programa
Ingeniero de datos en Python
40 h
Cuando tu amigo te cuente una estadística de la que no te fíes, puedes pedir conocer la fuente de la estadística para verificar su exactitud. Rastrear la información hasta su fuente es crucial para establecer la confianza. Este mismo principio se aplica a los datos.
El linaje de datos es un historial completo de tus datos, desde su origen, pasando por cada transformación, hasta su punto final. Este registro proporciona una imagen clara del recorrido de los datos.
Un linaje de datos ofrece una transparencia total al documentar cada paso de la cadena de datos, desde su recogida inicial hasta su análisis final. Esta visibilidad es crucial para generar confianza, ya que permite a las partes interesadas ver exactamente cómo se han procesado y transformado tus datos.
Puedes pensar en esto como si mostraras tu trabajo en clase de matemáticas. En clase, mostrar tu trabajo permite al profesor ver cada paso de tu proceso de resolución de problemas y demuestra que no has engañado a tu vecino. Un linaje de datos es como mostrar tu trabajo para tu canalización.
Mostrar tu trabajo en los deberes de matemáticas también ayuda al profesor (y a ti) a entender dónde te equivocaste si acabaste con una respuesta incorrecta. Esto puede ayudarte a corregir el error y a mejorar tu comprensión del tema en el futuro.
Del mismo modo, mostrar tu trabajo en un linaje de datos puede ayudarte a encontrar errores en una tubería. Rastrear los errores hasta su origen suele ser una tarea desalentadora cuando se producen errores en los datos. Un linaje de datos completo simplifica este proceso, ya que te permite seguir la trayectoria de los datos para encontrar dónde fallaron las cosas. Con este proceso de depuración más rápido, tendrás una mejor calidad de los datos, lo que fomenta la confianza.
Puedes aprender más sobre cómo garantizar la calidad de los datos en este curso de Introducción a la Calidad de los Datos.
La procedencia de los datos es un registro de metadatos del linaje de los datos. Muchos sectores tienen normativas que exigen pruebas de la procedencia de los datos, especialmente los que manejan información sensible, como la sanidad y las finanzas.
Demostrar la procedencia de los datos implica demostrar dónde se originaron y cómo se han manejado. El linaje de datos proporciona una pista de auditoría que cumple estos requisitos, mostrando todo el ciclo de vida de los datos. Además de fomentar la confianza, un registro de auditoría puede demostrar la conformidad de tus datos con las leyes de privacidad de datos, las políticas de gobierno y otras normativas.
Un linaje de datos completo registra el camino que siguen los datos en cada paso. He aquí un ejemplo de cómo pueden fluir los datos desde su fuente hasta una visualización.
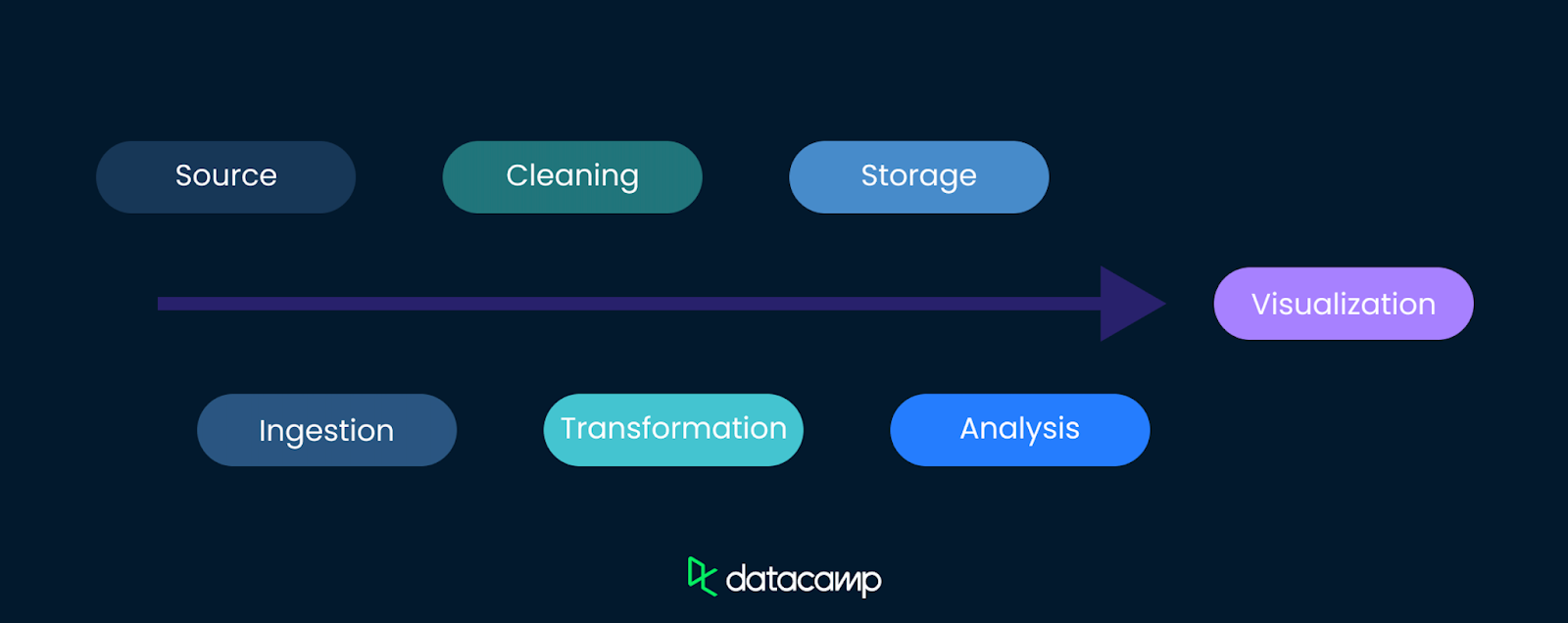
El linaje de los datos comienza en la fuente, que puede incluir bases de datos, API, sensores, encuestas u otros puntos de recogida de datos. Comprender dónde se originan los datos es el primer y más importante paso para seguir su recorrido.
La fuente de los datos proporciona contexto y antecedentes a los datos. También puede dar una pista sobre posibles sesgos y limitaciones en la recogida de datos.
Para demostrar la importancia de la fuente de datos, considera estos conjuntos de datos hipotéticos y sus fuentes.
|
Conjunto de datos |
Fuente |
Posibles sesgos/limitaciones |
|
Necesidades de hidratación |
Empresa que vende agua embotellada |
Puede sobrestimar las necesidades de hidratación para promover la venta de productos. |
|
Datos de presión arterial en pacientes con diferentes dietas |
Hospital de investigación de renombre mundial |
Es menos probable que tengan un sesgo significativo, pero existe la posibilidad de un sesgo de financiación o de selección en las muestras de pacientes. |
|
Datos sobre el uso de Internet en las zonas rurales de los países en desarrollo |
ONG pequeña con recursos limitados |
Pueden carecer de recursos para una recogida de datos exhaustiva, lo que puede dar lugar a un sesgo en el muestreo o a una cobertura geográfica limitada. |
|
Consumo energético e impacto medioambiental de las energías renovables |
Gran empresa petrolera |
Pueden restar importancia a los beneficios de las energías renovables o exagerar los retos para proteger los intereses empresariales existentes. |
|
Prevalencia de enfermedades cardiovasculares |
Centros para el Control y la Prevención de Enfermedades (CDC) |
Fuente reputada, pero con posibilidades de limitaciones en las metodologías de recopilación de datos o de infradeclaración en determinados grupos demográficos. |
|
Seguridad y eficiencia de una nueva línea de coches eléctricos |
Fabricante de vehículos eléctricos |
Puede exagerar la seguridad y la eficacia para promover las ventas, posible falta de transparencia en las metodologías de ensayo. |
|
Eficacia de un nuevo medicamento |
Organización de vigilancia independiente |
Es menos probable que haya un sesgo significativo, pero existe la posibilidad de que haya un sesgo de financiación o conflictos de intereses si existen vínculos con empresas farmacéuticas. |
|
Índices de satisfacción del cliente con un nuevo smartphone |
Empresa de fabricación de smartphones |
Puede inflar los índices de satisfacción para promover las ventas, posibilidad de diseño sesgado de la encuesta o muestreo selectivo. |
Cuando una amiga mía de Estados Unidos visitó Australia, contó a los lugareños que en ese momento hacía más de 100° en su ciudad natal. Se quedaron más sorprendidos de lo que ella esperaba hasta que todos se dieron cuenta de que en EE.UU. se utiliza el sistema Fahrenheit y en Australia el Celsius. Pensaron que se refería a 100 °C, ¡que son 212 °F! Pero se refería a 100 °F, que son unos 37 °C.
Afortunadamente, este malentendido se resolvió rápidamente en persona, pero imagina un escenario similar dentro de un conjunto de datos. Imagina un conjunto de datos que contiene la temperatura transformada de Fahrenheit a Celsius, pero la etiqueta de la unidad no se ha cambiado, por lo que sigue diciendo Fahrenheit. ¡Eso podría darte unos resultados realmente extraños!
Esto demuestra por qué documentar las transformaciones de datos es una parte importante de un linaje de datos. Si un usuario final de los datos, como un analista de datos, ve en sus análisis resultados que no tienen sentido (como una ciudad que experimenta regularmente temperaturas del aire en ebullición), puede mirar fácilmente hacia atrás en el linaje de los datos, ver la transformación que no se etiquetó y corregir el problema.
A medida que los datos se mueven desde su origen hasta su destino final, a menudo sufren numerosas transformaciones, incluidos procesos de limpieza, filtrado y agregación que dan forma a los datos para su uso previsto. Sin embargo, cada una de estas transformaciones también modifica la forma de interpretar los datos y debe documentarse.
Un linaje de datos claro documenta estas transformaciones, garantizando que cada cambio quede registrado y pueda rastrearse, mejorando la transparencia. Esto aumenta la confianza en tus datos y facilita la depuración.
La etapa final de tu flujo de datos es donde se almacenan y utilizan los datos. Puede ser en almacenes de datos, herramientas de elaboración de informes u otras plataformas analíticas. El linaje de datos rastrea los datos hasta estos puntos finales, proporcionando una imagen completa de su recorrido y garantizando que las partes interesadas puedan confiar en los datos que están viendo.
Documentar el destino de tus datos también es importante por motivos de seguridad, ya que proporciona un registro de quién tiene acceso a qué datos.
Establecer el linaje de los datos puede parecer sencillo: basta con saber de dónde proceden y qué se ha hecho con ellos. Sin embargo, varios retos pueden complicar este proceso. Consideremos algunas.
Uno de los principales retos a la hora de crear un linaje de datos es el tamaño y la complejidad de muchas canalizaciones de datos modernas. Los entornos de datos modernos suelen implicar intrincados flujos de datos que abarcan múltiples sistemas y plataformas. El seguimiento de estas vías detalladas requiere herramientas sólidas y una planificación cuidadosa.
Puede ser relativamente sencillo crear un linaje de datos para una cadena simple con una fuente de entrada y transformaciones limitadas. Pero si tienes una canalización compleja con varias entradas, muchas transformaciones y tal vez varios destinos, hacer un seguimiento de todo ello en un linaje de datos se vuelve más complicado. Pero también se hace más necesario.
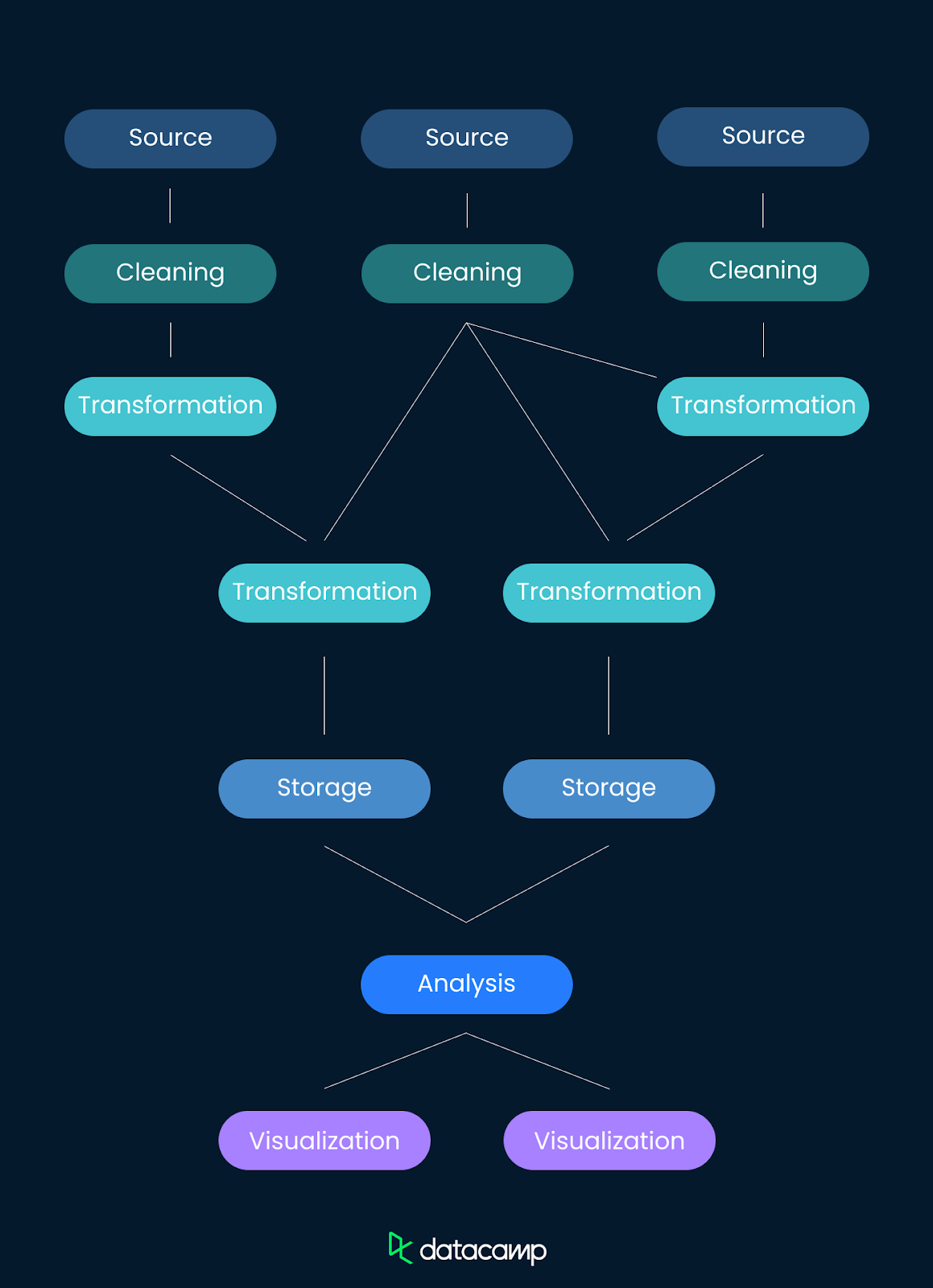
El linaje de los datos puede documentarse manual o automáticamente. La documentación manual del linaje de los datos puede llevar mucho tiempo y ser propensa a errores. Seguir manualmente los movimientos y transformaciones de los datos, especialmente en una operación de gran tamaño, no sólo es ineficaz, sino que aumenta el riesgo de inexactitudes, socavando la confianza que el linaje de datos pretende crear.
Para pipelines muy pequeños controlados completamente por una persona, puede bastar con el linaje manual de datos. Pero a medida que las cosas se complican, la documentación del linaje de datos debe ser más automatizada. En la siguiente sección, repasaremos algunos recursos que te ayudarán a hacerlo.
Si el linaje de datos no se incorporó inicialmente a un canal de datos, integrarlo retroactivamente puede llevar mucho tiempo y consumir muchos recursos. Adaptar la infraestructura actual para que admita un seguimiento exhaustivo del linaje de datos suele requerir cambios significativos, lo que puede suponer un obstáculo para algunas organizaciones. Ésta es una de las razones por las que es importante integrar soluciones de linaje de datos desde el principio.
Si no piensas documentar manualmente tu linaje de datos, necesitarás algunos componentes clave para crearlo: tendrás que recopilar metadatos sobre tus conjuntos de datos y disponer de un catálogo para esos metadatos.
Los metadatos son esencialmente datos sobre datos. Se refiere a información como el origen, la estructura, las transformaciones y el uso de tus datos. Una gestión eficaz de los metadatos implica recopilar metadatos de diversas fuentes, seguir las transformaciones de los datos y documentar los movimientos de datos. Esta recopilación y gestión suele estar automatizada, lo que garantiza que cada cambio quede registrado y sea rastreable. Esto proporciona una visión completa del linaje de tus datos.
Los catálogos de datos son repositorios completos que almacenan metadatos sobre los activos de datos de una organización, incluidos sus orígenes, transformaciones y destinos. A menudo automatizan el descubrimiento, la descripción y la organización de los activos de datos, facilitando la gestión del linaje de los datos, fomentando la confianza y garantizando el cumplimiento de las políticas de gobernanza de datos.
Hay muchas herramientas disponibles para ayudarte a rastrear el linaje de tus datos. Aquí tienes una breve lista de herramientas populares.
|
Nombre de la herramienta |
Tipo |
Características principales |
|
Pagado |
Gestión centralizada de metadatos, visualización del flujo de datos, compatible con una amplia gama de fuentes de datos |
|
|
Pagado |
Vistas detalladas del movimiento y la transformación de datos, garantiza la calidad y el cumplimiento de los datos |
|
|
Pagado |
Visualización avanzada del linaje, diagramas interactivos, integración de la gobernanza de datos |
|
|
Pagado |
Herramientas de integración e integridad de datos, seguimiento detallado de las transformaciones de datos |
|
|
Código abierto |
Gestión de metadatos, captura el linaje de los datos, diseñado para sistemas Hadoop |
|
|
Código abierto |
Automatiza los flujos de datos, incorpora funciones de seguimiento del linaje, supervisa los movimientos de datos |
|
|
Código abierto |
Servicio de metadatos para recopilar y visualizar el linaje de los datos, se integra con varios sistemas |
|
|
Código abierto |
Algoritmos de aprendizaje automático para la detección y documentación automáticas del flujo de datos |
Además de las herramientas mencionadas, muchas herramientas ETL/ELT, de visualización de datos y plataformas de gobierno de datos incluyen funciones de linaje. Estas herramientas automatizan la documentación de los procesos de extracción, transformación y carga de datos y ayudan a visualizar los flujos de datos entre sistemas.
Por ejemplo, ¿sabías que puedes ver el linaje de tus datos en PowerBI? Echa un vistazo a las herramientas que utilizas actualmente en tus conductos de datos y comprueba cuántos de tus datos ya están siendo rastreados.
A veces, una solución estándar no es práctica, y se prefiere una solución más personalizada. Si ése es tu caso, aquí tienes algunas opciones que puedes explorar para establecer un linaje de datos para tu pipeline.
En primer lugar, intenta documentar manualmente los flujos y transformaciones de datos en tu sistema, creando registros detallados de los orígenes, procesos y destinos de los datos. Este método puede ser suficiente para conjuntos de datos más pequeños o entornos de datos más sencillos gestionados por una sola persona o un equipo pequeño.
Sin embargo, si tu panorama de datos es mayor o más complejo, puede que sólo quieras documentar manualmente una vista de alto nivel de tu pipeline para tu propio uso, de modo que puedas señalar dónde añadir el seguimiento automatizado del linaje. La documentación manual permite un alto grado de personalización, pero puede requerir mucho trabajo en sistemas grandes.
Puedes desarrollar scripts personalizados utilizando lenguajes de programación como Python para capturar y registrar transformaciones y movimientos de datos. Estos scripts pueden integrarse en pipelines de procesamiento de datos para automatizar partes del proceso de documentación. Este enfoque es útil para organizaciones con requisitos específicos que no satisfacen plenamente las herramientas existentes o para aquellas con una complejidad de datos moderada.
Implementar disparadores de bases de datos para registrar automáticamente los cambios y movimientos de datos dentro de las bases de datos es otra técnica que puedes aplicar. Estos desencadenantes pueden registrar cualquier operación de inserción, actualización o eliminación ejecutada en una base de datos, proporcionando un registro de la evolución de los datos a lo largo del tiempo. Esta técnica es ideal para organizaciones con entornos de datos grandes y complejos, en los que el seguimiento en tiempo real de los cambios en los datos es crucial.
Puede que estés familiarizado con el control de versiones como forma de rastrear el linaje de las versiones del código. También pueden utilizarse prácticas similares de control de versiones para los datos. Llevando un registro de las versiones de los conjuntos de datos y documentando los cambios entre esas versiones, puedes seguir el linaje de los datos a lo largo del tiempo. Herramientas como Git pueden adaptarse para el versionado de datos. Este método es especialmente beneficioso para las organizaciones que necesitan mantener la integridad de los datos históricos y hacer un seguimiento de los cambios durante largos periodos.
Puedes crear visualizaciones personalizadas para trazar el linaje de los datos utilizando bibliotecas de visualización de redes como networkx en Python. Con estas bibliotecas, puedes generar diagramas que representen los flujos de datos y las transformaciones, facilitando la comprensión y el seguimiento del linaje de los datos. Este enfoque es adecuado para las organizaciones que necesitan visualizaciones muy personalizadas y tienen los conocimientos técnicos para desarrollar estas soluciones a medida.
Si rastreas muchos metadatos, tiene sentido crear un repositorio de metadatos centralizado para almacenar todos los metadatos relacionados con tus activos de datos. Este repositorio puede construirse utilizando bases de datos relacionales o soluciones NoSQL, y debe estar diseñado para integrarse fácilmente con los sistemas de procesamiento de datos para mantener los metadatos actualizados.
Este enfoque es ideal para organizaciones con activos de datos extensos y diversos que necesitan una solución escalable y flexible para la gestión de metadatos. Para empezar, consulta en OpenMetadata algunas herramientas de código abierto.
Escribo mucho sobre la importancia de la documentación en el código, y con razón. La documentación es una parte fundamental de las buenas prácticas de codificación. El linaje de los datos es importante por muchas de las mismas razones que la documentación del código. En muchos aspectos, puedes pensar en el linaje de los datos del mismo modo que en la documentación: es un rastro de pruebas que documenta cada paso que dieron tus datos.
Sin embargo, a diferencia de la documentación del código, los linajes de datos a menudo se basan en metadatos y automatización para su creación. Mientras que la documentación suele ser manual (o hoy en día la hace la IA), el linaje de datos suele ser demasiado complejo y voluminoso para hacerlo manualmente.
La documentación también suele aparecer en forma de comentarios dentro del código, junto con un archivo README. El linaje de datos suele visualizarse mediante diagramas e informes automatizados para comprender el flujo de datos en tu sistema.
El linaje de datos y la gobernanza de datos son conceptos estrechamente relacionados en la gestión de datos. El linaje de datos traza el recorrido de los datos a través de transformaciones y sistemas, proporcionando un registro histórico que garantiza la transparencia y la trazabilidad. Mientras tanto, la gobernanza de los datos abarca políticas y normas más amplias para la calidad de los datos, la seguridad y el cumplimiento. Los linajes de datos pueden apoyar el cumplimiento de las políticas de gobernanza de datos.
Las organizaciones pueden mejorar los esfuerzos de gobernanza aprovechando las herramientas y técnicas de linaje de datos, garantizando la integridad de los datos y el cumplimiento de los requisitos normativos. Juntos, el linaje de datos y la gobernanza crean un enfoque integral para gestionar y proteger los datos.
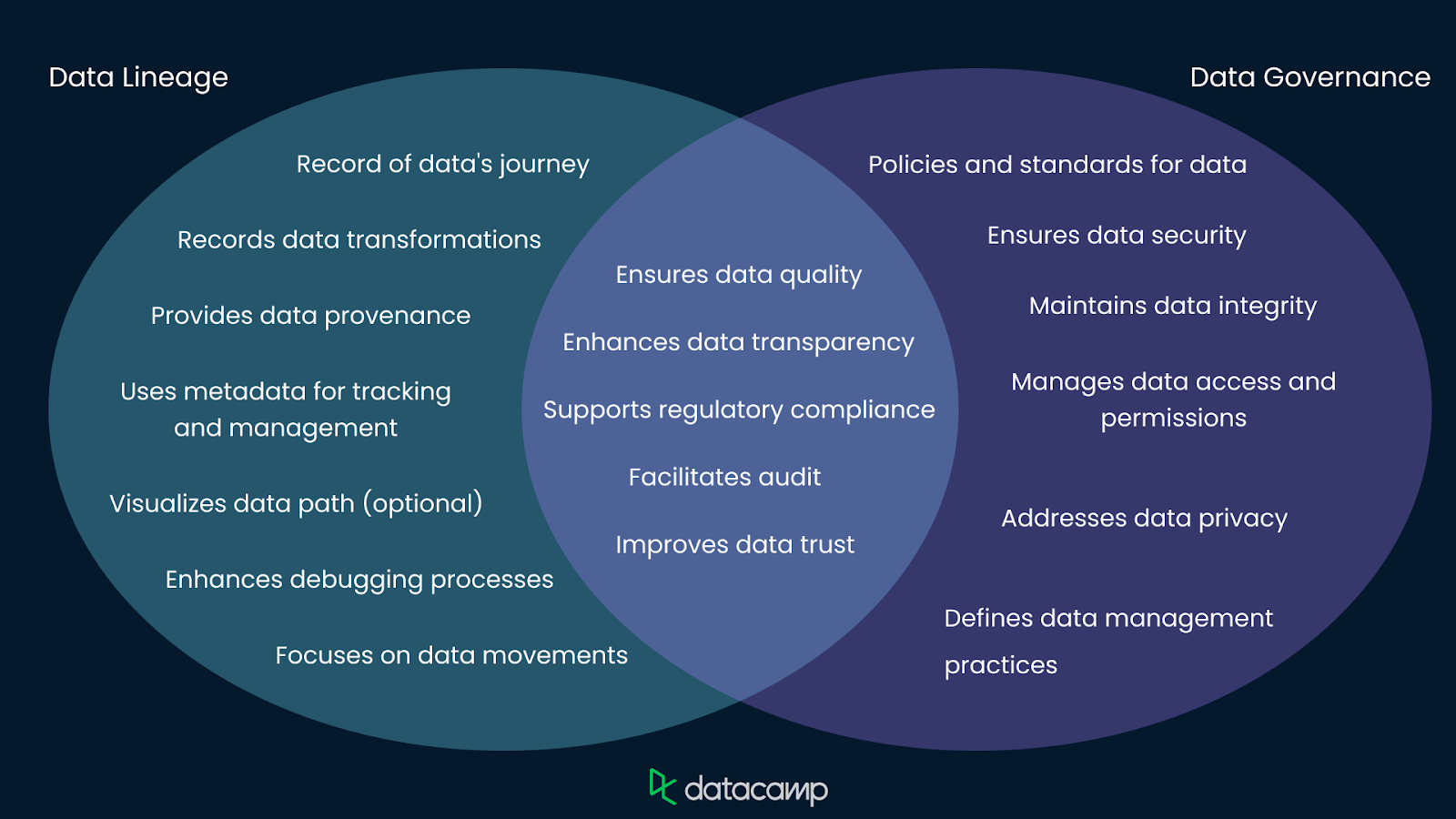
Puedes aprender más sobre la gobernanza de datos en este curso sobre Conceptos de Gobernanza de Datos. También puedes echar un vistazo más avanzado a Cómo pueden los líderes de datos hacer de la gobernanza de datos una prioridad.
A medida que los paisajes de datos se hacen más complejos, los linajes de datos son cada vez más vitales. Generan confianza proporcionando transparencia, permitiendo una depuración más rápida y demostrando la procedencia de los datos.
Con los avances en automatización y visualización, la importancia de las herramientas de linaje de datos no hará sino crecer, apoyando prácticas sólidas de gobierno y gestión de datos.
Si quieres saber más, prueba este curso sobre Comprender la Ingeniería de Datos. También te animo a que consultes Gestión responsable de datos de IA y Cómo hacer divertida la gobernanza de datos.
¡Aprende ingeniería de datos con estos cursos!
programa
programa
Curso
blog
Matt Crabtree
15 min
blog
Matt Crabtree
10 min
blog
Abid Ali Awan
6 min
blog
Javier Canales Luna
14 min


