
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Microsofts RStar-math stellt einen innovativen Ansatz zum Lösen mathematischer Probleme vor, der eine Kombination aus Reinforcement Learning, symbolischem Denken und Monte Carlo Tree Search (MCTS) verwendet.
In diesem Blog werde ich das RStar-Framework und seine Kernkomponenten vorstellen. Anschließend führe ich dich Schritt für Schritt durch eine vereinfachte Implementierung, die die wichtigsten Konzepte mit Gradio demonstriert. Diese Demo orientiert sich zwar an dem Papier, aber einige komplexe Sachverhalte wurden vereinfacht, um sie leichter zugänglich zu machen.
Die RStar-Mathematik zielt darauf ab, symbolisches Denken mit den Verallgemeinerungsfähigkeiten von vortrainierten neuronalen Modellen zu verbinden. Das Framework integriert Komponenten wie Monte Carlo Tree Search (MCTS), vortrainierte Sprachmodelle und Verstärkungslernen um eine effiziente Erkundung von Problemlösungsstrategien zu ermöglichen.
Die Kernidee ist, mathematisches Denken als einen Suchprozess über einen strukturierten Baum möglicher Schritte darzustellen, wobei jeder Knoten eine Teillösung oder einen Zustand darstellt.
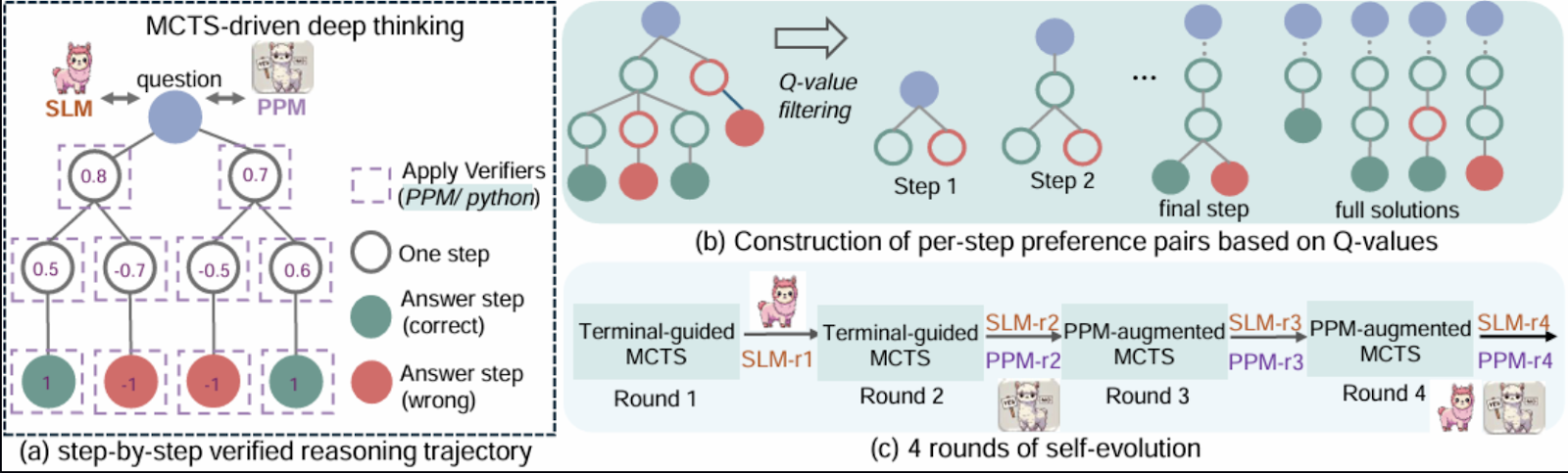
Quelle: Guan et al., 2025
Einige der Gründe, die rStar-Math für mich besonders interessant machen, sind:
Die Demo zeigt, wie ein Richtlinien- und ein Belohnungsmodell in Kombination mit symbolischem Denken unter Verwendung der sympy Bibliothek mathematische Probleme auf strukturierte Weise lösen können. Zu den wichtigsten Merkmalen dieser Umsetzung gehören:
Um die Demo einfach und fokussiert zu halten, sind bestimmte fortgeschrittene Funktionen, auf die in dem Papier hingewiesen wird, nicht Gegenstand dieses Tutorials. Diese Merkmale sind:
Die Demo ist in mehrere Komponenten unterteilt, die jeweils einen Teil der RStar-Methode widerspiegeln. Bevor wir beginnen, solltest du sicherstellen, dass du Folgendes installiert hast:
pip install requests gradio, sympy Dann importiere diese Bibliotheken:
import gradio as gr
import numpy as np
import torch
import re
import torch.nn as nn
import torch.optim as optim
from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E, sympify
from random import choiceJetzt, da alle Abhängigkeiten installiert sind, können wir die Hauptkomponenten einrichten.
Diese Netzwerke sind leichtgewichtige Versionen der in der Arbeit beschriebenen Modelle, die zur Vorhersage der nächsten Aktion und zur Erfolgsbewertung verwendet werden. Das Politikmodell sagt die nächsten Schritte zur Lösung der gegebenen Gleichungen voraus. Es verwendet ein neuronales Feedforward-Netzwerk, um kodierte Darstellungen des Problems zu verarbeiten.
Auch das Belohnungsmodell bewertet Teillösungen, um den MCTS-Prozess zu steuern. Beide Modelle werden mit PyTorch implementiert.
class PolicyModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
class RewardModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return xAls Nächstes erstellen wir eine Knotenklasse für MCTS-Bäume.
Die Klasse TreeNode stellt Knoten im MCTS-Baum dar. Jeder Knoten entspricht einem Zustand im Suchprozess, der Folgendes enthält:
class TreeNode:
"""Represents a node in the MCTS tree."""
def __init__(self, state, parent=None):
self.state = state # Current state
self.parent = parent
self.children = []
self.visits = 0
self.q_value = 0.0 # Accumulated rewards
def is_fully_expanded(self):
return len(self.children) > 0
def best_child(self, exploration_weight=1.4):
"""Select the best child using UCT formula."""
def uct_value(child):
return (child.q_value / (child.visits + 1e-6)) + exploration_weight * np.sqrt(np.log(self.visits + 1) / (child.visits + 1e-6))
return max(self.children, key=uct_value)
def add_child(self, child_state):
"""Add a child node with the given state."""
child = TreeNode(state=child_state, parent=self)
self.children.append(child)
return childNachdem wir nun die Grundstruktur festgelegt haben, werden wir als Nächstes mit den Kernkomponenten der Demo arbeiten.
Die Klasse MathSolver ist das Herzstück der Demo und kombiniert symbolisches Denken mit neural-geführter Suche. Es enthält mehrere Schlüsselkomponenten:
Die PolicyModel sagt die nächsten Schritte zur Lösung von Gleichungen voraus, während die RewardModel den Erfolg von Teil- oder Komplettlösungen bewertet.
class MathSolver:
def __init__(self, dataset=None):
self.dataset = dataset or [] # Dataset of math problems
self.policy_model = PolicyModel(input_size=128, hidden_size=64, output_size=4)
self.reward_model = RewardModel(input_size=128, hidden_size=64, output_size=1)
self.policy_optimizer = optim.Adam(self.policy_model.parameters(), lr=0.001)
self.reward_optimizer = optim.Adam(self.reward_model.parameters(), lr=0.001)
self.execution_context = {} Die obige Methode initialisiert die Klasse MathSolver, indem sie die Komponenten einrichtet, die zum Lösen mathematischer Probleme benötigt werden. Es akzeptiert optional einen Datensatz mit mathematischen Problemen und initialisiert zwei neuronale Netze: das Politikmodell, das die nächste Aktion vorhersagt, und das Belohnungsmodell, das den Erfolg von Aktionen bewertet .
Wir haben jetzt eine Politik- und Belohnungsfunktion eingerichtet. Als Nächstes müssen wir die Eingangsgleichungen analysieren und kodieren.
Die Gleichungen werden mit sympy geparst und in Merkmalsvektoren kodiert, die von den Richtlinien- und Belohnungsmodellen verarbeitet werden.
def encode_problem(self, problem):
# Advanced encoding using symbolic representation and problem length
variables = len(re.findall(r'[a-zA-Z]', problem))
operators = len(re.findall(r'[\+\-\*/\^]', problem))
problem_length = len(problem)
return np.array([variables, operators, problem_length] + [0] * 125)Die Methode encode_problem wandelt ein mathematisches Problem in eine numerische Darstellung mit fester Größe für die Modelle um. Sie extrahiert Merkmale wie die Anzahl der Variablen, Operatoren und die Problemlänge und kodiert sie in ein 128-dimensionales NumPy-Array. Diese Darstellung erfasst die Struktur des Problems und ermöglicht eine effektive Modellverarbeitung.
Der folgende Code generiert die nächsten Schritte zum Lösen der gegebenen Gleichungen, einschließlich der Definition der Variablen, der Erstellung der Gleichungen und der Lösung der Gleichungen.
def policy_model_predict(self, equation1, equation2=None):
try:
equations = []
if equation1:
equations.append(sympify(equation1.strip())) # Sympify only equations
if equation2:
equations.append(sympify(equation2.strip()))
all_variables = set()
for eq in equations:
all_variables.update(eq.free_symbols)
var_definitions = [f"{v} = symbols('{v}')" for v in all_variables]
steps = [
("Define variables", "\n".join(var_definitions)),
("Define equation(s)", f"equations = {equations}"),
("Solve equation(s)", f"solution = solve(equations, {list(all_variables)})"),
("Print solution", "print(solution)")
]
return steps
except Exception as e:
print(f"Error during policy model prediction: {e}")
return []Die Funktion policy_model_predict analysiert die eingegebenen Gleichungen mit Hilfe von SymPy's sympify, um sicherzustellen, dass es sich um gültige mathematische Ausdrücke handelt. Dann identifiziert es alle Variablen in den Gleichungen und löst sie mit der SymPy-Funktion solve. Diese Methode dient als Leitfaden für den Problemlösungsprozess.
Die Methode reward_model_predict spielt beim Reinforcement Learning eine wichtige Rolle, da sie Rückmeldungen zu den Aktionen gibt, die während der Monte Carlo Tree Search (MCTS) ausgeführt werden.
def reward_model_predict(self, steps, success):
encoded_steps = self.encode_problem(str(steps))
encoded_steps = torch.tensor(encoded_steps, dtype=torch.float32)
reward = self.reward_model(encoded_steps)
return reward.item() if success else -reward.item()Die Funktion kodiert Problemlösungsschritte in einem numerischen Format und bewertet sie durch das Belohnungsmodell, wobei eine positive Belohnung für Erfolg und eine negative Belohnung für Misserfolg zurückgegeben wird. Dieses Feedback trainiert das Politikmodell und hilft ihm, effektive Maßnahmen zu priorisieren und die Entscheidungsfindung zu verbessern. Nachdem wir die Vorhersagefunktionen für die Richtlinien und das Belohnungsmodell festgelegt haben, können wir jetzt an der Ausführungsaufgabe arbeiten.
Diese Methode behandelt mehrvariable Lösungen als Tupel oder Wörterbücher und wandelt symbolische Ergebnisse mit der N Funktion von SymPy in numerische Näherungen um.
def execute_code(self, code):
try:
# Ensure necessary imports and variables are in the execution context
exec("from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E", self.execution_context)
# Dynamically initialize variables in the context
for var_def in self.execution_context.get('var_definitions', []):
exec(var_def, self.execution_context)
exec(code, self.execution_context)
if "solution" in self.execution_context:
symbolic_solution = self.execution_context["solution"]
# Handle multi-variable solutions as tuples
if isinstance(symbolic_solution, list):
self.execution_context["solution"] = [tuple(map(N, sol)) if isinstance(sol, tuple) else N(sol) for sol in symbolic_solution]
elif isinstance(symbolic_solution, dict):
self.execution_context["solution"] = {k: N(v) for k, v in symbolic_solution.items()}
else:
self.execution_context["solution"] = N(symbolic_solution)
return True
except Exception as e:
print(f"Error executing code: {e}")
return FalseDiese Methode gewährleistet eine genaue Berechnung und ermöglicht einen flexiblen Umgang mit verschiedenen Lösungsformaten. Im Falle von Fehlern protokolliert es das Problem und gibt False zurück, um eine robuste Fehlerbehandlung zu gewährleisten.
Die MCTS-Methode wählt iterativ die besten Zustände aus, erweitert den Suchbaum und simuliert mögliche Lösungen. Belohnungen aus Simulationen werden zurückgespielt, um die Entscheidungsfindung zu verbessern.
def mcts(self, equation1, equation2=None, num_rollouts=10):
root = TreeNode(state=(equation1, equation2))
for _ in range(num_rollouts):
# Selection
node = root
while node.is_fully_expanded() and node.children:
node = node.best_child()
# Expansion
if not node.is_fully_expanded():
steps = self.policy_model_predict(*node.state)
for step, code in steps:
child_state = (step, code)
node.add_child(child_state)
# Simulation
success = True
for step, code in steps:
if not self.execute_code(code):
success = False
break
# Backpropagation
reward = self.reward_model_predict(steps, success)
while node:
node.visits += 1
node.q_value += reward
node = node.parent
return root.best_child().state if root.children else NoneDie Methode mcts führt iterativ vier wichtige Schritte durch :
policy_model_predict neue Unterknoten erstellt.reward_model_predict berechnet und im Baum nach oben weitergegeben, um die Knotenwerte zu aktualisieren . Nach einer bestimmten Anzahl von Rollouts gibt die Methode den Status des besten untergeordneten Knotens zurück, der die vielversprechendste Lösung darstellt, die während der Suche untersucht wurde.
Die lösen Methode steuert den gesamten Prozess, vom Parsen der Gleichungen bis zum Ausführen und Validieren der Lösungen.
def solve(self, equation1, equation2=None):
self.execution_context = {}
steps = self.policy_model_predict(equation1, equation2)
variables = set()
for eq in [equation1, equation2] if equation2 else [equation1]:
if eq:
variables.update(sympify(eq.strip()).free_symbols)
self.execution_context['var_definitions'] = [f"{v} = symbols('{v}')" for v in variables]
steps_output = ["Best solution found:"]
for step, code in steps:
steps_output.append(f"Step: {step}")
steps_output.append(f"Code: {code}")
if self.execute_code(code):
steps_output.append("Execution successful.")
else:
steps_output.append("Execution failed.")
if "solution" in self.execution_context:
final_answer = self.execution_context["solution"]
if isinstance(final_answer, dict):
for var, value in final_answer.items():
steps_output.append(f"{var} = {value}")
elif isinstance(final_answer, list):
for solution in final_answer:
if isinstance(solution, tuple):
for idx, var in enumerate(variables):
steps_output.append(f"{list(variables)[idx]} = {solution[idx]}")
else:
steps_output.append(f"Solution: {solution}")
else:
steps_output.append(f"Final Answer: {final_answer}")
else:
steps_output.append("No final answer found.")
return "\n".join(steps_output)Die Methode solve verarbeitet eine oder zwei vom Benutzer bereitgestellte Gleichungen, indem sie einen Ausführungskontext initialisiert und Schritte über policy_model_predict erzeugt. Sie führt jeden Schritt aus, protokolliert den Fortschritt und meldet Erfolg oder Misserfolg. Die Lösungen, einschließlich der ein- und mehrvariablen Ergebnisse, werden zur besseren Übersichtlichkeit mit Variablennamen und -werten formatiert. Wenn keine Lösung gefunden wird, wird eine entsprechende Meldung angezeigt.
Alle Kernkomponenten sind vorhanden, sodass wir als Nächstes an der Gradio-App arbeiten können.
Über die Gradio-Oberfläche kannst du eine oder mehrere Gleichungen eingeben, sie lösen und die Ergebnisse interaktiv betrachten.
with gr.Blocks() as app:
gr.Markdown("# Math Problem Solver with Advanced Multi-Step Reasoning and Learning")
with gr.Row():
equation1_input = gr.Textbox(label="Enter the first equation (e.g., x + y - 3)", placeholder="x + y - 3")
equation2_input = gr.Textbox(label="Enter the second equation (optional, e.g., x - y - 1)", placeholder="x - y - 1")
solve_button = gr.Button("Solve")
solution_output = gr.Textbox(label="Solution", interactive=False)
solve_button.click(solve_math_problem, inputs=[equation1_input, equation2_input], outputs=[solution_output])
app.launch(debug=True)Der obige Code erstellt eine Gradio-Benutzeroberfläche zum Lösen von mathematischen Gleichungen mit fortgeschrittener Argumentation. Die Schnittstelle ist in einem gr.Blocks Container verpackt, der zwei Eingabefelder mit gr.Textbox enthält: eines für die erste Gleichung (obligatorisch) und eines für die zweite Gleichung (optional).
Die Ausgabe wird in einem einzigen gr.Textbox mit der Bezeichnung "Solution" angezeigt. Der Befehl interface.launch() startet die Gradio-App in einem Browser, und das Flag debug=True ermöglicht detaillierte Protokolle, die bei der Fehlersuche helfen.
Es ist an der Zeit, unsere Mathe-Problemlöser-App zu testen. Hier sind einige Tests, die ich durchgeführt habe:
1. Einzelne Variable einzelne Gleichung: Ich habe versucht, die möglichen Werte einer einzelnen Variable x zu finden, wenn eine einzelne Gleichung als Eingabe vorliegt.
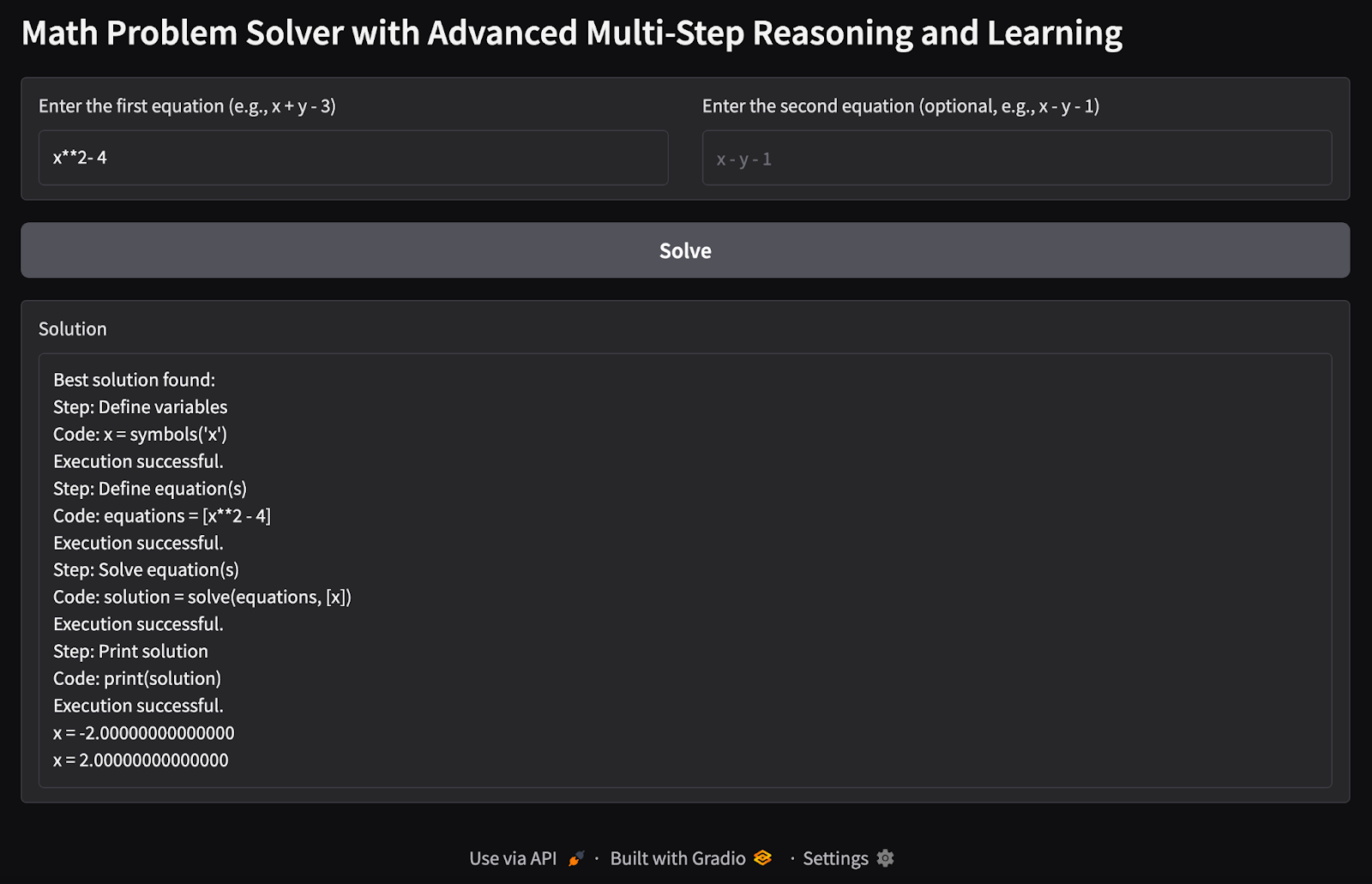
2. Problem mit mehreren Variablen und mehreren Gleichungen: Ich habe zwei Gleichungen mit zwei Variablen eingegeben, um mögliche Werte der Variablen x und y zu finden.

Diese Demo ist eine Basisversion dessen, was wir mit den Möglichkeiten der rStar-math-Methode erreichen können. Es gibt noch viel zu tun, um seine Möglichkeiten zu erweitern.
Du kannst das Original-Repository des rStar-math Papiers auf GitHub.
Diese Demo zeigt eine praktische Umsetzung des mehrstufigen Denkens zum Lösen mathematischer Gleichungen. Durch die Kombination von neuronalen Netzen, symbolischem Denken und MCTS gibt es einen Einblick, wie fortschrittliche KI-Techniken strukturierte Denkaufgaben bewältigen können. Zukünftige Erweiterungen könnten es näher an die vollen Möglichkeiten des RStar-Frameworks heranbringen.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
