
Kurs
Künstliche Intelligenz verstehen
2 Std.
401.5K
Nemotron 3 ist NVIDIAs Antwort auf die neuen Herausforderungen von Multi-Agenten-KI-Systemen. Was ich meine, ist: Wenn KI-Systeme mehr und mehr in Richtung Multi-Agenten-Workflows gehen, steigen die Kosten für die Inferenz, die Koordination wird schwieriger und lang andauernde Aufgaben strapazieren die Kontextgrenzen.
Bei Nemotron 3 basiert jedes Modell auf derselben Architektur, zielt aber auf eine unterschiedliche Balance zwischen Argumentationstiefe, Durchsatz und Effizienz ab.
In diesem Artikel schauen wir uns an, wie die Nemotron 3-Familie aufgebaut ist, was sich im Hintergrund geändert hat und wo sie in gängigen Agentensystemen passt.
Die Hauptidee von Nemotron 3 ist Spezialisierung. Einige Agenten müssen leicht und schnell sein und Routineaufgaben wie Weiterleitung oder Zusammenfassung erledigen. Andere kümmern sich um tiefere Analysen oder langfristige Planung. Durch das Angebot mehrerer Modelle innerhalb derselben Generation unterstützt Nemotron 3 diese Arbeitsteilung und bleibt dabei transparent und selbst hostbar.
Nemotron 3 Nano ist das Modell mit der höchsten Effizienz in der Familie. Es ist ein Modell mit 30 Milliarden Parametern, das bis zu 3B Parameter pro Token mit einer hybriden „Mixture-of-Experts”-Architektur aktiviert. Durch diese gezielte Aktivierung kann Nano einen hohen Durchsatz und niedrige Inferenzkosten erreichen und dabei eine für seine Größe konkurrenzfähige Genauigkeit beibehalten.
Nano ist für Aufgaben wie Zusammenfassung, Abruf, Klassifizierung und allgemeine Assistenz-Workflows gedacht. In Multi-Agenten-Systemen funktioniert es gut als Hochleistungsarbeiter, der häufige oder mittlere Schritte erledigt, ohne dass es zu einem Kostenengpass kommt.
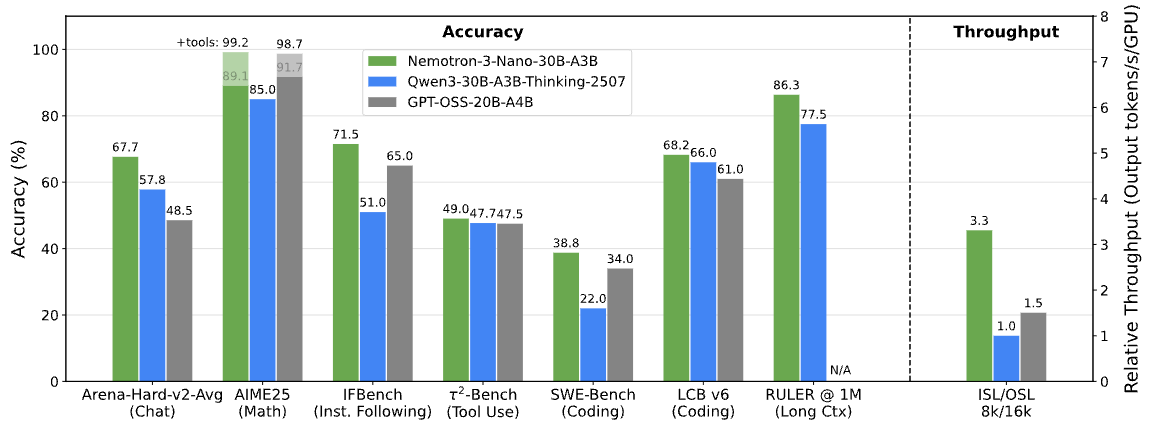
Nemotron 3 Benchmarks. Bild von NVIDIA Research
Nemotron 3 Super ist für Situationen gedacht, in denen man besser denken muss, aber trotzdem mit Latenzproblemen klarkommen muss. Es hat etwa 100 Milliarden Parameter, wobei bis zu 10 Milliarden pro Token aktiv sind, und ist für koordinierte Multi-Agent-Workloads optimiert.
Super liegt zwischen Nano und Ultra. Es bietet eine höhere Denkfähigkeit als Nano, ohne die vollen Rechenanforderungen des größten Modells, was es super für Agenten macht, die mehrere Eingaben kombinieren oder über mehrere Schritte hinweg denken müssen.
Nemotron 3 Ultra ist das leistungsstärkste Modell in der Produktreihe. Mit ungefähr 500 Milliarden Parametern und bis zu 50 Milliarden aktiven Parametern pro Token ist es eine echt leistungsstarke Engine für komplexe agentenbasierte Abläufe.
Ultra ist für Aufgaben gedacht, bei denen es um gründliche Analysen, langfristige Planung oder strategische Entscheidungen geht. Obwohl es höhere Rechenanforderungen hat, soll es zusammen mit kleineren Nemotron-Modellen laufen, wobei nur die anspruchsvollsten Aufgaben an es weitergeleitet werden.
Jetzt, wo die Modellpalette klar ist, geht's darum, wie NVIDIA Größe und Effizienz über so unterschiedliche Stufen hinweg ausbalanciert.
Anstatt sich auf einen einzigen architektonischen Durchbruch zu verlassen, kombiniert Nemotron 3 mehrere sich ergänzende Designentscheidungen, um große Multi-Agenten-Systeme praktisch einsetzbar zu machen.
Das Herzstück von Nemotron 3 ist ein hybrider Latent-Experten-Mix. Mixture-of-Experts (MoE). Anstatt alle Parameter für jedes Token zu aktivieren, leitet das Modell jedes Token durch eine kleine Untergruppe spezialisierter Expertennetzwerke.
Das senkt die Kosten für die Inferenz und behält trotzdem die Kapazität eines viel größeren Modells bei. In agentenbasierten Systemen, wo viele Agenten gleichzeitig Zwischenergebnisse erzeugen können, hilft die selektive Aktivierung dabei, die Rechenanforderungen bei steigender Größe überschaubar zu halten.
Nemotron 3 Super und Ultra werden mit dem 4-Bit-Präzisionsformat NVFP4 von NVIDIA auf der Blackwell-Architektur trainiert. Training mit geringerer Genauigkeit spart Speicherplatz und macht das Training schneller, sodass man mit größeren MoE-Modellen auf der vorhandenen Infrastruktur arbeiten kann.
Wichtig ist, dass das ohne nennenswerten Genauigkeitsverlust gegenüber präziseren Formaten passiert, was erklärt, warum Nemotron 3 skalierbar und trotzdem praktisch einsetzbar ist.
Nemotron 3 Nano kann Kontextfenster mit bis zu einer Million Token verarbeiten. Dadurch kann das Modell Infos über lange Dokumente, umfangreiche Protokolle oder mehrstufige Aufgabenverläufe hinweg behalten.
Bei Agent-Workflows, wie zum Beispiel der Weiterleitung von Aufgaben zwischen Planungs-, Abruf- und Ausführungsagenten, macht ein längerer Kontext aggressive Chunking-Verfahren oder externe Speichersysteme weniger wichtig.
Diese architektonischen Entscheidungen sind nicht abstrakt. Sie zeigen sich direkt im Verhalten von Nemotron 3 in echten Systemen.
NVIDIA sagt, dass Nemotron 3 Nano bis zu 60 % weniger Reasoning-Tokens braucht als Nemotron 2 Nano. In Multi-Agenten-Systemen, wo die Zwischenschritte beim Denken die Gesamtzahl der verwendeten Token dominieren können, wirkt sich diese Reduzierung direkt auf die Kosten und die Skalierbarkeit aus.
Kürzere Argumentationsketten helfen dabei, Schlussfolgerungen effizient zu halten, ohne die Genauigkeit der Aufgabe zu beeinträchtigen.
Durch die Kombination von MoE-Routing und selektiver Parameteraktivierung kann Nemotron 3 auch bei immer komplexeren Arbeitsabläufen einen hohen Durchsatz halten. Dadurch ist es einfacher, längere Aufgabenketten oder mehr Agenten gleichzeitig zu unterstützen, ohne dass die Latenzzeit proportional zunimmt.
Mit der Unterstützung von bis zu einer Million Token in Nano ermöglicht Nemotron 3 langfristige Überlegungen zu umfangreichen Eingaben. Agenten können auf frühere Schritte oder große Dokumente zurückgreifen, ohne alles immer wieder zusammenfassen oder neu laden zu müssen, was die Konsistenz auf Dauer verbessert.
Zusammen genommen zeigen diese Features, warum Nemotron 3 mehr Wert auf Effizienz und Koordination legt als auf die reine Leistung eines einzelnen Modells.
Jetzt sollten die Designziele von Nemotron 3 klar sein. Wenn man es mit Nemotron 2 vergleicht, kann man besser sehen, ob diese Ziele zu messbaren Verbesserungen geführt haben.
Nemotron 3 macht das Routing nach dem „Mixture-of-Experts”-Prinzip besser, steigert den Durchsatz, reduziert die Generierung von Reasoning-Tokens und erweitert die Kontextlänge deutlich. NVIDIA sagt, dass Nemotron 3 Nano bis zu viermal mehr Token durchläuft als Nemotron 2 Nano und dass es viel weniger Reasoning-Tokens braucht.
Ein weiterer Unterschied ist der Umfang. Nemotron 3 geht über reine Modelle hinaus und kommt mit Datensätzen für verstärktes Lernen, Agentensicherheitsdaten und offenen Tools wie NeMo Gym und NeMo RL. Nemotron 2 hat sich hauptsächlich auf Modellveröffentlichungen konzentriert, während Nemotron 3 als ein kompletterer Stack für die Agentenentwicklung gedacht ist.
Wenn man die Architektur und die Benchmarks im Blick hat, wird klarer, wo Nemotron 3 in die aktuelle Modelllandschaft passt. NVIDIA sieht Nemotron 3 nicht als Ersatz für die aktuellen proprietären Modelle. Stattdessen geht's um eine andere Herausforderung: agentenbasierte KI-Systeme effizient, vorhersehbar und skalierbar in echten Einsätzen zu machen.
Im Vergleich zu anderen großen offenen Modellen legt Nemotron 3 weniger Wert darauf, die Benchmark-Ergebnisse einzelner Modelle zu maximieren, sondern konzentriert sich mehr auf Dinge auf Systemebene wie Durchsatz, Effizienz der Reasoning-Token, Umgang mit langen Kontexten und die Koordination zwischen Agenten. Diese Einordnung ähnelt der Art und Weise, wie Mistral sein eigenes Angebot positioniert, legt aber einen stärkeren Fokus auf Multi-Agent-Workloads.
Die Tabelle unten zeigt die wichtigsten Punkte, in denen Nemotron 3im Vergleich zu anderen beliebten offenen und proprietären Modellen gut abschneidet.
|
Dimension |
Nemotron 3 |
Mistral Large 3 |
DeepSeek-Klasse-Modelle |
Frontier-eigene Modelle |
|
Hauptziel des Designs |
Effizienz von Multi-Agenten in großem Maßstab |
Einzelmodell-Fähigkeit |
Tiefe der Argumentation pro Eingabeaufforderung |
Grenzargumente & Akteure |
|
Architektur im Fokus |
Hybride latente MoE |
Sparse MoE |
Dicht / MoE |
Dicht, proprietär |
|
Durchsatz (Tokens/Sekunde) |
Super hoch (Nano ist der Beste) |
Hoch, aber rechenintensiv |
Mäßig |
Mäßig bis hoch |
|
Verwendung von Argumentationstoken |
Reduziert (bis zu ~60 % weniger in Nano) |
Mäßig |
Höher |
Höher |
|
Kontextfenster |
Bis zu 1 Million Token (Nano) |
Bis zu ~256K |
Lang, aber kleiner |
Lang (je nach Modell unterschiedlich) |
|
Eignung für Multi-Agenten |
Super |
Mäßig |
Mäßig |
Stark, aber teuer |
|
Selbsthosting & Kontrolle |
Voll (offene Gewichte) |
Voll (offene Gewichte) |
Voll (offene Gewichte) |
Eingeschränkt / keine |
|
Bester Anwendungsfall |
Agentenkoordination, Weiterleitung, Zusammenfassung |
Tiefes Denken, Programmieren |
Mathe- und Denkaufgaben |
Komplexe Planung, SWE |
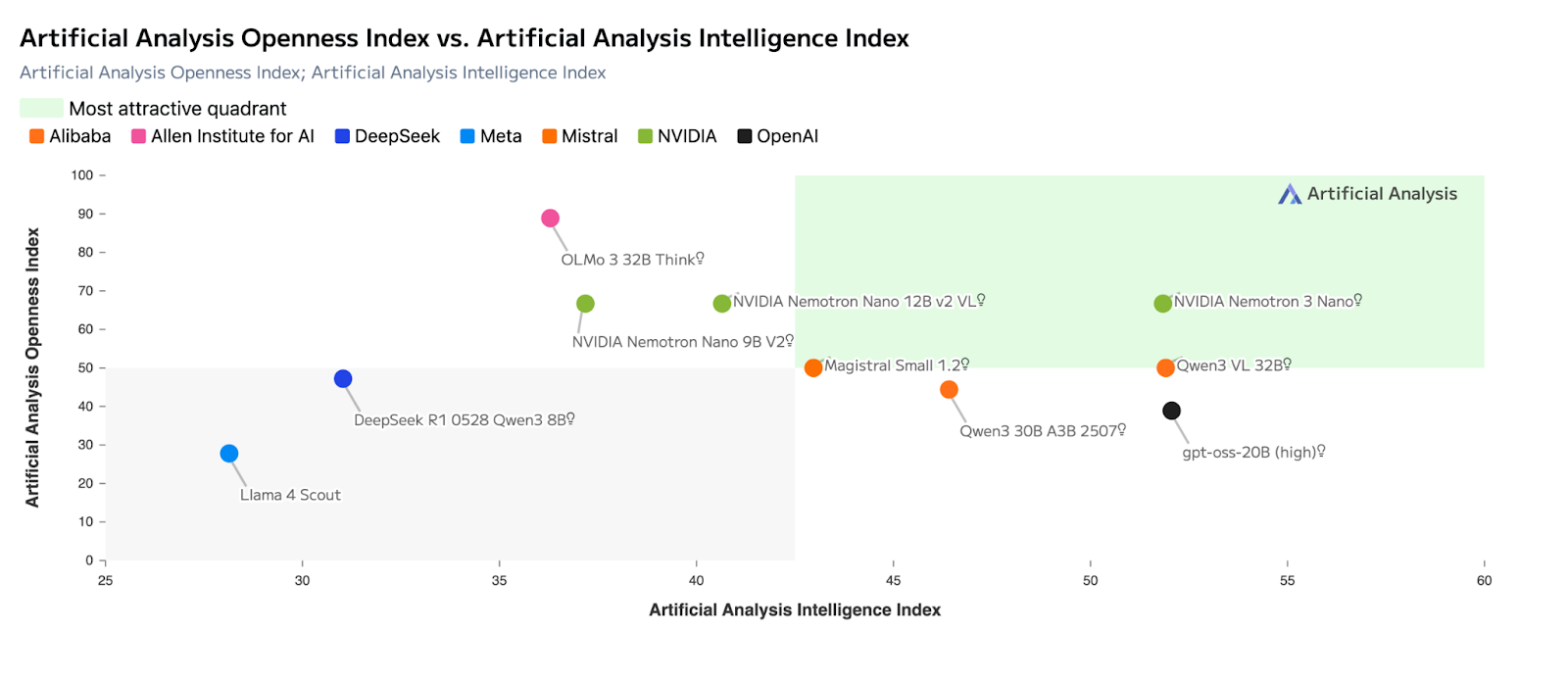
Mistral Large 3 und Nemotron 3 nutzen beide Expertenmischung , aber sie sind für unterschiedliche Ergebnisse optimiert.
Mistral Large 3 ist so gemacht, dass es die Leistung eines einzelnen Modells maximiert und bei Benchmarks für Schlussfolgerungen, Codierung und allgemeine Zwecke wie LMArena und SWE-ähnlichen Bewertungen richtig gut abschneidet. Es ist oft die bessere Wahl, wenn ein Modell eine ganze Aufgabe von Anfang bis Ende erledigen soll.
Nemotron 3 ist dagegen auf Effizienz auf Systemebene ausgelegt. Sein hybrides latentes MoE-Design aktiviert weniger Parameter pro Token und setzt auf Durchsatz statt auf maximale Rechentiefe. Das macht es besser für Aufgaben, bei denen es auf Koordination ankommt – Routing, Zusammenfassung und Zwischenüberlegungen, wo viele Agenten gleichzeitig arbeiten.
Sobald die Designziele klar sind, kommt die nächste Frage: Wie kannst du Nemotron 3 heute tatsächlich nutzen und welche Optionen sind bei deiner Konfiguration sinnvoll? NVIDIA hat verschiedene Möglichkeiten, von komplett gehosteten APIs bis hin zu selbstverwalteten Implementierungen.
Der schnellste Weg, um loszulegen, sind gehostete Inferenzanbieter. Nemotron 3 Nano ist jetzt auf Plattformen wie Baseten, DeepInfra, Fireworks, FriendliAI, OpenRouterund Together AI. Diese Dienste bieten Standard-API-Schnittstellen, mit denen du das Verhalten, den Durchsatz und die Verarbeitung langer Kontexte des Modells testen kannst, ohne Hardware bereitstellen zu müssen.
Diese Option ist super für das Erstellen von Prototypen für Agenten-Workflows, das Vergleichen der Leistung oder das Einbinden von Nemotron 3 in bestehende Anwendungen mit minimalem Aufwand.
Die Nemotron 3-Modelle gibt's auch mit offenen Gewichten auf Hugging Face, veröffentlicht, was die volle Kontrolle über den Einsatz ermöglicht. Diese Option ist für Teams gedacht, die die Modelle selbst hosten, sie anhand domänenspezifischer Daten optimieren oder in benutzerdefinierte Agent-Pipelines integrieren wollen.
Mit offenen Gewichten kannst du:
Dieser Ansatz passt zu NVIDIAs Fokus auf Transparenz und Eigentumsrechte bei langlebigen, produktionsreifen Agentensystemen.
Für Teams, die eine besser verwaltete Selbsthosting-Erfahrung wollen, gibt's Nemotron 3 Nano auch als NVIDIA NIM-Mikroservice. NIM macht das Modell für eine sichere und skalierbare Bereitstellung auf NVIDIA-beschleunigter Infrastruktur, egal ob vor Ort oder in der Cloud.
Wenn das System reifer wird, sollen die Nemotron-Modelle auch mit gängigen Frameworks und Laufzeitumgebungen für lokale und Edge-Inferenz zusammenarbeiten. Mit diesen Optionen kannst du Nemotron 3 in einer kontrollierten Umgebung ausprobieren, ohne einen Deployment-Stack von Grund auf neu aufbauen zu müssen.
Zum Zeitpunkt der Veröffentlichung:
In der Praxis heißt das, dass Entwickler sofort mit Nano loslegen können, während die größeren Modelle für spätere Einsätze gedacht sind, die mehr Rechenleistung brauchen.
Nemotron 3 ist in seinem vorgesehenen Anwendungsbereich echt stark. Der Hauptbeitrag besteht nicht darin, die Grenzen des Ein-Modell-Denkens zu erweitern, sondern darin, agentenbasierte Systeme praktischer einsetzbar und skalierbar zu machen.
Die architektonischen Entscheidungen bringen echte Vorteile im Betrieb, vor allem bei Arbeitsabläufen, bei denen viele Leute zusammenarbeiten. Wenn du aber vor allem auf tiefgreifende, auf einem einzigen Modell basierende Schlussfolgerungen oder komplexe, toolbasierte Planung angewiesen bist, sind proprietäre Modelle von Frontier immer noch die zuverlässigere Wahl.
Wenn man es richtig betrachtet, ergänzt Nemotron 3 diese Modelle, anstatt sie zu ersetzen.
Nemotron 3 passt am besten zu Situationen, in denen es auf Effizienz, Transparenz und Skalierbarkeit ankommt.
Weil die Modelle offen sind und so gemacht, dass sie zusammenarbeiten, können Teams verschiedenen Modellgrößen unterschiedliche Rollen zuweisen, anstatt sich auf ein einziges, monolithisches System zu verlassen.
NVIDIAs Fokus auf Effizienz, Offenheit und Design auf Systemebene zeigt, wie viele praktische KI-Anwendungen gerade entwickelt werden.
Um mit Modellen wie Nemotron 3 effektiv arbeiten zu können, ist es hilfreich, sowohl die Grundlagen von LLM als auch die Systemintegration zu verstehen.
Unser Kurs „Konzepte großer Sprachmodelle (LLMs) “ gibt dir die theoretischen Grundlagen, während unser Lernpfad „Erstellen von APIs in Python“ zeigt, wie man Modelle in Anwendungen einbaut.
Wenn man Nemotron 3 als Teil eines größeren Systems betrachtet, wirkt es weniger wie eine Modellveröffentlichung, sondern eher wie eine Grundlage dafür, wie agentenbasierte KI heute eingesetzt wird.
Lerne mit DataCamp
Kurs
Kurs
Kurs