
Programa
Desenvolvimento de aplicativos de IA
21 h
Microsoft RStar-math da Microsoft apresenta uma abordagem inovadora para resolver problemas matemáticos usando uma combinação de aprendizado por reforço, raciocínio simbólico e Monte Carlo Tree Search (MCTS).
Neste blog, explorarei a estrutura do RStar e seus principais componentes. Em seguida, guiarei você passo a passo por uma implementação simplificada que demonstra os principais conceitos usando o Gradio. Embora esta demonstração seja inspirada no documento, algumas complexidades foram simplificadas para facilitar a acessibilidade.
O objetivo da matemática RStar é unir o raciocínio simbólico aos recursos de generalização dos modelos neurais pré-treinados. A estrutura integra componentes como o Monte Carlo Tree Search (MCTS), modelos de linguagem pré-treinados e aprendizado por reforço para permitir a exploração eficiente de estratégias de solução de problemas.
A ideia central é representar o raciocínio matemático como um processo de pesquisa em uma árvore estruturada de etapas possíveis, em que cada nó representa uma solução parcial ou um estado.
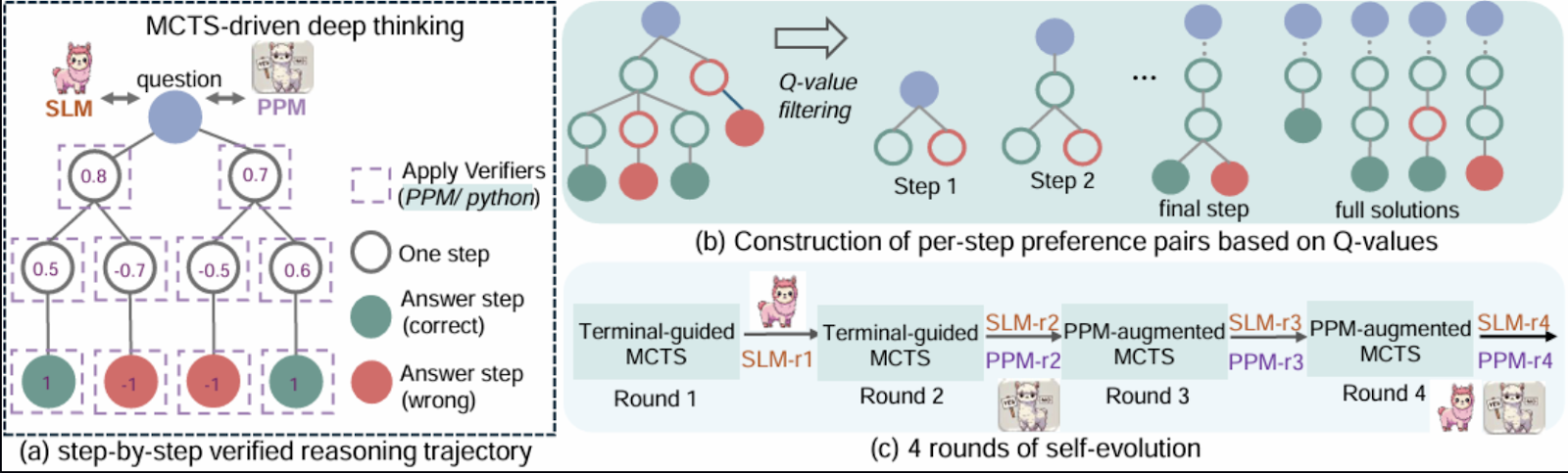
Fonte: Guan et al., 2025
Alguns dos motivos que tornam o rStar-Math particularmente interessante para mim são:
A demonstração mostra como um modelo de política e um modelo de recompensa, combinados com o raciocínio simbólico usando a biblioteca sympy , podem lidar com problemas matemáticos de forma estruturada. Os principais recursos dessa implementação incluem:
Para manter a demonstração simples e focada, alguns recursos avançados apontados no documento estão fora do escopo deste tutorial. Esses recursos são:
A demonstração é dividida em vários componentes, cada um refletindo uma parte da metodologia RStar. Antes de começarmos, verifique se você tem os seguintes itens instalados:
pip install requests gradio, sympy Em seguida, importe essas bibliotecas:
import gradio as gr
import numpy as np
import torch
import re
import torch.nn as nn
import torch.optim as optim
from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E, sympify
from random import choiceAgora que todas as dependências estão instaladas, vamos configurar os componentes principais.
Essas redes são versões leves dos modelos descritos no artigo, usadas para prever a próxima ação e avaliar o sucesso. O modelo de política prevê as próximas etapas para resolver as equações fornecidas. Ele usa uma rede neural feedforward para processar representações codificadas do problema.
Da mesma forma, o modelo de recompensa avalia soluções parciais para orientar o processo MCTS. Ambos os modelos são implementados usando o PyTorch.
class PolicyModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
class RewardModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return xEm seguida, criamos uma classe de nós para árvores MCTS.
A classe TreeNode representa os nós na árvore MCTS. Cada nó corresponde a um estado no processo de pesquisa, contendo:
class TreeNode:
"""Represents a node in the MCTS tree."""
def __init__(self, state, parent=None):
self.state = state # Current state
self.parent = parent
self.children = []
self.visits = 0
self.q_value = 0.0 # Accumulated rewards
def is_fully_expanded(self):
return len(self.children) > 0
def best_child(self, exploration_weight=1.4):
"""Select the best child using UCT formula."""
def uct_value(child):
return (child.q_value / (child.visits + 1e-6)) + exploration_weight * np.sqrt(np.log(self.visits + 1) / (child.visits + 1e-6))
return max(self.children, key=uct_value)
def add_child(self, child_state):
"""Add a child node with the given state."""
child = TreeNode(state=child_state, parent=self)
self.children.append(child)
return childAgora que já temos a estrutura básica pronta, trabalharemos com os componentes principais da demonstração.
A classe MathSolver é o núcleo da demonstração, combinando raciocínio simbólico com pesquisa orientada por neural. Ele implementa vários componentes-chave:
O PolicyModel prevê as próximas etapas para resolver equações, enquanto o RewardModel avalia o sucesso de soluções parciais ou completas.
class MathSolver:
def __init__(self, dataset=None):
self.dataset = dataset or [] # Dataset of math problems
self.policy_model = PolicyModel(input_size=128, hidden_size=64, output_size=4)
self.reward_model = RewardModel(input_size=128, hidden_size=64, output_size=1)
self.policy_optimizer = optim.Adam(self.policy_model.parameters(), lr=0.001)
self.reward_optimizer = optim.Adam(self.reward_model.parameters(), lr=0.001)
self.execution_context = {} O método acima inicializa a classe MathSolver configurando os componentes necessários para resolver problemas matemáticos. Opcionalmente, ele aceita um conjunto de dados de problemas matemáticos e inicializa duas redes neurais: omodelo de política , que prevê a próxima ação, e o modelo de recompensa, que avalia o sucesso das ações .
Agora temos uma política e uma função de recompensa em vigor. Em seguida, precisamos analisar e codificar as equações de entrada.
As equações são analisadas usando o site sympy e codificadas em vetores de recursos para processamento pelos modelos de política e recompensa.
def encode_problem(self, problem):
# Advanced encoding using symbolic representation and problem length
variables = len(re.findall(r'[a-zA-Z]', problem))
operators = len(re.findall(r'[\+\-\*/\^]', problem))
problem_length = len(problem)
return np.array([variables, operators, problem_length] + [0] * 125)O método encode_problem converte um problema matemático em uma representação numérica de tamanho fixo para os modelos. Ele extrai recursos como o número de variáveis, operadores e comprimento do problema, codificando-os em uma matriz NumPy de 128 dimensões. Essa representação captura a estrutura do problema, permitindo o processamento eficaz do modelo.
O código a seguir gera as próximas etapas para resolver as equações fornecidas, incluindo a definição de variáveis, a criação de equações e a resolução delas.
def policy_model_predict(self, equation1, equation2=None):
try:
equations = []
if equation1:
equations.append(sympify(equation1.strip())) # Sympify only equations
if equation2:
equations.append(sympify(equation2.strip()))
all_variables = set()
for eq in equations:
all_variables.update(eq.free_symbols)
var_definitions = [f"{v} = symbols('{v}')" for v in all_variables]
steps = [
("Define variables", "\n".join(var_definitions)),
("Define equation(s)", f"equations = {equations}"),
("Solve equation(s)", f"solution = solve(equations, {list(all_variables)})"),
("Print solution", "print(solution)")
]
return steps
except Exception as e:
print(f"Error during policy model prediction: {e}")
return []A função policy_model_predict analisa as equações de entrada usando o sympify do SymPy para garantir que sejam expressões matemáticas válidas. Em seguida, ele identifica todas as variáveis presentes nas equações e as resolve usando a função solve do SymPy. Esse método serve como um guia de alto nível para o fluxo de trabalho de solução de problemas.
O método reward_model_predict desempenha um papel fundamental no aprendizado por reforço, fornecendo feedback para as ações realizadas durante as implementações do Monte Carlo Tree Search (MCTS).
def reward_model_predict(self, steps, success):
encoded_steps = self.encode_problem(str(steps))
encoded_steps = torch.tensor(encoded_steps, dtype=torch.float32)
reward = self.reward_model(encoded_steps)
return reward.item() if success else -reward.item()A função codifica as etapas de solução de problemas em um formato numérico e as avalia por meio do modelo de recompensa, retornando uma recompensa positiva para o sucesso e uma recompensa negativa para o fracasso. Esse feedback treina o modelo de política, orientando-o para priorizar ações eficazes e melhorar a tomada de decisões. Com a política e as funções de previsão do modelo de recompensa implementadas, podemos agora trabalhar na tarefa de execução.
Esse método lida com soluções multivariáveis como tuplas ou dicionários e converte resultados simbólicos em aproximações numéricas usando a função N do SymPy.
def execute_code(self, code):
try:
# Ensure necessary imports and variables are in the execution context
exec("from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E", self.execution_context)
# Dynamically initialize variables in the context
for var_def in self.execution_context.get('var_definitions', []):
exec(var_def, self.execution_context)
exec(code, self.execution_context)
if "solution" in self.execution_context:
symbolic_solution = self.execution_context["solution"]
# Handle multi-variable solutions as tuples
if isinstance(symbolic_solution, list):
self.execution_context["solution"] = [tuple(map(N, sol)) if isinstance(sol, tuple) else N(sol) for sol in symbolic_solution]
elif isinstance(symbolic_solution, dict):
self.execution_context["solution"] = {k: N(v) for k, v in symbolic_solution.items()}
else:
self.execution_context["solution"] = N(symbolic_solution)
return True
except Exception as e:
print(f"Error executing code: {e}")
return FalseEsse método garante cálculos precisos e permite o manuseio flexível de vários formatos de solução. Em caso de erros, ele registra o problema e retorna False, mantendo um tratamento robusto de erros.
O método MCTS seleciona iterativamente os melhores estados, expande a árvore de pesquisa e simula possíveis soluções. As recompensas das simulações são retropropagadas para melhorar a tomada de decisões.
def mcts(self, equation1, equation2=None, num_rollouts=10):
root = TreeNode(state=(equation1, equation2))
for _ in range(num_rollouts):
# Selection
node = root
while node.is_fully_expanded() and node.children:
node = node.best_child()
# Expansion
if not node.is_fully_expanded():
steps = self.policy_model_predict(*node.state)
for step, code in steps:
child_state = (step, code)
node.add_child(child_state)
# Simulation
success = True
for step, code in steps:
if not self.execute_code(code):
success = False
break
# Backpropagation
reward = self.reward_model_predict(steps, success)
while node:
node.visits += 1
node.q_value += reward
node = node.parent
return root.best_child().state if root.children else NoneO método mcts executa iterativamente quatro etapas principais :
policy_model_predict.reward_model_predict e propagadas pela árvore para atualizar os valores dos nós . Após um número especificado de implementações, o método retorna o estado do melhor nó filho, representando a solução mais promissora explorada durante a pesquisa.
O solve orquestra todo o processo, desde a análise das equações até a execução e a validação das soluções.
def solve(self, equation1, equation2=None):
self.execution_context = {}
steps = self.policy_model_predict(equation1, equation2)
variables = set()
for eq in [equation1, equation2] if equation2 else [equation1]:
if eq:
variables.update(sympify(eq.strip()).free_symbols)
self.execution_context['var_definitions'] = [f"{v} = symbols('{v}')" for v in variables]
steps_output = ["Best solution found:"]
for step, code in steps:
steps_output.append(f"Step: {step}")
steps_output.append(f"Code: {code}")
if self.execute_code(code):
steps_output.append("Execution successful.")
else:
steps_output.append("Execution failed.")
if "solution" in self.execution_context:
final_answer = self.execution_context["solution"]
if isinstance(final_answer, dict):
for var, value in final_answer.items():
steps_output.append(f"{var} = {value}")
elif isinstance(final_answer, list):
for solution in final_answer:
if isinstance(solution, tuple):
for idx, var in enumerate(variables):
steps_output.append(f"{list(variables)[idx]} = {solution[idx]}")
else:
steps_output.append(f"Solution: {solution}")
else:
steps_output.append(f"Final Answer: {final_answer}")
else:
steps_output.append("No final answer found.")
return "\n".join(steps_output)O método solve processa uma ou duas equações fornecidas pelo usuário, inicializando um contexto de execução e gerando etapas via policy_model_predict. Ele executa cada etapa, registra o progresso e relata o sucesso ou a falha. As soluções, incluindo resultados simples e multivariáveis, são formatadas com nomes e valores de variáveis para maior clareza. Se nenhuma solução for encontrada, uma mensagem apropriada será exibida.
Temos todos os componentes principais instalados, portanto, podemos trabalhar no aplicativo Gradio em seguida.
A interface do Gradio permite que os usuários insiram equações (uma ou mais), resolvam-nas e visualizem os resultados de forma interativa.
with gr.Blocks() as app:
gr.Markdown("# Math Problem Solver with Advanced Multi-Step Reasoning and Learning")
with gr.Row():
equation1_input = gr.Textbox(label="Enter the first equation (e.g., x + y - 3)", placeholder="x + y - 3")
equation2_input = gr.Textbox(label="Enter the second equation (optional, e.g., x - y - 1)", placeholder="x - y - 1")
solve_button = gr.Button("Solve")
solution_output = gr.Textbox(label="Solution", interactive=False)
solve_button.click(solve_math_problem, inputs=[equation1_input, equation2_input], outputs=[solution_output])
app.launch(debug=True)O código acima cria uma interface de usuário Gradio para resolver equações matemáticas com raciocínio avançado. A interface é envolvida em um contêiner gr.Blocks, que contém dois campos de entrada usando gr.Textbox: um para a primeira equação (obrigatória) e outro para a segunda equação (opcional).
A saída é exibida em um único gr.Textbox rotulado como "Solution". O comando interface.launch() inicia o aplicativo Gradio em um navegador e o sinalizador debug=True permite registros detalhados para ajudar a solucionar erros.
Chegou a hora de você testar nosso aplicativo Math Problem Solver. Aqui estão alguns testes que realizei:
1. Equação única de variável única: Tentei encontrar os valores possíveis de uma única variável x com uma única equação como entrada.
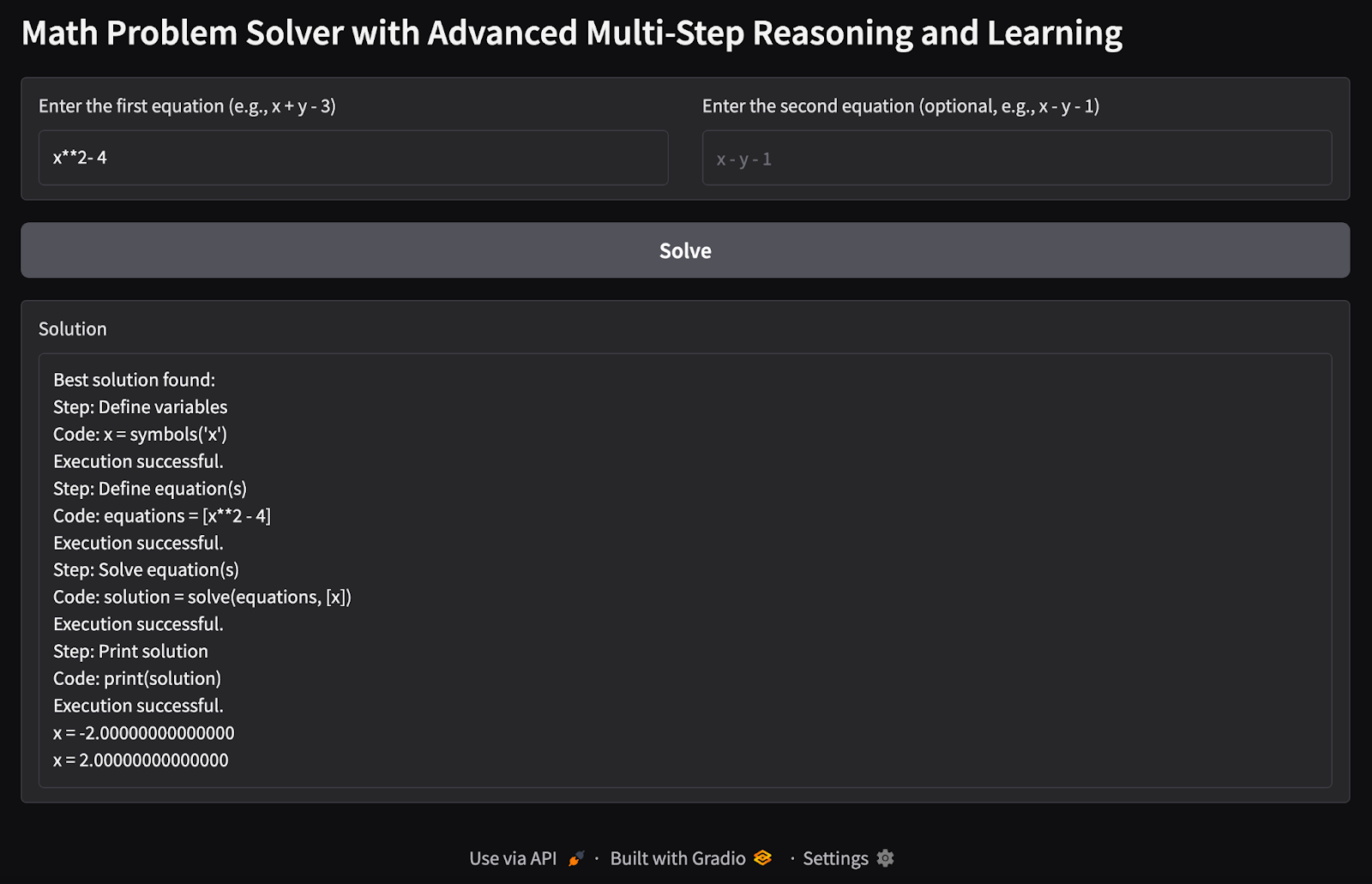
2. Problema de equações múltiplas com várias variáveis: Passei em duas equações com problemas de duas variáveis para encontrar os valores possíveis das variáveis x e y.

Esta demonstração é uma versão básica do que podemos obter com os recursos do método rStar-math. Ainda há muito trabalho que pode ser feito para ampliar seus recursos.
Você pode consultar o repositório original do artigo rStar-math no GitHub.
Esta demonstração mostra uma implementação prática de raciocínio em várias etapas para resolver equações matemáticas. Ao combinar redes neurais, raciocínio simbólico e MCTS, você terá uma ideia de como as técnicas avançadas de IA podem lidar com tarefas de raciocínio estruturado. Futuros aprimoramentos poderão aproximá-lo de todos os recursos da estrutura do RStar.
Aprenda IA com estes cursos!
Programa
Programa
Programa
blog
DataCamp Team
4 min
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Tutorial
Arunn Thevapalan



