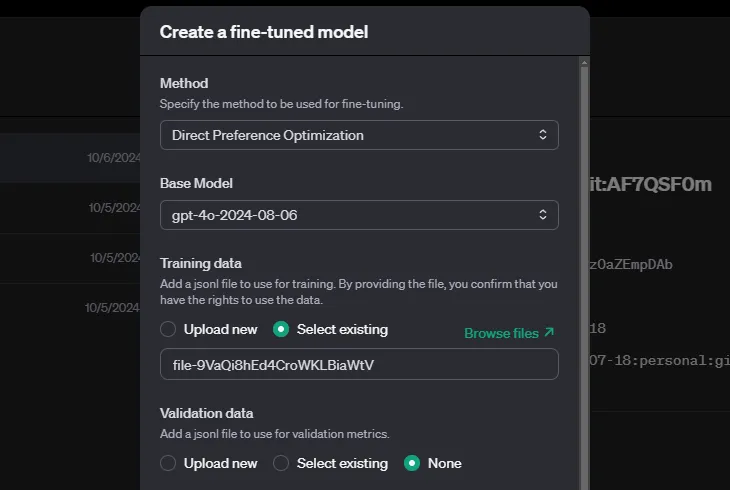
OpenAI allows you to specify hyperparameters, but you can also leave them empty, and the system will decide automatically. Depending on your dataset size, the training can take a while.
Direct preference optimization is a useful new feature in OpenAI’s fine-tuning toolbox which allows you to explicitly control the tone and style of your model’s response and make it more aligned with user preference.
As with OpenAI’s distillation, reinforcement fine-tuning, and supervised fine-tuning, your main contribution in preference fine-tuning would be preparing the dataset according to OpenAI’s format and structure, and their tools will take care of the rest:
To learn more, I recommend these resources:
Learn AI with these courses!
Cours
Cours
Cours
blog
Hesam Sheikh Hassani
5 min
blog
Javier Canales Luna
7 min
Tutoriel
Josep Ferrer
Tutoriel
Dimitri Didmanidze
Tutoriel
Zoumana Keita
code-along
Zoumana Keita

