
Course
Introduction to Data Engineering
4 hr
127.6K
Maintaining a physical or virtual server is no small feat, whether due to the high maintenance costs or the need for skilled manpower. Serverless computing solves these problems by providing a budget-friendly way of allowing developers to build and run applications on the cloud.
In this article, we will review serverless computing, its applications, and its benefits to developers and businesses. This is an important topic because the market size for serverless computing exceeded $9 million in 2022 and is projected to expand another 25% in the next ten years. Let's jump right in.
Let’s say the light and water you use in your house are charged based on your usage instead of a fixed estimated monthly fee. This is how serverless computing works: It is just a way cloud providers allocate their infrastructure for you to build and run your applications based on usage without worrying about server maintenance.
Unlike traditional cloud computing, where a physical or virtualized server, storage, and networking equipment are set up, in serverless computing, the cloud provider manages the infrastructure and automatically allocates resources to you as your application scales. In other words, serverless computing is the abstraction of the server from developers, allowing them to focus more on the applications they are building instead of worrying about the infrastructure the application is hosted on.
Imagine you are used to having 100 to 200 users daily on your application. If the next day your users suddenly increase to 1,000,000, the server will automatically scale your resources to meet that demand. This is not feasible with traditional cloud computing as the servers will experience downtime due to increased traffic, and if the server has low storage, larger storage has to be purchased, which takes time.
| Category | Serverless Computing | Traditional Computing |
|---|---|---|
| Scaling | Dynamic | Fixed |
| Billing | Based on usage | Ongoing costs, regardless of usage, also include maintenance and operational costs |
| Infrastructure management | Abstracted from businesses | Requires active management |
Before looking at key features that distinguish serverless computing from other traditional cloud models, let’s look at the key terminologies in serverless computing.
Event-driven execution is also known as function-as-a-service (FAAS), where the serverless application is divided into independent serverless functions triggered by specific events from sources such as HTTP requests, changes in a database, message queries, or file uploads.
Suppose you have a serverless application that automatically processes images whenever they are uploaded to an Amazon S3 bucket. When a user uploads an image file, a function is triggered to process the image and save it in another Amazon S3 bucket. This ensures the function runs only when needed, making the system efficient and cost-effective.
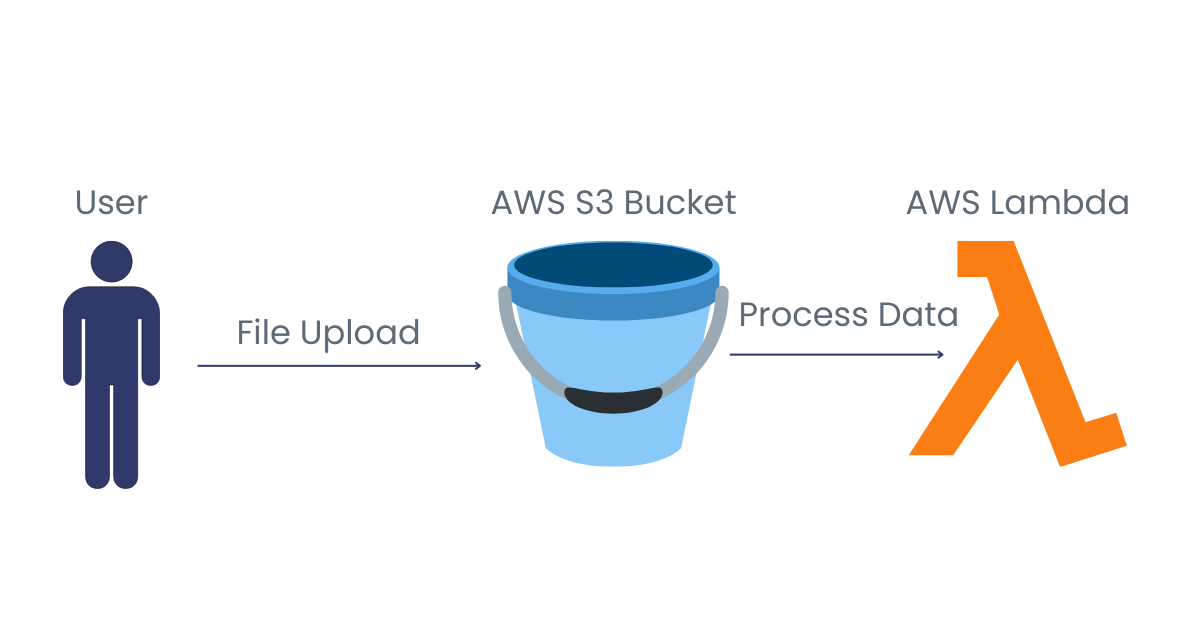
Event-driven execution, using file upload as an example. Image by Author
Auto-scaling is the allocation of computing resources based on demand or increase in workloads. It’s a key characteristic of serverless computing that makes it efficient and adaptable, ensuring resources are not wasted if there is not much workload or demand on the server, and downtime is not experienced when the server experiences high demand.
For example, your application gets a spike in traffic. Instead of experiencing downtime on your server due to the high traffic, the platform automatically provides additional instances to handle the increased workload. Likewise, the platform scales down resources to minimize costs when the traffic is low. This ensures efficiency without manual intervention, making the application cost-effective and responsive in various scenarios.
Serverless platforms charge users based on the resources used rather than the resources allocated. Unlike traditional cloud models where you might not use all of the allocated resources, in serverless platforms, you pay only for the compute time used. Costs are also metered, which means that you pay per invocation or duration of function execution, ensuring you are billed precisely for the resources you utilize.
If, for example, your application processes 100 images from users in a given month, instead of paying for 24/7 server usage, you pay only for the compute time used for the 100 processed images.
This is also a key feature of serverless computing where developers and businesses don’t have to worry about provisioning, scaling, and maintaining the servers. These allow them to focus on the core business problems and leave server maintenance to the cloud providers.
Serverless platforms can execute multiple functions simultaneously. This makes it fast and efficient when compared to traditional approaches. If users want to upload images on their platform and the serverless provider provides a default concurrency limit of 100, then any requests beyond the concurrency limit are queued and run in the next function execution.
Unlike traditional cloud computing, which requires dedicated servers and incurs costs whenever the server is idle, serverless platforms use an event-based model to charge developers. A useful analogy is using a taxi service instead of owning a car. With a taxi you don’t have to worry about the expenses spent on it such as parking fee, fuel and so on, you get to pay only for the distance you travel. In serverless computing, just like the taxi, you only pay for the computing resources you use. Unlike the traditional approach (owning a car), you are responsible for every computing resource you use, even when the system is idle.
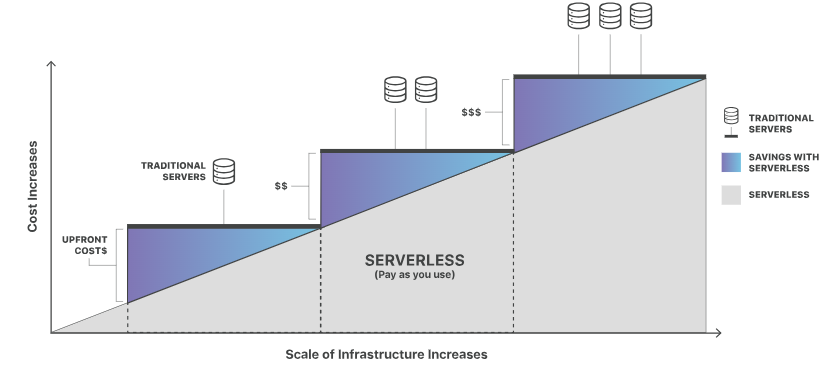
Cost efficiency comparison between server types. Source: Cloudflare
Much time is saved in serverless computing because developers don’t need to devote their time to installing and maintaining servers; they focus more on building the application. Since applications are built as independent cloud functions, one can update a function without disrupting others or the entire application.
This is one of the most important benefits of a serverless platform and why it is popular among smaller organizations and startups. Serverless platforms make it easy for developers to scale their operations automatically when demand increases. For functions that experience request fluctuations, serverless platforms scale to meet these requests by increasing or decreasing resource allocation, hence ensuring computing resources are optimized.
With serverless applications, you can release applications quickly and immediately get user feedback. This is important for startups as this reduces the time spent and the manpower needed to build applications.
Unlike applications hosted on dedicated servers, one can run serverless applications from anywhere. This improves application performance and reduces latency compared to traditional cloud computing.
Serverless architecture is a way of building applications without installing and managing the infrastructure hosting the application. Developers can build serverless applications using either of the two serverless models; either using Backend as a Service (BaaS) or Function as a Service (FaaS).
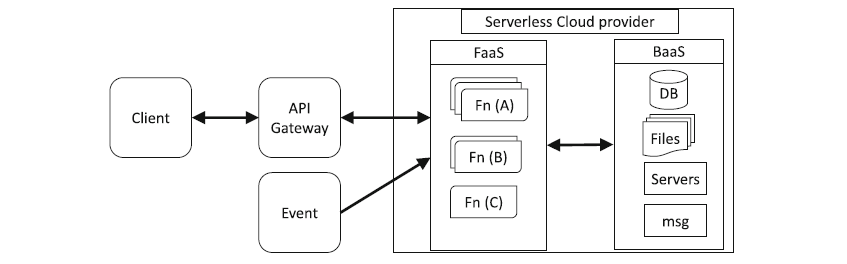
FAAS and BAAS serverless cloud architectures. Source: Journal of Cloud Computing
The main aim of serverless architecture is to abstract server management from developers. Here is a breakdown of how serverless platforms operate in their infrastructure.
One might wonder: Isn’t serverless architecture the same as container architecture since both abstract the server from the developers? This is true, but unlike serverless functions, which completely abstract the server when building and shipping applications in containers when an application experiences high traffic, one needs to scale the containers using tools like Kubernetes. This defeats the aim of FaaS, where all actions related to the server are handled automatically by the serverless platform.
In a container architecture, you can have container instances that can run for a long period which can incur costs, unlike in serverless functions where you are billed for the amount of time your function spends when running. For smaller applications, using a serverless architecture makes it easy to decouple it into parts that the serverless platforms can run as independent functions.
Before the advent of Google App Engine in 2008, Zimki offered the first “pay as you go” platform for code execution, but was later shut down. In its early stage, the Google App Engine could only support Python and featured metered billing for applications which among them was SnapChat. Around 2010, another platform called PiCloud also provided FaaS support for Python applications.
In 2014, AWS popularized the serverless model releasing tools such as AWS Serverless Application Model (AWS SAM), and Amazon CloudWatch. Google then released their second serverless offering Google Cloud functions alongside Azure functions in 2016. Since then various serverless platforms have been released such as Function Compute by Ali Baba Cloud and IBM Cloud Functions by IBM Cloud.
To eliminate the need for a virtualized or physical database, serverless databases have also been developed. AWS offers Amazon Aurora, a serverless version based on MySQL and PostgreSQL. Azure offers Azure Data Lake, and Google provides Firestore.

Serverless cloud platforms. Source: Network Interview
Serverless computing is used to build website applications and REST APIs. The interesting part is that applications are built using a serverless infrastructure auto-scale based on user demands, improving user experience.
Serverless architecture makes it easier to handle media processing. Users can upload media content from varying devices and sizes and the platform processes a single function that meets the demand of every user without reducing application performance. For example, a user can upload an image via an S3 bucket which triggers an AWS Lambda function to either add a watermark or thumbnail to the image.
Developers can implement a chatbot to respond to customer questions using serverless architecture and pay only for the resources the Chatbot uses. For example, Slack uses serverless architecture to handle the varying requests of bots to avoid underutilized bandwidth due to the everyday fluctuation of customer needs.
You can use a serverless platform to interact with SaaS vendors through a webhook HTTP endpoint, which receives notifications and performs tasks. This offers minimal maintenance, low costs, and automatic scaling for the built webhook.
Coca-Cola uses serverless architectures on their vending machine Freestyle to allow customers to order, pay, and receive payment notifications for their beverages. Coca-Cola claimed they were spending around $13,000/year to operate their vending machines, which was reduced to $4,500/year after implementing serverless architectures on the vending machines.
Major League Baseball Advanced Media built their product Statcast with serverless architecture to provide users with accurate and real-time sports metrics. It uses serverless computing to process data and give users insights about baseball games.
Serverless architecture is used for event-driven applications, such that when an event or a state is changed, it triggers a service. One can use serverless platforms to watch for changes to a database and compare the changes against quality standards.
Due to the long-distance travel of data, applications take time to process requests and deliver content from centralized servers, which introduces latency and bottleneck issues.
Serverless edge computing solves this issue by distributing computing resources to multiple locations to reduce the workload on the central server. Serverless edge computing is the location of computing resources that run serverless functions closer to end users (edge). This allows the serverless application to operate on more devices, decrease congestion, and lower latency.
In serverless edge computing, infrastructure is dedicated to each device, allowing it to perform complex tasks without sending data back to the central location for processing. Here are some use cases that optimize user experience using serverless edge functions:
Despite the benefits brought by serverless computing, it faces some of the following drawbacks.
For companies interested in building lightweight applications, serverless computing is the way forward. For applications made up of a large number of services with complex interactions, a hybrid infrastructure made up of virtual machines for large processes is recommended; in this case, the serverless containers are used only for short tasks. Serverless edge functions can also be considered because they minimize latency by processing data locally without putting much workload on the central server.
Keep in mind that various advancements and developments are still being made to expand the capabilities of serverless computing. For example, a multi-cloud approach can be used to build serverless applications, where one can build a serverless application using services from more than one cloud provider. More developments have also been made to ensure zero cold start of serverless functions, as implemented in Cloudflare Workers.
Thanks for tuning in. To learn more about serverless computing and build your skills in the field, check out the following DataCamp resources:
For shorter reading, check out our blog post for project ideas for all skill levels.
Learn with DataCamp
Course
Course
Course
blog
Alex Castrounis
13 min
blog
Maria Eugenia Inzaugarat
9 min
blog
Zoumana Keita
12 min
blog
Jana Barth
13 min
Tutorial
Bex Tuychiev
Tutorial
DataCamp Team
