
programa
Desarrollo de aplicaciones de IA
21 h
Microsoft RStar-math presenta un enfoque innovador para resolver problemas matemáticos utilizando una combinación de aprendizaje por refuerzo, razonamiento simbólico y búsqueda en árbol Monte Carlo (MCTS).
En este blog, exploraré el marco RStar y sus componentes básicos. A continuación, te guiaré paso a paso a través de una implementación simplificada que demuestra sus conceptos clave utilizando Gradio. Aunque esta demostración se inspira en el documento, se han simplificado algunas complejidades para que sea más accesible.
La matemática RStar pretende tender un puente entre el razonamiento simbólico y las capacidades de generalización de los modelos neuronales preentrenados. El marco integra componentes como la Búsqueda en Árbol de Montecarlo (MCTS), modelos lingüísticos preentrenados y aprendizaje por refuerzo para permitir una exploración eficaz de las estrategias de resolución de problemas.
La idea central es representar el razonamiento matemático como un proceso de búsqueda sobre un árbol estructurado de posibles pasos, donde cada nodo representa una solución parcial o estado.
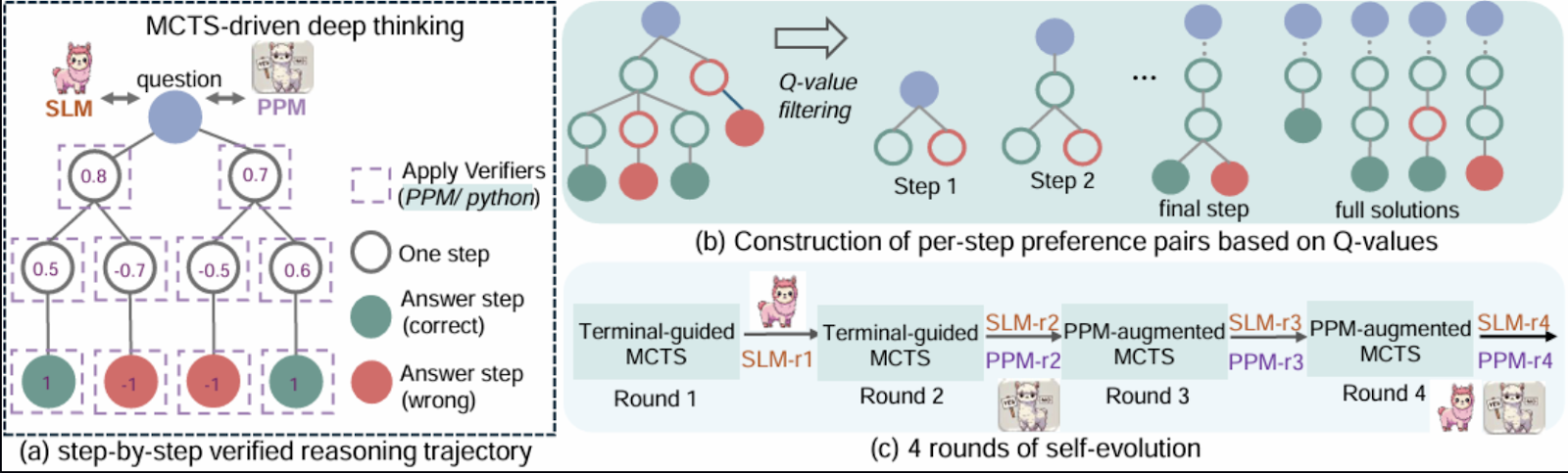
Fuente: Guan et al., 2025
Algunas de las razones que hacen que rStar-Math sea especialmente interesante para mí son:
La demo demuestra cómo un modelo de política y un modelo de recompensa, combinados con el razonamiento simbólico mediante la biblioteca sympy , pueden abordar problemas matemáticos de forma estructurada. Las características clave de esta implementación incluyen:
Para mantener la demostración sencilla y centrada, ciertas funciones avanzadas señaladas en el documento quedan fuera del alcance de este tutorial. Esas características son:
La demo está dividida en varios componentes, cada uno de los cuales refleja una parte de la metodología RStar. Antes de empezar, asegúrate de que tienes instalado lo siguiente:
pip install requests gradio, sympy Después, importa estas bibliotecas:
import gradio as gr
import numpy as np
import torch
import re
import torch.nn as nn
import torch.optim as optim
from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E, sympify
from random import choiceAhora que todas las dependencias están instaladas, vamos a configurar los componentes principales.
Estas redes son versiones ligeras de los modelos descritos en el artículo, que se utilizan para predecir la siguiente acción y evaluar el éxito. El modelo político predice los siguientes pasos para resolver las ecuaciones dadas. Utiliza una red neuronal feedforward para procesar las representaciones codificadas del problema.
Del mismo modo, el modelo de recompensa evalúa las soluciones parciales para guiar el proceso MCTS. Ambos modelos se implementan utilizando PyTorch.
class PolicyModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
class RewardModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return xA continuación, construimos una clase de nodos para los árboles MCTS.
La clase TreeNode representa los nodos del árbol MCTS. Cada nodo corresponde a un estado del proceso de búsqueda, que contiene:
class TreeNode:
"""Represents a node in the MCTS tree."""
def __init__(self, state, parent=None):
self.state = state # Current state
self.parent = parent
self.children = []
self.visits = 0
self.q_value = 0.0 # Accumulated rewards
def is_fully_expanded(self):
return len(self.children) > 0
def best_child(self, exploration_weight=1.4):
"""Select the best child using UCT formula."""
def uct_value(child):
return (child.q_value / (child.visits + 1e-6)) + exploration_weight * np.sqrt(np.log(self.visits + 1) / (child.visits + 1e-6))
return max(self.children, key=uct_value)
def add_child(self, child_state):
"""Add a child node with the given state."""
child = TreeNode(state=child_state, parent=self)
self.children.append(child)
return childAhora que ya tenemos la estructura básica, trabajaremos a continuación con los componentes principales de la demo.
La clase MathSolver es el núcleo de la demo, ya que combina el razonamiento simbólico con la búsqueda guiada por neuronas. Implementa varios componentes clave:
El PolicyModel predice los siguientes pasos para resolver ecuaciones, mientras que el RewardModel evalúa el éxito de las soluciones parciales o completas.
class MathSolver:
def __init__(self, dataset=None):
self.dataset = dataset or [] # Dataset of math problems
self.policy_model = PolicyModel(input_size=128, hidden_size=64, output_size=4)
self.reward_model = RewardModel(input_size=128, hidden_size=64, output_size=1)
self.policy_optimizer = optim.Adam(self.policy_model.parameters(), lr=0.001)
self.reward_optimizer = optim.Adam(self.reward_model.parameters(), lr=0.001)
self.execution_context = {} El método anterior inicializa la clase MathSolver configurando los componentes necesarios para resolver problemas matemáticos. Opcionalmente, acepta un conjunto de datos de problemas matemáticos e inicializa dos redes neuronales: elmodelo de política , que predice la siguiente acción, y el modelo de recompensa, que evalúa el éxito de las acciones .
Ahora disponemos de una función de política y recompensa. A continuación, tenemos que analizar y codificar las ecuaciones de entrada.
Las ecuaciones se analizan mediante sympy y se codifican en vectores de características para que las procesen los modelos de política y recompensa.
def encode_problem(self, problem):
# Advanced encoding using symbolic representation and problem length
variables = len(re.findall(r'[a-zA-Z]', problem))
operators = len(re.findall(r'[\+\-\*/\^]', problem))
problem_length = len(problem)
return np.array([variables, operators, problem_length] + [0] * 125)El método encode_problem convierte un problema matemático en una representación numérica de tamaño fijo para los modelos. Extrae características como el número de variables, operadores y longitud del problema, codificándolas en una matriz NumPy de 128 dimensiones. Esta representación capta la estructura del problema, lo que permite un procesamiento eficaz del modelo.
El código siguiente genera los pasos siguientes para resolver las ecuaciones dadas, incluyendo la definición de variables, la creación de ecuaciones y su resolución.
def policy_model_predict(self, equation1, equation2=None):
try:
equations = []
if equation1:
equations.append(sympify(equation1.strip())) # Sympify only equations
if equation2:
equations.append(sympify(equation2.strip()))
all_variables = set()
for eq in equations:
all_variables.update(eq.free_symbols)
var_definitions = [f"{v} = symbols('{v}')" for v in all_variables]
steps = [
("Define variables", "\n".join(var_definitions)),
("Define equation(s)", f"equations = {equations}"),
("Solve equation(s)", f"solution = solve(equations, {list(all_variables)})"),
("Print solution", "print(solution)")
]
return steps
except Exception as e:
print(f"Error during policy model prediction: {e}")
return []La función policy_model_predict analiza las ecuaciones de entrada utilizando sympify de SymPy para asegurarse de que son expresiones matemáticas válidas. A continuación, identifica todas las variables presentes en las ecuaciones y resuélvelas utilizando la función solve de SymPy. Este método sirve de guía de alto nivel para el flujo de trabajo de resolución de problemas.
El método reward_model_predict desempeña un papel vital en el aprendizaje por refuerzo, ya que proporciona información sobre las acciones realizadas durante las tiradas de Búsqueda en Árbol de Montecarlo (MCTS).
def reward_model_predict(self, steps, success):
encoded_steps = self.encode_problem(str(steps))
encoded_steps = torch.tensor(encoded_steps, dtype=torch.float32)
reward = self.reward_model(encoded_steps)
return reward.item() if success else -reward.item()La función codifica los pasos de resolución del problema en un formato numérico y los evalúa mediante el modelo de recompensa, devolviendo una recompensa positiva por el éxito y una recompensa negativa por el fracaso. Esta información capacita al modelo político, guiándolo para priorizar las acciones eficaces y mejorar la toma de decisiones. Una vez establecidas las funciones de predicción de la política y del modelo de recompensa, ya podemos trabajar en la tarea de ejecución.
Este método maneja soluciones multivariables como tuplas o diccionarios y convierte los resultados simbólicos en aproximaciones numéricas utilizando la función N de SymPy.
def execute_code(self, code):
try:
# Ensure necessary imports and variables are in the execution context
exec("from sympy import symbols, Eq, solve, N, sin, cos, tan, exp, log, E", self.execution_context)
# Dynamically initialize variables in the context
for var_def in self.execution_context.get('var_definitions', []):
exec(var_def, self.execution_context)
exec(code, self.execution_context)
if "solution" in self.execution_context:
symbolic_solution = self.execution_context["solution"]
# Handle multi-variable solutions as tuples
if isinstance(symbolic_solution, list):
self.execution_context["solution"] = [tuple(map(N, sol)) if isinstance(sol, tuple) else N(sol) for sol in symbolic_solution]
elif isinstance(symbolic_solution, dict):
self.execution_context["solution"] = {k: N(v) for k, v in symbolic_solution.items()}
else:
self.execution_context["solution"] = N(symbolic_solution)
return True
except Exception as e:
print(f"Error executing code: {e}")
return FalseEste método garantiza un cálculo preciso y admite el manejo flexible de varios formatos de solución. En caso de error, registra la incidencia y devuelve False, manteniendo un tratamiento robusto de los errores.
El método MCTS selecciona iterativamente los mejores estados, amplía el árbol de búsqueda y simula las posibles soluciones. Las recompensas de las simulaciones se retropropagan para mejorar la toma de decisiones.
def mcts(self, equation1, equation2=None, num_rollouts=10):
root = TreeNode(state=(equation1, equation2))
for _ in range(num_rollouts):
# Selection
node = root
while node.is_fully_expanded() and node.children:
node = node.best_child()
# Expansion
if not node.is_fully_expanded():
steps = self.policy_model_predict(*node.state)
for step, code in steps:
child_state = (step, code)
node.add_child(child_state)
# Simulation
success = True
for step, code in steps:
if not self.execute_code(code):
success = False
break
# Backpropagation
reward = self.reward_model_predict(steps, success)
while node:
node.visits += 1
node.q_value += reward
node = node.parent
return root.best_child().state if root.children else NoneEl método mcts realiza iterativamente cuatro pasos clave :
policy_model_predict.reward_model_predict y se propagan por el árbol para actualizar los valores de los nodos . Tras un número determinado de tiradas, el método devuelve el estado del mejor nodo hijo, que representa la solución más prometedora explorada durante la búsqueda.
En resolver orquesta todo el proceso, desde el análisis sintáctico de las ecuaciones hasta la ejecución y validación de las soluciones.
def solve(self, equation1, equation2=None):
self.execution_context = {}
steps = self.policy_model_predict(equation1, equation2)
variables = set()
for eq in [equation1, equation2] if equation2 else [equation1]:
if eq:
variables.update(sympify(eq.strip()).free_symbols)
self.execution_context['var_definitions'] = [f"{v} = symbols('{v}')" for v in variables]
steps_output = ["Best solution found:"]
for step, code in steps:
steps_output.append(f"Step: {step}")
steps_output.append(f"Code: {code}")
if self.execute_code(code):
steps_output.append("Execution successful.")
else:
steps_output.append("Execution failed.")
if "solution" in self.execution_context:
final_answer = self.execution_context["solution"]
if isinstance(final_answer, dict):
for var, value in final_answer.items():
steps_output.append(f"{var} = {value}")
elif isinstance(final_answer, list):
for solution in final_answer:
if isinstance(solution, tuple):
for idx, var in enumerate(variables):
steps_output.append(f"{list(variables)[idx]} = {solution[idx]}")
else:
steps_output.append(f"Solution: {solution}")
else:
steps_output.append(f"Final Answer: {final_answer}")
else:
steps_output.append("No final answer found.")
return "\n".join(steps_output)El método solve procesa una o dos ecuaciones proporcionadas por el usuario inicializando un contexto de ejecución y generando pasos a través de policy_model_predict. Ejecuta cada paso, registra el progreso e informa del éxito o fracaso. Las soluciones, incluidos los resultados con una o varias variables, se formatean con los nombres y valores de las variables para mayor claridad. Si no se encuentra ninguna solución, se muestra un mensaje apropiado.
Ya tenemos todos los componentes básicos, así que ahora podemos trabajar en la aplicación Gradio.
La interfaz de Gradio permite a los usuarios introducir ecuaciones (una o varias), resolverlas y ver los resultados de forma interactiva.
with gr.Blocks() as app:
gr.Markdown("# Math Problem Solver with Advanced Multi-Step Reasoning and Learning")
with gr.Row():
equation1_input = gr.Textbox(label="Enter the first equation (e.g., x + y - 3)", placeholder="x + y - 3")
equation2_input = gr.Textbox(label="Enter the second equation (optional, e.g., x - y - 1)", placeholder="x - y - 1")
solve_button = gr.Button("Solve")
solution_output = gr.Textbox(label="Solution", interactive=False)
solve_button.click(solve_math_problem, inputs=[equation1_input, equation2_input], outputs=[solution_output])
app.launch(debug=True)El código anterior crea una interfaz de usuario Gradio para resolver ecuaciones matemáticas con razonamiento avanzado. La interfaz está envuelta en un contenedor gr.Blocks, que contiene dos campos de entrada que utilizan gr.Textbox: uno para la primera ecuación (obligatoria) y otro para la segunda (opcional).
El resultado se muestra en un único gr.Textbox etiquetado "Solution". El comando interface.launch() inicia la aplicación Gradio en un navegador, y la bandera debug=True habilita registros detallados para ayudar a solucionar errores.
Es hora de poner a prueba nuestra aplicación Solucionador de Problemas Matemáticos. Aquí tienes algunas pruebas que he realizado:
1. Ecuación simple de variable única: He intentado encontrar los posibles valores de una única variable x dada una única ecuación como entrada.
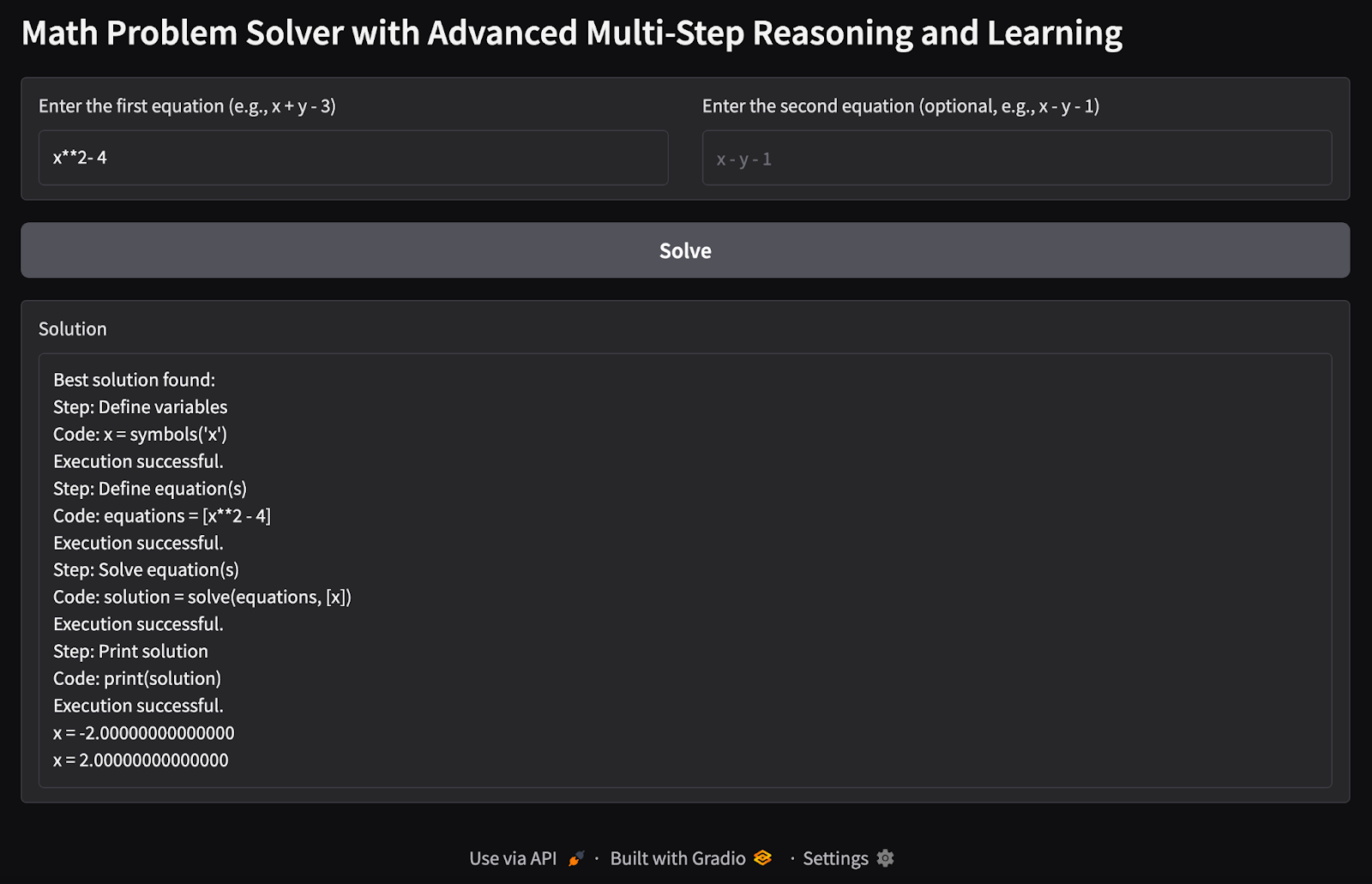
2. Problema de ecuaciones múltiples con múltiples variables: He pasado dos ecuaciones con problemas de dos variables para encontrar los posibles valores de las variables x y y.

Esta demostración es una versión básica de lo que podemos conseguir con las posibilidades del método rStar-math. Aún queda mucho trabajo por hacer para ampliar sus capacidades.
Puedes consultar el repositorio original del documento rStar-math en GitHub.
Esta demostración muestra una aplicación práctica del razonamiento en varios pasos para resolver ecuaciones matemáticas. Al combinar redes neuronales, razonamiento simbólico y MCTS, proporciona una visión de cómo las técnicas avanzadas de IA pueden abordar tareas de razonamiento estructurado. Futuras mejoras podrían acercarlo a las plenas capacidades del marco RStar.
Aprende IA con estos cursos
programa
programa
programa
blog
Summer Worsley
15 min
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Francisco Javier Carrera Arias
