programa
Desarrollo de aplicaciones de IA
21 h
Durante años, escalar los modelos de IA significaba sobre todo añadir más parámetros y datos de entrenamiento.
Aunque este enfoque mejora el rendimiento, también aumenta significativamente los costes computacionales. La Mezcla de Expertos (ME) ha surgido como una solución prometedora para abordar este reto, utilizando módulos expertos activados de forma dispersa en lugar de las tradicionales capas densas de avance.
El ME funciona delegando las tareas en distintos expertos en función de su experiencia en el tema. Cada experto está muy entrenado en un conjunto de datos específico para servir a un propósito concreto, y otro componente, la red de compuertas, se encarga de delegar estas tareas.
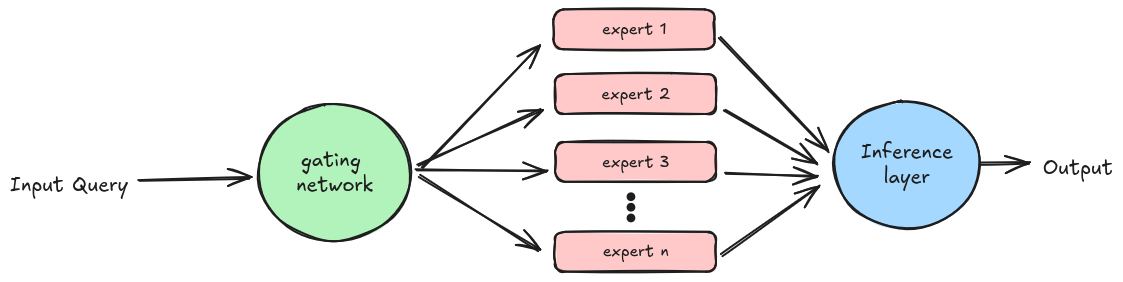
Aunque los modelos MoE superan a los modelos tradicionales con Capas Feed-Forward, su eficacia puede estancarse a medida que crece el tamaño del modelo, debido a las limitaciones de utilizar un número fijo de fichas de entrenamiento.
Abordar esta cuestión requiere arquitecturas de alta granularidad con un gran número de expertos. Sin embargo, la única arquitectura existente que admite más de diez mil expertos, la Mezcla de Expertos en Palabras (MoWE)es específica para cada lengua y se basa en un esquema de enrutamiento fijo.
El sitio Mezcla de un millón de expertos (MoME)presentada en este documentoaborda este reto introduciendo la Recuperación de Expertos Eficiente en Parámetros (PEER) que emplea la recuperación de claves de producto para el enrutamiento eficiente a un gran número de expertos.
Uno de los principales retos a la hora de ampliar LLM reside en las demandas de cálculo y memoria de las capas de avance dentro de los bloques transformadores. El ME lo aborda sustituyendo estas capas por módulos expertos activados de forma dispersa, cada uno especializado en diferentes aspectos de la tarea. Este enfoque mejora la eficacia activando sólo a los expertos relevantes para una entrada dada, reduciendo la sobrecarga computacional.
Los enfoques actuales del ME tienen limitaciones, como los encaminadores fijos que hay que reajustar cuando se añaden nuevos expertos. Por tanto, se introduce un nuevo enfoque del encaminamiento, sustituyendo el encaminador fijo por un índice aprendido.
La Recuperación Experta Eficaz de Parámetros (PEER) reduce el número de parámetros activos en la capa ME, lo que afecta al consumo de memoria de cálculo y activación durante el preentrenamiento y la inferencia.
PEER demuestra que, aplicando los mecanismos adecuados de recuperación y encaminamiento, MoE puede ampliarse a millones de expertos, reduciendo el coste y la complejidad de la formación y el servicio de modelos lingüísticos muy grandes.
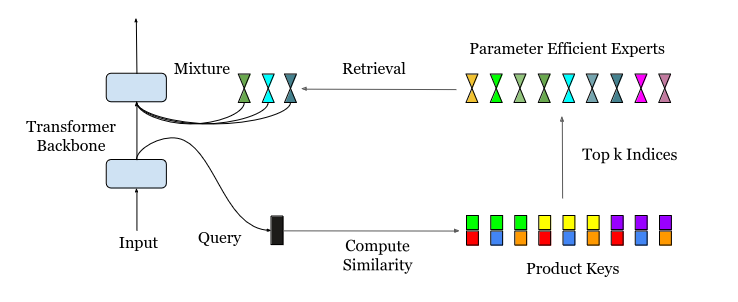
En el diagrama anterior, la consulta de entrada se somete inicialmente a una recuperación de claves de producto para identificar a los kmejores expertos de. A continuación, estos expertos seleccionados procesan la entrada basándose en sus conocimientos especializados, y sus resultados se combinan durante la fase de inferencia para generar la salida final del modelo.
La principal innovación de PEER es el uso de la recuperación de claves de producto. El objetivo sigue siendo el mismo que en el ME tradicional: encontrar a los k expertos más adecuados para la tarea dada. Sin embargo, con un gran número de expertos (potencialmente superior a un millón), las técnicas anteriores se vuelven computacionalmente caras o ineficaces.
Considera un escenario con N expertos, cada uno representado por un vectord-dimensional. Calcular directamente los k mejores expertos implicaría calcular la similitud entre la consulta de entrada y todas las N claves de expertos, lo que daría lugar a una complejidad temporal de O(Nd). Cuando N es muy grande (por ejemplo, N ≥ 10^6), esto resulta prohibitivamente caro.
PEER aborda esta cuestión empleando una estrategia inteligente: en lugar de utilizar N claves expertas independientes de d dimensiones, divide cada clave en dos subconjuntos independientes, cada uno con dimensionalidad d/2. Del mismo modo, el vector de consulta se divide en dos subconsultas. A continuación, se aplica la operación top-k a los productos internos entre estas subconsultas y subclaves.
Esta estructura de producto cartesiano de las claves reduce drásticamente la complejidad computacional de O(Nd) a O((N^.5+ k2)d), lo que hace factible identificar eficazmente a los k mejores expertos incluso con un número masivo de expertos.
La capa de Recuperación Experta Eficaz en Parámetros (PEER) es una arquitectura MoE que utiliza claves de producto en el enrutador y MLP de neurona única como expertos.
Una capa PEER consta de tres componentes:
Así es como funciona:
En esencia, la capa PEER identifica eficazmente a los expertos más relevantes para una entrada dada, lo que permite la utilización eficaz de un número masivo de expertos manteniendo la trazabilidad computacional. Esta innovación es un factor clave para escalar los modelos de ME a millones de expertos, allanando el camino para unos LLM más potentes y eficientes.
PEER, junto con la arquitectura MoME, ofrece varias ventajas convincentes sobre los enfoques tradicionales de MoE, ampliando los límites de las capacidades de LLM:
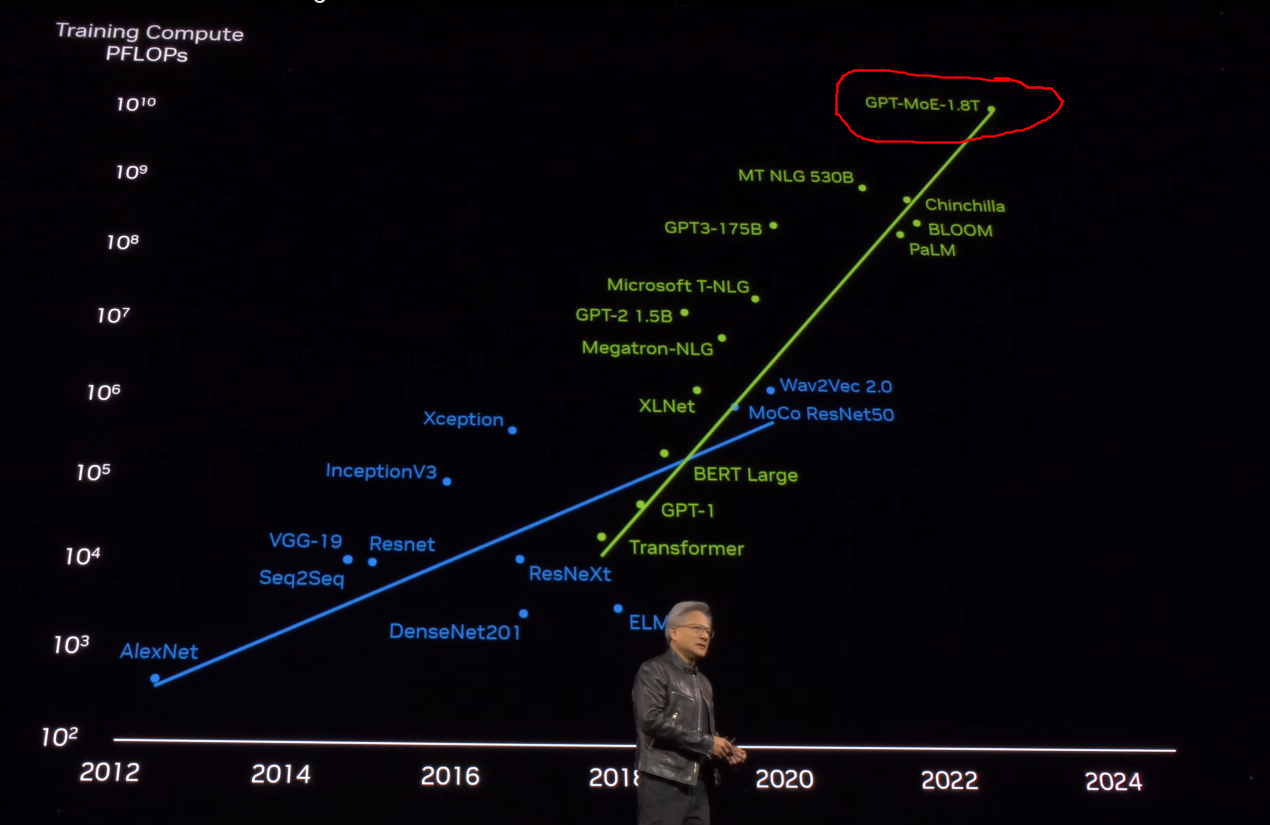
La Mezcla de Expertos ya es un paradigma de modelo ampliamente utilizado en el sector, con empresas como YouTube que lo integran en su sistema de recomendación. El futuro de MoME parece similar, y ya se insinuó en la GTC 2024 de Nvidia, cuando hablaron del modelo de 1,8 billones de GPT.
La Mezcla de Millones de Expertos (MoME), con su arquitectura PEER, resulta especialmente prometedora para tareas complejas de PNL que requieren una amplia base de conocimientos y una rápida recuperación de respuestas. Aborda los retos de escalabilidad inherentes al entrenamiento y servicio de modelos lingüísticos muy grandes, abriendo nuevas posibilidades para su uso en dominios como la visión por ordenador, la generación de contenidos, los sistemas de recomendación y la informática inteligente.
Ampliar un modelo hasta un millón de expertos parece prometedor desde el punto de vista de la eficacia, pero gestionar una red tan grande plantea sus dificultades. Exploremos algunas de ellas:
En este artículo, exploramos la técnica de la Mezcla de Millones de Expertos (MoME), un enfoque escalable para grandes modelos lingüísticos.
MoME aprovecha las redes de expertos especializados y el mecanismo de encaminamiento PEER para mejorar la eficacia y el rendimiento.
Hablamos de sus componentes básicos, ventajas y aplicaciones potenciales. Para profundizar más, consulta el documento de investigación para ver los detalles técnicos y los resultados de las pruebas comparativas.
Para más información, consulta el documento de investigación para conocer los detalles técnicos y los resultados de las pruebas comparativas.
¡Desarrolla aplicaciones de IA!
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Natassha Selvaraj
15 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
