
Curso
Comprender la inteligencia artificial
2 h
401.5K
Nemotron 3 es la respuesta de NVIDIA a las limitaciones emergentes de los sistemas de IA multiagente. Lo que quiero decir es que, a medida que los sistemas de IA avanzan hacia flujos de trabajo multiagente, los costes de inferencia aumentan, la coordinación se vuelve difícil y las tareas de larga duración sobrepasan los límites del contexto.
Con Nemotron 3, cada modelo se basa en la misma estructura arquitectónica, pero busca un equilibrio diferente entre profundidad de razonamiento, rendimiento y eficiencia.
En este artículo, veremos cómo está estructurada la familia Nemotron 3, qué ha cambiado en su interior y dónde encaja dentro de los sistemas de agentes que se utilizan habitualmente.
La idea central detrás de Nemotron 3 es la especialización. Algunos agentes deben ser ligeros y rápidos, y encargarse de tareas rutinarias como el enrutamiento o la síntesis. Otros se encargan de realizar análisis más profundos o de planificar a largo plazo. Al ofrecer múltiples modelos dentro de la misma generación, Nemotron 3 admite esa división del trabajo sin dejar de ser transparente y autohospedable.
Nemotron 3 Nano es el modelo más eficiente de la familia. Es un modelo de 30 000 millones de parámetros que activa hasta 3B parámetros por token utilizando una arquitectura híbrida de mezcla de expertos. Esta activación selectiva permite a Nano alcanzar un alto rendimiento y bajos costes de inferencia, al tiempo que mantiene una precisión competitiva para su tamaño.
Nano está diseñado para tareas como resumir, recuperar, clasificar y realizar flujos de trabajo de asistencia general. En los sistemas multiagente, funciona bien como un trabajador de gran volumen que se encarga de pasos frecuentes o intermedios sin convertirse en un cuello de botella en cuanto a costes.
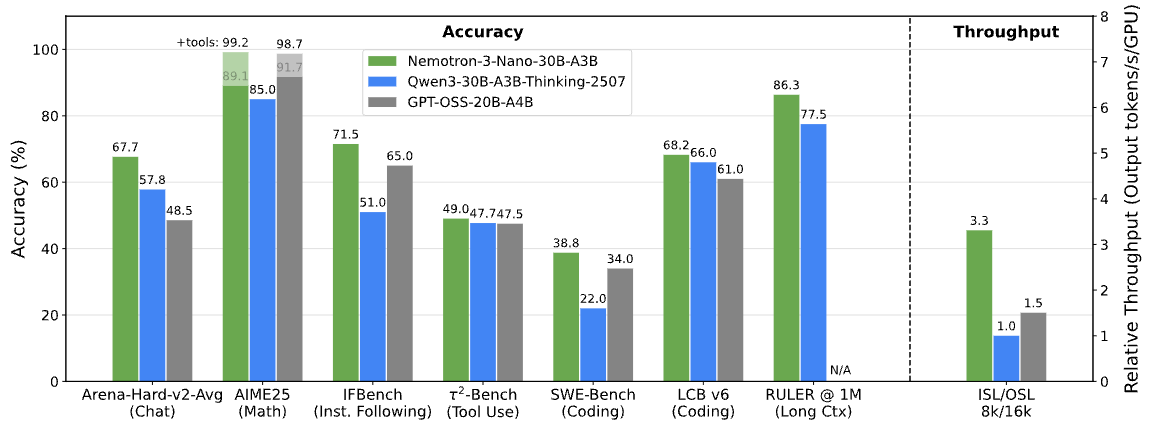
Pruebas de rendimiento de Nemotron 3. Imagen de NVIDIA Research.
Nemotron 3 Super se centra en escenarios que requieren un razonamiento más sólido, sin dejar de funcionar bajo restricciones de latencia. Tiene aproximadamente 100 000 millones de parámetros, con hasta 10 000 millones activos por token, y está optimizado para cargas de trabajo multiagente coordinadas.
Super se encuentra entre Nano y Ultra. Ofrece una capacidad de razonamiento superior a la de Nano sin los requisitos informáticos completos del modelo más grande, lo que lo hace ideal para agentes que necesitan combinar múltiples entradas o razonar a lo largo de varios pasos.
El Nemotron 3 Ultra es el modelo más potente de la gama. Con aproximadamente 500 000 millones de parámetros y hasta 50 000 millones activos por token, sirve como motor de razonamiento de alta gama para flujos de trabajo agenticos complejos.
Ultra está diseñado para tareas que implican análisis profundos, planificación a largo plazo o toma de decisiones estratégicas. Aunque tiene mayores requisitos de computación, está diseñado para funcionar junto con modelos Nemotron más pequeños, y solo se le asignan las tareas más exigentes.
Ahora que la gama de modelos está clara, la siguiente pregunta es cómo NVIDIA equilibra la escala y la eficiencia en niveles tan diferentes.
En lugar de basarse en un único avance arquitectónico, Nemotron 3 combina varias opciones de diseño complementarias para que los grandes sistemas multiagente sean prácticos de ejecutar.
En el núcleo de Nemotron 3 se encuentra una mezcla híbrida latente de mezcla de expertos (MoE) híbrida latente. En lugar de activar todos los parámetros para cada token, el modelo dirige cada token a través de un pequeño subconjunto de redes expertas especializadas.
Esto reduce el coste de inferencia al tiempo que preserva la capacidad de un modelo mucho más grande. En los sistemas basados en agentes, en los que muchos agentes pueden generar resultados intermedios simultáneamente, la activación selectiva ayuda a mantener los requisitos informáticos bajo control a medida que aumenta la escala.
Nemotron 3 Super y Ultra se entrenan utilizando el formato de precisión NVFP4 de 4 bits de NVIDIA en la arquitectura Blackwell. El entrenamiento de menor precisión reduce el uso de memoria y acelera el entrenamiento, lo que permite trabajar con modelos MoE más grandes en la infraestructura existente.
Es importante destacar que esto se hace sin una disminución significativa de la precisión en comparación con los formatos de mayor precisión, lo que ayuda a explicar cómo Nemotron 3 puede escalarse sin dejar de ser práctico para su implementación.
Nemotron 3 Nano admite ventanas de contexto de hasta un millón de tokens. Esto permite que el modelo conserve la información en documentos largos, registros extensos o historiales de tareas de varios pasos.
En los flujos de trabajo de los agentes, como las tareas de enrutamiento entre los agentes de planificación, recuperación y ejecución, un contexto más amplio reduce la necesidad de fragmentación agresiva o de sistemas de memoria externos.
Estas decisiones arquitectónicas no son abstractas. Se reflejan directamente en el comportamiento de Nemotron 3 en sistemas reales.
NVIDIA informa de que Nemotron 3 Nano genera hasta un 60 % menos de tokens de razonamiento que Nemotron 2 Nano. En los sistemas multiagente, donde los pasos intermedios del razonamiento pueden dominar el uso total de tokens, esta reducción repercute directamente en el coste y la escalabilidad.
Las trazas de razonamiento más cortas ayudan a mantener la eficiencia de la inferencia sin sacrificar la precisión de la tarea.
La combinación del enrutamiento MoE y la activación selectiva de parámetros permite a Nemotron 3 mantener un alto rendimiento a medida que los flujos de trabajo se vuelven más complejos. Esto facilita el soporte de cadenas de tareas más largas o de más agentes simultáneos sin aumentos proporcionales en la latencia.
Con soporte para hasta un millón de tokens en Nano, Nemotron 3 permite un razonamiento a largo plazo sobre entradas ampliadas. Los agentes pueden consultar pasos anteriores o documentos extensos sin tener que resumir o recargar el estado repetidamente, lo que mejora la coherencia a lo largo del tiempo.
En conjunto, estas características explican por qué Nemotron 3 hace hincapié en la eficiencia y la coordinación por encima del rendimiento bruto de un único modelo.
A estas alturas, los objetivos de diseño de Nemotron 3 deberían estar claros. Compararlo con Nemotron 2 ayuda a validar si esos objetivos se tradujeron en mejoras cuantificables.
Nemotron 3 perfecciona el enrutamiento de mezcla de expertos, aumenta el rendimiento, reduce la generación de tokens de razonamiento y amplía significativamente la longitud del contexto. NVIDIA informa de un rendimiento de tokens hasta cuatro veces superior para Nemotron 3 Nano en comparación con Nemotron 2 Nano, junto con una gran reducción en los tokens de razonamiento.
Otra diferencia es el alcance. Nemotron 3 va más allá de los modelos, ya que incluye conjuntos de datos de aprendizaje por refuerzo, datos de seguridad de agentes y herramientas abiertas como NeMo Gym y NeMo RL. Nemotron 2 se centraba principalmente en las versiones de modelos, mientras que Nemotron 3 se posiciona como una pila más completa para el desarrollo de agentes.
Con la arquitectura y los puntos de referencia en contexto, queda más claro dónde encaja Nemotron 3 en el panorama actual de modelos. NVIDIA no está posicionando Nemotron 3 como un sustituto directo de los modelos propietarios de Frontier. En cambio, se centra en un reto diferente: hacer que los sistemas de IA basados en agentes sean eficientes, predecibles y escalables en implementaciones reales.
En comparación con otros modelos abiertos de gran tamaño, Nemotron 3 pone menos énfasis en maximizar las puntuaciones de referencia de un solo modelo y más en cuestiones a nivel de sistema, como el rendimiento, la eficiencia de los tokens de razonamiento, el manejo de contextos largos y la coordinación entre agentes. Este enfoque es similar al que Mistral utiliza para posicionar su propia gama de productos, pero con un mayor énfasis en las cargas de trabajo multiagente.
La siguiente tabla resume las dimensiones clave en las que Nemotron 3 destacaen comparación con otros modelos populares, tanto abiertos como propietarios.
|
Dimensión |
Nemotron 3 |
Mistral Grande 3 |
Modelos DeepSeek-Class |
Modelos patentados por Frontier |
|
Objetivo principal del diseño |
Eficiencia multiagente a gran escala |
Capacidad para un solo modelo |
Profundidad del razonamiento por pregunta |
Razonamiento fronterizo y agentes |
|
Enfoque en la arquitectura |
MoE latente híbrido |
MoE disperso |
Denso / MoE |
Denso, exclusivo |
|
Rendimiento (tokens/segundo) |
Muy alto (Nano lidera el sector) |
Alto, pero con gran carga computacional |
Moderado |
Moderado a alto |
|
Razonamiento Uso de fichas |
Reducido (hasta un 60 % menos en Nano) |
Moderado |
Más alto |
Más alto |
|
Ventana de contexto |
Hasta 1 millón de tokens (Nano) |
Hasta ~256K |
Largo, pero más pequeño |
Largo (varía según el modelo) |
|
Idoneidad multiagente |
Excelente |
Moderado |
Moderado |
Fuerte pero costoso |
|
Autoalojamiento y control |
Completo (pesos abiertos) |
Completo (pesos abiertos) |
Completo (pesos abiertos) |
Limitado / ninguno |
|
Mejor caso de uso |
Coordinación de agentes, enrutamiento, resumen |
Razonamiento profundo, codificación |
Tareas de matemáticas y razonamiento |
Planificación compleja, SWE |
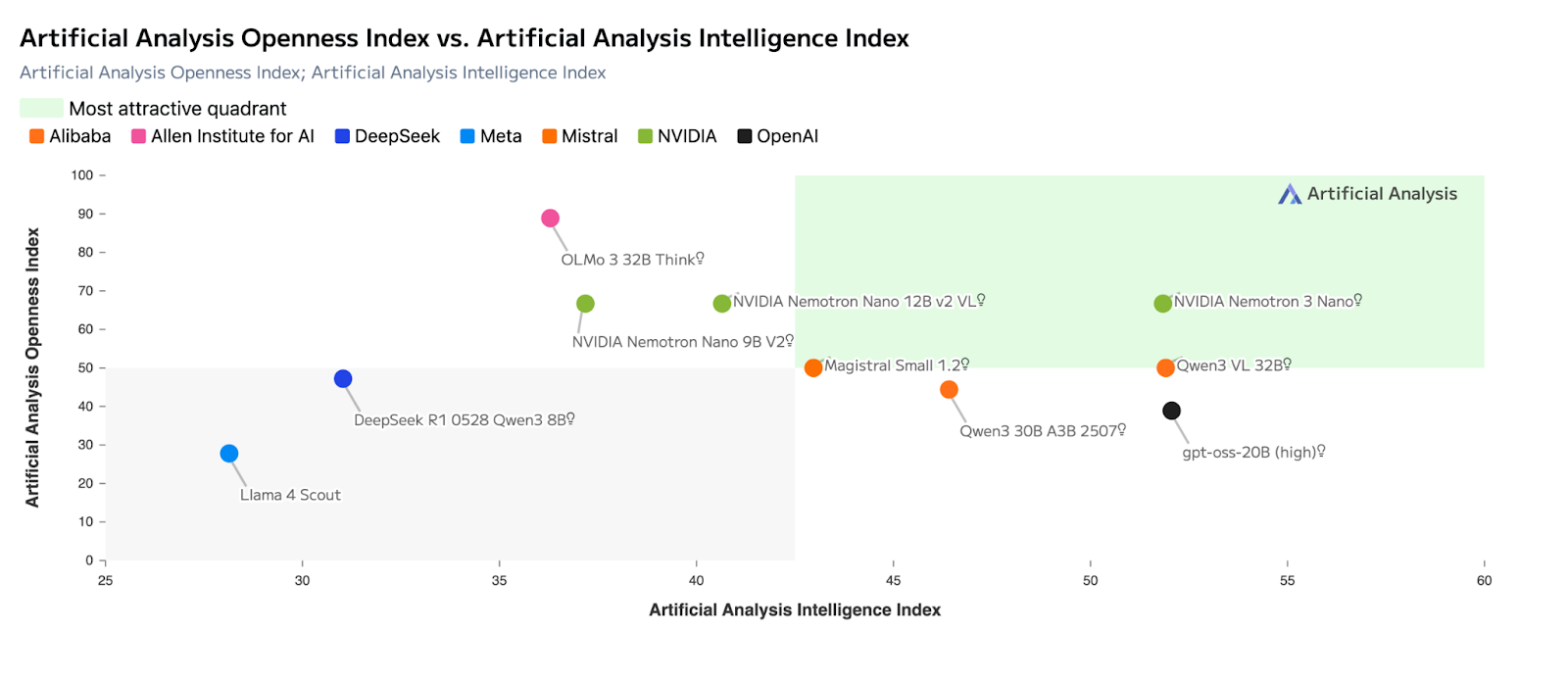
Mistral Large 3 y Nemotron 3 se basan en arquitecturas de mezcla de expertos , pero se optimizan para obtener resultados diferentes.
Mistral Large 3 está diseñado para maximizar la capacidad de un solo modelo, con un rendimiento excelente en razonamiento, codificación y pruebas de rendimiento de uso general, como las evaluaciones de tipo LMArena y SWE. A menudo es la mejor opción cuando se espera que un modelo gestione una tarea completa de principio a fin.
Nemotron 3, por el contrario, está optimizado para la eficiencia a nivel del sistema. Tu diseño híbrido MoE latente activa menos parámetros por token y prioriza el rendimiento por encima de la profundidad máxima de razonamiento. Esto hace que sea más adecuado para funciones que requieren mucha coordinación: enrutamiento, resumen y razonamiento intermedio, en las que operan simultáneamente muchos agentes.
Una vez que los objetivos de diseño están claros, la siguiente pregunta es práctica: ¿cómo puedes ejecutar Nemotron 3 hoy en día y qué opciones tienen sentido dada tu configuración? NVIDIA ofrece varias vías de acceso, que van desde API totalmente alojadas hasta implementaciones autogestionadas.
La forma más rápida de empezar es a través de proveedores de inferencia alojados. Nemotron 3 Nano está disponible actualmente en plataformas como Baseten, DeepInfra, Fireworks, FriendliAI, OpenRoutery Together AI. Estos servicios exponen interfaces API estándar, lo que te permite probar el comportamiento del modelo, el rendimiento y el manejo de contextos largos sin necesidad de aprovisionar hardware.
Esta opción es ideal para crear prototipos de flujos de trabajo de agentes, comparar el rendimiento o integrar Nemotron 3 en aplicaciones existentes con una configuración mínima.
Los modelos Nemotron 3 también se comercializan con pesos abiertos en Hugging Face, lo que permite un control total sobre la implementación. Esta ruta está pensada para equipos que desean alojar vosotros mismos los modelos, ajustarlos a datos específicos del dominio o integrarlos en canalizaciones de agentes personalizadas.
Con los pesos abiertos, puedes:
Este enfoque está en consonancia con el énfasis que NVIDIA pone en la transparencia y la propiedad de los sistemas de agentes de larga duración y aptos para la producción.
Para los equipos que desean una experiencia de autoalojamiento más gestionada, Nemotron 3 Nano también está disponible como un microservicio NVIDIA NIM. NIM empaqueta el modelo para una implementación segura y escalable en una infraestructura acelerada por NVIDIA, ya sea en tus instalaciones o en la nube.
A medida que el ecosistema madura, también se espera que los modelos Nemotron se integren con los marcos de implementación y los tiempos de ejecución comunes utilizados para la inferencia local y periférica. Estas opciones facilitan la experimentación con Nemotron 3 en entornos controlados sin tener que crear una pila de implementación desde cero.
En el momento del lanzamiento:
En la práctica, esto significa que los programadores pueden empezar a experimentar con Nano inmediatamente, mientras que los modelos más grandes están posicionados para implementaciones en etapas posteriores que requieren una mayor capacidad de razonamiento.
Nemotron 3 es potente dentro de su ámbito de aplicación previsto. Su principal contribución no es ampliar los límites del razonamiento basado en un único modelo, sino hacer que los sistemas basados en agentes sean más prácticos de implementar y escalar.
Las decisiones arquitectónicas se traducen en beneficios operativos reales, especialmente para los flujos de trabajo que dependen de muchos agentes que cooperan entre sí. Dicho esto, si tu requisito principal es un razonamiento profundo basado en un único modelo o una planificación compleja impulsada por herramientas, los modelos patentados de vanguardia siguen siendo, por lo general, más coherentes.
Si se analiza desde la perspectiva adecuada, Nemotron 3 complementa esos modelos en lugar de sustituirlos.
Nemotron 3 es ideal para situaciones en las que la eficiencia, la transparencia y la escalabilidad son importantes.
Dado que los modelos son abiertos y están diseñados para funcionar conjuntamente, los equipos pueden asignar diferentes funciones a diferentes tamaños de modelos, en lugar de depender de un único sistema monolítico.
El enfoque de NVIDIA en la eficiencia, la apertura y el diseño a nivel de sistema refleja cómo se están creando actualmente muchas aplicaciones de IA en el mundo real.
Ahora bien, para crear de forma eficaz con modelos como Nemotron 3, es útil comprender tanto los fundamentos del LLM como la integración de sistemas.
Nuestro curso Conceptos de modelos lingüísticos grandes (LLM) proporciona una base conceptual, mientras que nuestro programa Creación de API en Python cubre el aspecto práctico de la integración de modelos en aplicaciones.
Considerado como parte de un sistema más amplio, Nemotron 3 parece menos un lanzamiento de modelo y más una base para el despliegue actual de la IA basada en agentes.
Aprende con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
10 min
blog
Bhavishya Pandit
7 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali



