
programa
Aprendizaje profundo en Python
18 h
Los algoritmos de optimización desempeñan un papel crucial en el aprendizaje profundo: afinan los pesos del modelo para minimizar las funciones de pérdida durante el entrenamiento. Uno de estos algoritmos es el optimizador Adam.
Adam se hizo extremadamente popular en el aprendizaje profundo debido a su capacidad para combinar las ventajas del impulso y los ritmos de aprendizaje adaptativos. Esto la hizo muy eficaz para entrenar redes neuronales profundas. También requiere un ajuste mínimo de los hiperparámetros, lo que la hace ampliamente accesible y eficaz en diversas tareas.
En 2017, Ilya Loshchilov y Frank Hutter introdujeron una versión más avanzada del popular algoritmo Adam en su artículo "Regularización por Decaimiento de Peso Desacoplado."Lo llamaron AdamW, que destaca por desacoplar el decaimiento del peso del proceso de actualización del gradiente. Esta separación es una mejora crucial respecto a Adam y ayuda a una mejor generalización del modelo.
AdamW es cada vez más importante en las aplicaciones modernas de aprendizaje profundo, sobre todo en el manejo de modelos a gran escala. Su capacidad superior para regular las actualizaciones de peso ha contribuido a su adopción en tareas que exigen alto rendimiento y estabilidad.
En este tutorial, vamos a tocar las diferencias clave entre Adam y AdamW, y los diferentes casos de uso, y vamos a realizar una guía paso a paso para implementar AdamW en PyTorch.
Adam y AdamW son optimizadores adaptativos muy utilizados en el aprendizaje profundo. La gran diferencia entre ellos es cómo gestionan la regularización del peso, lo que repercute en su eficacia en distintos escenarios.
Aunque Adam combina el impulso y los ritmos de aprendizaje adaptativos para ofrecer una optimización eficaz, incorpora la regularización L2 de un modo que puede entorpecer el rendimiento. AdamW aborda este problema desvinculando el decaimiento del peso de la actualización de la tasa de aprendizaje, proporcionando un enfoque más eficaz para modelos grandes y mejorando la generalización. El decaimiento del peso, una forma de regularización L2, penaliza los pesos grandes en el modelo. Adam incorpora el decaimiento del peso en el proceso de actualización del gradiente, mientras que AdamW lo aplica por separado después de la actualización del gradiente
Aquí tienes otras formas en las que difieren:
Aunque ambos optimizadores están diseñados para gestionar el impulso y ajustar los ritmos de aprendizaje dinámicamente, difieren fundamentalmente en su tratamiento del decaimiento del peso.
En Adam, el decaimiento del peso se aplica indirectamente como parte de la actualización del gradiente, lo que puede modificar involuntariamente la dinámica de aprendizaje e interferir en el proceso de optimización. AdamW, sin embargo, separa el decaimiento del peso del paso del gradiente, garantizando que la regularización afecte directamente a los parámetros sin alterar el mecanismo de aprendizaje adaptativo.
Este diseño conduce a una regularización más precisa, ayudando a que los modelos generalicen mejor, sobre todo en tareas que implican conjuntos de datos grandes y complejos. Como resultado, los dos optimizadores suelen tener casos de uso muy diferentes.
Adam rinde mejor en tareas en las que la regularización es menos crítica o cuando se prioriza la eficiencia computacional sobre la generalización. Algunos ejemplos son:
AdamW destaca en situaciones en las que el sobreajuste es un problema y el tamaño del modelo es considerable. Por ejemplo:
Pero, ¿por qué querría alguien utilizar AdamW en lugar de Adam? Sencillo. AdamW ofrece varias ventajas clave que mejoran su rendimiento, sobre todo en escenarios de modelado complejos.
Aborda algunas de las limitaciones encontradas en el optimizador Adam, haciéndolo así más eficaz en la optimización y contribuyendo a mejorar la formación del modelo y su robustez.
Éstas son algunas de las ventajas más destacadas:
La principal fuerza de AdamW reside en su enfoque de la disminución del peso, que está desvinculado de las actualizaciones de gradiente adaptativas típicas de Adam. Este ajuste garantiza que la regularización se aplique directamente a los pesos del modelo, mejorando la generalización sin afectar negativamente a la dinámica del ritmo de aprendizaje.
El optimizador se basa en la naturaleza adaptativa de Adam, manteniendo las ventajas del impulso y los ajustes de la tasa de aprendizaje por parámetro. Aplicar el decaimiento del peso de forma independiente resuelve uno de los principales defectos de Adam: su tendencia a afectar a las actualizaciones del gradiente durante la regularización. Esta separación permite a AdamW mantener un aprendizaje estable, incluso en modelos complejos y a gran escala, al tiempo que mantiene bajo control el sobreajuste.
En las secciones siguientes, exploraremos la teoría que subyace a la reducción de pesos y la regularización, así como las matemáticas que sustentan el proceso de optimización de AdamW.
La regularización L2 es una técnica utilizada para evitar el sobreajuste. Consigue este objetivo añadiendo un término de penalización a la función de pérdida, desalentando los valores de peso grandes. Esta técnica ayuda a crear modelos más sencillos que se generalizan mejor a los nuevos datos.
En los optimizadores tradicionales, como Adam, el decaimiento del peso se aplica como parte de la actualización del gradiente, lo que afecta inadvertidamente a los ritmos de aprendizaje y puede llevar a un rendimiento subóptimo.
AdamW mejora esto desacoplando la caída del peso del cálculo del gradiente. En otras palabras, en lugar de aplicar el decaimiento del peso durante la actualización del gradiente, AdamW lo trata como un paso aparte, aplicándolo directamente a los pesos después de la actualización del gradiente. Esto evita que el decaimiento del peso interfiera en el proceso de optimización, lo que conduce a un entrenamiento más estable y a una mejor generalización.
AdamW modifica el optimizador Adam tradicional cambiando el modo en que se aplica el decaimiento del peso. Las ecuaciones básicas de AdamW pueden representarse como sigue:
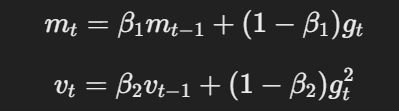
La ecuación para el impulso y la tasa de aprendizaje adaptativo
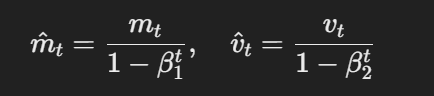
La fórmula para las estimaciones con corrección de sesgo
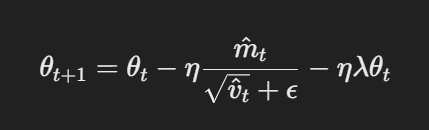
Actualización de parámetros con decaimiento de peso desacoplado
Aquí, η es la velocidad de aprendizaje, λ es el factor de decaimiento del peso y θt representa los parámetros. Este término de decaimiento del peso desacoplado λθt garantiza que la regularización se aplique independientemente de la actualización del gradiente, que es la diferencia clave con respecto a Adam.
Implementación de AdamW en PyTorch es sencillo; esta sección proporciona una guía completa para configurarlo. Sigue estos pasos para aprender a ajustar eficazmente los modelos con el Optimizador Adam.
Nota: este tutorial asume que ya tienes PyTorch instalado. Consulta la Documentación para cualquier orientación.
Paso 1: Importa las bibliotecas necesarias
import torch
import torch.nn as nn
import torch.optim as optim
Import torch.nn.functional as F
Paso 2: Definir el modelo
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8)
x = F.relu(self.fc1(x))
x = self.fc2(x)
Paso 3: Establece los hiperparámetros
learning_rate = 1e-4
weight_decay = 1e-2
num_epochs = 10 # number of epochsPaso 4: Inicializa el optimizador AdamW y configura la función de pérdida
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()¡Voilà!
Ahora ya estás preparado para empezar a entrenar tu modelo CNN, y eso es lo que haremos en la siguiente sección.
Anteriormente, definimos el modelo, establecimos los hiperparámetros, inicializamos el optimizador (AdamW) y establecimos la función de pérdida.
Para entrenar el modelo, necesitaremos importar algunos módulos más;
from torch.utils.data import DataLoader # provides an iterable of the dataset
import torchvision
import torchvision.transforms as transformsA continuación, define el conjunto de datos y los cargadores de datos. Para este ejemplo, utilizaremos el conjunto de datos CIFAR-10:
# Define transformations for the training set
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# Load CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)Como ya hemos definido nuestro modelo, el siguiente paso es implementar el bucle de entrenamiento para optimizar el modelo utilizando AdamW.
Así es como queda:
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad() # Clear gradients
outputs = model(inputs) # Forward pass
loss = criterion(outputs, labels) # Calculate loss
loss.backward() # Backward pass
optimizer.step() # Update weights
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')El último paso consiste en validar el rendimiento del modelo en el conjunto de datos de validación que creamos anteriormente.
Aquí tienes el código:
model.eval() # Set the model to evaluation mode
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs) # Forward pass
_, predicted = torch.max(outputs.data, 1) # Get predicted class
total += labels.size(0) # Update total samples
correct += (predicted == labels).sum().item() # Update correct predictions
accuracy = 100 * correct / total
print(f'Validation Accuracy: {accuracy:.2f}%')Y ahí lo tienes.
Ahora ya sabes cómo implementar AdamW en PyTorch.
Vale, ya hemos establecido que AdamW ganó popularidad debido a su gestión más eficaz de la pérdida de peso que su predecesor, Adam.
Pero, ¿cuáles son algunos casos de uso común de este optimizador?
Entraremos en ello en esta sección...
AdamW es especialmente beneficioso para entrenar grandes modelos como BERT, GPT y otras arquitecturas de transformadores. Tales modelos suelen tener millones o incluso miles de millones de parámetros, lo que a menudo significa que exigen algoritmos de optimización eficientes que manejen complejas actualizaciones de pesos y retos de generalización.
AdamW se ha convertido en el optimizador preferido en tareas de visión por ordenador que implican CNNs y en tareas de PNL que implican transformadores. Su capacidad para evitar el sobreajuste lo hace ideal para tareas que impliquen grandes conjuntos de datos y arquitecturas complejas. El desacoplamiento del decaimiento del peso significa que AdamW evita los problemas que encuentra Adam al regularizar en exceso los modelos.
El ajuste de hiperparámetros es el proceso de seleccionar los mejores valores para los parámetros que rigen el entrenamiento de un modelo de aprendizaje automático, pero que no se aprenden de los propios datos. Estos parámetros influyen directamente en el modo en que el modelo optimiza y converge.
El ajuste adecuado de estos hiperparámetros en AdamW es esencial para conseguir un entrenamiento eficaz, evitar el sobreajuste y garantizar que el modelo generalice bien a los datos no vistos.
En esta sección, exploraremos cómo afinar los hiperparámetros clave de AdamW para obtener un rendimiento óptimo.
La tasa de aprendizaje es un hiperparámetro que controla cuánto ajustar los pesos del modelo con respecto al gradiente de pérdida durante cada paso de entrenamiento. Una tasa de aprendizaje más alta acelera el entrenamiento, pero puede hacer que el modelo sobrepase los pesos óptimos, mientras que una tasa más baja permite ajustes más precisos, pero puede hacer que el entrenamiento sea más lento o que se atasque en mínimos locales.
Por otra parte, el decaimiento del peso es una técnica de regularización que se utiliza para evitar el sobreajuste penalizando los pesos grandes en el modelo. En concreto, el decaimiento del peso añade una pequeña penalización proporcional al tamaño de los pesos del modelo durante el entrenamiento, lo que ayuda a reducir la complejidad del modelo y a mejorar la generalización a nuevos datos.
Elegir los ritmos de aprendizaje y los valores de decaimiento del peso óptimos para AdamW:
AdamW ha surgido como uno de los optimizadores más eficaces en el aprendizaje profundo, especialmente para modelos a gran escala. Esto se debe a su capacidad para desacoplar el decaimiento del peso de las actualizaciones del gradiente. En concreto, el diseño de AdamW mejora la regularización y ayuda a que los modelos generalicen mejor, sobre todo cuando se trata de arquitecturas complejas y conjuntos de datos extensos.
Como se demuestra en este tutorial, la implementación de AdamW en PyTorch es sencilla: sólo requiere algunos ajustes por parte de Adam. Sin embargo, el ajuste de los hiperparámetros sigue siendo un paso crucial para maximizar la eficacia de AdamW. Encontrar el equilibrio adecuado entre la velocidad de aprendizaje y el decaimiento del peso es esencial para garantizar que el optimizador funcione eficazmente sin sobreajustar ni infraajustar el modelo.
Ahora ya sabes lo suficiente para aplicar AdamW en tus propios modelos. Para seguir aprendiendo, consulta algunos de estos recursos:
Los mejores cursos de DataCamp
programa
Curso
Curso
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Tutorial
Bekhruz Tuychiev