
Programa
Fundamentos do Microsoft Azure (AZ-900)
9 h
A capacidade de integrar, processar e analisar dados com eficiência é importante para as organizações que desejam obter insights e manter uma vantagem competitiva.
Duas ferramentas poderosas, o Azure Data Factory e o Databricks, surgiram como soluções líderes para gerenciar pipelines de dados e realizar análises avançadas no ecossistema do Azure. Embora essas ferramentas possam parecer semelhantes à primeira vista, elas abordam diferentes aspectos da engenharia e da análise de dados.
Neste artigo, exploraremos os recursos do Azure Data Factory e do Databricks, compararemos seus recursos e forneceremos insights sobre quando usar cada ferramenta.

O Azure Data Factory (ADF) é um serviço ETL (Extrair, Transformar, Carregar) baseado em nuvem que permite a integração, migração e orquestração de dados em vários armazenamentos de dados. Ele foi projetado para facilitar a movimentação e a transformação de dados de fontes diferentes para locais centralizados, onde eles podem ser analisados e aproveitados para
inteligência comercial.
Com o ADF, você pode criar e gerenciar pipelines de dados que automatizam o processo de extração de dados de várias fontes, transformando-os em um formato utilizável e carregando-os em um destino para análise.
Estes são os recursos mais interessantes do ADF, sem nenhuma ordem específica:
Como você pode ver, o ADF oferece tudo o que você precisa para criar pipelines de dados no ecossistema do Azure!
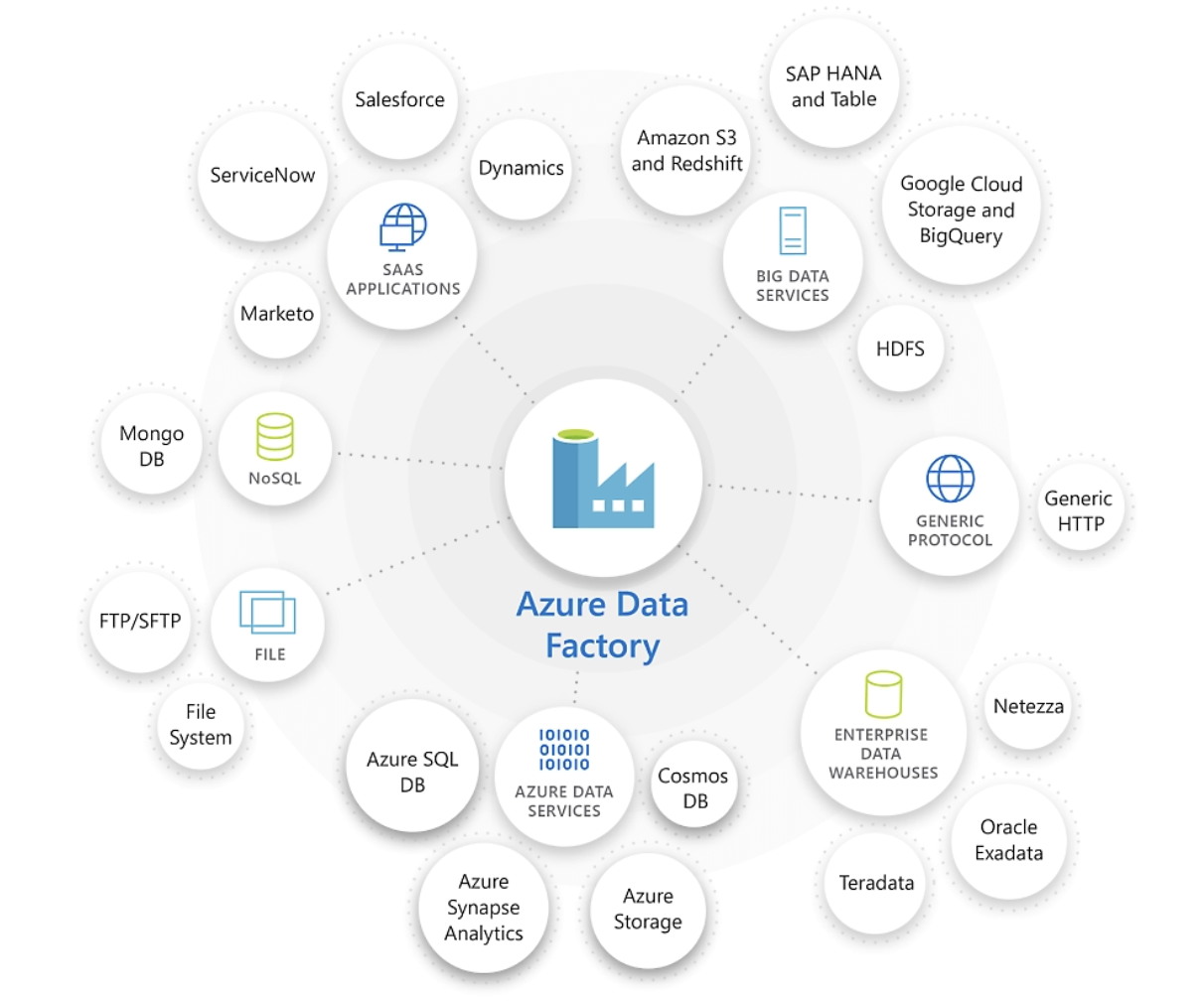
O Azure Data Factory é excelente na conexão e na integração de diversas fontes de dados. Fonte da imagem: Microsoft.
O curso Introdução ao Azure é um excelente recurso para os interessados em começar a usar o Azure. O curso Azure Management and Governance é ideal para os mais experientes.

A Databricks é uma plataforma de análise que oferece um ambiente colaborativo para processamento de big data e aprendizado de máquina. Com base no Apache Spark, o Databricks foi projetado para lidar com tarefas de processamento de dados em grande escala, permitindo que você realize análises complexas e desenvolva modelos de aprendizado de máquina.
A Databricks oferece uma plataforma unificada na qual engenheiros de dados, cientistas de dados e analistas podem colaborar para processar, analisar e visualizar dados em um fluxo de trabalho simplificado.
Aqui estão alguns dos recursos que tornam o Databricks uma ferramenta tão popular:
Elementos de arquitetura do Data Lakehouse da Databricks. Fonte da imagem: Telas de dados
Aí está o que você precisa! Se o Databricks chamou sua atenção por seus amplos recursos, você pode começar com o curso Introduction to Databricks.
Neste ponto, você pode ver como o ADF e o Databricks são diferentes um do outro. Agora, vamos nos aprofundar e analisar essas diferenças em várias categorias.
O Azure Data Factory foi projetado principalmente para integração e orquestração de dados. Ele é excelente para mover dados entre várias fontes, transformá-los e carregá-los em um local centralizado para análise posterior. O ADF é ideal para cenários em que você precisa automatizar e gerenciar fluxos de trabalho de dados em vários ambientes.
Por outro lado, a Databricks se concentra em processamento de dados, análise e aprendizado de máquina. É a plataforma ideal para empresas que desejam realizar análises de dados em grande escala, desenvolver modelos de aprendizado de máquina e colaborar em projetos de ciência de dados. O Databricks é particularmente adequado para ambientes de big data e aplicativos orientados por IA.
O Azure Data Factory fornece recursos de transformação de dados por meio do recurso Data Flow, que permite aos usuários realizar várias transformações diretamente no pipeline. Embora sejam eficientes, essas transformações geralmente são mais adequadas aos processos de ETL e podem não ser tão extensas ou flexíveis quanto as oferecidas pela Databricks.
O Databricks, com sua base no Apache Spark, oferece recursos avançados de transformação de dados. Os usuários podem aproveitar todo o poder do Spark para realizar transformações complexas, agregações e tarefas de processamento de dados, tornando-o a escolha preferida para cenários que exigem manipulação e computação pesadas de dados.
Tanto o ADF quanto o Databricks se integram a outros serviços do Azure, mas o fazem com focos diferentes. O ADF foi projetado para ETL e orquestração, o que o torna a ferramenta ideal para gerenciar fluxos de trabalho de dados que envolvem vários serviços do Azure, como o Azure Synapse Analytics e o Azure Blob Storage.
A Databricks, por outro lado, está mais focada em análise avançada e IA, integrando-se a serviços como o Delta Lake para armazenamento de dados e o Azure Machine Learning para implantação de modelos.
A interface de arrastar e soltar do Azure Data Factory o torna relativamente fácil de usar, mesmo para aqueles com conhecimento técnico limitado. Seu foco no desenvolvimento de pipeline com pouco ou nenhum código simplifica a criação e o gerenciamento de fluxos de trabalho de dados.
Embora poderoso, o Databricks exige um nível mais alto de proficiência técnica. Sua dependência de codificação (em linguagens como Python, Scala e SQL) e opções de configuração complexas o tornam mais adequado para engenheiros de dados e cientistas que se sentem à vontade para trabalhar com código e estruturas de Big Data.
O ADF e o Databricks são altamente dimensionáveis, mas se destacam em áreas diferentes. O ADF foi projetado para lidar com tarefas de integração e migração de dados em grande escala, o que o torna ideal para orquestrar fluxos de trabalho de ETL complexos.
O Databricks, com sua base no Apache Spark, oferece desempenho incomparável para processamento e análise de big data, tornando-o a escolha preferida para cenários que exigem computação de alto desempenho e escalabilidade.
Ao considerar o custo do uso do Azure Data Factory e do Databricks, é essencial entender seus modelos de preços e como eles podem afetar seu orçamento:
Ao avaliar os custos, considere as necessidades específicas de sua organização, como o volume de dados, a complexidade das transformações e a frequência de execução do pipeline.
Em alguns casos, o uso do ADF para orquestração e do Databricks para processamento pode proporcionar uma abordagem equilibrada, aproveitando os pontos fortes de ambas as ferramentas e, ao mesmo tempo, gerenciando os custos de forma eficaz.
Abaixo está uma tabela que compara o Azure Data Factory e o Databricks em uma ampla gama de aspectos:
|
Categoria |
Fábrica de dados do Azure (ADF) |
Telas de dados |
|
Visão geral |
Um serviço de integração de dados baseado em nuvem para orquestrar e automatizar a movimentação e a transformação de dados. |
Uma plataforma analítica unificada focada em processamento de big data e aprendizado de máquina. |
|
Caso de uso principal |
Integração de dados, pipelines ETL/ELT, orquestração de dados e automação de fluxo de trabalho. |
Análise de Big Data, processamento de dados em tempo real e aprendizado de máquina. |
|
Transformação de dados |
Usado principalmente para orquestrar transformações de dados, usando recursos de computação internos ou externos, como Databricks ou pools do Synapse Spark. |
Transformação de dados avançada e em grande escala com o Apache Spark e o Delta Lake para processamento em lote e em tempo real. |
|
ETL/ELT |
Especializado em orquestração de ETL/ELT, conectando várias fontes de dados e destinos, com atividades incorporadas, como cópia de dados, fluxo de dados e serviços do Azure. |
Recursos avançados de ETL, especialmente para transformações complexas de big data, aproveitando o Apache Spark para processamento na memória. |
|
Mecanismo de computação |
Não tem um mecanismo de computação nativo; depende de opções de computação externas, como Azure Databricks, Azure Synapse ou Azure HDInsight para transformação de dados. |
Mecanismo de computação baseado no Apache Spark para processamento em tempo real e em lote. |
|
Movimentação de dados |
Oferece uma ampla variedade de conectores integrados (por exemplo, para bancos de dados, armazenamento em nuvem, plataformas SaaS), o que o torna adequado para orquestrar a movimentação de dados em grande escala em diferentes ambientes. |
Normalmente, integra-se a soluções de armazenamento como Azure Data Lake, S3 e Delta Lake, mas a movimentação de dados não é o foco principal. |
|
Integração de dados |
Recursos avançados de integração de dados com suporte para mais de 90 conectores, incluindo serviços do Azure, bancos de dados no local e sistemas de terceiros. |
A integração de dados se concentrou principalmente em plataformas de armazenamento e processamento de big data (Azure Data Lake, Delta Lake). Menos diversidade nas opções de conectores. |
|
Processamento de dados |
Aproveita os fluxos de dados para transformar dados em escala usando mapeamento visual e de baixo código. Para transformações mais avançadas, ele usa o Databricks ou o Azure Synapse. |
Processamento avançado de dados usando o Spark; otimizado para cargas de trabalho em lote em tempo real e em grande escala. |
|
Colaboração |
Colaboração de pipeline por meio da integração do Git (Azure DevOps e GitHub). |
Recursos avançados de colaboração com o Databricks Workspaces e controle de versão integrado com o GitHub ou o Databricks Repos. |
|
Experiência do desenvolvedor |
Interface de usuário de arrastar e soltar para criar fluxos de trabalho de ETL; fácil para usuários não técnicos criarem pipelines de dados. |
Experiência avançada de desenvolvedor, oferecendo um ambiente de notebook e suporte para transformações baseadas em código (Python, Scala, R, SQL). |
|
Programação e orquestração |
Excelentes recursos de agendamento e orquestração, com gatilhos e controle de execução de pipeline. |
Recursos limitados de orquestração. Os Databricks podem ser orquestrados externamente usando o ADF ou outras ferramentas. |
|
Governança de dados |
Integração com o Azure Purview para governança de dados, rastreamento de linhagem e gerenciamento de metadados. |
Normalmente, a governança é feita externamente, usando ferramentas como o Azure Purview ou outras soluções de terceiros. |
|
Monitoramento e registro |
Monitoramento e registro incorporados por meio do Azure Monitor, dos alertas e do painel de monitoramento do ADF. |
Amplos recursos de registro e monitoramento por meio da API REST do Databricks, integração com o Azure Monitor e painéis personalizados. |
|
Escalabilidade |
Dimensione facilmente com integração e movimentação de dados sob demanda. Usa serviços de computação externos para dimensionar o processamento de dados. |
Altamente dimensionável, especialmente para grandes cargas de trabalho de dados e pipelines de aprendizado de máquina, com dimensionamento automático do cluster. |
|
Modelo de custo |
Pagamento por uso com base na movimentação de dados, orquestração e serviços de computação externa (Databricks, Synapse etc.) utilizados. |
Pagamento conforme você usa para armazenamento e computação. Os clusters podem ser dimensionados automaticamente para otimização de custos. |
|
Aprendizado de máquina |
Não há recursos integrados de aprendizado de máquina. O aprendizado de máquina pode ser integrado por meio da orquestração de serviços como o Azure ML ou o Databricks. |
Bibliotecas de aprendizado de máquina incorporadas, como MLlib, e integrações com MLflow para rastreamento e gerenciamento de modelos. |
|
Segurança |
Controle de acesso baseado em função (RBAC), integração com o Azure Active Directory, criptografia de dados incorporada e identidades gerenciadas. |
RBAC, criptografia de dados, integração com o Azure Active Directory e modelos de segurança personalizados. |
|
Integração de BI |
Você pode orquestrar pipelines de dados e alimentar dados para ferramentas de BI, como o Power BI, o Azure Synapse Analytics e outros serviços do Azure. |
Oferece suporte à integração com ferramentas de BI, como Power BI, Tableau e outras, para consumo direto de dados. |
|
Processamento de dados em tempo real |
Pode orquestrar a ingestão de dados em tempo real com acionadores e usar serviços de computação em tempo real, como o Stream Analytics ou o Databricks. |
Otimizado para processamento de dados em tempo real usando o Spark Streaming. |
|
Facilidade de uso |
Fácil de usar com uma interface de baixo código, facilitando a criação de pipelines de dados para usuários não técnicos. |
Requer mais conhecimento técnico, pois é voltado para engenheiros de big data, cientistas de dados e desenvolvedores. |
|
Suporte a várias nuvens |
O foco principal é o Azure, mas você pode se conectar a alguns outros serviços de nuvem usando conectores. |
Oferece suporte a ambientes com várias nuvens, incluindo Azure, AWS e GCP. |
|
Implantação |
Serviço totalmente gerenciado com atualizações automatizadas e dimensionamento de pipelines. |
Serviço gerenciado, mas os usuários têm mais controle sobre as configurações e o dimensionamento do cluster. |
|
Comunidade e ecossistema |
Ampla comunidade do Azure, com forte suporte da Microsoft e integração ao ecossistema do Azure. |
Grande comunidade, com contribuições significativas da Databricks e da comunidade Apache Spark de código aberto. |
|
Conformidade e certificações |
Em conformidade com vários padrões do setor, incluindo GDPR, HIPAA e certificações ISO. |
Também atende a vários padrões e certificações do setor, incluindo conformidade com GDPR, HIPAA e SOC. |
O Azure Data Factory é a escolha preferida em cenários em que a integração e a migração de dados são as principais preocupações. Mais especificamente, ele é ideal para você:
A Databricks é a plataforma ideal para cenários que exigem processamento de big data, análise e aprendizado de máquina. É mais adequado para você:
Em muitos casos, o Azure Data Factory e o Databricks podem ser usados juntos para criar um pipeline de dados abrangente.
O ADF pode orquestrar o pipeline de dados, gerenciando a extração, a transformação e o carregamento de dados de várias fontes. O Databricks pode então executar as tarefas mais complexas de processamento e análise de dados, aproveitando seus recursos avançados de processamento de big data e aprendizado de máquina.
Por exemplo, um pipeline de dados típico de ponta a ponta pode envolver o ADF extraindo dados de váriasfontes e carregando-os em um lago de dados. O Databricks poderia então processar os dados, realizar transformações avançadas e aplicar modelos de aprendizado de máquina antes que os resultados fossem carregados em um data warehouse para análise posterior.
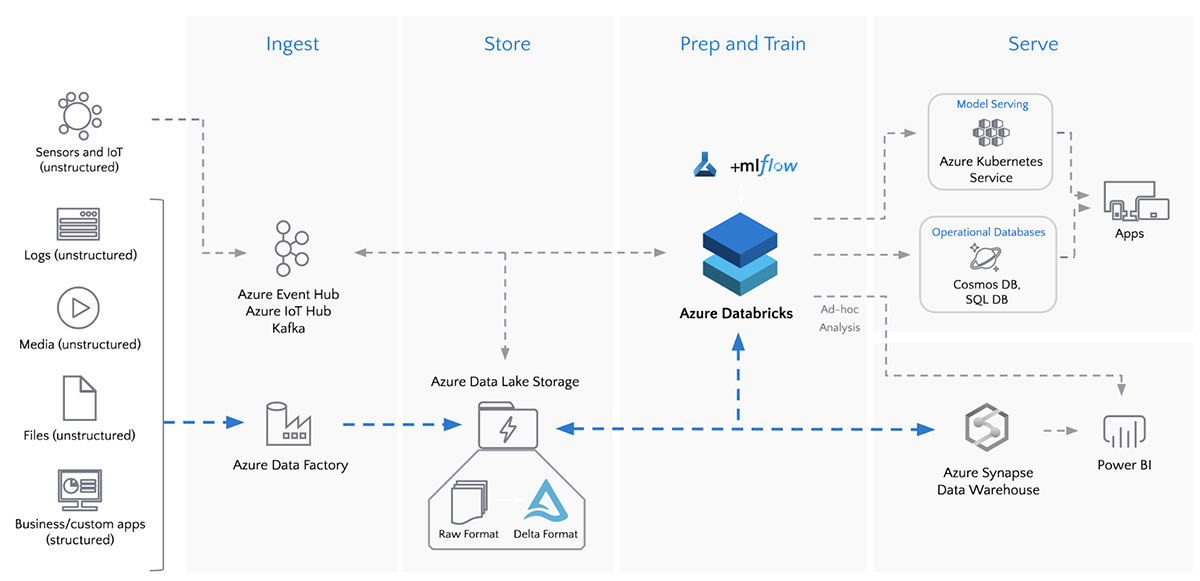
ETL em lote com o Azure Data Factory e o Azure Databricks. Fonte da imagem: Telas de dados
O Azure Data Factory e o Databricks são ferramentas poderosas no ecossistema do Azure, cada uma com seus pontos fortes e casos de uso ideais. Em muitos casos, a combinação de ADF e Databricks pode fornecer uma solução abrangente que aproveita o melhor dos dois mundos!
Para aqueles que desejam se aprofundar nessas plataformas, considere explorar os seguintes recursos:
Esses recursos fornecem uma base sólida para você entender o Azure Data Factory e o Databricks e como eles podem ser usados para criar pipelines de dados e soluções analíticas poderosas.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Saiba mais sobre o Azure e seus serviços com estes cursos!
Programa
Curso
Curso