
Curso
Streaming de datos con AWS Kinesis y Lambda
4 h
9.2K
Un corredor de mensajes es un software de servidor que permite la comunicación entre varios servicios, aplicaciones y componentes, sobre todo en sistemas distribuidos. Desempeña un papel importante en el soporte de la mensajería asíncrona, permitiendo que los sistemas se desacoplen y escalen de forma independiente.
Dos opciones populares en este espacio son ActiveMQ y Apache Kafka.
En este artículo, compararemos ActiveMQ y Kafka en profundidad, destacando sus características, arquitecturas, rendimiento y casos de uso. Al final, comprenderás mejor qué plataforma se adapta mejor a tus necesidades específicas.
ActiveMQ fue desarrollado originalmente por LogicBlaze, una empresa especializada en soluciones de integración y mensajería de código abierto. LogicBlaze aportó ActiveMQ a la Apache Software Foundation (ASF) en 2007, donde se convirtió en un proyecto Apache de primer nivel.
Desde entonces, la comunidad de código abierto bajo el gobierno de la Apache Software Foundation ha mantenido y desarrollado ActiveMQ, con contribuciones de varios desarrolladores y organizaciones de todo el mundo.
En concreto, ActiveMQ es un broker de mensajes de código abierto escrito en Java que implementa la API Java Message Service (JMS), una API estándar para middleware orientado a mensajes (MOM) definida por Oracle. El servicio es bien conocido por su facilidad de uso, amplia documentación y flexibilidad de despliegue, que incluye soporte para clustering, conmutación por error y múltiples protocolos de transporte.

Estas son las principales funciones y características de ActiveMQ:
Estos son los casos de uso más populares de ActiveMQ:
Apache Kafka fue desarrollado originalmente por LinkedIn para gestionar los flujos de datos en tiempo real de la empresa, y fue de código abierto a principios de 2011.
En 2012, Kafka se incorporó a la Apache Software Foundation (ASF), donde se convirtió en un proyecto de primer nivel. Desde entonces, ha sido mantenido y desarrollado por la comunidad de código abierto bajo el gobierno de la Apache Software Foundation, con importantes contribuciones de organizaciones como LinkedIn, Confluent y otras.
Kafka es una plataforma distribuida de streaming de eventos diseñada para mensajería de alto rendimiento, tolerante a fallos y escalable. Está escrito en Scala y Java, y su arquitectura está optimizada para manejar flujos de datos en tiempo real, lo que lo hace adecuado para construir canalizaciones de datos y aplicaciones basadas en eventos.
Kafka está bien considerado por su capacidad para procesar grandes volúmenes de datos con baja latencia, retención de datos robusta y capacidad de reproducción. Su amplio ecosistema incluye Kafka Connect y Kafka Streams para integrarse con otros sistemas de datos y procesar flujos en tiempo real.

Éstas son las características más destacadas de Kafka:
Estos son los casos de uso más relevantes y populares de Apache Kafka:
Si estás pensando en utilizar Kafka para tus datos en tiempo real o simplemente sientes curiosidad por esta tecnología, ¡sigue el curso Introducción a Apache Kafka para ponerte al día!
Elegir la plataforma de mensajería adecuada para tu aplicación es importante para garantizar un flujo de datos eficiente, escalabilidad y fiabilidad del sistema.
Como hemos visto antes, aunque tanto ActiveMQ como Apache Kafka sirven como intermediarios de mensajes, atienden a necesidades y casos de uso diferentes. Cada uno ofrece una arquitectura, unas características de rendimiento y unas funciones operativas únicas.
Repasemos las principales diferencias de estos intermediarios de mensajes en distintas categorías:
ActiveMQ utiliza una arquitectura centrada en el broker, almacenando los mensajes en un broker central que gestiona las colas y los temas. Esta configuración se basa en los acuses de recibo de los mensajes y en el almacenamiento persistente para garantizar una entrega fiable y la durabilidad de los mensajes.
En cambio, Kafka utiliza una arquitectura de registro distribuido, en la que los datos se particionan y replican en varios corredores de un clúster. El diseño de Kafka desacopla productores y consumidores, lo que permite una gran escalabilidad y rendimiento, haciéndolo ideal para manejar grandes volúmenes de datos en sistemas distribuidos.
ActiveMQ admite tanto punto a punto (colas) y publicar-suscribir (temas) modelosproporcionando flexibilidad para una amplia gama de escenarios de mensajería con un fuerte enfoque en las garantías de entrega de mensajes.
Por otro lado, Kafka funciona principalmente mediante un modelo de publicación-suscripción basado en registros distribuidos. Este enfoque permite que varios consumidores lean los datos de forma independiente y a su propio ritmo desde la misma partición, lo que resulta ventajoso para aplicaciones que requieren un alto rendimiento y un procesamiento concurrente.
En lo que se refiere a rendimiento y capacidad, ActiveMQ es adecuado para casos de uso que requieren una capacidad moderada y una latencia baja, pero su rendimiento puede verse afectado por la necesidad de mensajería persistente y enrutamiento complejo a través de un intermediario central. Esto puede limitar su capacidad para manejar con eficacia volúmenes de datos extremadamente altos.
Kafka, en comparación, está diseñado para un alto rendimiento y baja latencia, capaz de procesar millones de mensajes por segundo. Su arquitectura está optimizada para el flujo de datos en tiempo real, lo que la convierte en la opción preferida para aplicaciones que exigen un procesamiento de datos continuo y de alta velocidad, como la agregación de registros y el análisis en tiempo real.
ActiveMQ puede escalarse mediante clustering y una red de brokerspero este proceso puede ser complejo y a menudo requiere una cuidadosa configuración y gestión.
Kafka, sin embargo, está construido pensando en la escalabilidad, permitiendo un fácil escalado horizontal añadiendo más brokers al cluster. Las estrategias de partición y replicación de Kafka facilitan la gestión eficaz de los datos en un gran número de nodos, lo que le permite manejar cargas crecientes con un esfuerzo de configuración mínimo.
ActiveMQ utiliza opciones de almacenamiento persistente y clustering de brokers con mecanismos de conmutación por error para proporcionar durabilidad a los mensajes y garantizar que el sistema pueda recuperarse de fallos sin pérdida de datos.
Por otra parte, Kafka proporciona una sólida tolerancia a fallos mediante la replicación de datos a través de múltiples brokers en el cluster, garantizando una alta durabilidad incluso durante los fallos de los brokers. La capacidad de Kafka para reproducir mensajes desde su almacenamiento de registros añade una capa adicional de fiabilidad, permitiendo a los consumidores reprocesar los datos según sea necesario.
ActiveMQ es muy adecuado para las aplicaciones empresariales, especialmente las que requieren el cumplimiento de JMS. Es compatible con diversos protocolos de mensajería, como AMQP, STOMP y MQTT, lo que lo convierte en una opción versátil para conectar diversos sistemas y aplicaciones.
Kafka, en cambio, tiene un ecosistema en rápido crecimiento que incluye herramientas como Kafka Connect para la integración con diversas fuentes y sumideros de datos, y Kafka Streams para el procesamiento de datos en tiempo real. Sus capacidades de integración se extienden a plataformas de big data, servicios en la nube y otras tecnologías modernas, lo que la convierte en una potente opción para construir canalizaciones de datos escalables y en tiempo real y arquitecturas basadas en eventos.
La siguiente tabla resume las diferencias entre ActiveMQ y Kafka en las categorías anteriormente comentadas:
|
Función |
ActiveMQ |
Apache Kafka |
|
Arquitectura |
Centrado en el corredor |
Registro distribuido |
|
Modelo de mensajería |
Punto a punto, publicar-suscribir |
Publicar-suscribir, registros distribuidos |
|
Rendimiento |
Rendimiento moderado, baja latencia |
Alto rendimiento, baja latencia |
|
Escalabilidad |
Agrupación compleja a través de una red de intermediarios |
Escala horizontal (fácil de ampliar) |
|
Tolerancia a fallos |
Clustering, almacenamiento persistente |
Replicación, almacenamiento duradero de registros |
|
Durabilidad |
Persistencia de mensajes |
Replicación de datos, repetibilidad |
|
Ecosistema |
Soporte JMS, múltiples protocolos |
Kafka Connect, Streams, integración de big data |
Ahora, exploremos los casos de uso ideales para cada uno de estos corredores.
ActiveMQ es una opción sólida para diversos escenarios de mensajería, principalmente cuando se trata de sistemas heredados, necesidades de mensajería empresarial o requisitos de cumplimiento específicos.
Aquí tienes una visión más detallada de su idoneidad para distintos casos de uso:
ActiveMQ es especialmente adecuado para integrarse con sistemas heredados que dependen de la API Java Message Service (JMS). Implementa la especificación JMS, por lo que es una opción ideal para aplicaciones que necesitan comunicarse con sistemas antiguos diseñados en torno a los estándares JMS.
Además, ActiveMQ admite mensajería punto a punto (colas) y mensajería publicar-suscribir (temas), lo que puede ser esencial para garantizar la compatibilidad con la infraestructura existente que depende de estos paradigmas de mensajería.
ActiveMQ ofrece ventajas significativas en entornos empresariales en los que son importantes las funciones avanzadas de seguridad, el cumplimiento y las opciones flexibles de despliegue.
Proporciona mecanismos de seguridad sólidos, esenciales para mantener la confidencialidad y la integridad de los mensajes. Su conformidad con las normas JMS garantiza que pueda integrarse perfectamente con otros sistemas empresariales que se adhieran a las mismas normas.
Además, ActiveMQ admite varias opciones de despliegue, como brokers independientes, configuraciones en clúster y brokers en red, lo que permite a las empresas elegir el modelo de despliegue que mejor se adapte a su infraestructura y necesidades operativas.
ActiveMQ es un buen candidato para las aplicaciones que no requieren un rendimiento extremadamente alto, pero sí una mensajería fiable y de baja latencia. Su diseño se adapta a escenarios en los que se esperan volúmenes moderados de mensajería, y su enfoque en las garantías de entrega de mensajes asegura que éstos se transmitan de forma fiable incluso en entornos complejos.
Los mecanismos de persistencia y acuse de recibo de ActiveMQ proporcionan la fiabilidad necesaria para aplicaciones en las que la integridad de los mensajes es crítica, pero en las que el volumen de mensajes es manejable dentro de sus capacidades de rendimiento.
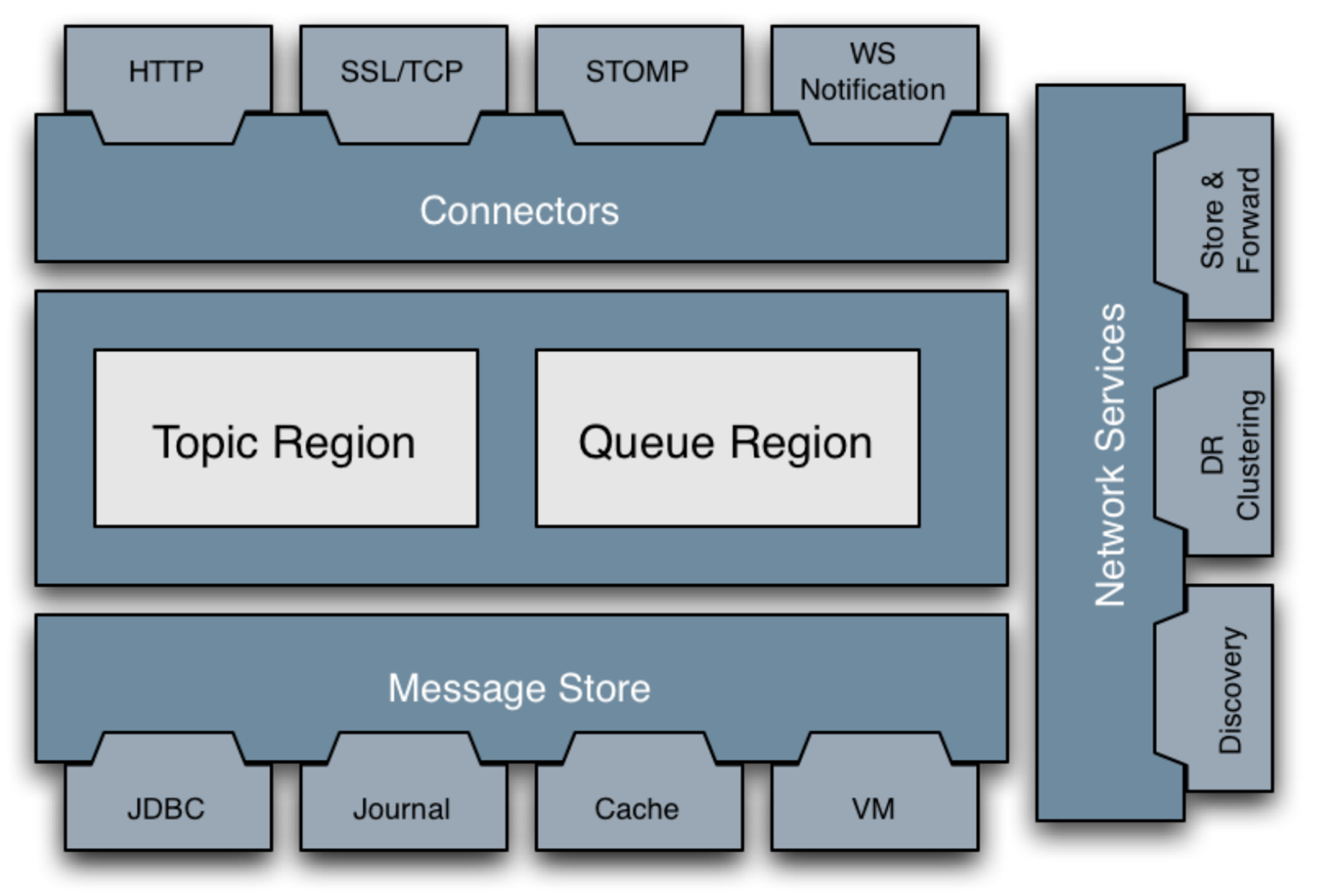
Componentes principales de ActiveMQ Classic. Fuente de la imagen: Documentación de ActiveMQ.
Kafka es especialmente adecuado para escenarios que requieren un alto rendimiento, una escalabilidad excepcional y capacidades avanzadas de manejo de datos.
Aquí tienes una visión detallada de cuándo utilizar Kafka:
Kafka es la mejor opción para aplicaciones que requieren procesamiento de datos en tiempo real y alto rendimiento. Destaca en los escenarios de agregación de registros y abastecimiento de eventos, en los que deben recopilarse, procesarse y analizarse enormes cantidades de datos en tiempo real.
La arquitectura de Kafka está optimizada para manejar millones de mensajes por segundo con baja latencia, lo que la hace ideal para aplicaciones de streaming que exigen un flujo continuo de datos y un retraso mínimo.
Kafka es muy eficaz para soportar arquitecturas de microservicios escalables. Proporciona un sistema de mensajería distribuido y tolerante a fallos que puede manejar la naturaleza dinámica y distribuida de los microservicios.
La capacidad de Kafka para desacoplar productores y consumidores permite que los microservicios se comuniquen eficientemente, incluso a medida que crece el número de servicios y el volumen de datos. Su sólida tolerancia a fallos garantiza que los mensajes se entreguen y procesen de forma fiable, incluso en entornos complejos y distribuidos.
Kafka destaca a la hora de construir canalizaciones de datos en tiempo real y plataformas analíticas debido a sus sólidas características de durabilidad y repetibilidad de los datos. Su arquitectura de registro distribuido permite almacenar y recuperar datos de forma fiable, lo que posibilita la construcción de sofisticados conductos de datos que pueden gestionar la ingestión y el procesamiento de grandes volúmenes de datos.
Su capacidad para retener y reproducir mensajes de sus registros es fundamental para las plataformas analíticasque procesan datos históricos y admiten consultas analíticas complejas.
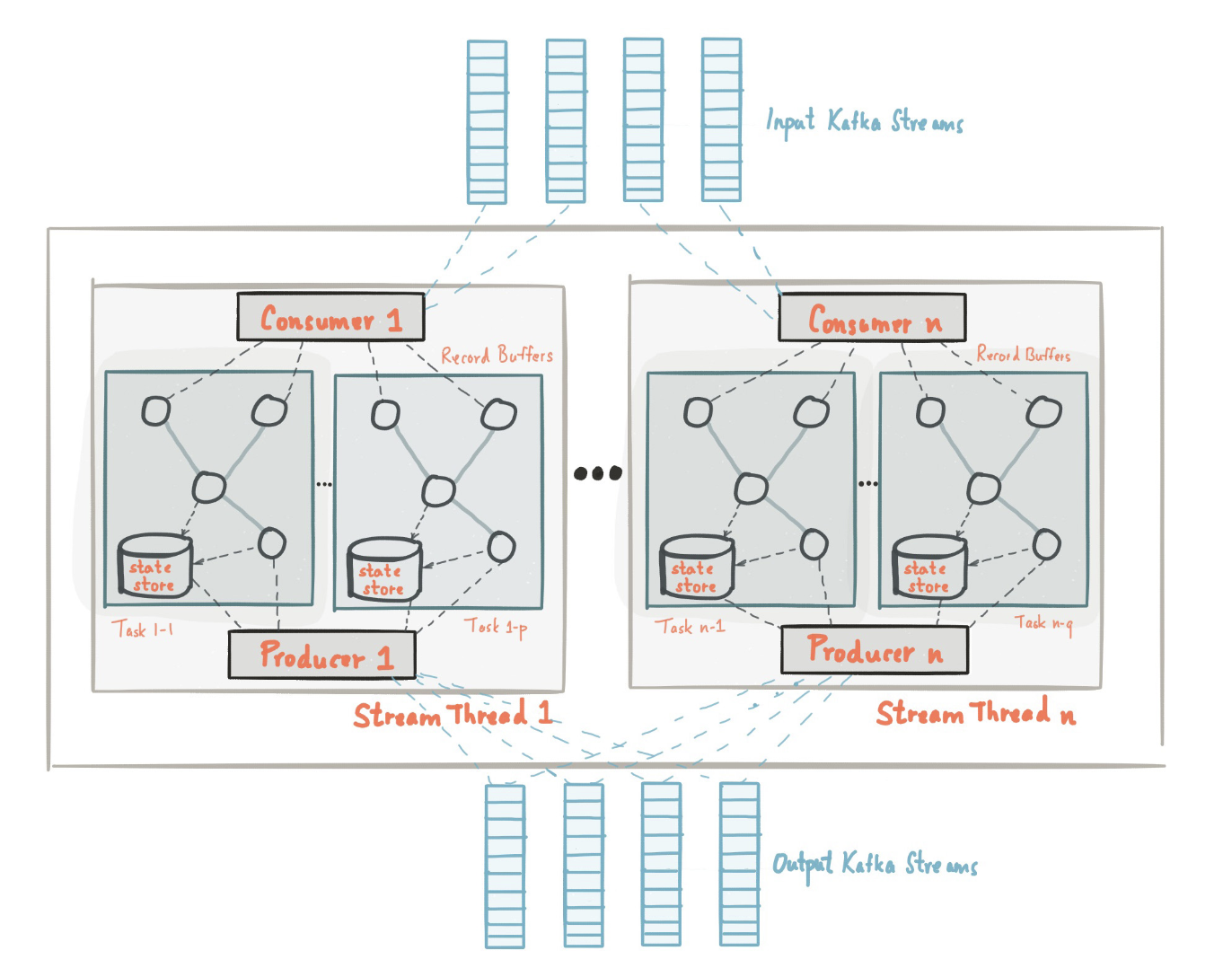
La anatomía de una aplicación que utiliza la biblioteca Kafka Streams. Fuente de la imagen: Documentación sobre Kafka.
Elegir entre ActiveMQ y Kafka depende de tus necesidades y casos de uso específicos. ActiveMQ es muy adecuado para los escenarios de mensajería tradicionales, especialmente en entornos empresariales que requieren el cumplimiento de JMS y un menor rendimiento. En cambio, Kafka brilla en entornos de alto rendimiento y escalabilidad, por lo que es ideal para el procesamiento de datos en tiempo real y el streaming.
Para leer más y profundizar en la ingeniería de datos, consulta los recursos que se indican a continuación:
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre streaming de datos y Apache Kafka con estos cursos!
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Adejumo Ridwan Suleiman
13 min
blog
Kurtis Pykes
12 min
blog
Mona Khalil
5 min
blog
Kurtis Pykes
15 min
blog
Arun Nanda
15 min