
Cours
Comprendre l'intelligence artificielle
2 h
401.5K
Nemotron 3 est la réponse de NVIDIA aux contraintes émergentes des systèmes d'IA multi-agents. Ce que je veux dire, c'est que lorsque les systèmes d'IA évoluent vers des flux de travail multi-agents, les coûts d'inférence augmentent, la coordination devient difficile et les tâches de longue durée mettent à rude épreuve les limites contextuelles.
Avec Nemotron 3, chaque modèle est construit sur la même base architecturale, mais vise un équilibre différent entre profondeur de raisonnement, débit et efficacité.
Dans cet article, nous examinerons la structure de la famille Nemotron 3, les modifications apportées en arrière-plan et sa place parmi les systèmes d'agents couramment utilisés.
L'idée centrale derrière Nemotron 3 est la spécialisation. Certains agents doivent être légers et rapides, afin de gérer des tâches courantes telles que le routage ou la synthèse. D'autres sont chargés d'effectuer des analyses plus approfondies ou d'élaborer des plans à long terme. En proposant plusieurs modèles au sein d'une même génération, Nemotron 3 favorise cette division du travail tout en restant transparent et auto-hébergeable.
Le Nemotron 3 Nano est le modèle le plus axé sur l'efficacité de la gamme. Il s'agit d'un modèle à 30 milliards de paramètres qui active jusqu'à 3 milliards de paramètres par jeton à l'aide d'une architecture hybride de mélange d'experts. Cette activation sélective permet à Nano d'atteindre un débit élevé et de réduire les coûts d'inférence tout en conservant une précision compétitive pour sa taille.
Nano est conçu pour des tâches telles que la synthèse, la recherche, la classification et les flux de travail d'assistance générale. Dans les systèmes multi-agents, il fonctionne efficacement en tant que travailleur à haut volume, traitant des étapes fréquentes ou intermédiaires sans devenir un goulot d'étranglement en termes de coûts.
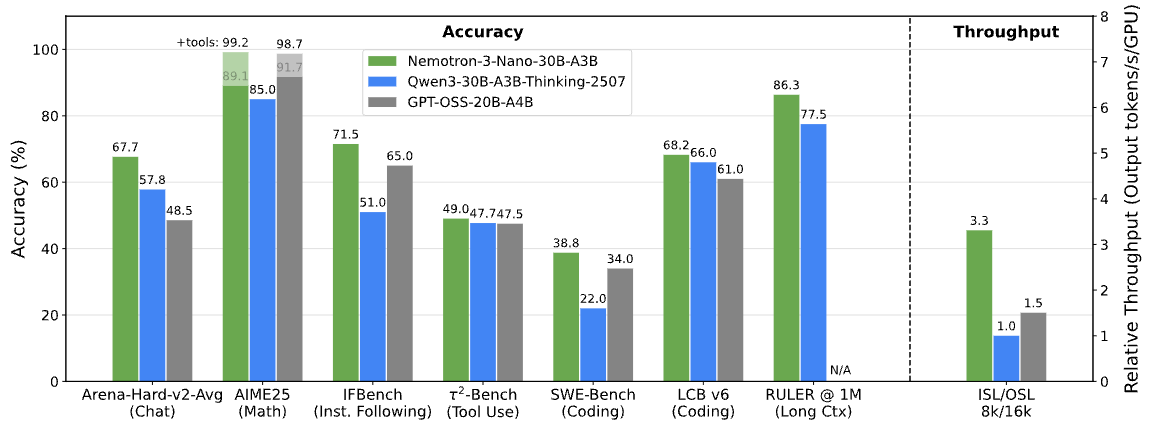
Benchmarks Nemotron 3. Image fournie par NVIDIA Research
Nemotron 3 Super cible les scénarios qui nécessitent un raisonnement plus poussé tout en continuant à fonctionner dans des conditions de latence. Il comporte environ 100 milliards de paramètres, avec jusqu'à 10 milliards actifs par jeton, et est optimisé pour les charges de travail multi-agents coordonnées.
Super se situe entre Nano et Ultra. Il offre une capacité de raisonnement supérieure à celle de Nano sans les exigences informatiques complètes du modèle le plus grand, ce qui le rend particulièrement adapté aux agents qui doivent combiner plusieurs entrées ou raisonner à travers plusieurs étapes.
Le Nemotron 3 Ultra est le modèle le plus performant de la gamme. Avec environ 500 milliards de paramètres et jusqu'à 50 milliards actifs par jeton, il sert de moteur de raisonnement haut de gamme pour les flux de travail complexes impliquant des agents.
Ultra est conçu pour les tâches impliquant une analyse approfondie, une planification à long terme ou une prise de décision stratégique. Bien qu'il présente des exigences informatiques plus élevées, il est conçu pour fonctionner en parallèle avec des modèles Nemotron plus petits, seules les tâches les plus exigeantes lui étant attribuées.
Maintenant que la gamme de modèles est claire, la question suivante est de savoir comment NVIDIA équilibre l'échelle et l'efficacité entre des niveaux aussi différents.
Plutôt que de s'appuyer sur une seule avancée architecturale, Nemotron 3 combine plusieurs choix de conception complémentaires afin de rendre les grands systèmes multi-agents pratiques à exploiter.
Au cœur de Nemotron 3 se trouve un mélange hybride latent mixture d'experts (MoE) hybride. Au lieu d'activer tous les paramètres pour chaque jeton, le modèle achemine chaque jeton à travers un petit sous-ensemble de réseaux experts spécialisés.
Cela réduit le coût de l'inférence tout en conservant la capacité d'un modèle beaucoup plus grand. Dans les systèmes basés sur des agents où de nombreux agents peuvent générer simultanément des résultats intermédiaires, l'activation sélective permet de maintenir les besoins informatiques à un niveau gérable à mesure que l'échelle augmente.
Nemotron 3 Super et Ultra sont entraînés à l'aide du format de précision NVFP4 4 bits de NVIDIA sur l'architecture Blackwell. Une formation à plus faible précision réduit l'utilisation de la mémoire et accélère la formation, ce qui permet de travailler avec des modèles MoE plus volumineux sur l'infrastructure existante.
Il est important de noter que cela se fait sans perte significative de précision par rapport aux formats plus précis, ce qui explique comment Nemotron 3 peut évoluer tout en restant pratique à déployer.
Nemotron 3 Nano prend en charge des fenêtres contextuelles pouvant contenir jusqu'à un million de jetons. Cela permet au modèle de conserver les informations contenues dans des documents volumineux, des journaux étendus ou des historiques de tâches en plusieurs étapes.
Pour les flux de travail des agents, tels que l'acheminement des tâches entre les agents de planification, de récupération et d'exécution, un contexte plus long réduit le besoin de découpage agressif ou de systèmes de mémoire externes.
Ces décisions architecturales ne sont pas abstraites. Ils apparaissent directement dans le comportement de Nemotron 3 dans les systèmes réels.
NVIDIA indique que Nemotron 3 Nano génère jusqu'à 60 % de jetons de raisonnement en moins que Nemotron 2 Nano. Dans les systèmes multi-agents, où les étapes de raisonnement intermédiaires peuvent dominer l'utilisation totale des jetons, cette réduction a un impact direct sur le coût et l'évolutivité.
Des raisonnements plus courts permettent de maintenir l'efficacité de l'inférence sans compromettre la précision de la tâche.
La combinaison du routage MoE et de l'activation sélective des paramètres permet à Nemotron 3 de maintenir un débit élevé à mesure que les flux de travail deviennent plus complexes. Cela facilite la prise en charge de chaînes de tâches plus longues ou d'un plus grand nombre d'agents simultanés sans augmentation proportionnelle de la latence.
Avec une prise en charge pouvant atteindre un million de jetons dans Nano, Nemotron 3 permet un raisonnement à long terme sur des entrées étendues. Les agents peuvent se référer aux étapes précédentes ou à des documents volumineux sans avoir à résumer ou à recharger l'état à plusieurs reprises, ce qui améliore la cohérence au fil du temps.
Ensemble, ces caractéristiques expliquent pourquoi Nemotron 3 privilégie l'efficacité et la coordination plutôt que les performances brutes d'un modèle unique.
À ce stade, les objectifs de conception du Nemotron 3 devraient être clairs. La comparaison avec Nemotron 2 permet de vérifier si ces objectifs se sont traduits par des améliorations mesurables.
Nemotron 3 améliore le routage par mélange d'experts, augmente le débit, réduit la génération de jetons de raisonnement et élargit considérablement la longueur du contexte. NVIDIA indique que le débit de jetons de Nemotron 3 Nano est jusqu'à 4 fois supérieur à celui de Nemotron 2 Nano, avec une réduction significative des jetons de raisonnement.
Une autre différence réside dans la portée. Nemotron 3 va au-delà des modèles seuls et est livré avec des ensembles de données d'apprentissage par renforcement, des données de sécurité des agents et des outils ouverts tels que NeMo Gym et NeMo RL. Nemotron 2 se concentrait principalement sur les versions de modèles, tandis que Nemotron 3 se positionne comme une pile plus complète pour le développement d'agents.
Une fois l'architecture et les benchmarks contextualisés, la place occupée par Nemotron 3 dans le paysage actuel des modèles apparaît plus clairement. NVIDIA ne positionne pas Nemotron 3 comme un substitut direct aux modèles propriétaires de pointe. Au lieu de cela, il vise un autre défi : rendre les systèmes d'IA basés sur des agents efficaces, prévisibles et évolutifs dans des déploiements réels.
Par rapport à d'autres modèles ouverts de grande envergure, Nemotron 3 accorde moins d'importance à l'optimisation des scores de référence d'un modèle unique et se concentre davantage sur des aspects liés au système, tels que le débit, l'efficacité des jetons de raisonnement, la gestion des contextes longs et la coordination entre les agents. Cette approche est similaire à la manière dont Mistral positionne sa propre gamme, mais avec un accent plus marqué sur les charges de travail multi-agents.
Le tableau ci-dessous résume les principales caractéristiques qui distinguent Nemotron 3des autres modèles ouverts et propriétaires courants.
|
Dimension |
Nemotron 3 |
Mistral Large 3 |
Modèles de classe DeepSeek |
Modèles exclusifs Frontier |
|
Objectif principal de conception |
Efficacité multi-agents à grande échelle |
Capacité d'un seul modèle |
Profondeur de raisonnement par invite |
Raisonnement et agents pionniers |
|
Focus sur l'architecture |
MoE hybride latent |
MoE clairsemé |
Dense / MoE |
Dense, exclusif |
|
Débit (jetons/seconde) |
Très élevé (Nano est en tête parmi ses pairs) |
Élevé mais exigeant en termes de calcul |
Modéré |
Modéré à élevé |
|
Utilisation des jetons de raisonnement |
Réduit (jusqu'à environ 60 % de moins dans Nano) |
Modéré |
Supérieur |
Supérieur |
|
Context Window |
Jusqu'à 1 million de jetons (Nano) |
Jusqu'à environ 256 Ko |
Long, mais plus petit |
Long (varie selon le modèle) |
|
Adéquation multi-agents |
Excellent |
Modéré |
Modéré |
Robuste mais coûteux |
|
Hébergement et contrôle autonomes |
Complet (poids ouverts) |
Complet (poids ouverts) |
Complet (poids ouverts) |
Limité / Aucun |
|
Meilleur cas d'utilisation |
Coordination des agents, acheminement, synthèse |
Raisonnement approfondi, codage |
Tâches de mathématiques et de raisonnement |
Planification complexe, SWE |
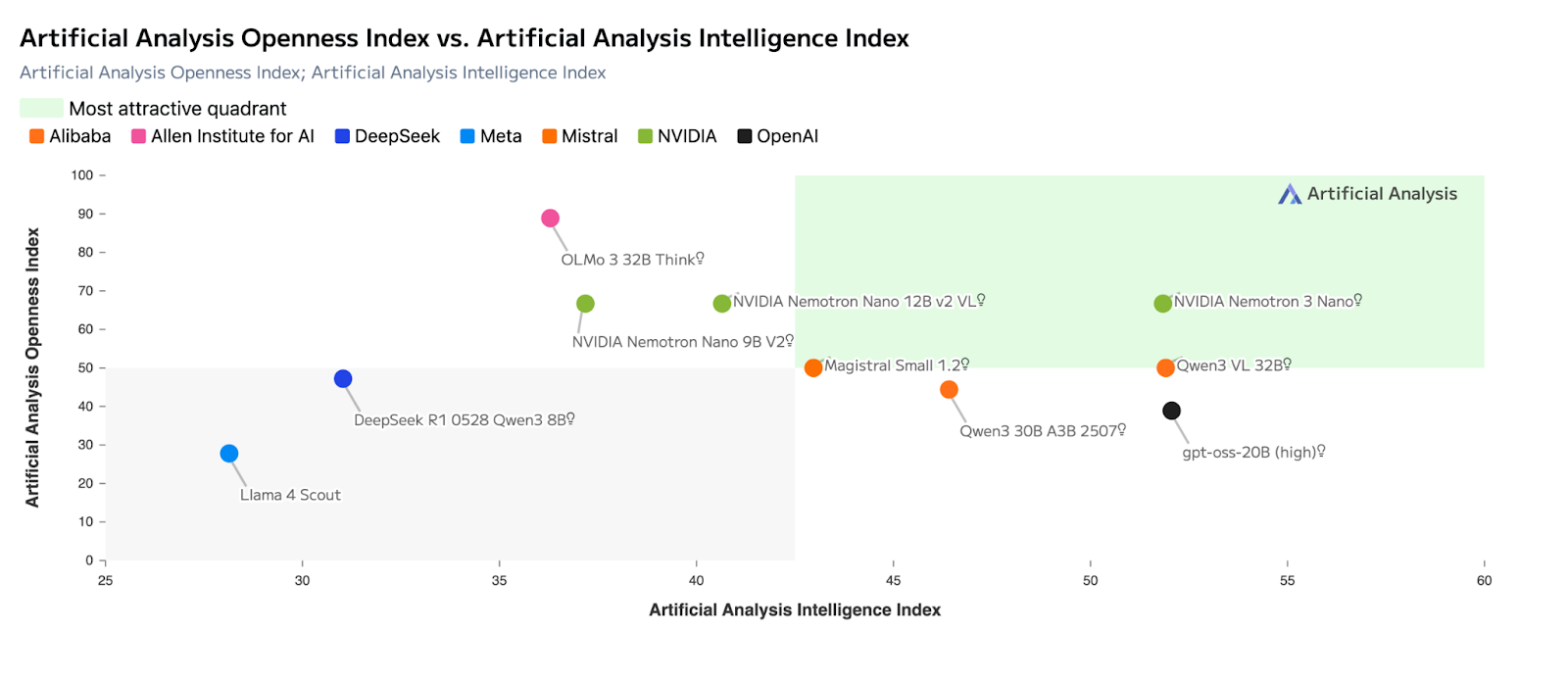
Mistral Large 3 et Nemotron 3 s'appuient tous deux sur architectures de mélange d'experts , mais ils optimisent pour des résultats différents.
Mistral Large 3 est conçu pour optimiser les capacités d'un modèle unique, avec des performances élevées en matière de raisonnement, de codage et de benchmarks à usage général tels que les évaluations de type LMArena et SWE. C'est souvent le choix le plus judicieux lorsqu'un modèle est censé gérer une tâche dans son intégralité, du début à la fin.
En revanche, Nemotron 3 est optimisé pour l'efficacité au niveau du système. Sa conception hybride MoE latente active moins de paramètres par jeton et privilégie le débit plutôt que la profondeur de raisonnement maximale. Cela le rend plus adapté aux rôles nécessitant une coordination importante, tels que le routage, la synthèse et le raisonnement intermédiaire, où de nombreux agents opèrent simultanément.
Une fois les objectifs de conception clairement définis, la question suivante est d'ordre pratique : comment pouvez-vous réellement utiliser Nemotron 3 aujourd'hui, et quelles options sont pertinentes compte tenu de votre configuration ? NVIDIA propose plusieurs modes d'accès, allant des API entièrement hébergées aux déploiements autogérés.
La manière la plus rapide de commencer est de recourir à des fournisseurs d'inférence hébergés. Nemotron 3 Nano est actuellement disponible sur des plateformes telles que Baseten, DeepInfra, Fireworks, FriendliAI, OpenRouteret Together AI. Ces services exposent des interfaces API standard, vous permettant de tester le comportement du modèle, son débit et sa gestion des contextes longs sans avoir à fournir de matériel.
Cette option est particulièrement adaptée pour le prototypage de flux de travail d'agents, l'évaluation comparative des performances ou l'intégration de Nemotron 3 dans des applications existantes avec une configuration minimale.
Les modèles Nemotron 3 sont également disponibles avec des poids ouverts sur Hugging Face, ce qui permet un contrôle total sur le déploiement. Cet itinéraire est destiné aux équipes qui souhaitent héberger elles-mêmes les modèles, les affiner à partir de données spécifiques à leur domaine ou les intégrer dans des pipelines d'agents personnalisés.
Avec les poids ouverts, vous pouvez :
Cette approche s'inscrit dans la droite ligne de l'importance accordée par NVIDIA à la transparence et à la propriété pour les systèmes d'agents durables et de qualité industrielle.
Pour les équipes qui souhaitent bénéficier d'une expérience d'auto-hébergement plus gérée, Nemotron 3 Nano est également disponible sous forme de microservice NVIDIA NIM. NIM intègre le modèle pour un déploiement sécurisé et évolutif sur une infrastructure accélérée par NVIDIA, que ce soit sur site ou dans le cloud.
À mesure que l'écosystème évolue, les modèles Nemotron devraient également s'intégrer aux cadres de déploiement et aux environnements d'exécution courants utilisés pour l'inférence locale et périphérique. Ces options facilitent l'expérimentation de Nemotron 3 dans des environnements contrôlés sans avoir à créer une pile de déploiement à partir de zéro.
Au moment de la sortie :
Concrètement, cela signifie que les développeurs peuvent commencer à expérimenter Nano immédiatement, tandis que les modèles plus importants sont destinés à des déploiements à un stade ultérieur qui nécessitent une plus grande capacité de raisonnement.
Nemotron 3 est performant dans le cadre de son utilisation prévue. Sa principale contribution ne consiste pas à repousser les limites du raisonnement à modèle unique, mais à rendre les systèmes basés sur des agents plus pratiques à déployer et à mettre à l'échelle.
Les choix architecturaux se traduisent par de réels avantages opérationnels, en particulier pour les flux de travail qui reposent sur la collaboration de nombreux agents. Cela dit, si votre principale exigence est un raisonnement approfondi à partir d'un seul modèle ou une planification complexe à l'aide d'outils, les modèles propriétaires de pointe ont toujours tendance à être plus cohérents.
Vu sous le bon angle, Nemotron 3 complète ces modèles plutôt que de les remplacer.
Nemotron 3 convient particulièrement aux scénarios où l'efficacité, la transparence et l'évolutivité sont importantes.
Les modèles étant ouverts et conçus pour fonctionner ensemble, les équipes peuvent attribuer différents rôles à différentes tailles de modèles plutôt que de s'appuyer sur un système unique et monolithique.
L'accent mis par NVIDIA sur l'efficacité, l'ouverture et la conception au niveau du système reflète la manière dont de nombreuses applications d'IA sont actuellement développées dans le monde réel.
Pour construire efficacement avec des modèles tels que Nemotron 3, il est utile de comprendre à la fois les principes fondamentaux du LLM et l'intégration des systèmes.
Notre cours sur les concepts des grands modèles linguistiques (LLM) fournit les bases théoriques, tandis que notre cursus de compétences « Création d'API en Python » couvre l'aspect pratique de l'intégration des modèles dans les applications.
Considéré comme faisant partie d'un système plus vaste, Nemotron 3 apparaît moins comme une version modèle que comme une base pour la manière dont l'IA basée sur des agents est déployée aujourd'hui.
Apprenez avec DataCamp
Cours
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Samuel Shaibu

