Curso
Introdução à Engenharia de Dados
4 h
127.6K
A manutenção de um servidor físico ou virtual não é pouca coisa, seja devido aos altos custos de manutenção ou à necessidade de mão de obra qualificada. A computação sem servidor resolve esses problemas fornecendo uma maneira econômica de permitir que os desenvolvedores criem e executem aplicativos na nuvem.
Neste artigo, analisaremos a computação sem servidor, seus aplicativos e seus benefícios para desenvolvedores e empresas. Esse é um tópico importante, pois o tamanho do mercado de computação sem servidor ultrapassou US$ 9 milhões em 2022 e a projeção é de que cresça mais 25% nos próximos dez anos. Vamos direto ao assunto.
Digamos que a luz e a água que você usa em sua casa sejam cobradas com base no seu uso, em vez de uma taxa mensal fixa estimada. É assim que a computação sem servidor funciona: É apenas uma forma de os provedores de nuvem alocarem sua infraestrutura para que você crie e execute seus aplicativos com base no uso, sem se preocupar com a manutenção do servidor.
Diferentemente da computação em nuvem tradicional, em que um servidor físico ou virtualizado, armazenamento e equipamento de rede são configurados, na computação sem servidor, o provedor de nuvem gerencia a infraestrutura e aloca automaticamente recursos para você à medida que seu aplicativo é dimensionado. Em outras palavras, a computação sem servidor é a abstração do servidor dos desenvolvedores, permitindo que eles se concentrem mais nos aplicativos que estão criando, em vez de se preocuparem com a infraestrutura na qual o aplicativo está hospedado.
Imagine que você está acostumado a ter de 100 a 200 usuários diariamente em seu aplicativo. Se no dia seguinte seus usuários aumentarem repentinamente para 1.000.000, o servidor dimensionará automaticamente seus recursos para atender a essa demanda. Isso não é viável com a computação em nuvem tradicional, pois os servidores sofrerão tempo de inatividade devido ao aumento do tráfego e, se o servidor tiver pouco armazenamento, será necessário comprar um armazenamento maior, o que leva tempo.
| Categoria | Computação sem servidor | Computação tradicional |
|---|---|---|
| Dimensionamento | Dinâmico | Fixo |
| Faturamento | Com base no uso | Os custos contínuos, independentemente do uso, também incluem custos operacionais e de manutenção |
| Gerenciamento de infraestrutura | Abstraído dos negócios | Requer gerenciamento ativo |
Antes de analisar os principais recursos que distinguem a computação sem servidor de outros modelos tradicionais de nuvem, vamos examinar as principais terminologias da computação sem servidor.
A execução orientada por eventos também é conhecida como FAAS (function-as-a-service, função como serviço), em que o aplicativo sem servidor é dividido em funções sem servidor independentes acionadas por eventos específicos de fontes como solicitações HTTP, alterações em um banco de dados, consultas de mensagens ou uploads de arquivos.
Suponha que você tenha um aplicativo sem servidor que processa automaticamente imagens sempre que elas são carregadas em um bucket do Amazon S3. Quando um usuário faz upload de um arquivo de imagem, uma função é acionada para processar a imagem e salvá-la em outro bucket do Amazon S3. Isso garante que a função seja executada somente quando necessário, tornando o sistema eficiente e econômico.
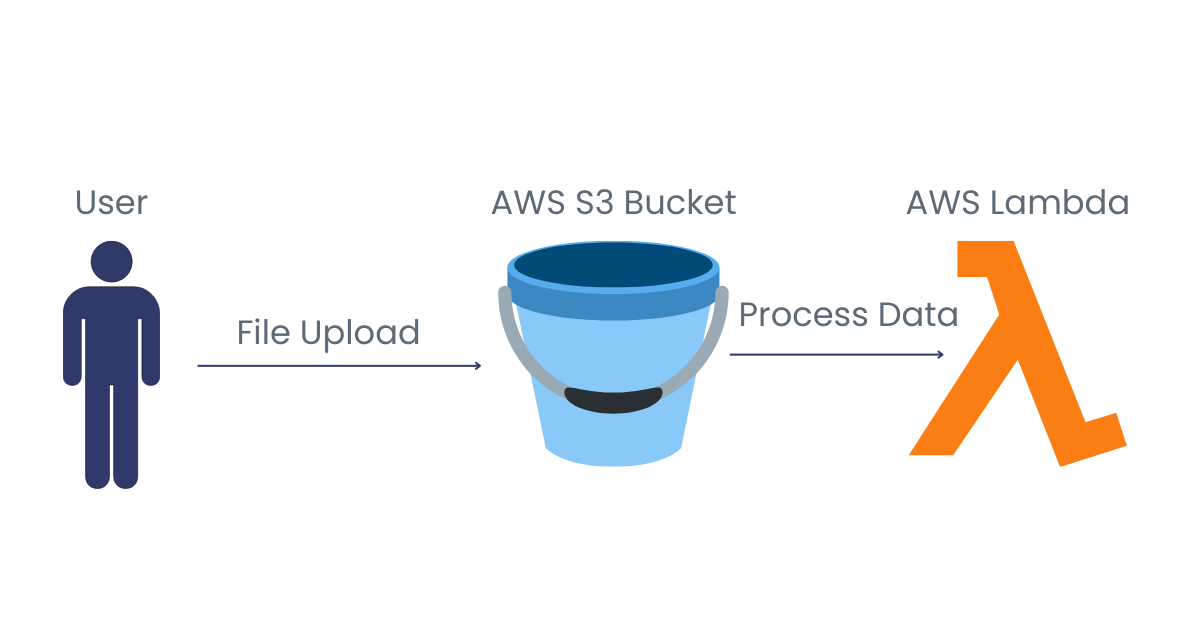
Execução orientada por eventos, usando o upload de arquivos como exemplo. Imagem do autor
Escalonamento automático é a alocação de recursos de computação com base na demanda ou no aumento das cargas de trabalho. Essa é uma característica fundamental da computação sem servidor que a torna eficiente e adaptável, garantindo que os recursos não sejam desperdiçados se não houver muita carga de trabalho ou demanda no servidor, e que não haja tempo de inatividade quando o servidor tiver alta demanda.
Por exemplo, seu aplicativo recebe um pico de tráfego. Em vez de sofrer tempo de inatividade em seu servidor devido ao alto tráfego, a plataforma fornece automaticamente instâncias adicionais para lidar com o aumento da carga de trabalho. Da mesma forma, a plataforma reduz os recursos para minimizar os custos quando o tráfego é baixo. Isso garante a eficiência sem intervenção manual, tornando o aplicativo econômico e responsivo em vários cenários.
As plataformas sem servidor cobram dos usuários com base nos recursos usados, e não nos recursos alocados. Ao contrário dos modelos tradicionais de nuvem, em que você pode não usar todos os recursos alocados, nas plataformas sem servidor, você paga apenas pelo tempo de computação usado. Os custos também são medidos, o que significa que você paga por invocação ou duração da execução da função, garantindo que você seja cobrado exatamente pelos recursos que utiliza.
Se, por exemplo, seu aplicativo processar 100 imagens de usuários em um determinado mês, em vez de pagar pelo uso do servidor 24 horas por dia, 7 dias por semana, você pagará apenas pelo tempo de computação usado para as 100 imagens processadas.
Esse também é um recurso fundamental da computação sem servidor, em que os desenvolvedores e as empresas não precisam se preocupar com o provisionamento, o dimensionamento e a manutenção dos servidores. Isso permite que eles se concentrem nos principais problemas de negócios e deixem a manutenção do servidor para os provedores de nuvem.
As plataformas sem servidor podem executar várias funções simultaneamente. Isso o torna rápido e eficiente em comparação com as abordagens tradicionais. Se os usuários quiserem fazer upload de imagens em sua plataforma e o provedor sem servidor fornecer um limite de simultaneidade padrão de 100, todas as solicitações além do limite de simultaneidade serão colocadas em fila e executadas na próxima execução da função.
Ao contrário da computação em nuvem tradicional, que exige servidores dedicados e incorre em custos sempre que o servidor está ocioso, as plataformas sem servidor usam um modelo baseado em eventos para cobrar dos desenvolvedores. Uma analogia útil é usar um serviço de táxi em vez de ter um carro. Com um táxi, você não precisa se preocupar com as despesas gastas com ele, como taxa de estacionamento, combustível e assim por diante; você paga apenas pela distância percorrida. Na computação sem servidor, assim como no táxi, você só paga pelos recursos de computação que usar. Diferentemente da abordagem tradicional (possuir um carro), você é responsável por cada recurso de computação que usa, mesmo quando o sistema está ocioso.
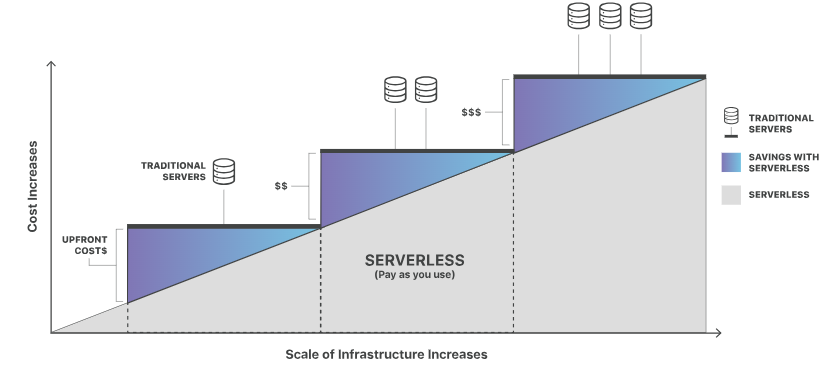
Comparação da eficiência de custo entre os tipos de servidores. Fonte: Cloudflare
A computação sem servidor economiza muito tempo porque os desenvolvedores não precisam dedicar seu tempo à instalação e manutenção de servidores; eles se concentram mais na criação do aplicativo. Como os aplicativos são criados como funções de nuvem independentes, é possível atualizar uma função sem interromper as outras ou o aplicativo inteiro.
Esse é um dos benefícios mais importantes de uma plataforma sem servidor e o motivo pelo qual ela é popular entre organizações menores e startups. As plataformas sem servidor facilitam para os desenvolvedores dimensionar suas operações automaticamente quando a demanda aumenta. Para funções que sofrem flutuações de solicitações, as plataformas sem servidor são dimensionadas para atender a essas solicitações aumentando ou diminuindo a alocação de recursos, garantindo assim que os recursos de computação sejam otimizados.
Com aplicativos sem servidor, você pode lançar aplicativos rapidamente e obter feedback imediato do usuário. Isso é importante para as startups, pois reduz o tempo gasto e a mão de obra necessária para criar aplicativos.
Ao contrário dos aplicativos hospedados em servidores dedicados, você pode executar aplicativos sem servidor de qualquer lugar. Isso melhora o desempenho dos aplicativos e reduz a latência em comparação com a computação em nuvem tradicional.
A arquitetura sem servidor é uma forma de criar aplicativos sem instalar e gerenciar a infraestrutura que hospeda o aplicativo. Os desenvolvedores podem criar aplicativos sem servidor usando um dos dois modelos sem servidor; usando Backend as a Service (BaaS) ou Function as a Service (FaaS).
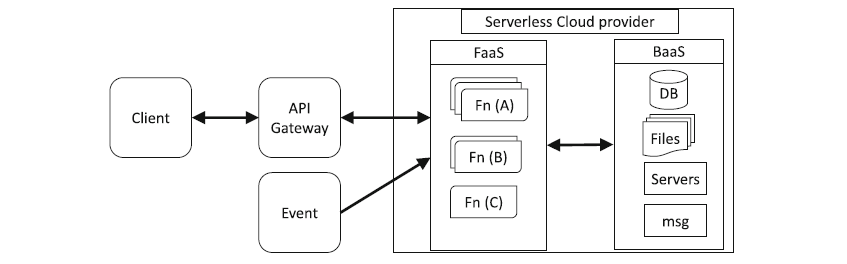
Arquiteturas de nuvem sem servidor FAAS e BAAS. Fonte: Jornal de computação em nuvem
O principal objetivo da arquitetura sem servidor é abstrair o gerenciamento do servidor dos desenvolvedores. Aqui está um detalhamento de como as plataformas sem servidor operam em sua infraestrutura.
Você pode se perguntar: A arquitetura sem servidor não é o mesmo que a arquitetura de contêiner, já que ambas abstraem o servidor dos desenvolvedores? Isso é verdade, mas, diferentemente das funções sem servidor, que abstraem completamente o servidor ao criar e enviar aplicativos em contêineres, quando um aplicativo tem alto tráfego, é necessário dimensionar os contêineres usando ferramentas como o Kubernetes. Isso anula o objetivo da FaaS, em que todas as ações relacionadas ao servidor são tratadas automaticamente pela plataforma sem servidor.
Em uma arquitetura de contêineres, você pode ter instâncias de contêineres que podem ser executadas por um longo período, o que pode gerar custos, ao contrário das funções sem servidor, em que você é cobrado pelo tempo que sua função gasta durante a execução. Para aplicativos menores, o uso de uma arquitetura sem servidor facilita a dissociação em partes que as plataformas sem servidor podem executar como funções independentes.
Antes do advento do Google App Engine em 2008, a Zimki oferecia a primeira plataforma "pay as you go" para execução de código, mas foi fechada posteriormente. Em seu estágio inicial, o Google App Engine suportava apenas Python e oferecia faturamento medido para aplicativos, entre eles o SnapChat. Por volta de 2010, outra plataforma chamada PiCloud também forneceu suporte FaaS para aplicativos Python.
Em 2014, a AWS popularizou o modelo sem servidor, lançando ferramentas como o AWS Serverless Application Model (AWS SAM) e o Amazon CloudWatch. Em seguida, o Google lançou sua segunda oferta sem servidor, o Google Cloud functions, juntamente com o Azure functions, em 2016. Desde então, várias plataformas sem servidor foram lançadas, como Function Compute, da Ali Baba Cloud, e IBM Cloud Functions, da IBM Cloud.
Para eliminar a necessidade de um banco de dados virtualizado ou físico, também foram desenvolvidos bancos de dados sem servidor. A AWS oferece o Amazon Aurora, uma versão sem servidor baseada no MySQL e no PostgreSQL. O Azure oferece o Azure Data Lake, e o Google fornece o Firestore.

Plataformas de nuvem sem servidor. Fonte: Entrevista de rede
A computação sem servidor é usada para criar aplicativos de site e APIs REST. A parte interessante é que os aplicativos são criados usando uma infraestrutura sem servidor em escala automática com base nas demandas do usuário, melhorando a experiência do usuário.
A arquitetura sem servidor facilita o processamento de mídia. Os usuários podem fazer upload de conteúdo de mídia de vários dispositivos e tamanhos, e a plataforma processa uma única função que atende à demanda de cada usuário sem reduzir o desempenho do aplicativo. Por exemplo, um usuário pode fazer upload de uma imagem por meio de um bucket S3 que aciona uma função AWS Lambda para adicionar uma marca d'água ou uma miniatura à imagem.
Os desenvolvedores podem implementar um chatbot para responder às perguntas dos clientes usando a arquitetura sem servidor e pagar apenas pelos recursos que o chatbot usa. Por exemplo, o Slack usa a arquitetura sem servidor para lidar com as solicitações variáveis de bots para evitar a subutilização da largura de banda devido à flutuação diária das necessidades dos clientes.
Você pode usar uma plataforma sem servidor para interagir com fornecedores de SaaS por meio de um endpoint HTTP de webhook, que recebe notificações e executa tarefas. Isso oferece manutenção mínima, baixos custos e dimensionamento automático para o webhook incorporado.
A Coca-Cola usa arquiteturas sem servidor em sua máquina de venda automática Freestyle para permitir que os clientes façam pedidos, paguem e recebam notificações de pagamento de suas bebidas. A Coca-Cola alegou que estava gastando cerca de US$ 13.000/ano para operar suas máquinas de venda automática, valor que foi reduzido para US$ 4.500/ano após a implementação de arquiteturas sem servidor nas máquinas de venda automática.
A Major League Baseball Advanced Media criou seu produto Statcast com arquitetura sem servidor para fornecer aos usuários métricas esportivas precisas e em tempo real. Ele usa computação sem servidor para processar dados e fornecer aos usuários insights sobre jogos de beisebol.
A arquitetura sem servidor é usada para aplicativos orientados por eventos, de modo que, quando um evento ou um estado é alterado, ele aciona um serviço. Você pode usar plataformas sem servidor para observar as alterações em um banco de dados e comparar as alterações com os padrões de qualidade.
Devido ao deslocamento de longa distância dos dados, os aplicativos levam tempo para processar solicitações e fornecer conteúdo de servidores centralizados, o que introduz problemas de latência e gargalo.
A computação de borda sem servidor resolve esse problema distribuindo recursos de computação em vários locais para reduzir a carga de trabalho no servidor central. A computação de borda sem servidor é o local dos recursos de computação que executam funções sem servidor mais próximas dos usuários finais (borda). Isso permite que o aplicativo sem servidor opere em mais dispositivos, diminua o congestionamento e reduza a latência.
Na computação de borda sem servidor, a infraestrutura é dedicada a cada dispositivo, permitindo que ele execute tarefas complexas sem enviar dados de volta ao local central para processamento. Aqui estão alguns casos de uso que otimizam a experiência do usuário usando funções de borda sem servidor:
Apesar dos benefícios trazidos pela computação sem servidor, ela enfrenta algumas das seguintes desvantagens.
Para empresas interessadas em criar aplicativos leves, a computação sem servidor é o caminho a seguir. Para aplicativos compostos por um grande número de serviços com interações complexas, recomenda-se uma infraestrutura híbrida composta por máquinas virtuais para processos grandes; nesse caso, os contêineres sem servidor são usados apenas para tarefas curtas. As funções de borda sem servidor também podem ser consideradas porque minimizam a latência ao processar dados localmente sem colocar muita carga de trabalho no servidor central.
Lembre-se de que vários avanços e desenvolvimentos ainda estão sendo feitos para expandir os recursos da computação sem servidor. Por exemplo, uma abordagem de várias nuvens pode ser usada para criar aplicativos sem servidor, em que é possível criar um aplicativo sem servidor usando serviços de mais de um provedor de nuvem. Também foram feitos mais desenvolvimentos para garantir a inicialização a frio zero de funções sem servidor, conforme implementado no Cloudflare Workers.
Obrigado por você estar sintonizado. Para saber mais sobre a computação sem servidor e desenvolver suas habilidades na área, confira os seguintes recursos do DataCamp:
Para uma leitura mais curta, confira nossa publicação no blog com ideias de projetos para todos os níveis de habilidade.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Joleen Bothma
7 min
blog
Moez Ali
11 min
blog
Abid Ali Awan
5 min
blog
Matt Crabtree
9 min


