
Cursus
Développer des applications d'IA
21 h
Microsoft's RStar-math de Microsoft présente une approche innovante de la résolution de problèmes mathématiques en combinant l'apprentissage par renforcement, le raisonnement symbolique et la recherche arborescente de Monte Carlo (MCTS).
Dans ce blog, je vais explorer le cadre RStar et ses principaux éléments. Je vous guiderai ensuite pas à pas dans une mise en œuvre simplifiée qui démontrera ses concepts clés à l'aide de Gradio. Bien que cette démo s'inspire de l'article, certaines complexités ont été simplifiées pour des raisons d'accessibilité.
Les mathématiques RStar visent à établir un lien entre le raisonnement symbolique et les capacités de généralisation des modèles neuronaux pré-entraînés. Le cadre intègre des composants tels que la recherche arborescente de Monte Carlo (MCTS), des modèles linguistiques pré-entraînés et l'apprentissage par renforcement. l'apprentissage par renforcement pour permettre une exploration efficace des stratégies de résolution de problèmes.
L'idée de base est de représenter le raisonnement mathématique comme un processus de recherche sur un arbre structuré d'étapes possibles, où chaque nœud représente une solution partielle ou un état.
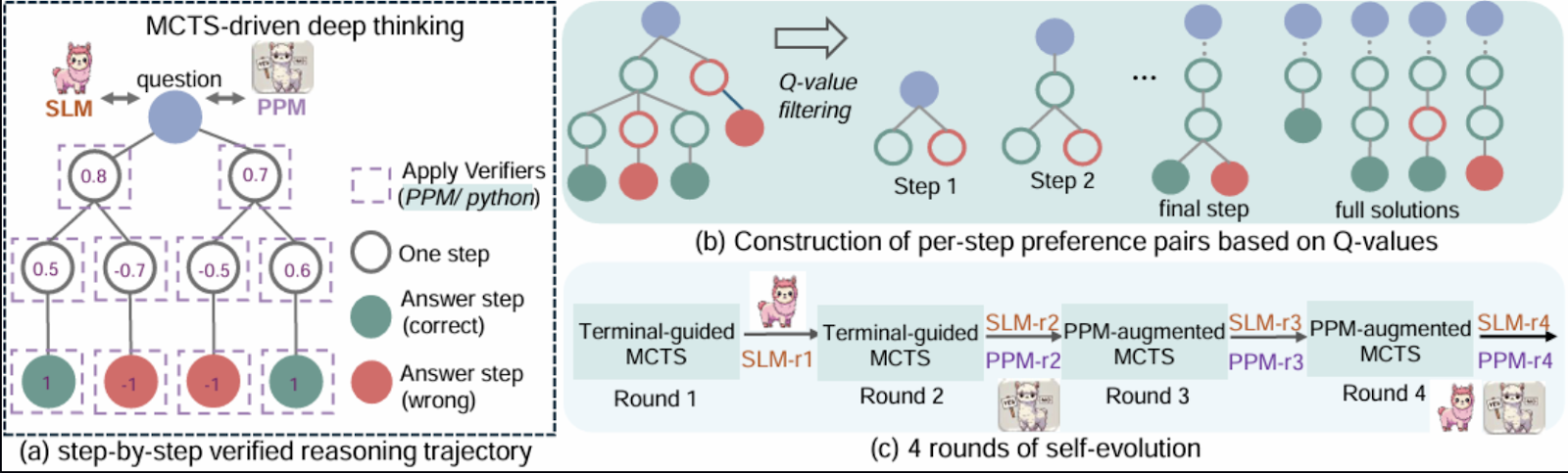
Source : Guan et al, 2025
Voici quelques-unes des raisons qui rendent rStar-Math particulièrement intéressant à mes yeux :
La démonstration montre comment un modèle de politique et un modèle de récompense, combinés à un raisonnement symbolique utilisant la bibliothèque sympy , peuvent résoudre des problèmes mathématiques de manière structurée. Les principales caractéristiques de cette mise en œuvre sont les suivantes
Pour que la démonstration reste simple et ciblée, certaines fonctionnalités avancées mentionnées dans le document dépassent le cadre de ce tutoriel. Ces caractéristiques sont les suivantes :
La démonstration est divisée en plusieurs éléments, chacun reflétant une partie de la méthodologie RStar. Avant de commencer, assurez-vous que les éléments suivants sont installés :
pip install requests gradio, sympy Importez ensuite ces bibliothèques :
import gradio as gr
import numpy as np
import torch
import re
import torch.nn as nn
import torch.optim as optim
from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E, sympify
from random import choiceMaintenant que toutes les dépendances sont installées, mettons en place les principaux composants.
Ces réseaux sont des versions allégées des modèles décrits dans l'article, utilisés pour prédire l'action suivante et évaluer le succès. Le modèle de politique prédit les étapes suivantes pour résoudre les équations données. Il utilise un réseau neuronal en amont pour traiter les représentations codées du problème.
De même, le modèle de récompense évalue les solutions partielles pour guider le processus des SCTM. Les deux modèles sont mis en œuvre à l'aide de PyTorch.
class PolicyModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
class RewardModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return xEnsuite, nous créons une classe de nœuds pour les arbres des SCTM.
La classe TreeNode représente les nœuds de l'arbre des SCTM. Chaque nœud correspond à un état dans le processus de recherche, contenant :
class TreeNode:
"""Represents a node in the MCTS tree."""
def __init__(self, state, parent=None):
self.state = state # Current state
self.parent = parent
self.children = []
self.visits = 0
self.q_value = 0.0 # Accumulated rewards
def is_fully_expanded(self):
return len(self.children) > 0
def best_child(self, exploration_weight=1.4):
"""Select the best child using UCT formula."""
def uct_value(child):
return (child.q_value / (child.visits + 1e-6)) + exploration_weight * np.sqrt(np.log(self.visits + 1) / (child.visits + 1e-6))
return max(self.children, key=uct_value)
def add_child(self, child_state):
"""Add a child node with the given state."""
child = TreeNode(state=child_state, parent=self)
self.children.append(child)
return childMaintenant que nous avons mis en place la structure de base, nous allons travailler sur les composants essentiels de la démo.
La classe MathSolver est le cœur de la démo, combinant le raisonnement symbolique et la recherche guidée par les neurones. Il met en œuvre plusieurs éléments clés :
Le site PolicyModel prédit les étapes suivantes pour résoudre les équations, tandis que le site RewardModel évalue la réussite des solutions partielles ou complètes.
class MathSolver:
def __init__(self, dataset=None):
self.dataset = dataset or [] # Dataset of math problems
self.policy_model = PolicyModel(input_size=128, hidden_size=64, output_size=4)
self.reward_model = RewardModel(input_size=128, hidden_size=64, output_size=1)
self.policy_optimizer = optim.Adam(self.policy_model.parameters(), lr=0.001)
self.reward_optimizer = optim.Adam(self.reward_model.parameters(), lr=0.001)
self.execution_context = {} La méthode ci-dessus initialise la classe MathSolver en mettant en place les composants nécessaires à la résolution de problèmes mathématiques. Il accepte en option un ensemble de données de problèmes mathématiques et initialise deux réseaux neuronaux : lemodèle de politique , qui prédit l'action suivante, et le modèle de récompense, qui évalue la réussite des actions.
Nous disposons désormais d'une politique et d'une fonction de récompense. Ensuite, nous devons analyser et coder les équations d'entrée.
Les équations sont analysées à l'aide de sympy et codées en vecteurs de caractéristiques pour être traitées par les modèles de politique et de récompense.
def encode_problem(self, problem):
# Advanced encoding using symbolic representation and problem length
variables = len(re.findall(r'[a-zA-Z]', problem))
operators = len(re.findall(r'[\+\-\*/\^]', problem))
problem_length = len(problem)
return np.array([variables, operators, problem_length] + [0] * 125)La méthode encode_problem convertit un problème mathématique en une représentation numérique de taille fixe pour les modèles. Il extrait des caractéristiques telles que le nombre de variables, d'opérateurs et la longueur du problème, en les encodant dans un tableau NumPy à 128 dimensions. Cette représentation capture la structure du problème, ce qui permet un traitement efficace du modèle.
Le code suivant génère les étapes suivantes de la résolution des équations données, y compris la définition des variables, la création des équations et leur résolution.
def policy_model_predict(self, equation1, equation2=None):
try:
equations = []
if equation1:
equations.append(sympify(equation1.strip())) # Sympify only equations
if equation2:
equations.append(sympify(equation2.strip()))
all_variables = set()
for eq in equations:
all_variables.update(eq.free_symbols)
var_definitions = [f"{v} = symbols('{v}')" for v in all_variables]
steps = [
("Define variables", "\n".join(var_definitions)),
("Define equation(s)", f"equations = {equations}"),
("Solve equation(s)", f"solution = solve(equations, {list(all_variables)})"),
("Print solution", "print(solution)")
]
return steps
except Exception as e:
print(f"Error during policy model prediction: {e}")
return []La fonction policy_model_predict analyse les équations d'entrée à l'aide de la fonction sympify de SymPy pour s'assurer qu'il s'agit d'expressions mathématiques valides. Il identifie ensuite toutes les variables présentes dans les équations et les résout à l'aide de la fonction SymPy solve. Cette méthode sert de guide de haut niveau pour le processus de résolution des problèmes.
La méthode reward_model_predict joue un rôle essentiel dans l'apprentissage par renforcement en fournissant un retour d'information sur les actions entreprises au cours des déploiements de la recherche arborescente de Monte Carlo (MCTS).
def reward_model_predict(self, steps, success):
encoded_steps = self.encode_problem(str(steps))
encoded_steps = torch.tensor(encoded_steps, dtype=torch.float32)
reward = self.reward_model(encoded_steps)
return reward.item() if success else -reward.item()La fonction encode les étapes de la résolution de problèmes dans un format numérique et les évalue par le biais du modèle de récompense, renvoyant une récompense positive en cas de succès et une récompense négative en cas d'échec. Ce retour d'information permet de former le modèle politique, en l'aidant à hiérarchiser les actions efficaces et à améliorer la prise de décision. Les fonctions de prédiction de la politique et du modèle de récompense étant en place, nous pouvons maintenant nous atteler à la tâche d'exécution.
Cette méthode traite les solutions multi-variables sous forme de tuples ou de dictionnaires et convertit les résultats symboliques en approximations numériques à l'aide de la fonction N de SymPy.
def execute_code(self, code):
try:
# Ensure necessary imports and variables are in the execution context
exec("from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E", self.execution_context)
# Dynamically initialize variables in the context
for var_def in self.execution_context.get('var_definitions', []):
exec(var_def, self.execution_context)
exec(code, self.execution_context)
if "solution" in self.execution_context:
symbolic_solution = self.execution_context["solution"]
# Handle multi-variable solutions as tuples
if isinstance(symbolic_solution, list):
self.execution_context["solution"] = [tuple(map(N, sol)) if isinstance(sol, tuple) else N(sol) for sol in symbolic_solution]
elif isinstance(symbolic_solution, dict):
self.execution_context["solution"] = {k: N(v) for k, v in symbolic_solution.items()}
else:
self.execution_context["solution"] = N(symbolic_solution)
return True
except Exception as e:
print(f"Error executing code: {e}")
return FalseCette méthode garantit la précision des calculs et permet une gestion souple des différents formats de solutions. En cas d'erreur, il enregistre le problème et renvoie False, ce qui permet de gérer les erreurs de manière efficace.
La méthode MCTS sélectionne itérativement les meilleurs états, étend l'arbre de recherche et simule les solutions possibles. Les récompenses obtenues lors des simulations sont rétro-propagées afin d'améliorer la prise de décision.
def mcts(self, equation1, equation2=None, num_rollouts=10):
root = TreeNode(state=(equation1, equation2))
for _ in range(num_rollouts):
# Selection
node = root
while node.is_fully_expanded() and node.children:
node = node.best_child()
# Expansion
if not node.is_fully_expanded():
steps = self.policy_model_predict(*node.state)
for step, code in steps:
child_state = (step, code)
node.add_child(child_state)
# Simulation
success = True
for step, code in steps:
if not self.execute_code(code):
success = False
break
# Backpropagation
reward = self.reward_model_predict(steps, success)
while node:
node.visits += 1
node.q_value += reward
node = node.parent
return root.best_child().state if root.children else NoneLa méthode mcts effectue quatre étapes clés de manière itérative :
policy_model_predict.reward_model_predict et propagées dans l'arbre pour mettre à jour les valeurs des nœuds . Après un nombre spécifié d'exécutions, la méthode renvoie l'état du meilleur nœud enfant, qui représente la solution la plus prometteuse explorée au cours de la recherche.
La résoudre orchestre l'ensemble du processus, depuis l'analyse des équations jusqu'à l'exécution et la validation des solutions.
def solve(self, equation1, equation2=None):
self.execution_context = {}
steps = self.policy_model_predict(equation1, equation2)
variables = set()
for eq in [equation1, equation2] if equation2 else [equation1]:
if eq:
variables.update(sympify(eq.strip()).free_symbols)
self.execution_context['var_definitions'] = [f"{v} = symbols('{v}')" for v in variables]
steps_output = ["Best solution found:"]
for step, code in steps:
steps_output.append(f"Step: {step}")
steps_output.append(f"Code: {code}")
if self.execute_code(code):
steps_output.append("Execution successful.")
else:
steps_output.append("Execution failed.")
if "solution" in self.execution_context:
final_answer = self.execution_context["solution"]
if isinstance(final_answer, dict):
for var, value in final_answer.items():
steps_output.append(f"{var} = {value}")
elif isinstance(final_answer, list):
for solution in final_answer:
if isinstance(solution, tuple):
for idx, var in enumerate(variables):
steps_output.append(f"{list(variables)[idx]} = {solution[idx]}")
else:
steps_output.append(f"Solution: {solution}")
else:
steps_output.append(f"Final Answer: {final_answer}")
else:
steps_output.append("No final answer found.")
return "\n".join(steps_output)La méthode solve traite une ou deux équations fournies par l'utilisateur en initialisant un contexte d'exécution et en générant des étapes via policy_model_predict. Il exécute chaque étape, enregistre la progression et signale le succès ou l'échec. Les solutions, y compris les résultats à une ou plusieurs variables, sont formatées avec les noms et les valeurs des variables pour plus de clarté. Si aucune solution n'est trouvée, un message approprié s'affiche.
Tous les composants de base étant en place, nous pouvons maintenant travailler sur l'application Gradio.
L'interface de Gradio permet aux utilisateurs de saisir des équations (une ou plusieurs), de les résoudre et de visualiser les résultats de manière interactive.
with gr.Blocks() as app:
gr.Markdown("# Math Problem Solver with Advanced Multi-Step Reasoning and Learning")
with gr.Row():
equation1_input = gr.Textbox(label="Enter the first equation (e.g., x + y - 3)", placeholder="x + y - 3")
equation2_input = gr.Textbox(label="Enter the second equation (optional, e.g., x - y - 1)", placeholder="x - y - 1")
solve_button = gr.Button("Solve")
solution_output = gr.Textbox(label="Solution", interactive=False)
solve_button.click(solve_math_problem, inputs=[equation1_input, equation2_input], outputs=[solution_output])
app.launch(debug=True)Le code ci-dessus crée une interface utilisateur Gradio pour la résolution d'équations mathématiques avec un raisonnement avancé. L'interface est enveloppée dans un conteneur gr.Blocks, qui contient deux champs de saisie utilisant gr.Textbox: un pour la première équation (obligatoire) et un autre pour la deuxième équation (facultative).
La sortie est affichée sur un seul site gr.Textbox intitulé "Solution". La commande interface.launch() lance l'application Gradio dans un navigateur, et le drapeau debug=True permet d'obtenir des journaux détaillés pour aider à résoudre les erreurs.
Il est temps de tester notre application de résolution de problèmes mathématiques. Voici quelques tests que j'ai effectués :
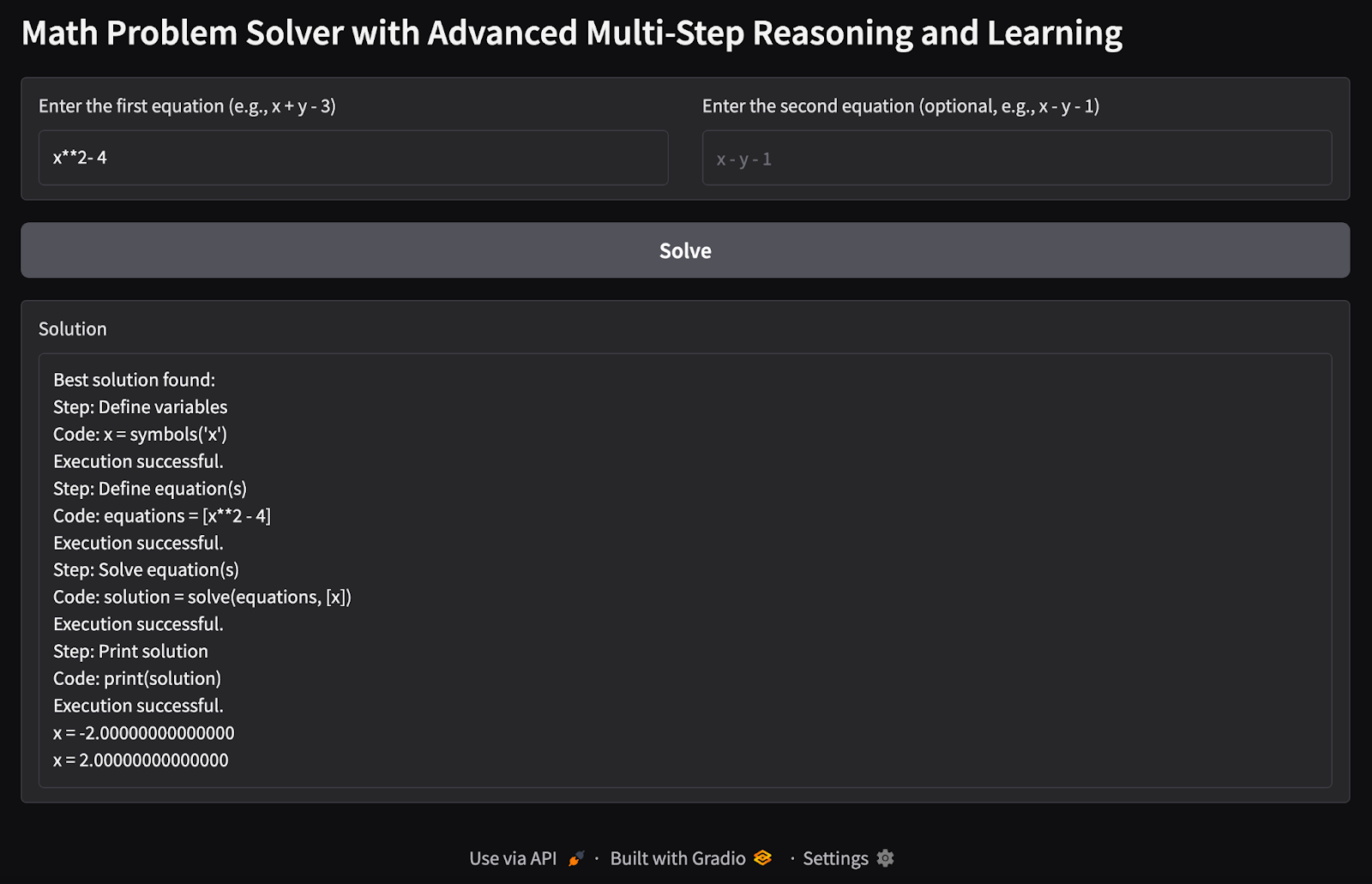
1. Variable unique équation unique: J'ai essayé de trouver les valeurs possibles d'une seule variable x à partir d'une seule équation.
2. Problème de variables multiples et d'équations multiples : J'ai passé des problèmes d'équations à deux variables pour trouver les valeurs possibles des variables x et y.

Cette démo est une version basique de ce que nous pouvons réaliser avec les capacités de la méthode rStar-math. Il y a encore beaucoup de travail à faire pour étendre ses capacités.
Vous pouvez consulter le dépôt original de l'article rStar-math sur GitHub.
Cette démo présente une mise en œuvre pratique du raisonnement en plusieurs étapes pour la résolution d'équations mathématiques. En combinant les réseaux neuronaux, le raisonnement symbolique et les SCTM, il donne un aperçu de la manière dont les techniques d'IA avancées peuvent s'attaquer aux tâches de raisonnement structuré. Des améliorations futures pourraient le rapprocher des capacités complètes du cadre RStar.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cursus