
Track
Microsoft Azure Fundamentals (AZ-900)
9 hr
The ability to efficiently integrate, process, and analyze data is important for organizations aiming to gain insights and maintain a competitive edge.
Two powerful tools, Azure Data Factory and Databricks, have emerged as leading solutions for managing data pipelines and performing advanced analytics in the Azure ecosystem. While these tools may look similar at first glance, they address different aspects of data engineering and analytics.
In this article, we will explore the capabilities of Azure Data Factory and Databricks, compare their features, and provide insights into when to use each tool.

Azure Data Factory (ADF) is a cloud-based ETL (Extract, Transform, Load) service that enables data integration, migration, and orchestration across various data stores. It is designed to facilitate the movement and transformation of data from disparate sources to centralized locations, where it can be analyzed and leveraged for
business intelligence.
With ADF, you can create and manage data pipelines that automate the process of extracting data from multiple sources, transforming it into a usable format, and loading it into a destination for analysis.
These are the most interesting features of ADF, in no particular order:
As you can see, ADF offers everything you need to create data pipelines within the Azure ecosystem!
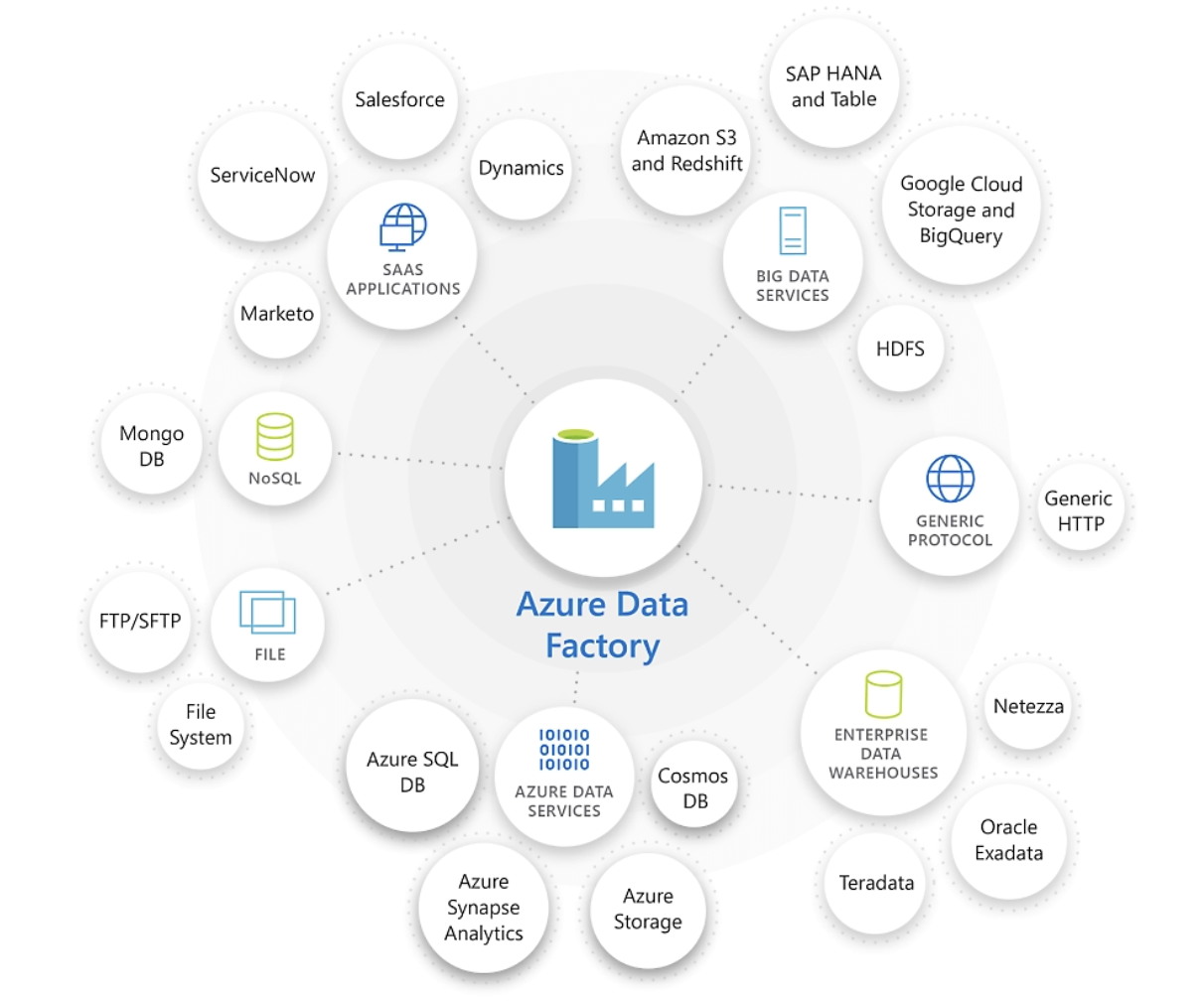
Azure Data Factory excels at connecting to and integrating diverse data sources. Image source: Microsoft.
The Introduction to Azure course is an excellent resource for those interested in getting started with Azure. The Azure Management and Governance course is ideal for those more experienced.

Databricks is an analytics platform that provides a collaborative environment for big data processing and machine learning. Based on Apache Spark, Databricks is designed to handle large-scale data processing tasks, enabling you to perform complex analytics and develop machine learning models.
Databricks offers a unified platform on which data engineers, data scientists, and analysts can collaborate to process, analyze, and visualize data in a streamlined workflow.
Here are some of the features that make Databricks such a popular tool:
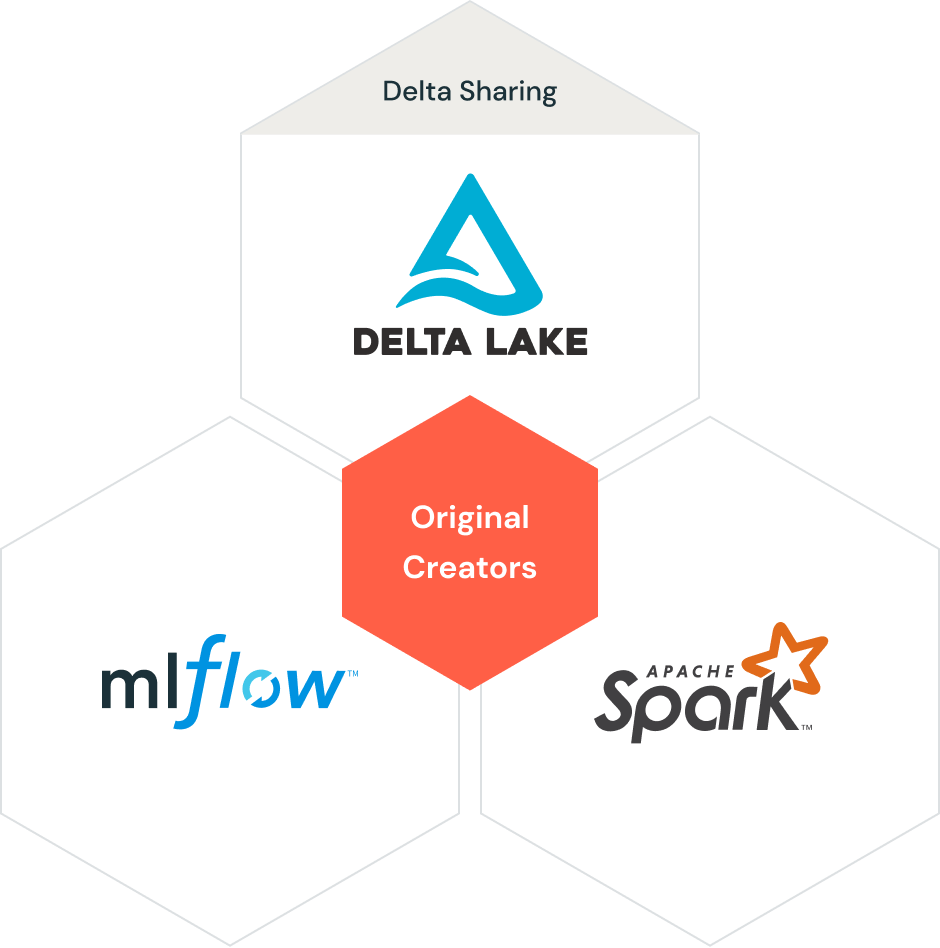
Databricks Data Lakehouse architecture elements. Image source: Databricks
There you have it! If Databricks got your attention for its extensive capabilities, you can start with the Introduction to Databricks course.
At this point, you may be able to see how ADF and Databricks are different from each other. Now, let’s go deeper and analyze such differences under several categories.
Azure Data Factory is primarily designed for data integration and orchestration. It excels at moving data between various sources, transforming it, and loading it into a centralized location for further analysis. ADF is ideal for scenarios where you need to automate and manage data workflows across multiple environments.
On the other hand, Databricks is focused on data processing, analytics, and machine learning. It is the go-to platform for companies looking to perform large-scale data analysis, develop machine learning models, and collaborate on data science projects. Databricks is particularly well-suited for big data environments and AI-driven applications.
Azure Data Factory provides data transformation capabilities through its Data Flow feature, which allows users to perform various transformations directly within the pipeline. While powerful, these transformations are generally more suited to ETL processes and may not be as extensive or flexible as those offered by Databricks.
Databricks, with its foundation in Apache Spark, offers advanced data transformation capabilities. Users can leverage Spark's full power to perform complex transformations, aggregations, and data processing tasks, making it the preferred choice for scenarios that require heavy data manipulation and computation.
Both ADF and Databricks integrate with other Azure services but do so with different focuses. ADF is designed for ETL and orchestration, making it the ideal tool for managing data workflows that involve multiple Azure services like Azure Synapse Analytics and Azure Blob Storage.
Databricks, on the other hand, is more focused on advanced analytics and AI, integrating with services like Delta Lake for data storage and Azure Machine Learning for model deployment.
Azure Data Factory’s drag-and-drop interface makes it relatively easy to use, even for those with limited technical expertise. Its focus on low-code/no-code pipeline development simplifies creating and managing data workflows.
While powerful, Databricks requires a higher level of technical proficiency. Its reliance on coding (in languages like Python, Scala, and SQL) and complex configuration options make it more suitable for data engineers and scientists who are comfortable working with code and big data frameworks.
ADF and Databricks are highly scalable but excel in different areas. ADF is designed to handle large-scale data integration and migration tasks, making it ideal for orchestrating complex ETL workflows.
Databricks, with its foundation in Apache Spark, offers unparalleled performance for big data processing and analytics, making it the preferred choice for scenarios that require high-performance computing and scalability.
When considering the cost of using Azure Data Factory and Databricks, it’s essential to understand their pricing models and how they might impact your budget:
When evaluating costs, consider your organization’s specific needs, such as the volume of data, complexity of transformations, and frequency of pipeline execution.
In some cases, using ADF for orchestration and Databricks for processing can provide a balanced approach, leveraging the strengths of both tools while effectively managing costs.
Below is a table comparing Azure Data Factory and Databricks across a wide range of aspects:
|
Category |
Azure Data Factory (ADF) |
Databricks |
|
Overview |
A cloud-based data integration service for orchestrating and automating data movement and transformation. |
A unified analytics platform focused on big data processing and machine learning. |
|
Primary Use Case |
Data integration, ETL/ELT pipelines, data orchestration, and workflow automation. |
Big data analytics, real-time data processing, and machine learning. |
|
Data Transformation |
Primarily used for orchestrating data transformations, using built-in or external compute resources like Databricks or Synapse Spark pools. |
Advanced, large-scale data transformation with Apache Spark and Delta Lake for both batch and real-time processing. |
|
ETL/ELT |
Specialized in ETL/ELT orchestration, connecting multiple data sources and destinations, with built-in activities like copy data, data flow, and Azure services. |
Powerful ETL capabilities, especially for complex big data transformations, leveraging Apache Spark for in-memory processing. |
|
Compute Engine |
Does not have a native compute engine; relies on external compute options like Azure Databricks, Azure Synapse, or Azure HDInsight for data transformation. |
Apache Spark-based compute engine for real-time and batch processing. |
|
Data Movement |
Offers a wide range of built-in connectors (e.g., for databases, cloud storage, SaaS platforms), making it suitable for orchestrating large-scale data movement across different environments. |
Typically integrates with storage solutions like Azure Data Lake, S3, and Delta Lake, but data movement is not the primary focus. |
|
Data Integration |
Strong data integration capabilities with support for over 90 connectors, including Azure services, on-prem databases, and third-party systems. |
Data integration mainly focused on big data storage and processing platforms (Azure Data Lake, Delta Lake). Less diverse in connector options. |
|
Data Processing |
Leverages data flows for transforming data at scale using visual, low-code mapping. For more advanced transformations, it uses Databricks or Azure Synapse. |
Advanced data processing using Spark; optimized for real-time and large-scale batch workloads. |
|
Collaboration |
Pipeline collaboration through Git integration (Azure DevOps and GitHub). |
Advanced collaboration features with Databricks Workspaces and integrated version control with GitHub or Databricks Repos. |
|
Developer Experience |
Drag-and-drop UI for building ETL workflows; easy for non-technical users to create data pipelines. |
Advanced developer experience, offering a notebook environment and support for code-based transformations (Python, Scala, R, SQL). |
|
Scheduling & Orchestration |
Excellent scheduling and orchestration capabilities, with triggers and pipeline execution control. |
Limited orchestration capabilities. Databricks can be orchestrated externally using ADF or other tools. |
|
Data Governance |
Integration with Azure Purview for data governance, lineage tracking, and metadata management. |
Governance is typically handled externally, using tools like Azure Purview or other third-party solutions. |
|
Monitoring & Logging |
Built-in monitoring and logging via Azure Monitor, Alerts, and ADF's monitoring dashboard. |
Extensive logging and monitoring capabilities through Databricks REST API, integration with Azure Monitor, and custom dashboards. |
|
Scalability |
Scales easily with on-demand data integration and data movement. Uses external compute services for scaling data processing. |
Highly scalable, especially for large data workloads and machine learning pipelines, with automatic cluster scaling. |
|
Cost Model |
Pay-per-use based on data movement, orchestration, and the external compute services (Databricks, Synapse, etc.) utilized. |
Pay-as-you-go for storage and compute. Clusters can be auto-scaled for cost optimization. |
|
Machine Learning |
No built-in machine learning capabilities. Machine learning can be integrated by orchestrating services like Azure ML or Databricks. |
Built-in machine learning libraries like MLlib and integrations with MLflow for model tracking and management. |
|
Security |
Role-based access control (RBAC), integration with Azure Active Directory, built-in data encryption, and managed identities. |
RBAC, data encryption, integration with Azure Active Directory, and custom security models. |
|
BI Integration |
Can orchestrate data pipelines and feed data to BI tools like Power BI, Azure Synapse Analytics, and other Azure services. |
Supports integration with BI tools like Power BI, Tableau, and others for direct data consumption. |
|
Real-time Data Processing |
Can orchestrate real-time data ingestion with triggers, and use real-time compute services like Stream Analytics or Databricks. |
Optimized for real-time data processing using Spark Streaming. |
|
Ease of Use |
User-friendly with a low-code interface, making it easy for non-technical users to build data pipelines. |
Requires more technical knowledge, as it's focused on big data engineers, data scientists, and developers. |
|
Multi-cloud Support |
Primarily focused on Azure, but can connect to some other cloud services using connectors. |
Supports multi-cloud environments, including Azure, AWS, and GCP. |
|
Deployment |
Fully managed service with automated updates and scaling of pipelines. |
Managed service, but more control is given to users over cluster configurations and scaling. |
|
Community & Ecosystem |
Extensive Azure community, with strong support from Microsoft and integration into the Azure ecosystem. |
Large community, with significant contributions from Databricks and the open-source Apache Spark community. |
|
Compliance & Certifications |
Compliant with various industry standards, including GDPR, HIPAA, and ISO certifications. |
Also meets various industry standards and certifications, including GDPR, HIPAA, and SOC compliance. |
Azure Data Factory is the preferred choice in scenarios where data integration and migration are the primary concerns. More specifically, it is ideal for:
Databricks is the go-to platform for scenarios that require big data processing, analytics, and machine learning. It is best suited for:
In many cases, Azure Data Factory and Databricks can be used together to create a comprehensive data pipeline.
ADF can orchestrate the data pipeline, managing the extraction, transformation, and loading of data from various sources. Databricks can then perform the more complex data processing and analytics tasks, leveraging its advanced capabilities in big data processing and machine learning.
For example, a typical end-to-end data pipeline might involve ADF extracting data from multiple sources and loading it into a data lake. Databricks could then process the data, perform advanced transformations, and apply machine learning models before the results are loaded into a data warehouse for further analysis.
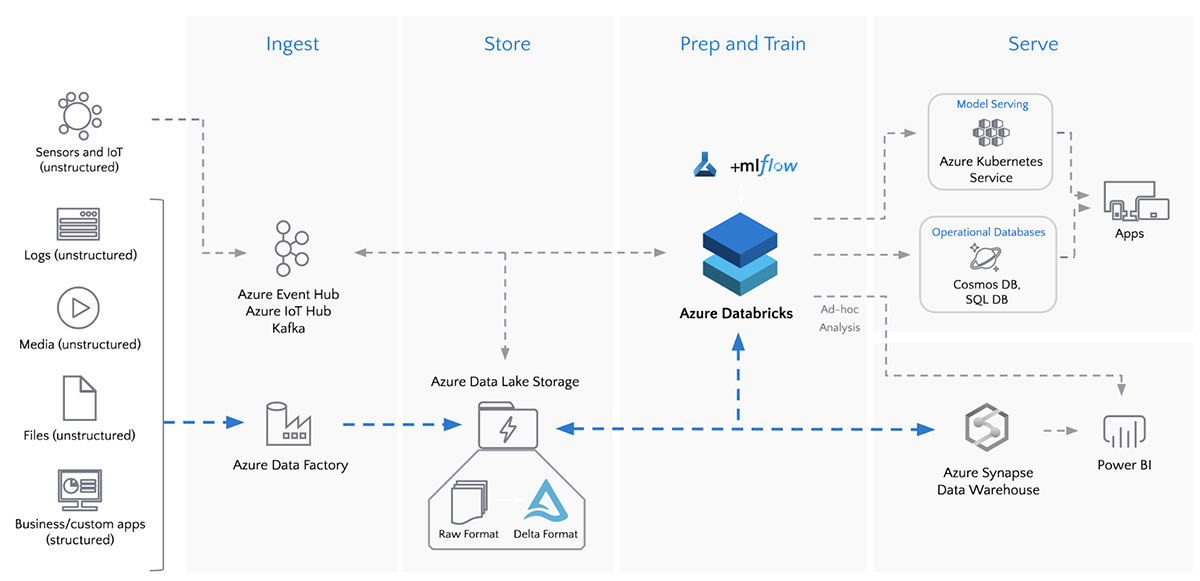
Batch ETL with Azure Data Factory and Azure Databricks. Image source: Databricks
Azure Data Factory and Databricks are powerful tools within the Azure ecosystem, each with its strengths and ideal use cases. In many cases, combining ADF and Databricks can provide a comprehensive solution that leverages the best of both worlds!
For those looking to dive deeper into these platforms, consider exploring the following resources:
These resources provide a solid foundation for understanding Azure Data Factory and Databricks and how they can be used to build powerful data pipelines and analytics solutions.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Learn more about Azure and its services with these courses!
Track
Course
Course
blog
Gus Frazer
14 min
blog
Kurtis Pykes
12 min
blog
Maria Eugenia Inzaugarat
8 min
cheat-sheet
Richie Cotton
Tutorial
Gus Frazer
Tutorial
Arunn Thevapalan


