
Curso
Entendendo a inteligência artificial
2 h
401.5K
O Nemotron 3 é a resposta da NVIDIA para as novas limitações dos sistemas de IA multiagentes. O que quero dizer é que, à medida que os sistemas de IA avançam para fluxos de trabalho com vários agentes, os custos de inferência aumentam, a coordenação fica mais difícil e as tarefas de longa duração sobrecarregam os limites do contexto.
Com o Nemotron 3, cada modelo é construído com a mesma base arquitetônica, mas visa um equilíbrio diferente entre profundidade de raciocínio, rendimento e eficiência.
Neste artigo, vamos ver como a família Nemotron 3 está estruturada, o que mudou nos bastidores e onde ela se encaixa nos sistemas de agentes comumente usados.
A ideia principal por trás do Nemotron 3 é a especialização. Alguns agentes precisam ser leves e rápidos, lidando com tarefas rotineiras, como roteamento ou resumo. Outros são responsáveis por análises mais detalhadas ou planejamento de longo prazo. Ao oferecer vários modelos dentro da mesma geração, o Nemotron 3 ajuda nessa divisão de tarefas, sem deixar de ser transparente e auto-hospedável.
O Nemotron 3 Nano é o modelo mais focado na eficiência da família. É um modelo de 30 bilhões de parâmetros que ativa até 3B parâmetros por token usando uma arquitetura híbrida de mistura de especialistas. Essa ativação seletiva permite que o Nano tenha um alto rendimento e custos baixos de inferência, mantendo uma precisão competitiva para o seu tamanho.
O Nano é feito pra tarefas como resumir, recuperar, classificar e ajudar em fluxos de trabalho gerais. Em sistemas multiagentes, ele funciona bem como um trabalhador de alto volume, lidando com etapas frequentes ou intermediárias sem se tornar um gargalo de custo.
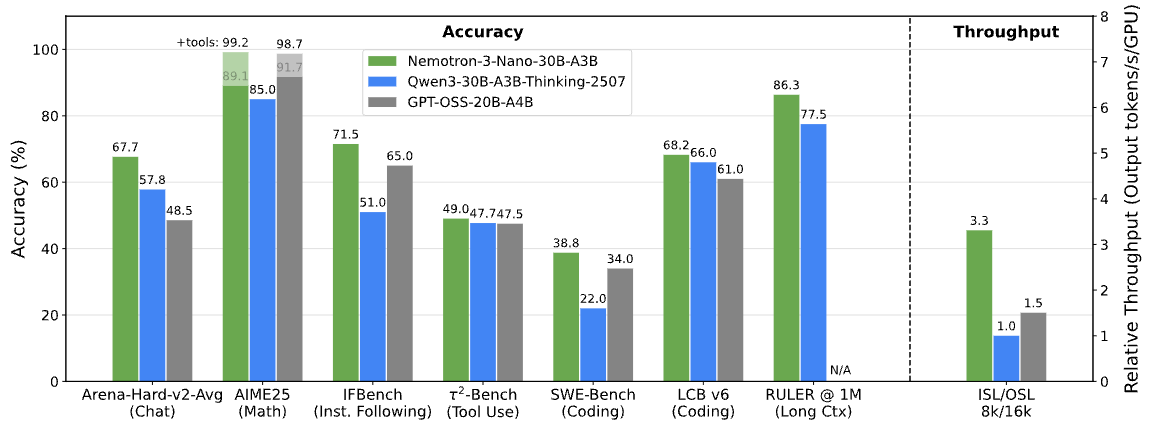
Benchmarks do Nemotron 3. Imagem da NVIDIA Research
O Nemotron 3 Super é feito pra situações que pedem um raciocínio mais forte, mesmo com as limitações de latência. Tem cerca de 100 bilhões de parâmetros, com até 10 bilhões ativos por token, e é otimizado para cargas de trabalho coordenadas de múltiplos agentes.
Super fica entre Nano e Ultra. Ele oferece uma capacidade de raciocínio maior do que o Nano, sem os requisitos completos de computação do modelo maior, o que o torna uma boa opção para agentes que precisam juntar várias entradas ou raciocinar em várias etapas.
O Nemotron 3 Ultra é o modelo mais potente da linha. Com cerca de 500 bilhões de parâmetros e até 50 bilhões ativos por token, ele funciona como um mecanismo de raciocínio de ponta para fluxos de trabalho complexos de agentes.
O Ultra foi feito pra tarefas que envolvem análises detalhadas, planejamento de longo prazo ou tomadas de decisão estratégicas. Embora tenha requisitos de computação mais elevados, ele foi projetado para operar junto com modelos Nemotron menores, com apenas as tarefas mais exigentes sendo encaminhadas para ele.
Agora que a linha de modelos está clara, a próxima pergunta é como a NVIDIA equilibra escala e eficiência em níveis tão diferentes.
Em vez de depender de uma única inovação arquitetônica, o Nemotron 3 junta várias opções de design que se complementam para tornar os grandes sistemas multiagentes práticos de usar.
No centro do Nemotron 3 está uma mistura híbrida latente mistura de especialistas (MoE) híbrida. Em vez de ativar todos os parâmetros para cada token, o modelo encaminha cada token por um pequeno subconjunto de redes especializadas.
Isso reduz o custo da inferência, ao mesmo tempo que mantém a capacidade de um modelo bem maior. Em sistemas baseados em agentes, onde muitos agentes podem gerar resultados intermediários ao mesmo tempo, a ativação seletiva ajuda a manter os requisitos de computação sob controle conforme a escala aumenta.
O Nemotron 3 Super e o Ultra são treinados usando o formato de precisão NVFP4 de 4 bits da NVIDIA na arquitetura Blackwell. O treinamento com menor precisão reduz o uso de memória e acelera o treinamento, permitindo trabalhar com modelos MoE maiores na infraestrutura existente.
É importante ressaltar que isso é feito sem uma queda significativa na precisão em relação aos formatos de maior precisão, o que ajuda a explicar como o Nemotron 3 pode ser dimensionado e, ao mesmo tempo, permanecer prático para implantação.
O Nemotron 3 Nano suporta janelas de contexto de até um milhão de tokens. Isso permite que o modelo retenha informações em documentos longos, registros extensos ou históricos de tarefas com várias etapas.
Para fluxos de trabalho de agentes, como tarefas de roteamento entre agentes de planejamento, recuperação e execução, um contexto mais longo reduz a necessidade de fragmentação agressiva ou sistemas de memória externos.
Essas decisões arquitetônicas não são abstratas. Eles aparecem diretamente na forma como o Nemotron 3 se comporta em sistemas reais.
A NVIDIA diz que o Nemotron 3 Nano gera até 60% menos tokens de raciocínio do que o Nemotron 2 Nano. Em sistemas multiagentes, onde as etapas intermediárias de raciocínio podem dominar o uso total de tokens, essa redução afeta diretamente o custo e a escalabilidade.
Raciocínios mais curtos ajudam a manter a eficiência da inferência sem comprometer a precisão da tarefa.
A combinação do roteamento MoE e a ativação seletiva de parâmetros permite que o Nemotron 3 mantenha um alto rendimento à medida que os fluxos de trabalho se tornam mais complexos. Isso facilita o suporte a cadeias de tarefas mais longas ou mais agentes simultâneos sem aumentos proporcionais na latência.
Com suporte para até um milhão de tokens em Nano, o Nemotron 3 permite raciocínios de longo prazo sobre entradas estendidas. Os agentes podem consultar etapas anteriores ou documentos grandes sem precisar resumir ou recarregar o estado várias vezes, melhorando a consistência ao longo do tempo.
Juntas, essas características explicam por que o Nemotron 3 dá mais importância à eficiência e à coordenação do que ao desempenho bruto de um único modelo.
A essa altura, os objetivos do projeto do Nemotron 3 já devem estar bem claros. Comparar com o Nemotron 2 ajuda a ver se essas metas se transformaram em melhorias que a gente pode medir.
O Nemotron 3 melhora o roteamento de mistura de especialistas, aumenta a produtividade, reduz a geração de tokens de raciocínio e aumenta bastante o comprimento do contexto. A NVIDIA diz que o Nemotron 3 Nano tem um rendimento de tokens até 4 vezes maior do que o Nemotron 2 Nano, além de uma grande redução nos tokens de raciocínio.
Outra diferença é o escopo. O Nemotron 3 vai além dos modelos, vindo com conjuntos de dados de aprendizado por reforço, dados de segurança de agentes e ferramentas abertas, como o NeMo Gym e o NeMo RL. O Nemotron 2 focava principalmente em lançamentos de modelos, enquanto o Nemotron 3 é mais completo para o desenvolvimento de agentes.
Com a arquitetura e os benchmarks no contexto, fica mais claro onde o Nemotron 3 se encaixa no cenário atual dos modelos. A NVIDIA não está posicionando o Nemotron 3 como um substituto direto para os modelos proprietários de ponta. Em vez disso, ele foca em um desafio diferente: tornar os sistemas de IA baseados em agentes eficientes, previsíveis e escaláveis em implementações reais.
Comparado com outros grandes modelos abertos, o Nemotron 3 dá menos importância a maximizar as pontuações de benchmark de um único modelo e mais a questões relacionadas ao nível do sistema, como rendimento, eficiência de tokens de raciocínio, tratamento de contexto longo e coordenação entre agentes. Esse enquadramento é parecido com a forma como a Mistral posiciona sua própria linha de produtos, mas com um foco maior em cargas de trabalho com vários agentes.
A tabela abaixo mostra os principais pontos em que o Nemotron 3 se destacaem relação a outros modelos populares abertos e proprietários.
|
Dimensão |
Nemotron 3 |
Mistral Grande 3 |
DeepSeek-Class Models |
Modelos de propriedade da Frontier |
|
Objetivo principal do projeto |
Eficiência multiagente em escala |
Capacidade de modelo único |
Profundidade do raciocínio por prompt |
Raciocínio e agentes de fronteira |
|
Foco em Arquitetura |
MoE latente híbrido |
MoE esparso |
Denso / MoE |
Denso, exclusivo |
|
Taxa de transferência (Tokens/segundo) |
Muito alto (a Nano lidera o grupo) |
Alto, mas exige muito processamento |
Moderado |
Moderado a alto |
|
Uso do token de raciocínio |
Reduzido (até ~60% menos no Nano) |
Moderado |
Mais alto |
Mais alto |
|
Janela de contexto |
Até 1 milhão de tokens (Nano) |
Até ~256K |
Longo, mas menor |
Longo (varia de acordo com o modelo) |
|
Adequação de múltiplos agentes |
Ótimo |
Moderado |
Moderado |
Forte, mas caro |
|
Auto-hospedagem e controle |
Completo (pesos abertos) |
Completo (pesos abertos) |
Completo (pesos abertos) |
Limitado / nenhum |
|
Melhor caso de uso |
Coordenação de agentes, encaminhamento, resumo |
Raciocínio profundo, codificação |
Tarefas de matemática e raciocínio |
Planejamento complexo, SWE |
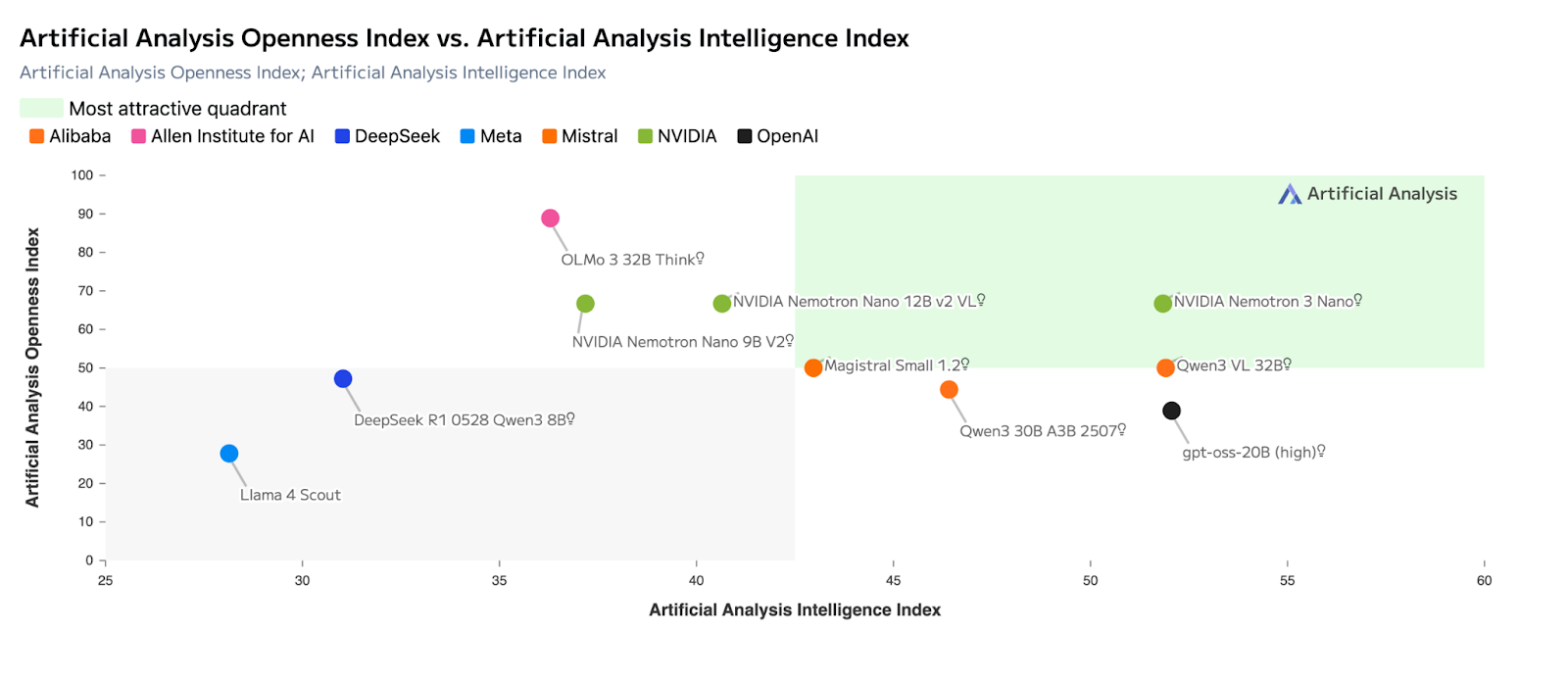
O Mistral Large 3 e o Nemotron 3 dependem ambos de mistura de especialistas , mas otimizam para resultados diferentes.
O Mistral Large 3 foi feito pra maximizar a capacidade de um único modelo, com um desempenho forte em raciocínio, codificação e benchmarks de uso geral, como avaliações do tipo LMArena e SWE. Muitas vezes, é a melhor escolha quando se espera que um modelo lide com uma tarefa inteira do início ao fim.
Já o Nemotron 3 é feito pra ser eficiente no nível do sistema. Seu design híbrido de MoE latente ativa menos parâmetros por token e prioriza a taxa de transferência em vez da profundidade máxima de raciocínio. Isso faz com que seja mais adequado para funções que exigem muita coordenação — roteamento, resumo e raciocínio intermediário, onde muitos agentes operam ao mesmo tempo.
Depois que os objetivos do projeto estiverem claros, a próxima pergunta é prática: como você pode realmente executar o Nemotron 3 hoje e quais opções fazem sentido, considerando sua configuração? A NVIDIA oferece várias formas de acesso, desde APIs totalmente hospedadas até implantações autogerenciadas.
A maneira mais rápida de começar é usando provedores de inferência hospedados. O Nemotron 3 Nano já está disponível em plataformas como Baseten, DeepInfra, Fireworks, FriendliAI, OpenRoutere Together AI. Esses serviços expõem interfaces API padrão, permitindo que você teste o comportamento do modelo, a taxa de transferência e o tratamento de contexto longo sem precisar provisionar hardware.
Essa opção é ideal para criar protótipos de fluxos de trabalho de agentes, comparar desempenho ou integrar o Nemotron 3 em aplicativos já existentes com o mínimo de configuração.
Os modelos Nemotron 3 também são lançados com pesos abertos no Hugging Face, o que permite controle total sobre a implantação. Essa rota é pra equipes que querem hospedar os modelos por conta própria, ajustá-los com dados específicos do domínio ou integrá-los em pipelines de agentes personalizados.
Com pesos abertos, você pode:
Essa abordagem está alinhada com a ênfase da NVIDIA na transparência e na propriedade de sistemas de agentes de longa duração e de nível de produção.
Para equipes que querem uma experiência de auto-hospedagem mais gerenciada, o Nemotron 3 Nano também está disponível como um microsserviço NVIDIA NIM. A NIM empacota o modelo para uma implantação segura e escalável em infraestrutura acelerada pela NVIDIA, seja no local ou na nuvem.
À medida que o ecossistema amadurece, espera-se que os modelos Nemotron também se integrem com estruturas de implantação comuns e tempos de execução usados para inferência local e de ponta. Essas opções facilitam a experimentação do Nemotron 3 em ambientes controlados, sem precisar criar uma pilha de implantação do zero.
Na hora do lançamento:
Na prática, isso quer dizer que os desenvolvedores podem começar a testar o Nano já, enquanto os modelos maiores são mais indicados para implementações em fases posteriores, que exigem uma capacidade de raciocínio mais forte.
O Nemotron 3 é forte dentro do seu escopo pretendido. A principal contribuição não é expandir os limites do raciocínio de modelo único, mas tornar os sistemas baseados em agentes mais práticos para implantar e escalar.
As escolhas arquitetônicas trazem benefícios operacionais reais, principalmente para fluxos de trabalho que dependem de muitos agentes trabalhando juntos. Dito isso, se o que você mais precisa é um raciocínio profundo com um único modelo ou um planejamento complexo com ferramentas, os modelos proprietários de ponta ainda costumam ser mais consistentes.
Visto pela perspectiva certa, o Nemotron 3 complementa esses modelos em vez de substituí-los.
O Nemotron 3 é ideal para situações em que eficiência, transparência e escalabilidade são importantes.
Como os modelos são abertos e feitos para trabalhar juntos, as equipes podem atribuir funções diferentes a tamanhos diferentes de modelos, em vez de depender de um único sistema monolítico.
O foco da NVIDIA em eficiência, abertura e design em nível de sistema mostra como muitas aplicações de IA do mundo real estão sendo criadas agora.
Agora, para construir de forma eficaz com modelos como o Nemotron 3, é útil entender tanto os fundamentos do LLM quanto a integração do sistema.
Nosso curso Conceitos de Modelos de Linguagem de Grande Porte (LLMs) dá uma base conceitual, enquanto nosso programa Construindo APIs em Python mostra o lado prático de integrar modelos em aplicativos.
Visto como parte de um sistema maior, o Nemotron 3 parece menos um lançamento de modelo e mais uma base para como a IA baseada em agentes está sendo usada hoje em dia.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
blog
blog
Richie Cotton
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan



