
programa
Microsoft Azure Fundamentals (AZ-900)
9 h
La capacidad de integrar, procesar y analizar datos de forma eficaz es importante para las organizaciones que pretenden obtener información y mantener una ventaja competitiva.
Dos potentes herramientas, Azure Data Factory y Databricks, han surgido como soluciones líderes para gestionar canalizaciones de datos y realizar análisis avanzados en el ecosistema Azure. Aunque estas herramientas puedan parecer similares a primera vista, abordan aspectos diferentes de la ingeniería y el análisis de datos.
En este artículo, exploraremos las capacidades de Azure Data Factory y Databricks, compararemos sus características y daremos ideas sobre cuándo utilizar cada herramienta.

Azure Data Factory (ADF) es un servicio ETL (Extraer, Transformar, Cargar) basado en la nube que permite la integración, migración y orquestación de datos en varios almacenes de datos. Está diseñado para facilitar el movimiento y la transformación de datos desde fuentes dispares a ubicaciones centralizadas, donde pueden analizarse y aprovecharse para
inteligencia empresarial.
Con ADF, puedes crear y gestionar canalizaciones de datos que automaticen el proceso de extraer datos de múltiples fuentes, transformarlos en un formato utilizable y cargarlos en un destino para su análisis.
Estas son las características más interesantes del ADF, sin ningún orden en particular:
Como puedes ver, ¡ADF ofrece todo lo que necesitas para crear canalizaciones de datos dentro del ecosistema Azure!
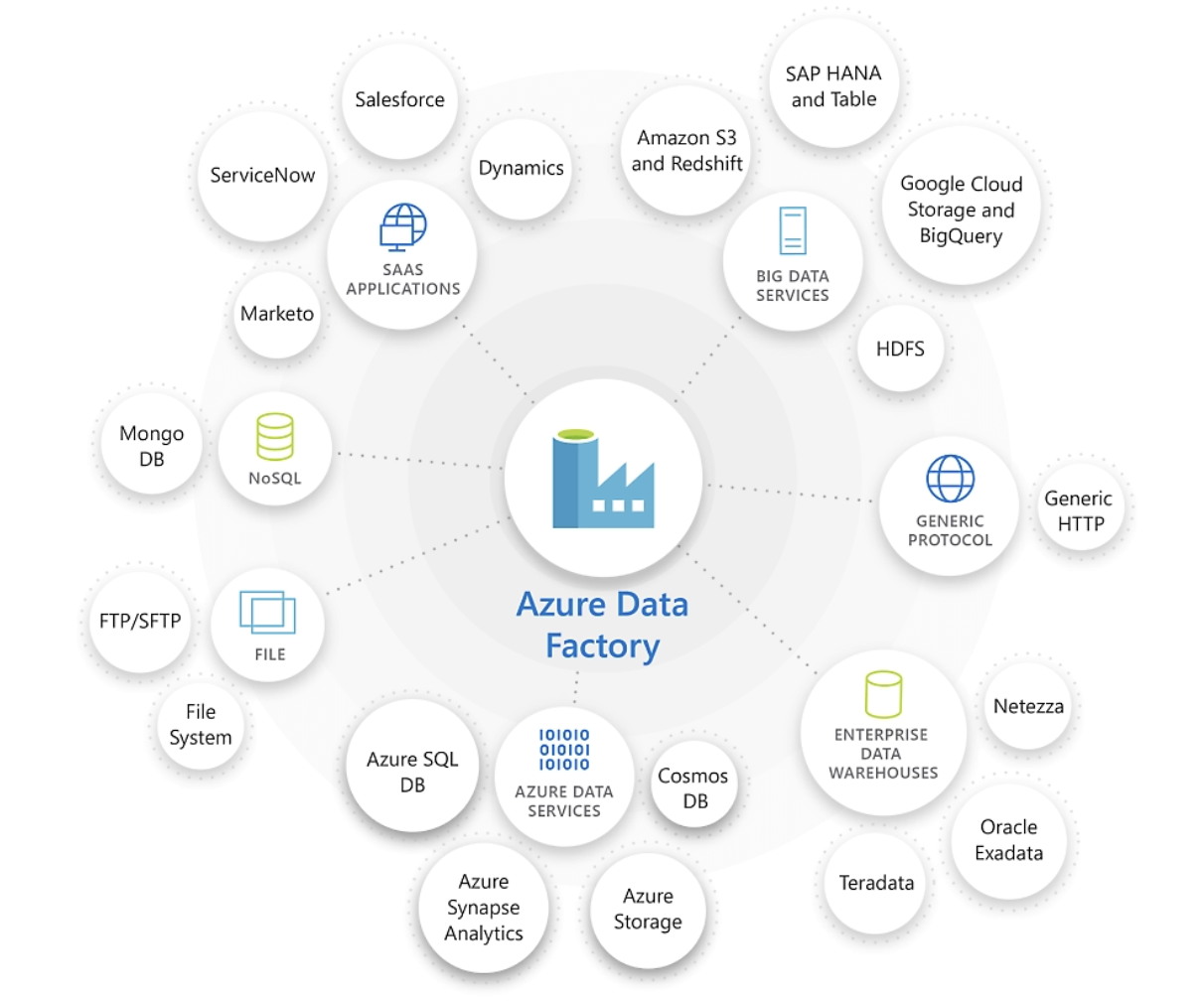
Azure Data Factory destaca en la conexión e integración de diversas fuentes de datos. Fuente de la imagen: Microsoft.
El curso Introducción a Azure es un recurso excelente para los interesados en iniciarse en Azure. El curso de Gestión y Gobernanza de Azure es ideal para los más experimentados.

Databricks es una plataforma analítica que proporciona un entorno colaborativo para el procesamiento de big data y el aprendizaje automático. Basado en Apache Spark, Databricks está diseñado para manejar tareas de procesamiento de datos a gran escala, permitiéndote realizar análisis complejos y desarrollar modelos de aprendizaje automático.
Databricks ofrece una plataforma unificada en la que ingenieros de datos, científicos de datos y analistas pueden colaborar para procesar, analizar y visualizar datos en un flujo de trabajo racionalizado.
Éstas son algunas de las características que hacen de Databricks una herramienta tan popular:
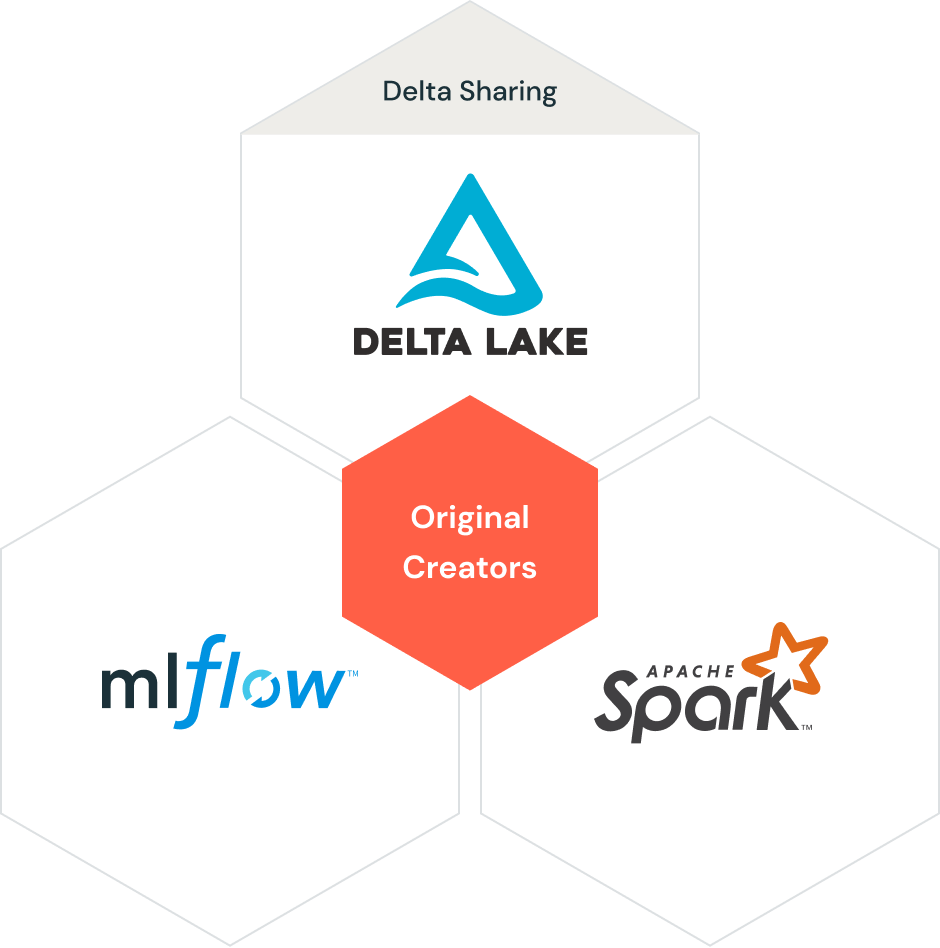
Elementos de la arquitectura Data Lakehouse de Databricks. Fuente de la imagen: Databricks
¡Ahí lo tienes! Si Databricks llamó tu atención por sus amplias capacidades, puedes empezar con el curso Introducción a Databricks.
Llegados a este punto, quizá puedas ver en qué se diferencian ADF y Databricks. Ahora, profundicemos y analicemos dichas diferencias en varias categorías.
Azure Data Factory está diseñado principalmente para la integración y orquestación de datos. Es excelente moviendo datos entre varias fuentes, transformándolos y cargándolos en una ubicación centralizada para su posterior análisis. El ADF es ideal para situaciones en las que necesitas automatizar y gestionar flujos de trabajo de datos en varios entornos.
Por otro lado, Databricks se centra en el procesamiento de datos, la analítica y el aprendizaje automático. Es la plataforma a la que acuden las empresas que desean realizar análisis de datos a gran escala, desarrollar modelos de aprendizaje automático y colaborar en proyectos de ciencia de datos. Databricks es especialmente adecuado para entornos de big data y aplicaciones basadas en IA.
Azure Data Factory proporciona capacidades de transformación de datos a través de su función Flujo de Datos, que permite a los usuarios realizar diversas transformaciones directamente dentro de la canalización. Aunque potentes, estas transformaciones suelen ser más adecuadas para procesos ETL y pueden no ser tan amplias o flexibles como las que ofrece Databricks.
Databricks, con su base en Apache Spark, ofrece capacidades avanzadas de transformación de datos. Los usuarios pueden aprovechar toda la potencia de Spark para realizar transformaciones complejas, agregaciones y tareas de procesamiento de datos, lo que lo convierte en la opción preferida para escenarios que requieren una gran manipulación y cálculo de datos.
Tanto ADF como Databricks se integran con otros servicios de Azure, pero lo hacen con enfoques diferentes. ADF está diseñado para ETL y orquestación, lo que lo convierte en la herramienta ideal para gestionar flujos de trabajo de datos que implican múltiples servicios de Azure, como Azure Synapse Analytics y Azure Blob Storage.
Databricks, por su parte, se centra más en la analítica avanzada y la IA, integrándose con servicios como Delta Lake para el almacenamiento de datos y Azure Machine Learning para el despliegue de modelos.
La interfaz de arrastrar y soltar de Azure Data Factory hace que sea relativamente fácil de usar, incluso para quienes tienen conocimientos técnicos limitados. Su enfoque en el desarrollo de canalizaciones de bajo código/sin código simplifica la creación y gestión de flujos de trabajo de datos.
Aunque potente, Databricks requiere un mayor nivel de competencia técnica. Su dependencia de la codificación (en lenguajes como Python, Scala y SQL) y sus complejas opciones de configuración lo hacen más adecuado para ingenieros y científicos de datos que se sienten cómodos trabajando con código y marcos de big data.
ADF y Databricks son altamente escalables, pero destacan en áreas diferentes. El ADF está diseñado para gestionar tareas de integración y migración de datos a gran escala, por lo que es ideal para orquestar flujos de trabajo ETL complejos.
Databricks, con su base en Apache Spark, ofrece un rendimiento sin igual para el procesamiento y análisis de big data, lo que lo convierte en la opción preferida para escenarios que requieren computación de alto rendimiento y escalabilidad.
Al considerar el coste de utilizar Azure Data Factory y Databricks, es esencial comprender sus modelos de precios y cómo pueden afectar a tu presupuesto:
Al evaluar los costes, ten en cuenta las necesidades específicas de tu organización, como el volumen de datos, la complejidad de las transformaciones y la frecuencia de ejecución de las canalizaciones.
En algunos casos, utilizar ADF para la orquestación y Databricks para el procesamiento puede proporcionar un enfoque equilibrado, aprovechando los puntos fuertes de ambas herramientas a la vez que se gestionan eficazmente los costes.
A continuación se muestra una tabla comparativa entre Azure Data Factory y Databricks en una amplia gama de aspectos:
|
Categoría |
Azure Data Factory (ADF) |
Databricks |
|
Visión general |
Un servicio de integración de datos basado en la nube para orquestar y automatizar el movimiento y la transformación de datos. |
Una plataforma analítica unificada centrada en el procesamiento de big data y el aprendizaje automático. |
|
Caso de uso principal |
Integración de datos, canalizaciones ETL/ELT, orquestación de datos y automatización del flujo de trabajo. |
Análisis de grandes datos, procesamiento de datos en tiempo real y aprendizaje automático. |
|
Transformación de datos |
Se utiliza principalmente para orquestar transformaciones de datos, utilizando recursos informáticos integrados o externos, como Databricks o pools Spark de Synapse. |
Transformación avanzada de datos a gran escala con Apache Spark y Delta Lake, tanto para procesamiento por lotes como en tiempo real. |
|
ETL/ELT |
Especializado en orquestación ETL/ELT, conectando múltiples fuentes y destinos de datos, con actividades integradas como copiar datos, flujo de datos y servicios Azure. |
Potentes capacidades ETL, especialmente para transformaciones complejas de big data, aprovechando Apache Spark para el procesamiento en memoria. |
|
Motor de cálculo |
No tiene un motor de computación nativo; depende de opciones de computación externas como Azure Databricks, Azure Synapse o Azure HDInsight para la transformación de datos. |
Motor de cálculo basado en Apache Spark para procesamiento en tiempo real y por lotes. |
|
Movimiento de datos |
Ofrece una amplia gama de conectores integrados (por ejemplo, para bases de datos, almacenamiento en la nube, plataformas SaaS), lo que lo hace adecuado para orquestar el movimiento de datos a gran escala en distintos entornos. |
Normalmente se integra con soluciones de almacenamiento como Azure Data Lake, S3 y Delta Lake, pero el movimiento de datos no es el objetivo principal. |
|
Integración de datos |
Sólidas capacidades de integración de datos con soporte para más de 90 conectores, incluidos servicios Azure, bases de datos on-prem y sistemas de terceros. |
La integración de datos se centró principalmente en las plataformas de almacenamiento y procesamiento de big data (Azure Data Lake, Delta Lake). Menos diversidad de opciones de conectores. |
|
Tratamiento de datos |
Aprovecha los flujos de datos para transformarlos a escala mediante un mapeo visual de bajo código. Para transformaciones más avanzadas, utiliza Databricks o Azure Synapse. |
Procesamiento avanzado de datos mediante Spark; optimizado para cargas de trabajo en tiempo real y por lotes a gran escala. |
|
Colaboración |
Colaboración en canalizaciones mediante la integración de Git (Azure DevOps y GitHub). |
Funciones avanzadas de colaboración con Databricks Workspaces y control de versiones integrado con GitHub o Databricks Repos. |
|
Experiencia como desarrollador |
Interfaz de usuario de arrastrar y soltar para crear flujos de trabajo ETL; los usuarios no técnicos pueden crear fácilmente canalizaciones de datos. |
Experiencia avanzada de desarrollador, que ofrece un entorno de bloc de notas y soporte para transformaciones basadas en código (Python, Scala, R, SQL). |
|
Programación y orquestación |
Excelentes capacidades de programación y orquestación, con disparadores y control de ejecución de canalizaciones. |
Capacidades de orquestación limitadas. Los Databricks pueden orquestarse externamente mediante ADF u otras herramientas. |
|
Gobernanza de datos |
Integración con Azure Purview para la gobernanza de datos, el seguimiento del linaje y la gestión de metadatos. |
La gobernanza suele gestionarse externamente, utilizando herramientas como Azure Purview u otras soluciones de terceros. |
|
Monitorización y registro |
Supervisión y registro integrados mediante Azure Monitor, Alertas y el panel de supervisión del ADF. |
Amplias capacidades de registro y supervisión a través de la API REST de Databricks, integración con Azure Monitor y paneles personalizados. |
|
Escalabilidad |
Escala fácilmente con integración y movimiento de datos bajo demanda. Utiliza servicios informáticos externos para escalar el procesamiento de datos. |
Altamente escalable, especialmente para grandes cargas de trabajo de datos y pipelines de aprendizaje automático, con escalado automático del clúster. |
|
Modelo de costes |
Pago por uso basado en el movimiento de datos, la orquestación y los servicios informáticos externos (Databricks, Synapse, etc.) utilizados. |
Pago por uso de almacenamiento y computación. Los clusters pueden autoescalarse para optimizar costes. |
|
Aprendizaje automático |
No incorpora funciones de aprendizaje automático. El aprendizaje automático puede integrarse orquestando servicios como Azure ML o Databricks. |
Bibliotecas de aprendizaje automático integradas, como MLlib, e integraciones con MLflow para el seguimiento y la gestión de modelos. |
|
Seguridad |
Control de acceso basado en roles (RBAC), integración con Azure Active Directory, cifrado de datos incorporado e identidades gestionadas. |
RBAC, cifrado de datos, integración con Azure Active Directory y modelos de seguridad personalizados. |
|
Integración BI |
Puede orquestar canalizaciones de datos y alimentar con datos herramientas de BI como Power BI, Azure Synapse Analytics y otros servicios de Azure. |
Admite la integración con herramientas de BI como Power BI, Tableau y otras para el consumo directo de datos. |
|
Procesamiento de datos en tiempo real |
Puede orquestar la ingesta de datos en tiempo real con disparadores, y utilizar servicios informáticos en tiempo real como Stream Analytics o Databricks. |
Optimizado para el procesamiento de datos en tiempo real mediante Spark Streaming. |
|
Facilidad de uso |
Fácil de usar con una interfaz de bajo código, que facilita a los usuarios no técnicos la creación de canalizaciones de datos. |
Requiere más conocimientos técnicos, ya que está enfocado a ingenieros de big data, científicos de datos y desarrolladores. |
|
Soporte multi-nube |
Centrado principalmente en Azure, pero puede conectarse a algunos otros servicios en la nube mediante conectores. |
Admite entornos multi-nube, incluidos Azure, AWS y GCP. |
|
Despliegue |
Servicio totalmente gestionado con actualizaciones automatizadas y escalado de canalizaciones. |
Servicio gestionado, pero se da más control a los usuarios sobre las configuraciones y el escalado del clúster. |
|
Comunidad y Ecosistema |
Amplia comunidad Azure, con fuerte apoyo de Microsoft e integración en el ecosistema Azure. |
Gran comunidad, con importantes contribuciones de Databricks y de la comunidad de código abierto Apache Spark. |
|
Cumplimiento y certificaciones |
Cumple varias normas del sector, como las certificaciones GDPR, HIPAA e ISO. |
También cumple varias normas y certificaciones del sector, como GDPR, HIPAA y conformidad SOC. |
Azure Data Factory es la opción preferida en escenarios en los que la integración y la migración de datos son las principales preocupaciones. Más concretamente, es ideal para:
Databricks es la plataforma de referencia para escenarios que requieren procesamiento de big data, analítica y aprendizaje automático. Es el más adecuado para:
En muchos casos, Azure Data Factory y Databricks pueden utilizarse juntos para crear una canalización de datos completa.
ADF puede orquestar la canalización de datos, gestionando la extracción, transformación y carga de datos de diversas fuentes. A continuación, Databricks puede realizar las tareas más complejas de procesamiento y análisis de datos, aprovechando sus capacidades avanzadas de procesamiento de big data y aprendizaje automático.
Por ejemplo, una típica canalización de datos de extremo a extremo puede implicar que ADF extraiga datos de múltiplesfuentes y los cargue en un lago de datos. A continuación, Databricks podría procesar los datos, realizar transformaciones avanzadas y aplicar modelos de aprendizaje automático antes de cargar los resultados en un almacén de datos para su posterior análisis.
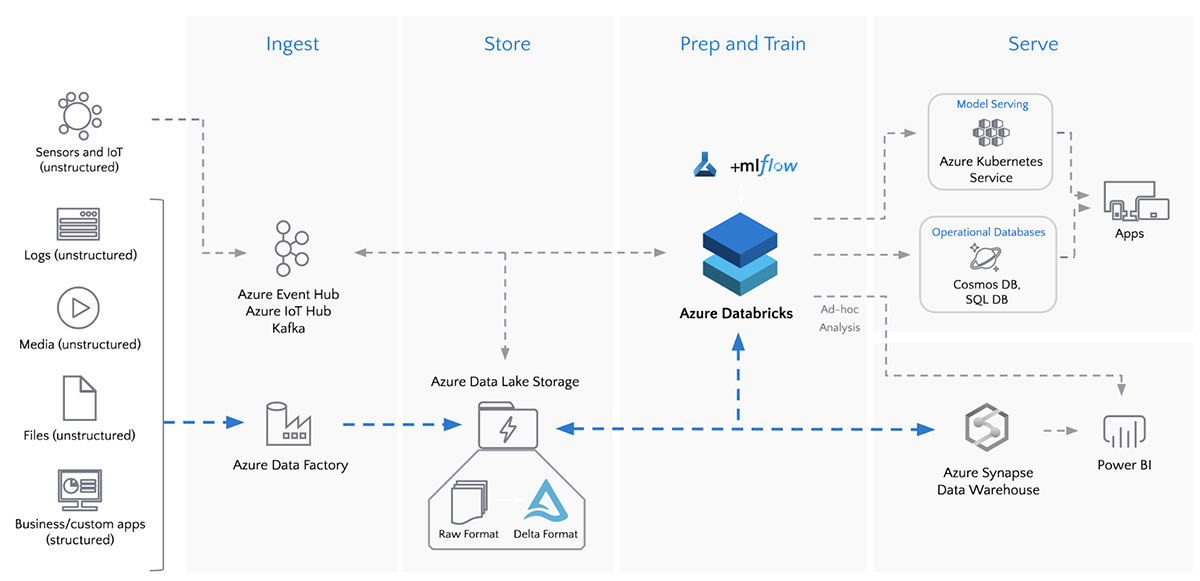
ETL por lotes con Azure Data Factory y Azure Databricks. Fuente de la imagen: Databricks
Azure Data Factory y Databricks son herramientas potentes dentro del ecosistema Azure, cada una con sus puntos fuertes y casos de uso ideales. En muchos casos, combinar ADF y Databricks puede proporcionar una solución integral que aproveche lo mejor de ambos mundos.
Quienes deseen profundizar en estas plataformas, pueden explorar los siguientes recursos:
Estos recursos proporcionan una base sólida para comprender Azure Data Factory y Databricks y cómo pueden utilizarse para crear potentes canalizaciones de datos y soluciones analíticas.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre Azure y sus servicios con estos cursos!
programa
Curso
Curso
blog
Kurtis Pykes
12 min
blog
Kurtis Pykes
10 min
Tutorial
Maarten Van den Broeck
