Ja. GPT-Image-1.5 ist in der OpenAI API verfügbar und bietet dieselben Verbesserungen wie ChatGPT Images. Bildinputs und -outputs sind etwa 20% günstiger als bei GPT Image 1 und eignen sich damit gut für Anwendungsfälle wie Marketing, E-Commerce und Design-Workflows.
Willst du mit generativer KI beginnen?
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Was ist ChatGPT Images?
Der neue Tab „Images“ ist der kreative Hub für alles Visuelle in der ChatGPT-Oberfläche und ersetzt die persönliche Bildbibliothek. Der größte Unterschied: Direkte Bearbeitungstools sind integriert, mit denen du gezielt einzelne Bilddetails änderst, während alles andere unverändert bleibt.
ChatGPT Images wird von GPT-Image-1.5 angetrieben, OpenAIs neuestem und fortschrittlichstem Text-zu-Bild-Modell. Es baut auf dem Release von GPT-Image-1 im März 2025 auf, das in der ersten Woche über 700 Millionen Bilder generieren ließ.
Es bietet verbesserte Detailtreue und präziseres Textrendering und soll bis zu „4× schneller“ sein als der Vorgänger.
Die neuen Funktionen wurden für alle Nutzer ausgerollt – Free und Paid – in Web, Mobile und API. Einzig Business- und Enterprise-Accounts müssen noch auf den Zugriff warten.
Die wichtigsten Funktionen von ChatGPT Images
Was bringt ChatGPT Images gegenüber dem bisherigen Modell und der Konkurrenz? OpenAI hebt besonders „präzise Bearbeitungen, die Wesentliches erhalten“ hervor. Werfen wir einen Blick auf die Features und was dahinter steckt.
Eigener Kreativ-Arbeitsbereich
Der Images-Tab wurde als visueller Kreativhub in der ChatGPT-UI eingeführt. Ziel ist es, Bildgenerierung und -bearbeitung von normalen Chats zu trennen.
Die bisherige Library speicherte zwar ebenfalls generierte Bilder, führte aber nur zurück in das damalige Gespräch. Neue Bilder wurden aus dem gesamten Gesprächskontext heraus erstellt – in langen Threads oft mit Halluzinationen als Folge.
Der neue Ansatz stellt das Bild ins Zentrum: Jede Bearbeitung nimmt ein bestehendes Bild als Ausgangspunkt und ändert nur ausgewählte Aspekte – statt eine komplette Neugenerierung anzustoßen.
Bilder sind persistente Artefakte und verschwinden nicht mehr im Chatverlauf. Das ermöglicht schnellere Feedback-Schleifen mit Variationen und fördert Experimentieren – die Erfahrung wechselt praktisch vom Chat-Thread zur Canvas.
Um diesen Flow zu unterstützen, bringt der Workspace neue Explorationstools mit, die die Lücke zwischen Idee und Umsetzung schließen. Du kannst integrierte Stil-Presets anwenden (z. B. „Sketch“ oder „Dramatic“) oder durch angesagte Ästhetiken stöbern, um den nächsten „Studio Ghibli“-Trend zu erwischen. Für Einsteiger gibt es kreative Vorschläge und proaktive Prompt-Hilfen, um Ergebnisse zu verfeinern.
Detailtreue und präzise Bearbeitung
Das wohl wichtigste neue Feature: Du kannst gezielt Bereiche im Bild auswählen und direkt ändern – ohne die restliche Komposition anzutasten. Das Modell ist kontextsensitiv, versteht also, was bearbeitet werden soll, und hält Umgebungselemente konsistent.
Solche punktgenauen Edits werden durch die verbesserte Detailerhaltung des neuen Modells möglich.
Objekte, Licht, Komposition und das Erscheinungsbild von Personen bleiben über Ausgaben und nachfolgende Edits hinweg konsistent. Auch das bessere Befolgen von Anweisungen trägt zur Präzision bei, weil Beziehungen zwischen Elementen zuverlässiger erhalten bleiben.
Präzisionsedits sind ideal, um kleine Probleme zu beheben oder einzelne Details auszuprobieren, wenn keine vollständige Neugenerierung nötig ist. Sie ermöglichen auch kreative Transformationen, etwa wenn ein Element aus einem Bild in eine andere Szene versetzt wird.
Allerdings hat das Modell Schwierigkeiten, in Bildern mit vielen Personen die genaue Identität jeder einzelnen konstant zu halten.
Besseres Textrendering und mehr Realismus
Eine der großen Stärken des Vorgängers GPT-Image-1 war bereits der Umgang mit längeren Texten und zusammenhängenden Sätzen. Darauf baut das neue Release auf und verarbeitet jetzt noch dichteren und kleineren Text.
Das ist vor allem für Infografiken hilfreich – die ersten Ergebnisse sind beeindruckend – und eröffnet neue Möglichkeiten, etwa Text in Bildern, z. B. in einer Zeitung, sauber zu setzen. Später testen wir Infografiken im Detail.
Laut OpenAIs Statement bestehen jedoch weiterhin Einschränkungen bei bestimmten Sprachen wie Chinesisch, Arabisch und Hebräisch.
Auch wenn es nicht der Hauptfokus war, hat sich der Realismus spürbar verbessert. Besonders sichtbar wird das bei Reflexionen – z. B. Blendenflecken auf Fotos – und bei vielen kleinen Gesichtern in großen Menschenmengen.
Wie so oft gehen große Upgrades mit Trade-offs einher. Hier ist die Fähigkeit, bestimmte Kunststile zu generieren, etwas zurückgefallen. OpenAI empfiehlt, im Images-Tab mit Preset-Filtern zu arbeiten oder auf das Vorgängermodell zurückzugreifen, das weiterhin als Custom GPT verfügbar ist.
Beschleunigte Performance
Die gezielten Edit-Funktionen sind auch die Hauptquelle der höheren Geschwindigkeit. Vollständige Neugenerierungen sind zwar merklich schneller, erreichen aber nicht ganz den in den Release Notes genannten Wert. GPT-Image-1.5 wirkt vor allem deshalb „bis zu 4× schneller“, weil bei Edits nur die geänderten Bildteile neu generiert werden.
Ähnlich verhält es sich bei den rund 20% niedrigeren API-Kosten: Sie entstehen vor allem durch Teil-Neugenerierungen bei Edits, ergänzt durch effizientere Inferenz – nicht durch billigere Vollgenerierungen.
Unterm Strich ermöglichen die neuen Funktionen eine effizientere und verlässlichere Nutzung, besonders in API-Workflows.
Beispiele zu ChatGPT Images
Die Ankündigungen klingen vielversprechend. Ich habe sie mit ein paar einfachen Prompts und dem neuen Auswahlwerkzeug getestet.
Präzision der Edits testen
Im ersten Test wollte ich prüfen, wie gut das Modell wiederholte Änderungen verkraftet, ohne Qualitätsverlust. Zuerst ließ ich ein Bild von einem Braunbären erstellen, der während der Mitternachtssonne durch einen finnischen Wald läuft.

Prompt: „A brown bear walking through a dense Finnish forest during the midnight sun.“
Die erste Ausgabe ist meiner Meinung nach sehr hochwertig. Der Bär wirkt natürlich, Baum- und Buscharten passen bestens zu finnischen Wäldern (ich kenne mich aus!) und die tief stehende Sonne entspricht dem, was man in Nordfinnland zur Mitternachtssonne erwarten kann.
Auch Licht und Schatten im Fell und im Hintergrund sehen realistisch aus. Irgendwie erkennt man noch die KI, aber die Details sind gelungen.
Jetzt ändern wir den Bären in einen Eisbären und schauen, was passiert. Eisbären gibt es in Finnland zwar nicht, aber wenn alles funktioniert, bleibt der Hintergrund gleich.

Prompt: „Change the bear to a polar bear.“
Wie man sieht, blieb der Hintergrund komplett unverändert – genau wie beabsichtigt.
Als Nächstes habe ich Kopf und Augen des Eisbären markiert und ihm eine Vintage-Sonnenbrille verpasst.

Prompt: „Put a pair of vintage sunglasses on the bear.“ (head selected)
So sieht es aus, wenn die Auswahlfläche zu groß ist: Hintergrund und Körper bleiben zwar konsistent, aber der Kopf wurde zu einer riesigen Sonnenbrille. Also neuer Versuch – nur die Augen markieren.

Prompt: „Put a pair of vintage sunglasses on the bear.“ (eyes selected)
Viel besser – und ziemlich cool! Der Test zeigt, wie stark die Detailtreue ist: Wir mussten die wichtigen Szeneninfos nur einmal nennen und konnten am Protagonisten iterieren, ohne uns um den Hintergrund zu sorgen. Wichtiges Learning: Die Größe des Auswahlfensters ist entscheidend.
Konsistenz bei Transformationen testen
Als Nächstes habe ich Objektkonstanz in wechselnden Szenen und die Grenzen bei großen Menschenmengen getestet. Dafür durfte unser Eisbär reisen – hinein in eine volle U-Bahn-Szene in Tokio.

Prompt: „Place this bear into a very busy subway scene in Tokyo.“
Die Charakterkonsistenz ist beeindruckend: Haltung und Identität des Bären wurden perfekt erhalten, und die Sonnenreflexe im Fell sind verschwunden.
Allerdings entsteht ein sichtbarer Bruch – der „Sticker-Effekt“: Weil das Modell den Lichtkontext nicht angepasst hat (gerichteter Schatten und Waldspiegelungen in der Brille blieben), wirkt der Bär wie ein 2D-Aufkleber statt wie ein 3D-Objekt in der Szene.
Auch die Perspektive passt nicht: Der Bär „schwebt“ vor einem Passanten, der eigentlich näher an der Kamera steht.
Das zu korrigieren, war frustrierend. Ich habe den Bereich des Passanten und seine Überlappung mit dem Bären markiert und ChatGPT gebeten, die Perspektive zu korrigieren. In jeder Variation hat das Modell eine neue Person nahe der Kamera eingefügt – so wie hier:

Prompt: „Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back.“
Offenbar konnte das Modell die Person nicht identifizieren – selbst markiert – und hat deshalb eine neue Figur eingefügt, um der Anweisung zu folgen.
Das Beheben von Schatten und Brillenreflexionen war erfolgreicher. Ich bin so vorgegangen:
- Schatten: Boden um die Bärenpfoten markieren und prompten: „Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting.“
- Sonnenbrille: Brille markieren und prompten: „Update the reflections of the sunglasses to match the subway environment.“

Unser Eisbär in der Tokioter U-Bahn nach Korrektur von Schatten und Brillenreflexionen
Schon deutlich besser, wenn auch nicht perfekt.
In Summe war der zweite Test weniger überzeugend. Während Elemente über Bilder hinweg konsistent bleiben, stößt die Objekterkennung in dichten Menschenmengen an Grenzen.
Textrendering testen
Zum Schluss wollte ich die neuen Textrendering-Fähigkeiten testen – besonders bei dichtem Text und Edits. Verbesserungen wären willkommen, da visuelle Modelle traditionell bei Objekten, Texturen und Szenen stark sind, bei Symbolen jedoch schwächeln.
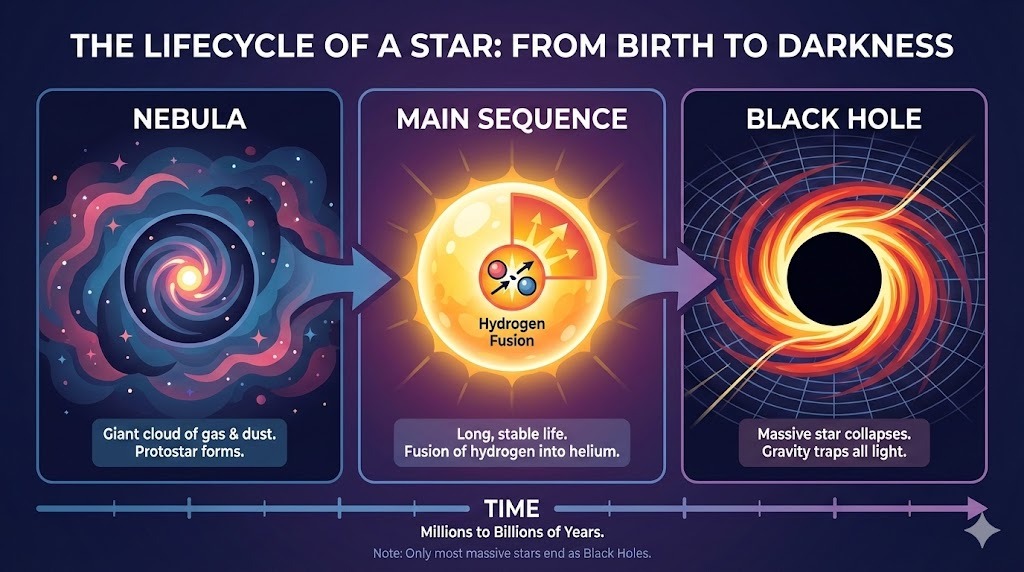
Ich habe ChatGPT um ein komplexes Layout für eine Infografik zum Lebenszyklus eines Sterns gebeten:
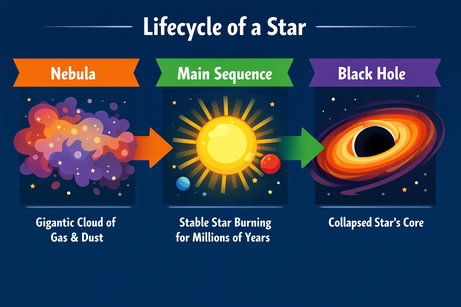
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
Das Ergebnis folgt den Anweisungen exakt und rendert den Text fehlerfrei. Der Stil ist durchgängig passend und konsistent.
Die Multimodalität von ChatGPT zwingt zu präzisen Formulierungen beim Texteinsatz. Als ich bat, „hier“ (in einem markierten Bildbereich) einen Bulletpoint hinzuzufügen, kam der Punkt nur als Textausgabe. Mit dem Zusatz „to the image“ hat es geklappt:
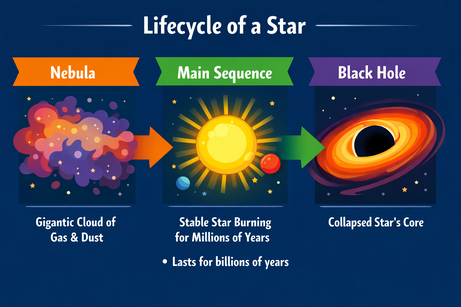
Prompt: „Add a bullet point to the image here that says: 'Lasts for billions of years'.“
Nach der Klarstellung wurde der Bulletpoint an der richtigen Stelle eingefügt. Schrift, Größe und Farbe passen zum Stil der Grafik.
Wie bekomme ich Zugriff auf ChatGPT Images?
ChatGPT Images ist jetzt auf mehreren Plattformen für fast alle Nutzer verfügbar. Lediglich Business- und Enterprise-Tiers fehlen noch; der Zugriff folgt später.
In der UI findest du die Funktionen sofort im Web oder in der mobilen App von ChatGPT im Tab Images. Exakte Zahlen sind nicht bekannt, aber Free-Accounts haben strikte Tageslimits, während Plus- und Pro-Pläne deutlich höhere, stabilere Kontingente bieten.
Für Entwickler steht das neue Modell GPT-Image-1.5 sowohl über die OpenAI API als auch über den Azure OpenAI Service für Generierung und Bearbeitung bereit. Auch wenn die Integration in große Drittanbieter-Suites sicher bald folgt, kannst du schon heute Edit-Workflows direkt in deine Anwendungen bauen – über die Endpunkte v1/images/generations und v1/images/edits.
Im Gegensatz zum Vorgänger rechnet GPT-Image-1.5 Bildausgaben als separat bepreiste Tokens ab und nutzt bildspezifische API-Endpunkte statt des vereinheitlichten /v1/responses. Du zahlst nur die Tokens für die tatsächlich geänderten Bildteile – nicht jedes Mal für eine komplette Neugenerierung.
Daher gilt das neue Modell als rund 20% günstiger als sein Vorgänger, obwohl die Tokenpreise gegenüber GPT-Image-1 unverändert sind.
Wie gut ist ChatGPT Images?
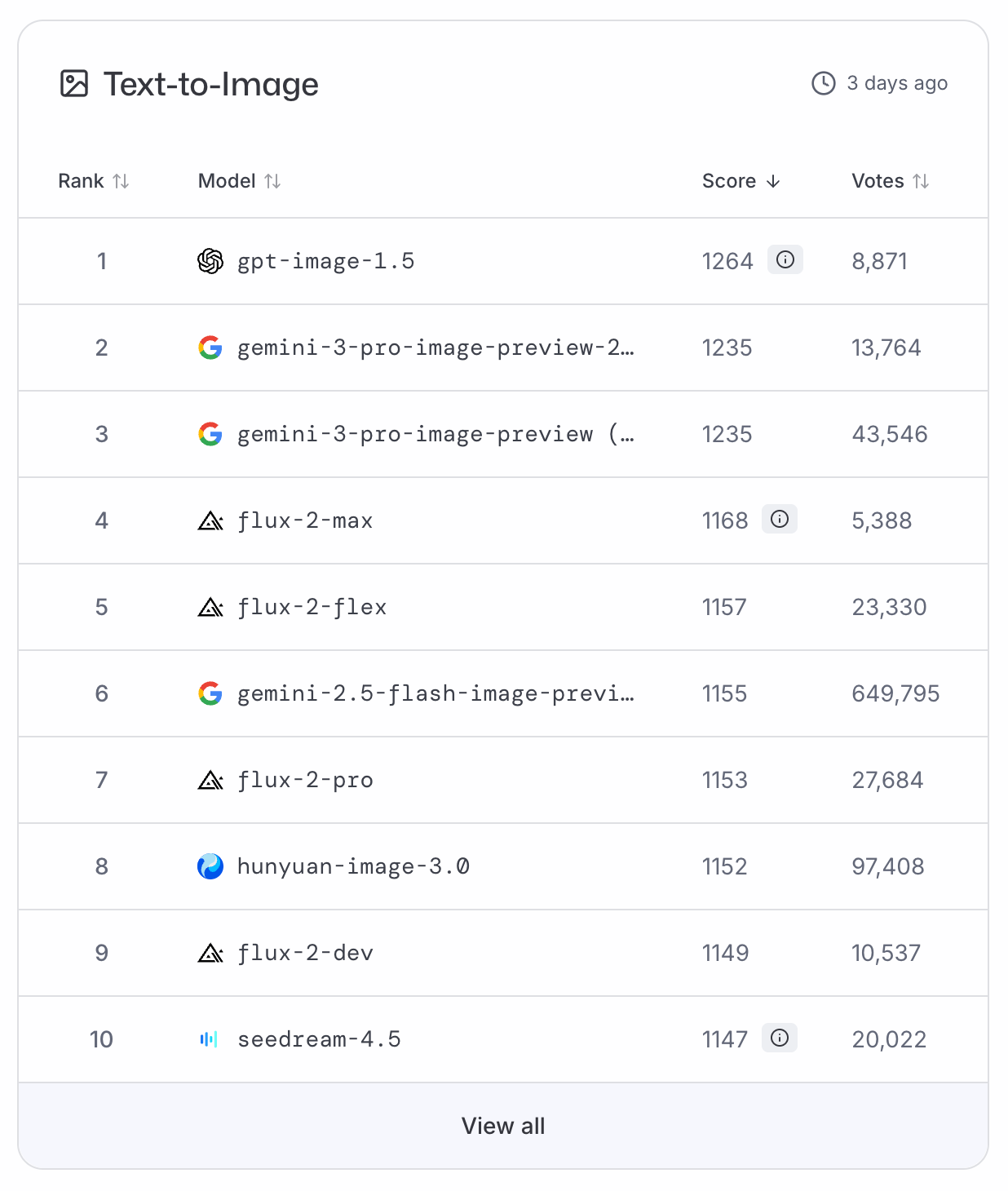
GPT-Image-1.5 sprang sofort an die Spitze der LMArena- und ArtificialAnalysis-Leaderboards für Text-zu-Bild und verdrängte Nano Banana Pro auf Platz zwei. Da es derzeit keine Benchmark-Daten gibt, stützen wir uns für eine objektive Einordnung auf diese Abstimmungsrankings.
Um einen berühmten Astronauten zu paraphrasieren: GPT-Image-1.5 ist ein kleiner Schritt für die Branche, aber ein großer Sprung für OpenAI.
Präzisionsedits sind nicht völlig neu, aber ihre native Integration in ChatGPT ist der größte Gamechanger. Präzision ist dabei entscheidend: Markiere nur die wirklich nötigen Bereiche, sonst drohen Glitches wie der „kopflosen Eisbär“ im Test.
Aus meiner Sicht liefert das Update einen deutlichen Qualitätssprung, was sich auch in den Leaderboards widerspiegelt. Standardbilder wirken lebendiger, Infografiken deutlich weniger schematisch.
Nutzer haben jetzt wesentlich mehr Kontrolle über jede Ausgabe – statt komplizierte Folgeprompts zu basteln und auf Glück zu hoffen. Der Hauptgrund: Die Detailerhaltung funktioniert sehr gut. In unseren Tests blieben Elemente vollständig intakt.
Die Charakterkonsistenz ist stark, dennoch solltest du auf den „Sticker-Effekt“ und unlogische Perspektiven achten. Zielgerichtete Edits erleichtern Korrekturen, aber in vollen Szenen mit vielen Menschen gibt es weiterhin Grenzen.
ChatGPT Images vs. Nano Banana Pro
Der aktuell stärkste Konkurrent für ChatGPT Images ist klar Googles Nano Banana Pro. Die folgende Tabelle vergleicht beide Modelle:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Editiermodell |
Präzision: Bereichsauswahl & In-Place-Editing |
Reasoning: Konversational & Smart Masking |
|
Workflow |
Eigener Kreativ-Arbeitsbereich |
In den Chat integriert |
|
Iteration |
Effizient: Teil-Neugenerierung |
Explorativ: Remixing |
|
Konsistenz |
Hohe Layout- & Detailtreue |
Hohe Layout- & Detailtreue |
|
Ökosystem |
OpenAI & Azure |
Google / Gemini-Stack |
Beide – GPT-Image-1.5 und Nano Banana Pro – liefern hervorragende Ergebnisse, unterscheiden sich aber in Editierphilosophie, Workflows und Zielgruppenfokus.
ChatGPT Images setzt auf pixelgenaue Isolation und damit auf manuelle Kontrolle: Du wählst einen exakten Bereich, der wie eine Inpainting-Canvas behandelt wird, während der Rest gesperrt ist. Nano Banana Pro versucht hingegen, deine Absicht zu verstehen und darauf basierend die passenden Änderungen vorzunehmen.
Auch beim Workflow gehen beide unterschiedliche Wege: Der Images-Tab in ChatGPT fühlt sich wie ein eigenes Kreativstudio an, getrennt von Konversationen; Nano Banana Pro ist vollständig in den Chatstream eingebettet.
Update: Googles neue Version des Non-Pro-Modells, Nano Banana 2, bringt spürbare Verbesserungen. Nano Banana Pro bleibt knapp vorn, doch das neue Modell liefert (fast) die gleiche Qualität bei deutlich höherer Geschwindigkeit.
Wann ChatGPT Images vs. Nano Banana Pro nutzen
Nutze ChatGPT Images, wenn du Layouts korrigieren, Text bearbeiten oder präzise Änderungen an einem bestehenden Bild vornehmen willst, ohne den Stil zu verändern. Greife zu Nano Banana Pro, wenn du datenreiche Visuals generieren, mehrere Bilder remixen oder lieber eine smarte Assistenz deine Absicht erkennen lassen möchtest, statt alles manuell zu steuern.
Mit denselben Prompts wie oben habe ich die Testbilder nachgebaut. Persönlich gefielen mir die Infografiken von Nano Banana Pro besser; die Bärenbilder lagen gleichauf.
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
Einsatzszenarien für ChatGPT Images
Basierend auf unseren Tests und den Stärken von GPT-Image-1.5 glänzt das Modell besonders bei iterativen Prozessen und Textbearbeitung. Top-Use-Cases:
- Marketing-Workflow: Social-Ads oder Produktshots, bei denen Details variieren (z. B. „Ändere den Pullover von Rot auf Blau“)
- Didaktische Infografiken: Diagramme für Lehrbücher, Präsentationen oder Blogs – wie unser Beispiel „Lebenszyklus eines Sterns“
- Storyboarding: Skripte oder Comics visualisieren, bei denen derselbe Charakter an verschiedenen Orten auftaucht
- Fashion: Hybride Content-Erstellung zur visuellen Erkundung von Outfit-Kombis, z. B. in diesem FLUX.2 Wardrobe-Visualizer-Tutorial
- Interior Design: Skizze oder Foto mit Prompts kombinieren, um Räume in einem bestimmten Stil neu zu gestalten
- UI/UX-Mockups: Schnell visualisieren, wie eine Website-Landingpage oder ein Verpackungsdesign aussehen könnte
Fazit
Seit Nano Banana Pro stand OpenAI unter Zugzwang. Mit diesem Update sind sie im Rennen um das leistungsfähigste Text-zu-Bild-Modell zurück. Perfekt ist es nicht – aber mit Fokus auf saubere Typografie und präzise Edits erzielst du sehr gute Ergebnisse. Probiere das Feature in deiner ChatGPT-UI aus oder im OpenAI Playground. Zur Inspiration schau dir die Galerie und den Prompt-Guide an.
Wenn du mit GPT-Modellen eigene Tools bauen möchtest, ist unser OpenAI Fundamentals Lernpfad genau richtig.
Welche Arten von Bildbearbeitungen kann ChatGPT Images durchführen?
Worin ist GPT-Image-1.5 besser als das vorherige Bildmodell?
Ist ChatGPT Images für alle verfügbar?
Können Entwickler das neue Bildmodell über die API nutzen?


Author
Josef Waples