Sim. O GPT-Image-1.5 está disponível na OpenAI API e inclui as mesmas melhorias do ChatGPT Images. Entradas e saídas de imagem são aproximadamente 20% mais baratas do que no GPT Image 1, o que o torna uma ótima opção para aplicações de marketing, ecommerce e fluxos de design.
Você quer começar a usar a IA generativa?
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

O que é o ChatGPT Images?
A nova aba Images do ChatGPT funciona como um hub criativo para tudo que é visual dentro da interface do ChatGPT e substitui a biblioteca pessoal de imagens. A mudança mais notável é a integração de ferramentas de edição direta que permitem alterar detalhes específicos de uma imagem mantendo todo o restante intacto.
O ChatGPT Images é alimentado pelo GPT-Image-1.5, o modelo de IA texto-para-imagem mais recente e avançado da OpenAI. Ele dá sequência ao lançamento do GPT-Image-1 em março de 2025, que foi um grande sucesso com mais de 700 milhões de imagens geradas na primeira semana.
Ele oferece preservação de detalhes e renderização de texto aprimorada, e a OpenAI afirma que é "até 4x" mais rápido que seu antecessor.
Os novos recursos foram liberados para todos os usuários, tanto no plano gratuito quanto nos pagos, na web, no app móvel e via API. Apenas contas Business e Enterprise ainda precisam aguardar o acesso.
Principais recursos do ChatGPT Images
Então, o que o ChatGPT Images oferece em comparação com o modelo anterior e com a concorrência? A OpenAI destaca especialmente as "edições precisas que preservam o que importa". Vamos conferir os novos recursos para entender o que isso significa.
Espaço criativo dedicado
A aba Images foi lançada como um hub de criação visual dentro da interface do ChatGPT. A ideia é separar a criação e a edição de imagens das conversas comuns.
Enquanto o antigo recurso Library também armazenava as imagens geradas, ele apenas levava você de volta à conversa onde foram criadas. Usava o contexto de todo o histórico para gerar uma nova imagem do zero, o que muitas vezes levava a alucinações em tópicos longos.
A nova abordagem, porém, é mais centrada na imagem: cada edição toma uma imagem como ponto de partida e altera apenas os aspectos selecionados, em vez de criar uma geração completamente nova.
As imagens viram artefatos persistentes, não ficam escondidas no histórico da conversa. Isso permite ciclos de feedback mais rápidos com novas variações e incentiva a experimentação, transformando a experiência de um fio de chat para algo mais próximo de uma tela de criação.
Para potencializar esse fluxo criativo, o workspace traz novas ferramentas de exploração para encurtar a distância entre ideia e execução. Dá para aplicar presets de estilo (como "sketch" ou "dramatic") ou navegar por estéticas em alta para pegar o próximo "Studio Ghibli". Para quem está começando, a interface oferece sugestões criativas e suporte proativo ao prompt para ajudar a refinar os resultados.
Preservação de detalhes e edição precisa
Provavelmente o recurso mais importante: a atualização permite selecionar partes específicas de uma imagem e modificá-las diretamente, sem alterar o restante da composição. O modelo é sensível ao contexto, ou seja, entende o que deve ser editado enquanto mantém os elementos ao redor consistentes.
Esse tipo de ajuste cirúrgico é possível graças à melhor preservação de detalhes do novo modelo.
Ele consegue manter objetos, iluminação, composição e a aparência das pessoas consistentes entre saídas e edições subsequentes. Além disso, o seguimento de instruções aprimorado contribui para a precisão ao preservar melhor as relações entre elementos.
A edição precisa é perfeita para corrigir pequenos problemas e experimentar detalhes específicos quando não é necessário refazer tudo. Ela também permite transformações criativas, como levar um elemento de uma imagem para a cena de outra.
Vale mencionar, porém, que o modelo tem dificuldade em manter a identidade exata de cada pessoa quando há muitas pessoas na mesma imagem.
Renderização de texto e realismo aprimorados
Um dos destaques do GPT-Image-1 foi lidar bem com textos mais longos e frases coerentes. A nova versão se apoia nessa base e agora consegue lidar com textos mais densos e menores do que antes.
Isso é especialmente útil para infográficos, onde os primeiros resultados impressionam, e abre novas possibilidades como texto em markdown dentro de uma imagem, por exemplo, em um jornal. Vamos testar infográficos mais adiante.
No entanto, segundo o comunicado da OpenAI, ainda persistem limitações em alguns idiomas específicos, como chinês, árabe e hebraico.
Embora não tenha sido o foco principal da atualização, o realismo das saídas melhorou bastante em relação ao modelo anterior. Dois casos em que isso aparece bem são reflexos (por exemplo, o brilho em uma foto) e muitos rostos pequenos em grandes multidões.
Como costuma acontecer, grandes upgrades trazem trade-offs em áreas específicas. Aqui, a capacidade de gerar alguns estilos artísticos regrediu. A OpenAI recomenda usar os filtros predefinidos na aba Images ou recorrer ao modelo anterior, que ainda está disponível como um GPT customizado.
Performance acelerada
As capacidades de edição direcionada também explicam boa parte do aumento de velocidade na geração. Embora a geração completa esteja visivelmente mais rápida, ela não chega ao número divulgado na nota da OpenAI. O GPT-Images-1.5 parece "até 4x mais rápido" principalmente porque regenera apenas o que muda durante as edições.
Da mesma forma, a redução de cerca de 20% no custo de API vem principalmente da regeneração parcial durante as edições, com ganhos adicionais de inferência mais eficiente, e não de gerações completas mais baratas.
No geral, os novos recursos permitem um uso mais eficiente e confiável, especialmente em fluxos via API.
Exemplos do ChatGPT Images
Os recursos anunciados são empolgantes. Coloquei tudo à prova com alguns prompts simples combinados com a nova ferramenta de seleção.
Testando a precisão das edições
O objetivo do primeiro teste foi avaliar a capacidade do modelo de lidar com mudanças iterativas sem perder qualidade. Primeiro, pedi para criar a imagem de um urso-pardo caminhando por uma floresta finlandesa durante o sol da meia-noite.

Prompt: "A brown bear walking through a dense Finnish forest during the midnight sun."
Na minha opinião, a qualidade da primeira saída é muito alta. O urso parece natural, o tipo de árvores e arbustos representa muito bem as florestas finlandesas (eu saberia!), e a posição baixa do sol condiz com o que se espera no norte da Finlândia durante o sol da meia-noite.
Além disso, a iluminação e as sombras no pelo do urso e no fundo parecem bem realistas. Ainda dá para notar que é IA, de alguma forma, embora os detalhes estejam caprichados.
Vamos tentar transformar o urso em um urso-polar e ver o que acontece. Não existem ursos-polares na Finlândia, mas, se tudo funcionar como deveria, o fundo deve permanecer igual.

Prompt: "Change the bear to a polar bear."
Como vemos, o fundo foi mantido totalmente intacto, exatamente como pretendido.
Na edição seguinte, selecionei a cabeça e os olhos do urso-polar e pedi para ele usar um par de óculos de sol vintage.

Prompt: "Put a pair of vintage sunglasses on the bear." (head selected)
Parece que descobrimos o que acontece quando você seleciona uma área grande demais. Embora o fundo e o corpo do urso tenham sido mantidos, a cabeça virou um grande par de óculos. Vamos tentar de novo, selecionando apenas os olhos.

Prompt: "Put a pair of vintage sunglasses on the bear." (eyes selected)
Bem legal, e bem melhor! Nesse primeiro teste, deu para ver o quanto a preservação de detalhes é poderosa: só precisamos definir os pontos importantes do cenário uma vez e pudemos iterar sobre o personagem principal sem nos preocupar com o fundo. Outro aprendizado é que o tamanho da área selecionada faz diferença.
Testando a consistência das transformações
Depois, testei a permanência do objeto em diferentes cenários e as limitações do modelo em multidões. Para isso, fiz nosso urso-polar viajar um pouco e tentei colocá-lo em uma cena movimentada do metrô de Tóquio.

Prompt: "Place this bear into a very busy subway scene in Tokyo."
Primeiro, a consistência do personagem é impressionante: o modelo preservou perfeitamente a postura e a identidade do urso e removeu o brilho do sol no pelo.
Porém, essa preservação rígida gerou um descompasso visual conhecido como "efeito adesivo". Como o modelo não atualizou o contexto de iluminação (mantendo a sombra direcional e os reflexos da floresta nos óculos), o urso parece um recorte 2D colado na cena, e não um objeto 3D dentro dela.
A perspectiva também quebra a ilusão: o urso flutua à frente de um transeunte que está fisicamente mais próximo da câmera.
Tentar corrigir essa última questão foi frustrante. Selecionei a área do transeunte e a interseção com o urso e pedi ao ChatGPT para corrigir a perspectiva. A cada variação, o modelo inseriu uma nova pessoa perto da câmera, assim:

Prompt: "Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back."
Parece que o modelo não conseguiu identificar a pessoa, mesmo selecionada, e por isso precisou criar um novo personagem para cumprir o comando do prompt.
Consertar a sombra e os reflexos dos óculos foi mais bem-sucedido. Usei as seguintes iterações:
- Sombra: Selecione o chão ao redor dos pés do urso e peça: "Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting."
- Óculos de sol: Selecione os óculos e peça: "Update the reflections of the sunglasses to match the subway environment."

Nosso urso-polar no metrô de Tóquio após corrigir sombra e reflexos dos óculos
Já ficou bem melhor, embora ainda não perfeito.
No geral, o segundo teste não foi tão bem quanto o primeiro. Embora a consistência entre elementos em diferentes imagens funcione bem, o reconhecimento de personagens parece chegar ao limite em cenas lotadas.
Testando a renderização de texto
Por fim, quis testar as novas capacidades de renderização de texto, especialmente em textos densos e com edições. Melhorias nessa área são bem-vindas porque, historicamente, modelos de visão se saem melhor com objetos, texturas e cenas, não com símbolos.
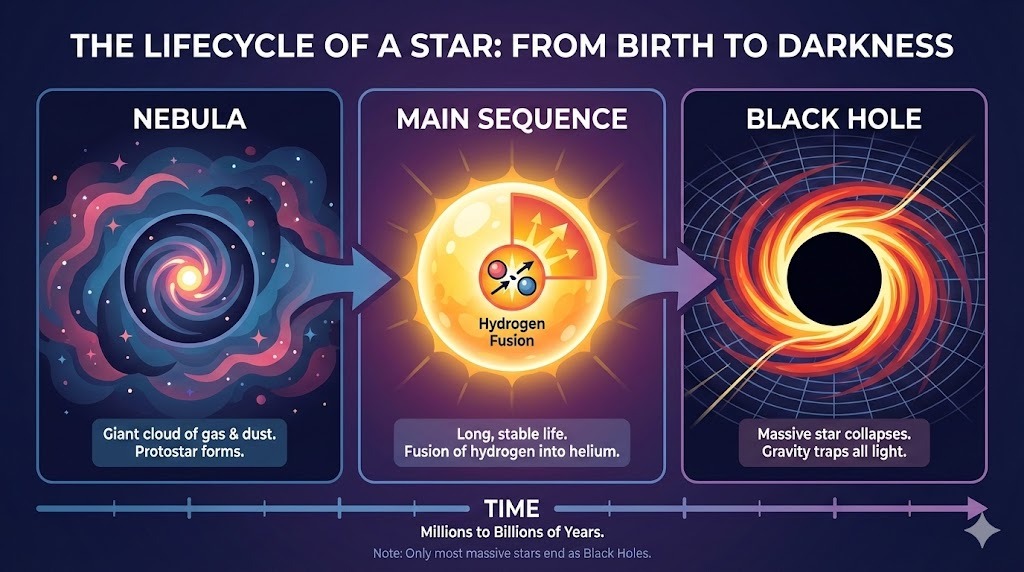
Pedi ao ChatGPT um layout complexo para um infográfico sobre o ciclo de vida de uma estrela:
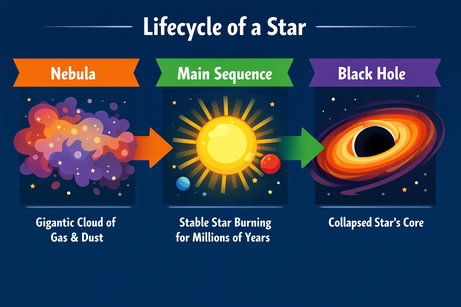
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
A saída segue as instruções perfeitamente e renderiza o texto sem erros. O estilo é fiel e consistente em todo o infográfico.
A multimodalidade de saída do ChatGPT exige precisão ao inserir texto. Quando pedi para adicionar um bullet point "aqui" (em uma área selecionada da imagem), ele apenas devolveu o bullet como texto. Acrescentar a frase "na imagem" resolveu:
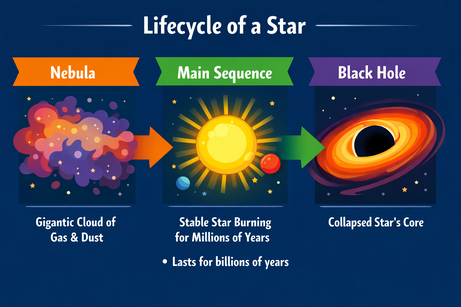
Prompt: "Add a bullet point to the image here that says: 'Lasts for billions of years'."
Depois do esclarecimento, o bullet foi inserido no lugar certo. Fonte, tamanho e cor combinam com o estilo do gráfico.
Como acessar o ChatGPT Images?
O ChatGPT Images já está disponível para quase todos os usuários em várias plataformas. Só falta o suporte para usuários dos planos Business e Enterprise, que chegará depois.
Na interface, você acessa os recursos imediatamente pela web ou pelo app móvel do ChatGPT na aba Images. Embora os números exatos não sejam públicos, há limites diários rígidos para contas Free e cotas progressivamente maiores e mais estáveis nos planos Plus e Pro.
Para desenvolvedores, o novo modelo GPT-Image-1.5 pode ser usado tanto pela OpenAI API quanto pelo Azure OpenAI Service, com geração e edição de imagens. Enquanto esperamos a integração nas principais suítes criativas de terceiros, já dá para construir fluxos de edição diretamente nos seus apps usando os endpoints v1/images/generations e v1/images/edits.
Ao contrário do antecessor, o GPT-Image-1.5 precifica a saída de imagem como tokens separados, usando endpoints específicos de imagem em vez do unificado /v1/responses. Você paga apenas pelos tokens necessários para gerar as mudanças, e não por uma imagem inteira a cada vez.
Por isso, o novo modelo é apontado como cerca de 20% mais barato que o anterior, embora os preços por token não tenham mudado em relação ao GPT-Image-1.
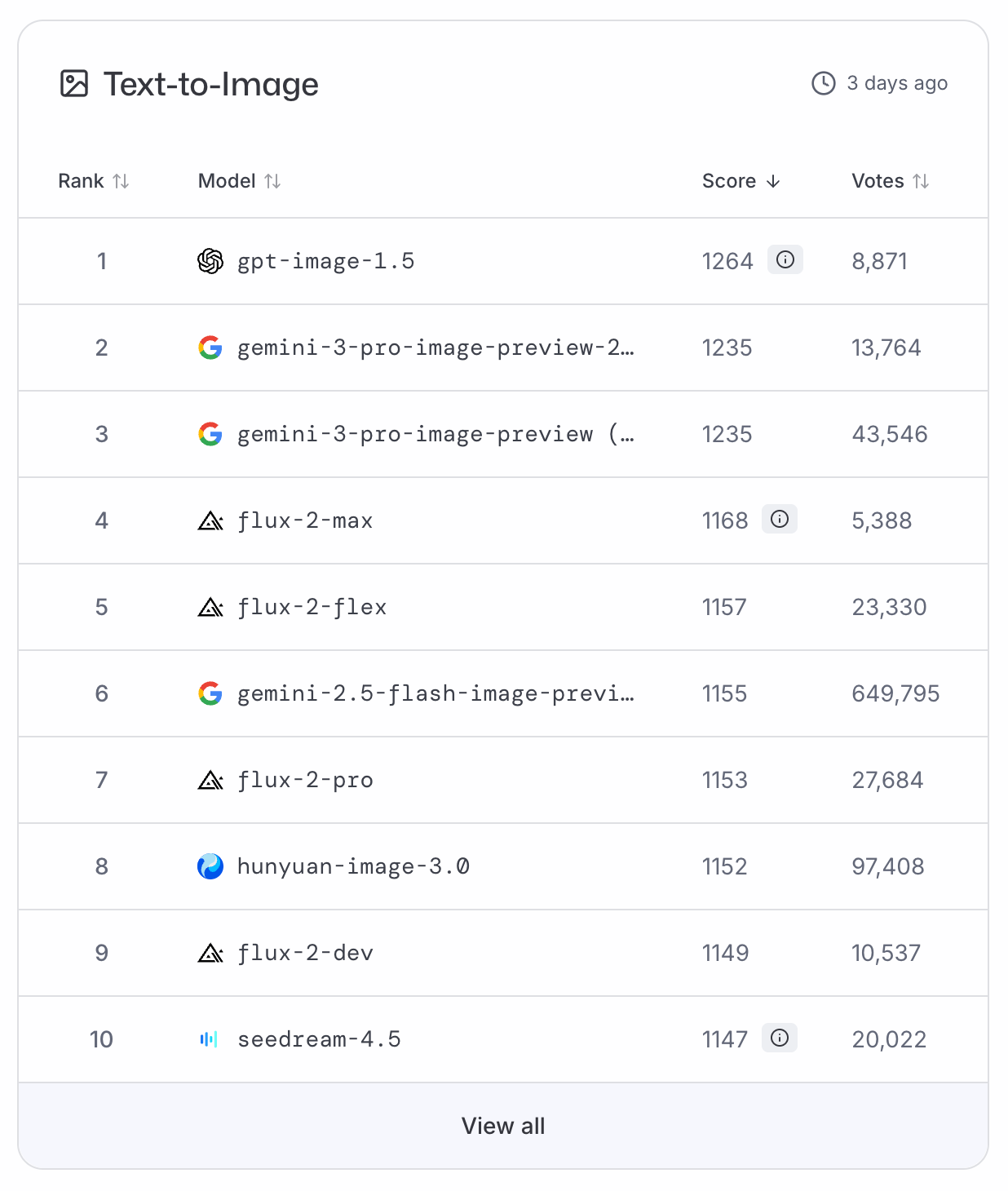
Quão bom é o ChatGPT Images?
O GPT-Image-1.5 subiu imediatamente ao topo dos rankings do LMArena e do ArtificialAnalysis para texto-para-imagem, deixando o Nano Banana Pro em segundo lugar. Como ainda não há dados de benchmark disponíveis, precisamos nos apoiar nesses rankings baseados em votação para uma classificação mais objetiva.
Parafraseando um famoso astronauta: o GPT-Image-1.5 é um pequeno passo para o setor, mas um salto gigantesco para a OpenAI.
Embora a edição precisa não seja totalmente nova, trazê-la de forma nativa ao ChatGPT é a grande virada deste lançamento. Porém, precisão é tudo: lembre-se de selecionar apenas o necessário para evitar falhas como o "urso-polar sem cabeça" do nosso teste.
Pela minha experiência, a atualização entrega um salto de qualidade significativo, o que também aparece nos rankings. Imagens padrão parecem mais vivas, e infográficos ficaram bem menos simplificados do que antes.
Os usuários agora têm muito mais controle sobre cada saída, substituindo o fluxo antigo de escrever prompts de acompanhamento complexos e torcer pelo melhor. Isso acontece principalmente porque a preservação de detalhes funciona muito bem. Em nossos testes, os elementos foram mantidos completamente intactos.
A consistência de personagens é forte, mas é bom ficar atento ao "efeito adesivo" e a problemas lógicos de perspectiva. Embora as edições direcionadas ajudem a corrigir isso com mais facilidade, limitações persistem em cenas lotadas.
ChatGPT Images vs. Nano Banana Pro
O concorrente a ser batido pelo ChatGPT Images é claramente o Nano Banana Pro do Google. A tabela a seguir compara os dois modelos:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Modelo de edição |
Precisão: seleção de área e edição in-place |
Raciocínio: conversa e máscara inteligente |
|
Fluxo de trabalho |
Workspace criativo dedicado |
Recurso integrado ao chat |
|
Iteração |
Eficiente: regeneração parcial |
Exploratória: remix |
|
Consistência |
Alta retenção de layout e detalhes |
Alta retenção de layout e detalhes |
|
Ecossistema |
OpenAI e Azure |
Google / stack Gemini |
Embora GPT-Image-1.5 e Nano Banana Pro entreguem resultados excelentes, eles diferem em filosofia de edição, fluxos de trabalho e foco no cliente.
O ChatGPT Images aposta no isolamento pixel a pixel, com força no controle manual: você seleciona uma área exata e ela vira uma tela para in-painting enquanto o resto fica travado. Já o Nano Banana Pro tenta entender a sua intenção para fazer as mudanças certas.
Quanto ao fluxo, as empresas também seguiram caminhos diferentes: a aba Images do ChatGPT parece um estúdio criativo, separado das conversas, enquanto o Nano Banana Pro fica totalmente integrado ao fluxo do chat.
Atualização: a nova versão do modelo não-pro de geração de imagens do Google, o Nano Banana 2, trouxe melhorias importantes. Embora o Nano Banana Pro ainda tenha uma leve vantagem, o novo modelo oferece (quase) a mesma qualidade com velocidade bem maior.
Quando usar ChatGPT Images vs. Nano Banana Pro
Sugiro usar o ChatGPT Images quando você precisar corrigir layouts, editar texto ou fazer mudanças precisas em uma imagem existente sem alterar o estilo. Escolha o Nano Banana Pro se precisar gerar visuais ricos em dados, remixar várias imagens ou preferir que um assistente inteligente deduza sua intenção em vez do controle manual.
Usando os mesmos prompts acima, refiz as imagens de teste. Pessoalmente, gostei mais dos infográficos do Nano Banana Pro, enquanto as imagens do urso ficaram equivalentes.
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
Casos de uso do ChatGPT Images
Com base nos nossos testes práticos e nas forças específicas do GPT-Image-1.5, o modelo brilha em processos iterativos e na edição de texto. Alguns casos de uso de destaque:
- Workflow de marketing: criação de anúncios para redes sociais ou fotos de produto em que detalhes específicos mudam (ex.: "mude o suéter de vermelho para azul")
- Infográficos educacionais: geração de diagramas para livros, apresentações ou blogs, como no nosso exemplo de "ciclo de vida de uma estrela"
- Storyboarding: visualização de um roteiro ou HQ em que o mesmo personagem precisa aparecer em locais diferentes
- Moda: uso de criação híbrida para explorar combinações de looks visualmente, como neste tutorial de visualizador de guarda-roupa com FLUX.2
- Design de interiores: combinar um rascunho ou foto com prompts para redecorar ambientes em um estilo específico
- Mockups de UI/UX: visualizar rapidamente como pode ficar a landing page de um site ou a embalagem de um novo produto
Considerações finais
Desde o lançamento do Nano Banana Pro, a OpenAI vinha sob pressão para acompanhar o ritmo. Com esta atualização promissora, ela volta à disputa pelo modelo texto-para-imagem mais capaz. Não é perfeito, mas, focando no essencial — tipografia nítida e edição precisa — dá para alcançar ótimos resultados. Para começar, experimente o recurso na interface do seu ChatGPT ou no OpenAI Playground. Para se inspirar, veja a galeria e o guia de prompts.
Se você quer começar a criar ferramentas com modelos GPT, nossa trilha de habilidades OpenAI Fundamentals é para você.
Que tipos de edição de imagem o ChatGPT Images consegue fazer?
Como o GPT-Image-1.5 é melhor que o modelo anterior?
O ChatGPT Images está disponível para todo mundo?
Desenvolvedores podem usar o novo modelo de imagem pela API?


Author
Josef Waples


