Sí. GPT-Image-1.5 está disponible en la API de OpenAI e incluye las mismas mejoras que ChatGPT Images. Las entradas y salidas de imagen son aproximadamente un 20% más baratas que en GPT Image 1, lo que lo hace ideal para aplicaciones de marketing, ecommerce y diseño.
¿Quieres iniciarte en la IA Generativa?
Aprende a trabajar con LLMs en Python directamente en tu navegador

¿Qué es ChatGPT Images?
La nueva pestaña Imágenes de ChatGPT funciona como un centro creativo para todo lo visual dentro de la interfaz de ChatGPT y sustituye la biblioteca personal de imágenes. El cambio más notable es la integración de herramientas de edición directa que permiten actuar sobre detalles concretos de una imagen manteniendo intacto el resto.
ChatGPT Images funciona con GPT-Image-1.5, el modelo de IA texto-a-imagen más reciente y avanzado de OpenAI. Se basa en el lanzamiento del modelo GPT-Image-1 en marzo de 2025, que fue todo un éxito con más de 700 millones de imágenes generadas en la primera semana.
Ofrece conservación del detalle y una mejor representación de texto, y se afirma que es «hasta 4 veces» más rápido que su predecesor.
Las nuevas funciones ya están disponibles para todos los usuarios, tanto en planes gratuitos como de pago, en la web, el móvil y la API. Solo las cuentas Business y Enterprise tendrán que esperar para acceder.
Funciones clave de ChatGPT Images
Entonces, ¿qué ofrece ChatGPT Images frente a su modelo anterior y la competencia? OpenAI destaca especialmente las «ediciones precisas que conservan lo importante». Veamos las nuevas funciones y qué implican.
Espacio creativo dedicado
La pestaña Imágenes se ha introducido como un centro de creación visual dentro de la interfaz de ChatGPT. La idea es separar la creación y edición de imágenes de las conversaciones habituales.
La antigua Biblioteca también almacenaba las imágenes generadas, pero solo te llevaba de vuelta a la conversación donde se crearon. Usaba el contexto de todo el historial para generar una imagen desde cero, lo que a menudo llevaba a alucinaciones en hilos largos.
El nuevo enfoque, sin embargo, es más centrado en la imagen: cada edición toma una imagen como punto de partida y solo cambia los aspectos seleccionados, en lugar de crear una generación completamente nueva.
Las imágenes son artefactos persistentes, no quedan enterradas en el historial de chat. Esto permite ciclos de feedback más rápidos con nuevas variaciones y fomenta la experimentación, convirtiendo la experiencia de un hilo de chat en la de un lienzo.
Para potenciar este flujo creativo, el espacio de trabajo incorpora herramientas de exploración que acortan la distancia entre idea y ejecución. Puedes aplicar estilos predefinidos (como «boceto» o «dramático») o explorar estéticas en tendencia para detectar el próximo «Studio Ghibli». Para quienes empiezan, la interfaz ofrece sugerencias creativas y ayuda proactiva con los prompts para afinar resultados.
Conservación del detalle y edición de precisión
Probablemente la mejora más importante es que ahora puedes seleccionar partes concretas de una imagen y modificarlas directamente, sin alterar el resto de la composición. El modelo comprende el contexto, es decir, entiende qué debe editarse manteniendo coherentes los elementos alrededor.
Este tipo de ediciones precisas son posibles gracias a las mejores capacidades del nuevo modelo para conservar el detalle.
Es capaz de mantener consistentes objetos, iluminación, composición y la apariencia de las personas a lo largo de las salidas y ediciones sucesivas. Además, la mejora en el seguimiento de instrucciones contribuye a preservar mejor las relaciones entre los elementos.
La edición de precisión es perfecta para corregir detalles pequeños y experimentar con aspectos concretos cuando no hace falta una regeneración completa. También permite transformaciones creativas, como llevar un elemento de una imagen a la escena de otra.
Eso sí, conviene mencionar que el modelo tiene dificultades para mantener la identidad exacta de cada persona cuando hay muchas en una misma imagen.
Mejor tipografía y realismo
Una de las grandes virtudes del modelo anterior, GPT-Image-1, era su capacidad para manejar textos largos y oraciones coherentes. La nueva versión se apoya en esa base y ahora puede gestionar textos más densos y pequeños que antes.
Esto es especialmente útil para infografías, donde los primeros resultados son bastante llamativos, y abre posibilidades como maquetar texto dentro de una imagen, por ejemplo, en un periódico. Más abajo probaremos con infografías.
Sin embargo, según la nota de lanzamiento de OpenAI, siguen existiendo limitaciones en algunos idiomas específicos como chino, árabe y hebreo.
Aunque no ha sido el foco principal de la actualización, el realismo del resultado ha mejorado notablemente frente al modelo anterior. Se aprecia especialmente en reflejos (por ejemplo, brillos en una foto) y en muchas caras pequeñas dentro de grandes multitudes.
Como suele ocurrir, las grandes mejoras implican concesiones en áreas concretas. En este caso, ha retrocedido la capacidad para generar ciertos estilos artísticos. OpenAI recomienda usar los filtros predefinidos en la pestaña Imágenes o recurrir al modelo anterior, que sigue disponible como un GPT personalizado.
Rendimiento acelerado
Las capacidades de edición puntual también explican buena parte del aumento de velocidad. Aunque la generación completa es notablemente más rápida, no alcanza del todo lo afirmado en la nota de OpenAI. GPT-Image-1.5 parece «hasta 4 veces más rápido» sobre todo porque regenera únicamente lo que cambia durante las ediciones.
Del mismo modo, la bajada de costes por API de en torno al 20% proviene principalmente de la regeneración parcial durante las ediciones, con ganancias adicionales por una inferencia más eficiente, más que por generaciones completas más baratas.
En conjunto, las nuevas funciones permiten un uso más eficiente y fiable, especialmente en flujos por API.
Ejemplos de ChatGPT Images
Las funciones anunciadas suenan prometedoras. Las puse a prueba con unos prompts sencillos combinados con la nueva herramienta de selección.
Prueba de precisión de edición
El objetivo de la primera prueba era evaluar la capacidad del modelo para manejar cambios iterativos sin degradar la calidad. Primero le pedí crear una imagen de un oso pardo caminando por un bosque finlandés durante el sol de medianoche.

Prompt: «A brown bear walking through a dense Finnish forest during the midnight sun.»
En mi opinión, la calidad de la primera salida es muy alta. El oso parece natural, el tipo de árboles y arbustos representa muy bien los bosques finlandeses (¡lo sé de primera mano!) y la posición baja del sol encaja con lo que cabe esperar en el norte de Finlandia durante el sol de medianoche.
Además, la iluminación y las sombras en el pelaje del oso, así como en el fondo, resultan bastante realistas. Se nota que es IA, de algún modo, aunque los detalles están muy cuidados.
Ahora intentemos convertir el oso en un oso polar y ver qué pasa. No hay osos polares en Finlandia, pero si todo funciona como debe, el fondo debería mantenerse igual.

Prompt: «Change the bear to a polar bear.»
Como se ve, el fondo se mantuvo totalmente intacto, justo como se pretendía.
En la siguiente edición, seleccioné la cabeza y los ojos del oso polar y le puse unas gafas de sol vintage.

Prompt: «Put a pair of vintage sunglasses on the bear.» (cabeza seleccionada)
Aquí vemos qué ocurre cuando seleccionas un área demasiado grande. Aunque el fondo y el cuerpo del oso se mantienen consistentes, su cabeza se convirtió en un gran par de gafas de sol. Probemos de nuevo, seleccionando solo los ojos.

Prompt: «Put a pair of vintage sunglasses on the bear.» (ojos seleccionados)
Mucho mejor, y con muy buen resultado. En esta primera prueba hemos visto la potencia real de la conservación del detalle: solo tuvimos que definir una vez los aspectos importantes de la escena, y pudimos iterar sobre el protagonista sin preocuparnos por el fondo. Otra lección importante: el tamaño de la ventana de selección importa.
Prueba de consistencia en transformaciones
Después probé la permanencia del objeto en distintas escenas y las limitaciones del modelo en multitudes. Para ello, hice viajar a nuestro oso polar y lo coloqué en una estación de metro abarrotada en Tokio.

Prompt: «Place this bear into a very busy subway scene in Tokyo.»
Para empezar, la consistencia del personaje es impresionante: el modelo conservó perfectamente la postura e identidad exactas del oso y eliminó el brillo del sol de su pelaje.
Sin embargo, esta preservación tan rígida provocó una desconexión visual conocida como «efecto pegatina». Al no actualizar el contexto de iluminación (manteniendo la sombra direccional y los reflejos del bosque en las gafas), el oso parece un recorte 2D pegado en la escena en lugar de un objeto 3D integrado en ella.
La perspectiva rompe aún más la ilusión: el oso flota delante de un transeúnte que está físicamente más cerca de la cámara.
Corregir este último aspecto fue bastante frustrante. Seleccioné el área del transeúnte y su intersección con el oso, y pedí a ChatGPT que ajustara la perspectiva. En cada variación, el modelo insertaba una persona nueva cerca de la cámara, así:

Prompt: «Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back.»
Parece que el modelo no fue capaz de identificar a la persona, incluso al seleccionarla, y por eso necesitó crear un nuevo personaje para seguir la instrucción del prompt.
Corregir la sombra y los reflejos de las gafas fue más sencillo. Usé estas iteraciones:
- Sombra: Selecciona el suelo alrededor de las patas del oso y usa el prompt «Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting.»
- Gafas de sol: Selecciona las gafas y usa el prompt «Update the reflections of the sunglasses to match the subway environment.»

Nuestro oso polar en el metro de Tokio tras corregir la sombra y los reflejos de las gafas
Bastante mejor, aunque aún no perfecto.
En conjunto, la segunda prueba no fue tan bien como la primera. Si bien la consistencia de elementos entre imágenes diferentes funciona bien, el reconocimiento de personajes parece tocar techo en escenas abarrotadas.
Prueba de representación de texto
Para terminar, quise probar la nueva capacidad de renderizar texto, especialmente en textos densos y ediciones. Serían mejoras muy bienvenidas porque, históricamente, los modelos de visión han sido mejores con objetos, texturas y escenas, no con símbolos.
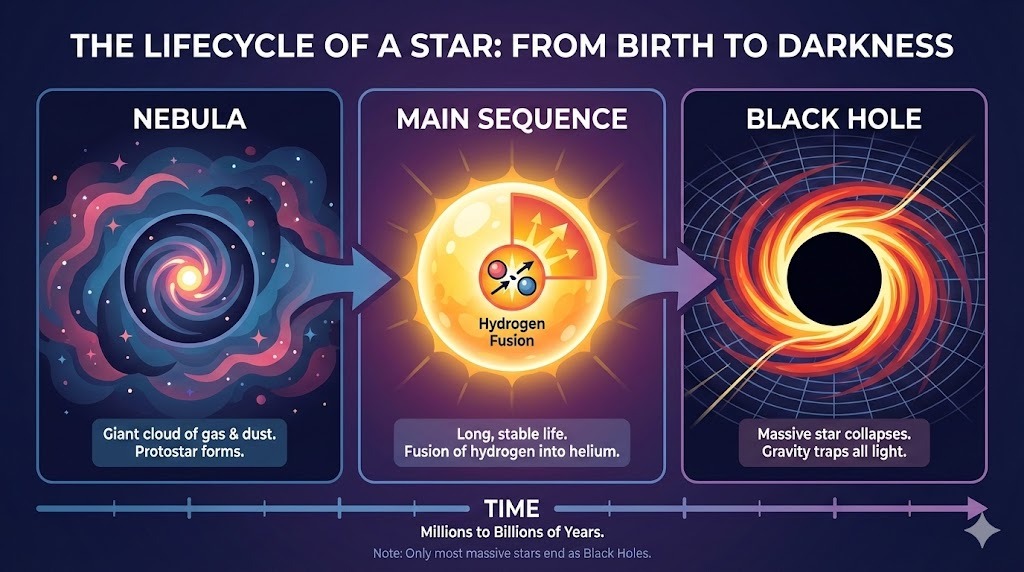
Pedí a ChatGPT un diseño complejo para una infografía sobre el ciclo de vida de una estrella:
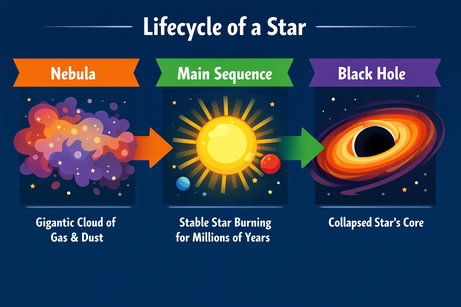
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
La salida sigue las instrucciones a la perfección y representa el texto sin errores. El estilo es preciso y consistente en toda la infografía.
La multimodalidad de ChatGPT nos obliga a ser precisos al insertar texto. Cuando pedí añadir una viñeta «aquí» (en un área seleccionada de la imagen), la devolvió como texto plano. Añadir la aclaración «en la imagen» solucionó el problema:
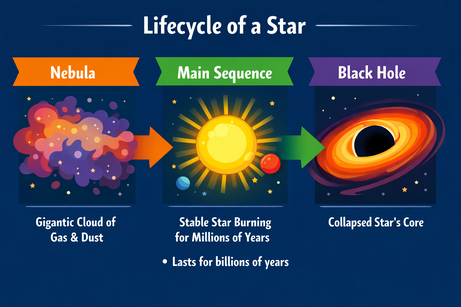
Prompt: «Add a bullet point to the image here that says: 'Lasts for billions of years'.»
Tras la aclaración, la viñeta se insertó en la posición correcta. La tipografía, el tamaño y el color encajan con el estilo del gráfico.
¿Cómo puedo acceder a ChatGPT Images?
ChatGPT Images ya está disponible para casi todos los usuarios en varias plataformas. El soporte para los planes Business y Enterprise llegará más adelante.
En la interfaz, puedes acceder de inmediato desde la web o la app móvil de ChatGPT a través de la pestaña Imágenes. Aunque no se conocen las cifras exactas, las cuentas Free tienen límites diarios estrictos y Plus y Pro disfrutan de cupos mayores y más estables.
Para desarrolladores, el nuevo modelo GPT-Image-1.5 puede usarse tanto a través de la API de OpenAI como de Azure OpenAI Service, disponible para generación y edición de imágenes. Mientras esperamos que se integre en suites creativas de terceros, ya es posible construir flujos de edición directamente en tus aplicaciones usando los endpoints v1/images/generations y v1/images/edits.
A diferencia de su predecesor, GPT-Image-1.5 expone la salida de imagen como tokens con precio independiente, usando endpoints específicos de imagen en lugar del unificado /v1/responses. Solo pagas por los tokens necesarios para generar los cambios, no por una imagen nueva completa cada vez.
Por eso se afirma que el nuevo modelo es aproximadamente un 20% más barato que su predecesor, aunque los precios por token no han cambiado respecto a GPT-Image-1.
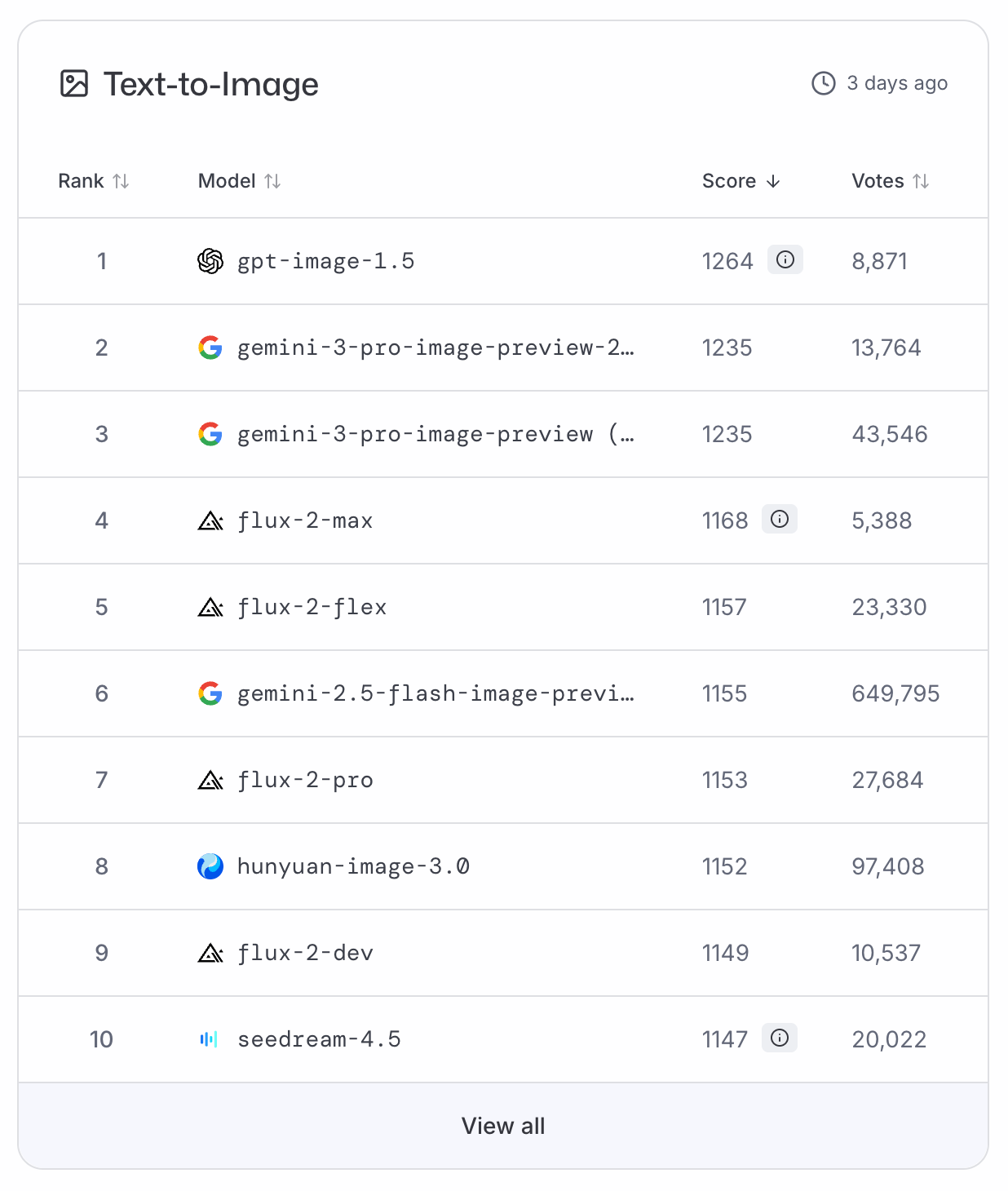
¿Qué tal es ChatGPT Images?
GPT-Image-1.5 se situó de inmediato en lo alto de los rankings de LMArena y ArtificialAnalysis de texto a imagen, relegando a Nano Banana Pro al segundo puesto. Como no hay datos de benchmark disponibles por ahora, debemos fiarnos de estos rankings basados en votos para una clasificación objetiva.
Parafraseando a un astronauta famoso: GPT-Image-1.5 es un pequeño paso para la industria, pero un gran salto para OpenAI.
Aunque la edición de precisión no es completamente nueva, incorporarla de forma nativa en ChatGPT es el mayor cambio de este lanzamiento. Eso sí, la precisión es clave: recuerda seleccionar solo lo necesario para evitar fallos como el «oso polar sin cabeza» que vimos en las pruebas.
Por mi experiencia, la actualización supone un salto de calidad notable, algo que también reflejan los rankings. Las imágenes estándar se sienten más vivas y las infografías mucho menos simplificadas que antes.
Ahora tienes mucho más control sobre cada salida, sustituyendo el antiguo flujo de redactar prompts complejos y cruzar los dedos. En gran parte, porque la conservación del detalle funciona muy bien. En nuestras pruebas, mantuvo los elementos completamente intactos.
La consistencia de personajes es sólida, aunque conviene vigilar el «efecto pegatina» y los problemas de perspectiva. Aunque las ediciones puntuales ayudan a corregirlo, siguen existiendo limitaciones en escenas abarrotadas.
ChatGPT Images vs. Nano Banana Pro
El rival a batir por ChatGPT Images es claramente Nano Banana Pro de Google. La siguiente tabla compara ambos modelos:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Modelo de edición |
Precisión: selección de área y edición in situ |
Razonamiento: chat integrado y enmascarado inteligente |
|
Flujo de trabajo |
Espacio creativo dedicado |
Función integrada en el chat |
|
Iteración |
Eficiente: regeneración parcial |
Exploratoria: remix |
|
Consistencia |
Alta retención de diseño y detalle |
Alta retención de diseño y detalle |
|
Ecosistema |
OpenAI y Azure |
Google / pila Gemini |
Aunque GPT-Image-1.5 y Nano Banana Pro ofrecen resultados excelentes, difieren en su filosofía de edición, en el flujo de trabajo y en su enfoque de cliente.
ChatGPT Images apuesta por el aislamiento al píxel, con fortaleza en el control manual: seleccionas un área exacta y la trata como un lienzo para inpainting mientras el resto de la imagen queda bloqueado. Nano Banana Pro, en cambio, intenta entender tu intención para aplicar los cambios adecuados.
En cuanto al flujo, ambas empresas han tomado caminos distintos: la pestaña Imágenes en ChatGPT se siente como un estudio creativo separado de las conversaciones, mientras que Nano Banana Pro está totalmente integrado en el hilo del chat.
Actualización: la nueva versión del modelo de generación de imágenes no Pro de Google, Nano Banana 2, introduce mejoras importantes. Aunque Nano Banana Pro mantiene una ligera ventaja, el nuevo modelo ofrece (casi) la misma calidad a mucha más velocidad.
Cuándo usar ChatGPT Images vs. Nano Banana Pro
Te sugerimos usar ChatGPT Images si necesitas corregir diseños, editar texto o hacer cambios precisos en una imagen existente sin alterar el estilo. Elige Nano Banana Pro si necesitas generar visualizaciones con muchos datos, remezclar varias imágenes o prefieres que un asistente inteligente interprete tu intención antes que el control manual.
Con los mismos prompts anteriores, recreé las imágenes de prueba. Personalmente, me gustaron más las infografías de Nano Banana Pro, mientras que las imágenes del oso estuvieron a la par.
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
Casos de uso de ChatGPT Images
A partir de nuestras pruebas y las fortalezas específicas de GPT-Image-1.5, el modelo destaca en procesos iterativos y edición de texto. Estos son algunos casos de uso clave:
- Flujos de marketing: Crear anuncios para redes sociales o fotos de producto donde cambian detalles concretos (p. ej., «Cambia el jersey de rojo a azul»)
- Infografías educativas: Generar diagramas para libros, presentaciones o blogs, como nuestro ejemplo del «ciclo de vida de una estrella»
- Storyboards: Visualizar un guion o cómic donde el mismo personaje debe aparecer en distintos lugares
- Moda: Usar creación híbrida de contenido para explorar combinaciones de outfits, como en este tutorial de armario con FLUX.2
- Interiorismo: Combinar un boceto o una foto con prompts para redecorar estancias en un estilo concreto
- Prototipos UI/UX: Visualizar rápidamente cómo podría ser la landing de una web o el packaging de un nuevo producto
Reflexiones finales
Desde el lanzamiento de Nano Banana Pro, OpenAI estaba bajo presión para ponerse al día. Con esta actualización prometedora, vuelve a la pelea por el modelo de texto a imagen más capaz. No es perfecto, pero si te centras en lo esencial —tipografía nítida y edición precisa— podrás lograr muy buenos resultados. Para empezar, prueba la función en tu interfaz de ChatGPT o en el OpenAI Playground. Para inspirarte, consulta la galería y la guía de prompts.
Si quieres empezar a crear herramientas con modelos GPT, nuestro itinerario de OpenAI Fundamentals es para ti.
¿Qué tipos de ediciones de imagen puede manejar ChatGPT Images?
¿En qué mejora GPT-Image-1.5 al modelo de imagen anterior?
¿ChatGPT Images está disponible para todo el mundo?
¿Pueden los desarrolladores usar el nuevo modelo de imagen a través de la API?


Author
Josef Waples

