Oui. GPT-Image-1.5 est disponible via l'API OpenAI et inclut les mêmes améliorations que ChatGPT Images. Les entrées et sorties image sont environ 20 % moins chères que GPT Image 1, ce qui le rend adapté à des applications comme le marketing, l'e-commerce et les workflows de design.
Vous souhaitez vous lancer dans l'IA générative ?
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Qu'est-ce que ChatGPT Images ?
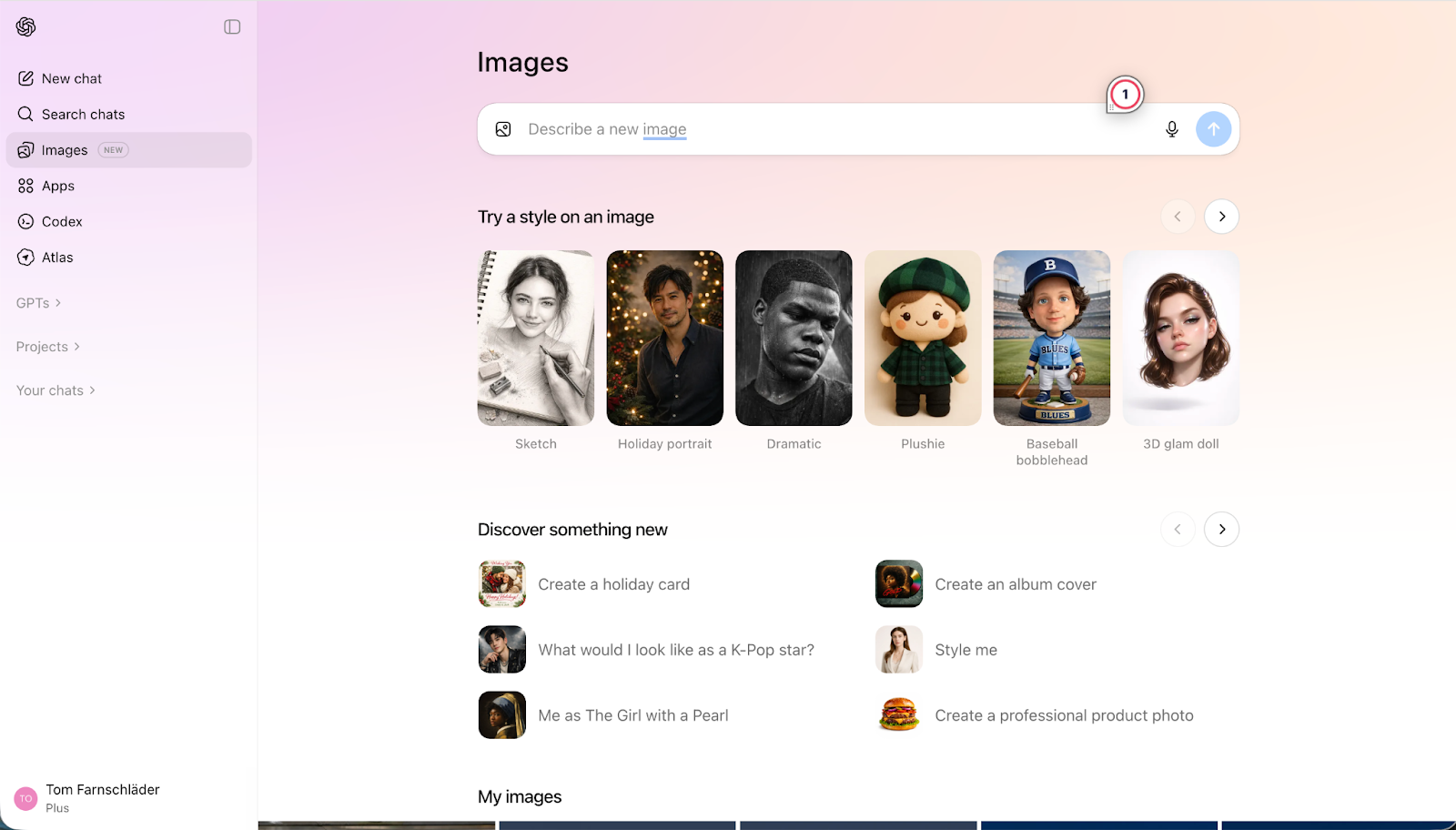
Le nouvel onglet Images de ChatGPT sert d'espace créatif pour tout ce qui est visuel dans l'interface, et remplace la bibliothèque d'images personnelle. Le changement le plus notable est l'intégration d'outils d'édition directe permettant de cibler des détails précis dans une image tout en conservant le reste inchangé.
ChatGPT Images est propulsé par GPT-Image-1.5, le modèle IA texte→image le plus récent et le plus avancé d'OpenAI. Il s'appuie sur la sortie du modèle GPT-Image-1 en mars 2025, un grand succès avec plus de 700 millions d'images générées la première semaine.
Il offre une meilleure conservation des détails et un rendu de texte amélioré, et serait jusqu'à "4×" plus rapide que son prédécesseur.
Les nouvelles fonctionnalités sont déployées pour tous les utilisateurs, gratuits et payants, sur le web, l'app mobile et l'API. Seuls les comptes Business et Enterprise doivent encore patienter.
Fonctionnalités clé de ChatGPT Images
Alors, qu'apporte ChatGPT Images par rapport à son précédent modèle et à la concurrence ? OpenAI met notamment en avant des "retouches précises qui préservent l'essentiel". Voyons concrètement ce que cela signifie.
Espace de création dédié
L'onglet Images a été conçu comme un hub de création visuelle au sein de l'interface. L'idée est de séparer la création et l'édition d'images des interactions de chat classiques.
L'ancienne Bibliothèque conservait bien les images générées, mais ne proposait que de revenir à la conversation où elles avaient été créées. Elle exploitait le contexte de tout l'historique pour générer une nouvelle image à partir de zéro, au risque de provoquer des hallucinations dans les fils très longs.
La nouvelle approche est centrée sur l'image : chaque retouche part d'une image existante et ne modifie que des éléments sélectionnés, au lieu de recréer une génération complète.
Les images deviennent des artefacts persistants, et ne se perdent plus dans l'historique. Résultat : des boucles de feedback plus rapides avec de nouvelles variations, plus d'expérimentation, et une expérience qui ressemble davantage à un canvas qu'à un fil de discussion.
Pour entretenir ce flux créatif, l'espace introduit des outils d'exploration qui facilitent le passage de l'idée à l'exécution. Vous pouvez appliquer des préréglages de style (par exemple "croquis" ou "dramatique") ou parcourir des esthétiques tendance pour ne pas manquer le prochain "Studio Ghibli". Les moins expérimentés bénéficient de suggestions créatives et d'une aide proactive au prompt pour affiner les résultats.
Conservation des détails et retouche de précision
C'est sans doute la nouveauté la plus importante : l'outil permet de sélectionner des parties précises d'une image et de les modifier directement, sans altérer le reste de la composition. Le modèle est contextuel : il comprend ce qu'il faut éditer tout en conservant les éléments environnants cohérents.
Ces retouches tranchées sont possibles grâce aux progrès du modèle en matière de conservation des détails.
Il parvient à maintenir la cohérence des objets, de la lumière, de la composition et de l'apparence des personnes entre les différents rendus et retouches successives. L'amélioration du suivi des instructions renforce encore la précision en préservant mieux les relations entre éléments.
La retouche de précision est idéale pour corriger des détails ou expérimenter sur des éléments ciblés quand une régénération complète n'est pas nécessaire. Elle autorise également des transformations créatives, comme intégrer un élément d'une image dans la scène d'une autre.
Précision utile : le modèle peine à conserver l'identité exacte de chaque personne lorsque l'image contient beaucoup de monde.
Rendu du texte et réalisme améliorés
L'une des forces de GPT-Image-1 était sa capacité à gérer des textes longs et des phrases cohérentes. La nouvelle version pousse plus loin et gère désormais des textes plus denses et plus petits.
C'est particulièrement utile pour les infographies, où les premiers résultats sont très convaincants, et ouvre des possibilités comme l'intégration de texte mise en forme dans une image, par exemple dans un journal. Nous testerons les infographies plus loin.
Cependant, d'après OpenAI, des limitations persistent pour certaines langues comme le chinois, l'arabe ou l'hébreu.
Même si ce n'était pas l'axe principal, le réalisme des sorties progresse nettement par rapport au modèle précédent. C'est flagrant, par exemple, sur les reflets : l'éblouissement d'une photo, ou les nombreux visages dans une foule.
Comme souvent, ces avancées s'accompagnent de compromis : la capacité à générer certains styles artistiques a reculé. OpenAI recommande d'utiliser les filtres prédéfinis dans l'onglet Images ou de revenir au modèle précédent, toujours disponible en tant que GPT personnalisé.
Performances accélérées
Les capacités de retouche ciblée expliquent en grande partie la hausse de vitesse. La génération complète est plus rapide, mais ne semble pas atteindre le chiffre avancé dans la note d'OpenAI. GPT-Images-1.5 paraît "jusqu'à 4× plus rapide" surtout parce qu'il ne régénère que ce qui change lors des retouches.
De même, la baisse d'environ 20 % du coût API vient principalement de cette régénération partielle pendant les éditions, avec des gains complémentaires liés à une inférence plus efficace plutôt qu'à des générations intégrales moins chères.
Au global, ces nouveautés permettent un usage plus efficace et plus fiable, notamment pour les workflows API.
Exemples avec ChatGPT Images
Les fonctionnalités annoncées sont alléchantes. Je les ai testées avec quelques prompts simples et le nouvel outil de sélection.
Tester la précision des retouches
Objectif du premier test : évaluer la capacité du modèle à gérer des modifications itératives sans dégrader la qualité. J'ai d'abord demandé une image d'un ours brun marchant dans une forêt finlandaise sous le soleil de minuit.

Prompt : « Un ours brun marchant dans une forêt finlandaise dense sous le soleil de minuit. »
La première sortie est, à mon sens, de très haute qualité. L'ours paraît naturel, le type d'arbres et de buissons représente bien les forêts finlandaises (je m'y connais !), et la position basse du soleil correspond à ce qu'on observe dans le nord de la Finlande pendant le soleil de minuit.
La lumière et les ombres sur le pelage de l'ours, comme en arrière-plan, sont assez réalistes. On devine encore la patte de l'IA, mais les détails sont soignés.
Essayons de transformer l'ours en ours polaire pour voir. Il n'y a pas d'ours polaires en Finlande, mais si tout se passe bien, l'arrière-plan devrait rester identique.

Prompt : « Remplace l'ours par un ours polaire. »
Comme on le voit, l'arrière-plan est resté strictement intact, comme prévu.
Pour la retouche suivante, j'ai sélectionné la tête et les yeux de l'ours polaire et je lui ai mis une paire de lunettes de soleil vintage.

Prompt : « Mettez une paire de lunettes de soleil vintage à l'ours. » (tête sélectionnée)
On voit ce qui se passe quand la zone sélectionnée est trop grande. Le fond et le corps de l'ours sont cohérents, mais la tête s'est transformée en gigantesques lunettes. Retentons en ne sélectionnant que les yeux.

Prompt : « Mettez une paire de lunettes de soleil vintage à l'ours. » (yeux sélectionnés)
Beau résultat, nettement meilleur ! Ce premier test montre à quel point la conservation des détails est efficace : il suffit de définir une fois les éléments clés de la scène, puis d'itérer sur le personnage sans craindre pour l'arrière-plan. Autre enseignement : la taille de la fenêtre de sélection compte.
Tester la cohérence des transformations
Ensuite, j'ai testé la permanence de l'objet selon les décors et les limites du modèle dans les foules. J'ai fait voyager notre ours polaire dans une station de métro bondée à Tokyo.

Prompt : « Placez cet ours dans une scène de métro très animée à Tokyo. »
Première constatation : l'identité du personnage est remarquablement conservée : posture et traits identiques, éclat du soleil supprimé sur le pelage.
Mais cette conservation rigide entraîne un effet de "stickers" : le modèle n'ayant pas adapté la lumière (ombre directionnelle et reflets de forêt encore visibles dans les lunettes), l'ours ressemble à un découpage 2D collé sur la scène, plutôt qu'à un objet 3D qui l'habite.
La perspective casse aussi l'illusion : l'ours flotte devant un passant pourtant plus proche de la caméra.
Corriger ce dernier point fut frustrant. J'ai sélectionné la zone du passant et son intersection avec l'ours, puis demandé à ChatGPT d'ajuster la perspective. À chaque variante, le modèle a inséré une nouvelle personne au premier plan, comme ici :

Prompt : « Corrigez la perspective : le dos du passant sélectionné est au premier plan et doit masquer partiellement l'ours. L'ours se tient derrière son dos. »
Le modèle n'a visiblement pas identifié la personne, même sélectionnée, et a donc créé un nouveau personnage pour exécuter l'instruction.
En revanche, corriger l'ombre et les reflets des lunettes a été plus concluant. Voici les itérations employées :
- Ombre : Sélectionnez le sol autour des pattes de l'ours et indiquez : « Remplacez l'ombre actuelle par une ombre douce et diffuse sur le carrelage du métro, cohérente avec l'éclairage fluorescent au plafond. »
- Lunettes : Sélectionnez les lunettes et demandez : « Mettez à jour les reflets des lunettes pour correspondre à l'environnement du métro. »

Notre ours polaire dans le métro de Tokyo après correction de l'ombre et des reflets des lunettes
C'est déjà bien mieux, même si ce n'est pas parfait.
Globalement, ce deuxième test est moins concluant que le premier. Si la cohérence des éléments entre différentes images fonctionne bien, la reconnaissance des personnages montre ses limites dans les foules.
Tester le rendu du texte
J'ai enfin testé les nouvelles capacités de rendu du texte, notamment pour du texte dense et en phase d'édition. Ces progrès sont bienvenus : historiquement, les modèles de vision excellent sur les objets, textures et scènes, moins sur les symboles.
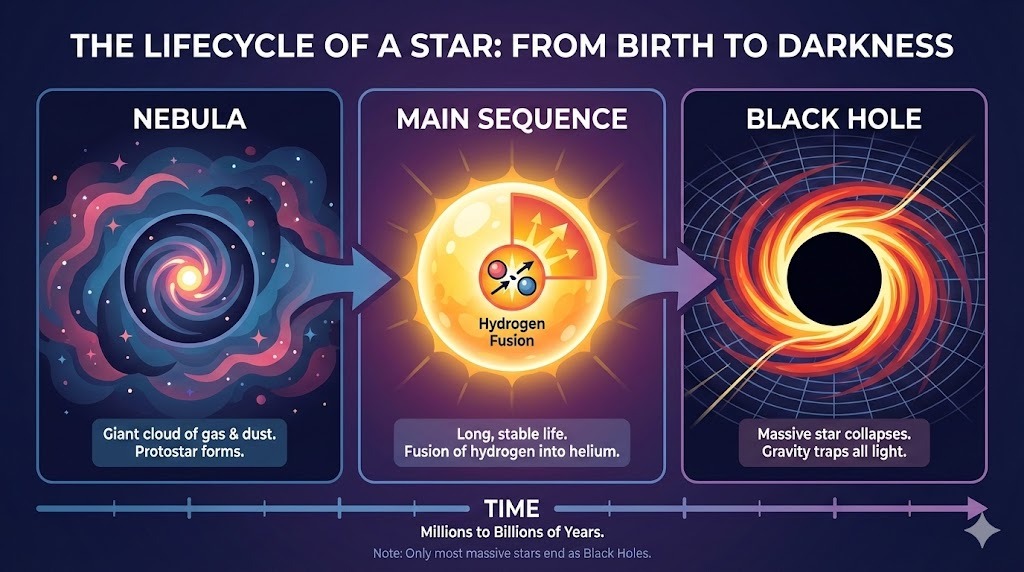
J'ai demandé à ChatGPT une mise en page complexe pour une infographie sur le cycle de vie d'une étoile :
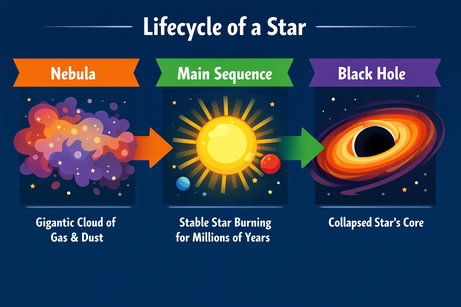
Prompt : "Une infographie horizontale expliquant le 'Cycle de vie d'une étoile'. Trois sections : Nébuleuse, Séquence principale, Trou noir. Style vectoriel plat."
La sortie suit parfaitement les instructions et rend le texte sans erreur. Le style est juste et homogène dans toute l'infographie.
La multimodalité de ChatGPT impose d'être explicite lors de l'insertion de texte. En demandant d'ajouter une puce "ici" (sur une zone sélectionnée), il a renvoyé la puce en sortie texte. En précisant "dans l'image", tout est rentré dans l'ordre :
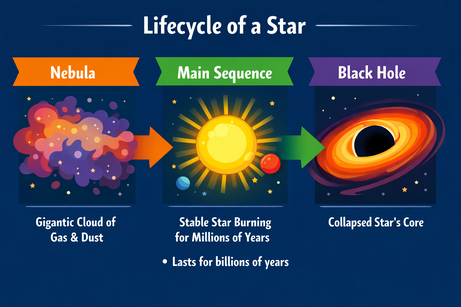
Prompt : « Ajoutez dans l'image, ici, une puce disant : 'Dure des milliards d'années'. »
Après clarification, la puce a été insérée au bon endroit. La police, la taille et la couleur correspondent au style du visuel.
Comment accéder à ChatGPT Images ?
ChatGPT Images est désormais disponible pour presque tous les utilisateurs et plateformes. Seuls les comptes Business et Enterprise n'y ont pas encore accès : cela arrivera plus tard.
Dans l'UI, vous pouvez l'utiliser immédiatement sur le web ou l'app mobile, via l'onglet Images. Même si les chiffres exacts ne sont pas publics, des limites quotidiennes strictes s'appliquent aux comptes Free, avec des quotas plus élevés et stables en offres Plus et Pro.
Côté développeurs, le nouveau modèle GPT-Image-1.5 est accessible via l'API OpenAI et Azure OpenAI Service, pour la génération et l'édition d'images. En attendant son intégration dans les grandes suites créatives, vous pouvez déjà construire des workflows d'édition dans vos applications avec les endpoints v1/images/generations et v1/images/edits.
Contrairement à son prédécesseur, GPT-Image-1.5 facture la sortie image en jetons au prix distinct, via des endpoints spécifiques à l'image plutôt qu'en /v1/responses unifié. Vous ne payez que les jetons nécessaires aux changements, pas une image complète à chaque fois.
D'où un coût annoncé environ 20 % inférieur à la version précédente, même si les prix par jeton n'ont pas changé par rapport à GPT-Image-1.
Quelle est la qualité de ChatGPT Images ?
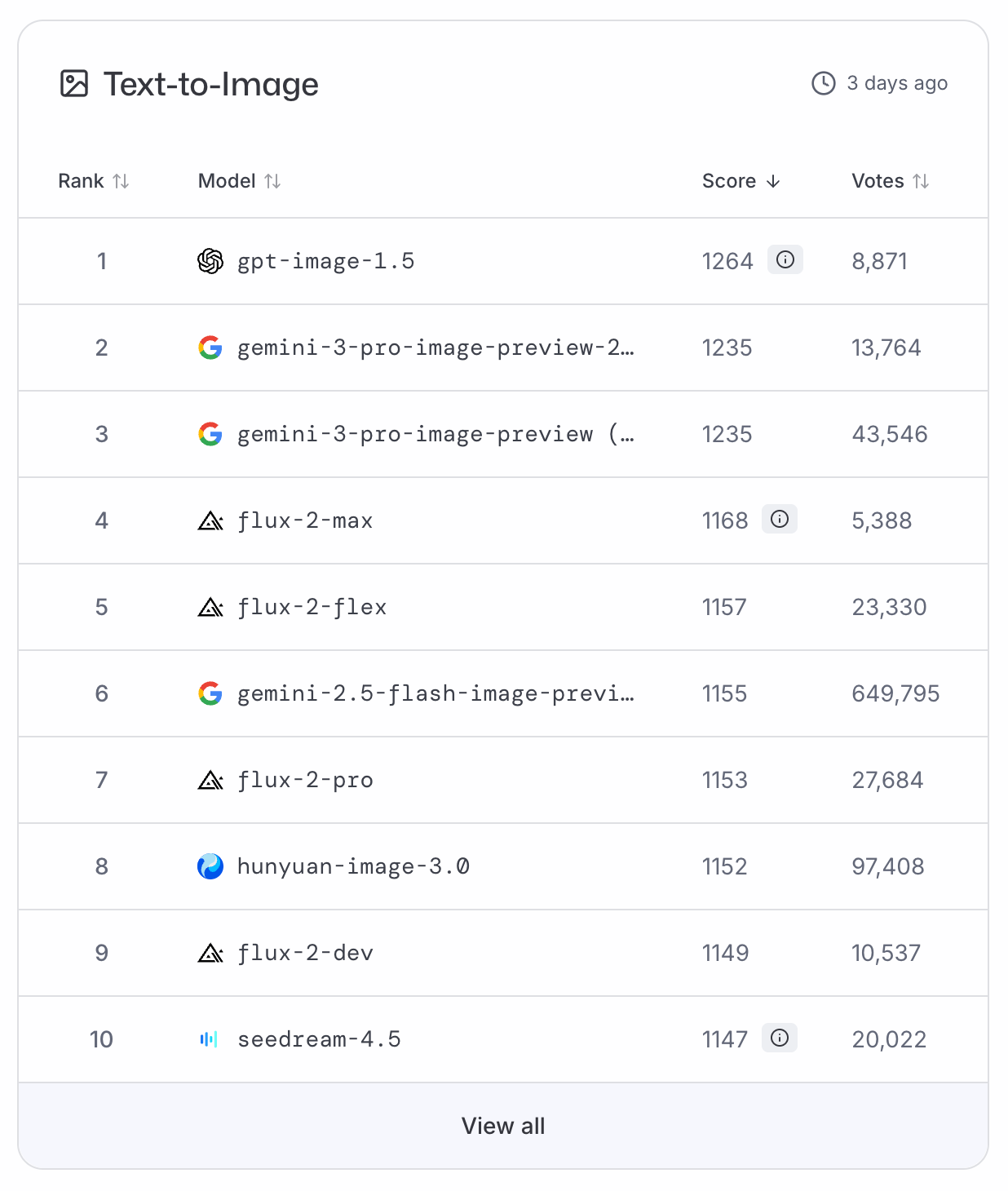
GPT-Image-1.5 s'est immédiatement hissé en tête des classements LMArena et ArtificialAnalysis pour le texte→image, reléguant Nano Banana Pro à la 2ème place. Faute de benchmark public, on s'appuie sur ces classements par votes pour une référence objective.
Pour paraphraser un célèbre astronaute : GPT-Image-1.5 est un petit pas pour l'industrie, mais un grand bond pour OpenAI.
Si la retouche précise n'est pas une invention en soi, son intégration native dans ChatGPT constitue le plus grand changement. En revanche, la précision est cruciale : sélectionnez uniquement les zones nécessaires pour éviter les ratés, comme l'"ours polaire sans tête" de nos tests.
Selon mon expérience, la qualité fait un vrai bond, ce que corroborent les classements. Les images standards sont plus vivantes et les infographies paraissent bien moins simplistes qu'avant.
Les utilisateurs ont désormais un contrôle nettement plus fin sur chaque rendu, remplaçant l'ancien rituel des prompts de suivi complexes et de l'espoir. Essentiel : la conservation des détails fonctionne très bien. Dans nos tests, les éléments sont restés parfaitement intacts.
La cohérence des personnages est solide, même s'il faut se méfier de l'effet "stickers" et des incohérences de perspective. Les retouches ciblées facilitent les corrections, mais des limites persistent dans les scènes très peuplées.
ChatGPT Images vs Nano Banana Pro
Le concurrent à battre pour ChatGPT Images est clairement Nano Banana Pro de Google. Le tableau suivant compare les deux modèles :
|
ChatGPT Images |
Nano Banana Pro |
|
|
Modèle d'édition |
Précision : sélection de zone et édition in situ |
Raisonnement : conversationnel et masquage intelligent |
|
Workflow |
Espace de création dédié |
Fonction intégrée au chat |
|
Itération |
Efficiente : régénération partielle |
Exploratoire : remix |
|
Cohérence |
Haute rétention de mise en page et de détails |
Haute rétention de mise en page et de détails |
|
Écosystème |
OpenAI & Azure |
Google / pile Gemini |
Si GPT-Image-1.5 et Nano Banana Pro livrent tous deux d'excellents résultats, ils diffèrent par leur philosophie d'édition, leur workflow et leur cible client.
ChatGPT Images mise sur l'isolation au pixel près, avec un atout de contrôle manuel : vous sélectionnez une zone exacte, traitée comme un canvas d'inpainting, tandis que le reste est verrouillé. Nano Banana Pro, lui, cherche à comprendre votre intention pour appliquer les bons changements.
Côté workflow, les approches divergent : l'onglet Images de ChatGPT ressemble à un studio de création, séparé des conversations, alors que Nano Banana Pro est pleinement intégré au flux de chat.
Mise à jour : la nouvelle version du modèle non pro de génération d'images de Google, Nano Banana 2, apporte des améliorations notables. Nano Banana Pro garde une légère avance, mais le nouveau modèle offre une qualité (presque) équivalente à une vitesse bien supérieure.
Quand utiliser ChatGPT Images vs Nano Banana Pro
Privilégiez ChatGPT Images si vous devez corriger des mises en page, éditer du texte ou effectuer des changements précis sur une image existante sans en altérer le style. Optez pour Nano Banana Pro si vous devez générer des visuels riches en données, remixer plusieurs images, ou si vous préférez un assistant capable d'inférer votre intention plutôt qu'un contrôle manuel.
Avec les mêmes prompts que ci-dessus, j'ai recréé les images de test. Personnellement, j'ai préféré les infographies de Nano Banana Pro, tandis que les images de l'ours se valaient.
Prompt : "Une infographie horizontale expliquant le 'Cycle de vie d'une étoile'. Trois sections : Nébuleuse, Séquence principale, Trou noir. Style vectoriel plat." (Nano Banana Pro)
Cas d'usage de ChatGPT Images
D'après nos tests et les points forts de GPT-Image-1.5, le modèle excelle dans les processus itératifs et l'édition de texte. Exemples prioritaires :
- Workflow marketing : créer des publicités sociales ou photos produits où certains détails changent (ex. : « Passez le pull du rouge au bleu »)
- Infographies éducatives : générer des schémas pour manuels, présentations ou blogs, comme notre exemple sur le « cycle de vie d'une étoile »
- Storyboard : visualiser un script ou une BD où le même personnage doit apparaître dans différents lieux
- Mode : exploiter la création de contenu hybride pour explorer visuellement des associations de tenues, comme dans ce tutoriel FLUX.2 de visualisation de dressing
- Décoration d'intérieur : combiner croquis ou photo et prompts pour redécorer des pièces dans un style donné
- Maquettes UI/UX : visualiser rapidement une landing page ou un packaging pour un nouveau produit
Conclusion
Depuis la sortie de Nano Banana Pro, OpenAI était sous pression. Avec cette mise à jour prometteuse, l'entreprise revient dans la course au meilleur modèle texte→image. Ce n'est pas parfait, mais en misant sur l'essentiel — typographie nette et édition précise — vous obtiendrez de bons résultats. Pour vous lancer, testez la fonction dans votre interface ChatGPT ou dans le Playground d'OpenAI. Pour l'inspiration, consultez la galerie et le guide de prompts.
Si vous souhaitez commencer à créer des outils avec les modèles GPT, notre parcours de OpenAI Fundamentals est fait pour vous.
Quelles retouches d'images ChatGPT Images peut-il gérer ?
En quoi GPT-Image-1.5 est-il meilleur que le modèle d'image précédent ?
ChatGPT Images est-il disponible pour tout le monde ?
Les développeurs peuvent-ils utiliser le nouveau modèle d'image via l'API ?


Author
Josef Waples

