
Programa
Aprendizagem profunda Em Python
18 h
Os algoritmos de otimização desempenham um papel fundamental na aprendizagem profunda: eles ajustam os pesos do modelo para minimizar as funções de perda durante o treinamento. Um desses algoritmos é o otimizador Adam.
O Adam se tornou extremamente popular na aprendizagem profunda devido à sua capacidade de combinar as vantagens das taxas de aprendizagem adaptativa e dinâmica. Isso o tornou altamente eficiente para o treinamento de redes neurais profundas. Ele também exige um ajuste mínimo dos hiperparâmetros, o que o torna amplamente acessível e eficaz em várias tarefas.
Em 2017, Ilya Loshchilov e Frank Hutter apresentaram uma versão mais avançada do popular algoritmo Adam em seu artigo "Regularização de decaimento de peso desacoplado."Eles o chamaram de AdamW, que se destaca por desacoplar o decaimento do peso do processo de atualização do gradiente. Essa separação é um aprimoramento crucial em relação ao Adam e ajuda a melhorar a generalização do modelo.
O AdamW tem se tornado cada vez mais importante nos aplicativos modernos de aprendizagem profunda, principalmente no manuseio de modelos de grande escala. Sua capacidade superior de regular as atualizações de peso contribuiu para sua adoção em tarefas que exigem alto desempenho e estabilidade.
Neste tutorial, abordaremos as principais diferenças entre o Adam e o AdamW, bem como os diferentes casos de uso, e implementaremos um guia passo a passo para implementar o AdamW no PyTorch.
O Adam e o AdamW são otimizadores adaptativos amplamente usados na aprendizagem profunda. A grande diferença entre eles é como lidam com a regularização de peso, o que afeta sua eficácia em diferentes cenários.
Embora o Adam combine momentum e taxas de aprendizado adaptáveis para oferecer uma otimização eficiente, ele incorpora a regularização L2 de uma forma que pode prejudicar o desempenho. O AdamW aborda essa questão desacoplando o decaimento do peso da atualização da taxa de aprendizado, fornecendo uma abordagem mais eficaz para modelos grandes e melhorando a generalização. O decaimento de peso, uma forma de regularização L2, penaliza pesos grandes no modelo. O Adam incorpora a redução de peso no processo de atualização do gradiente, enquanto o AdamW a aplica separadamente após a atualização do gradiente
Aqui estão algumas outras maneiras pelas quais eles diferem:
Embora ambos os otimizadores tenham sido projetados para gerenciar o momentum e ajustar as taxas de aprendizado dinamicamente, eles diferem fundamentalmente no tratamento da deterioração do peso.
Na Adam, a redução do peso é aplicada indiretamente como parte da atualização do gradiente, o que pode modificar involuntariamente a dinâmica do aprendizado e interferir no processo de otimização. O AdamW, no entanto, separa o decaimento do peso da etapa do gradiente, garantindo que a regularização afete diretamente os parâmetros sem alterar o mecanismo de aprendizagem adaptativa.
Esse design leva a uma regularização mais precisa, ajudando os modelos a se generalizarem melhor, principalmente em tarefas que envolvem conjuntos de dados grandes e complexos. Como resultado, os dois otimizadores geralmente têm casos de uso muito diferentes.
O Adam tem um desempenho melhor em tarefas em que a regularização é menos crítica ou quando a eficiência computacional é priorizada em relação à generalização. Os exemplos incluem:
O AdamW é excelente em cenários em que o excesso de ajuste é uma preocupação e o tamanho do modelo é substancial. Por exemplo:
Mas por que você gostaria de usar o AdamW em vez do Adam? Simples. O AdamW oferece vários benefícios importantes que melhoram seu desempenho, especialmente em cenários de modelagem complexos.
Ele aborda algumas das limitações encontradas no otimizador Adam, tornando-o mais eficaz na otimização e contribuindo para melhorar o treinamento e a robustez do modelo.
Aqui estão algumas das vantagens mais importantes:
O ponto forte do AdamW está em sua abordagem de redução de peso, que é desacoplada das atualizações de gradiente adaptativo típicas do Adam. Esse ajuste garante que a regularização seja aplicada diretamente aos pesos do modelo, melhorando a generalização sem afetar negativamente a dinâmica da taxa de aprendizado.
O otimizador se baseia na natureza adaptativa do Adam, mantendo os benefícios dos ajustes da taxa de aprendizado por parâmetro e por momento. A aplicação do decaimento de peso aborda independentemente uma das principais deficiências do Adam: sua tendência de afetar as atualizações de gradiente durante a regularização. Essa separação permite que o AdamW mantenha um aprendizado estável, mesmo em modelos complexos e de grande escala, ao mesmo tempo em que mantém o excesso de ajuste sob controle.
Nas seções a seguir, exploraremos a teoria por trás da redução e regularização do peso e a matemática que sustenta o processo de otimização do AdamW.
A regularização L2 é uma técnica usada para evitar o ajuste excessivo. Ele atinge esse objetivo adicionando um termo de penalidade à função de perda, desencorajando valores de peso grandes. Essa técnica ajuda a criar modelos mais simples que se generalizam melhor para novos dados.
Nos otimizadores tradicionais, como o Adam, a redução do peso é aplicada como parte da atualização do gradiente, o que afeta inadvertidamente as taxas de aprendizado e pode levar a um desempenho abaixo do ideal.
O AdamW aprimora isso ao desacoplar o decaimento do peso do cálculo do gradiente. Em outras palavras, em vez de aplicar o decaimento do peso durante a atualização do gradiente, o AdamW o trata como uma etapa separada, aplicando-o diretamente aos pesos após a atualização do gradiente. Isso evita que a deterioração do peso interfira no processo de otimização, levando a um treinamento mais estável e a uma melhor generalização.
O AdamW modifica o otimizador Adam tradicional, alterando a forma como a redução de peso é aplicada. As principais equações do AdamW podem ser representadas da seguinte forma:
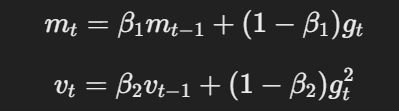
A equação para o momento e a taxa de aprendizagem adaptativa
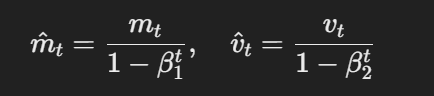
A fórmula para estimativas com correção de viés
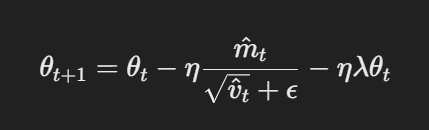
Atualização de parâmetros com decaimento de peso desacoplado
Aqui, η é a taxa de aprendizado, λ é o fator de decaimento do peso e θt representa os parâmetros. Esse termo de decaimento de peso desacoplado λθt garante que a regularização seja aplicada independentemente da atualização do gradiente, que é a principal diferença em relação ao Adam.
Implementação do AdamW no PyTorch é simples; esta seção fornece um guia abrangente para configurá-lo. Siga estas etapas para saber como fazer o ajuste fino dos modelos de forma eficaz com o Adam Optimizer.
Observação: este tutorial pressupõe que você já tenha o PyTorch instalado. Consulte a Documentação para obter orientação.
Etapa 1: Importar as bibliotecas necessárias
import torch
import torch.nn as nn
import torch.optim as optim
Import torch.nn.functional as F
Etapa 2: Definir o modelo
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8)
x = F.relu(self.fc1(x))
x = self.fc2(x)
Etapa 3: Definir os hiperparâmetros
learning_rate = 1e-4
weight_decay = 1e-2
num_epochs = 10 # number of epochsEtapa 4: Inicialize o otimizador AdamW e configure a função de perda
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()Voila!
Agora, você está pronto para começar a treinar o modelo CNN, e é isso que faremos na próxima seção.
Acima, definimos o modelo, definimos os hiperparâmetros, inicializamos o otimizador (AdamW) e configuramos a função de perda.
Para treinar o modelo, precisaremos importar mais alguns módulos;
from torch.utils.data import DataLoader # provides an iterable of the dataset
import torchvision
import torchvision.transforms as transformsEm seguida, defina o conjunto de dados e os carregadores de dados. Para este exemplo, usaremos o conjunto de dados CIFAR-10:
# Define transformations for the training set
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# Load CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)Como já definimos nosso modelo, a próxima etapa é implementar o loop de treinamento para otimizar o modelo usando o AdamW.
Aqui está a aparência:
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad() # Clear gradients
outputs = model(inputs) # Forward pass
loss = criterion(outputs, labels) # Calculate loss
loss.backward() # Backward pass
optimizer.step() # Update weights
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')A última etapa é validar o desempenho do modelo no conjunto de dados de validação que criamos anteriormente.
Aqui está o código:
model.eval() # Set the model to evaluation mode
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs) # Forward pass
_, predicted = torch.max(outputs.data, 1) # Get predicted class
total += labels.size(0) # Update total samples
correct += (predicted == labels).sum().item() # Update correct predictions
accuracy = 100 * correct / total
print(f'Validation Accuracy: {accuracy:.2f}%')E aí está o que você precisa.
Agora você sabe como implementar o AdamW no PyTorch.
Ok, então estabelecemos que o AdamW ganhou popularidade devido ao seu gerenciamento mais eficaz da perda de peso do que seu antecessor, o Adam.
Mas quais são alguns casos de uso comuns para esse otimizador?
Vamos falar sobre isso nesta seção...
O AdamW é particularmente útil no treinamento de modelos grandes, como BERT, GPT e outras arquiteturas de transformadores. Esses modelos normalmente têm milhões ou até bilhões de parâmetros, o que geralmente significa que eles exigem algoritmos de otimização eficientes que lidem com atualizações de peso complexas e desafios de generalização.
O AdamW tornou-se o otimizador preferido em tarefas de visão computacional que envolvem CNNs e tarefas de PNL que envolvem transformadores. Sua capacidade de evitar o ajuste excessivo o torna ideal para tarefas que envolvem grandes conjuntos de dados e arquiteturas complexas. O desacoplamento do decaimento do peso significa que o AdamW evita os problemas encontrados pelo Adam em modelos com excesso de regularização.
O ajuste de hiperparâmetros é o processo de seleção dos melhores valores para os parâmetros que regem o treinamento de um modelo de aprendizado de máquina, mas que não são aprendidos com os próprios dados. Esses parâmetros influenciam diretamente a forma como o modelo é otimizado e converge.
O ajuste adequado desses hiperparâmetros no AdamW é essencial para obter um treinamento eficiente, evitar o ajuste excessivo e garantir que o modelo seja bem generalizado para dados não vistos.
Nesta seção, exploraremos como fazer o ajuste fino dos principais hiperparâmetros do AdamW para obter o melhor desempenho.
A taxa de aprendizado é um hiperparâmetro que controla o quanto ajustar os pesos do modelo em relação ao gradiente de perda durante cada etapa de treinamento. Uma taxa de aprendizado mais alta acelera o treinamento, mas pode fazer com que o modelo ultrapasse os pesos ideais, enquanto uma taxa mais baixa permite ajustes mais finos, mas pode tornar o treinamento mais lento ou ficar preso em mínimos locais.
A redução de peso, por outro lado, é uma técnica de regularização usada para evitar o ajuste excessivo, penalizando pesos grandes no modelo. Ou seja, o decaimento de peso adiciona uma pequena penalidade proporcional ao tamanho dos pesos do modelo durante o treinamento, ajudando a reduzir a complexidade do modelo e a melhorar a generalização para novos dados.
Para escolher as taxas de aprendizado ideais e os valores de decaimento de peso para o AdamW:
O AdamW surgiu como um dos otimizadores mais eficazes na aprendizagem profunda, especialmente para modelos de grande escala. Isso se deve à sua capacidade de desacoplar a redução de peso das atualizações de gradiente. Ou seja, o design do AdamW melhora a regularização e ajuda os modelos a se generalizarem melhor, principalmente ao lidar com arquiteturas complexas e conjuntos de dados extensos.
Conforme demonstrado neste tutorial, a implementação do AdamW no PyTorch é simples - requer apenas alguns ajustes do Adam. No entanto, o ajuste de hiperparâmetros continua sendo uma etapa crucial para maximizar a eficácia do AdamW. Encontrar o equilíbrio certo entre a taxa de aprendizado e o decaimento do peso é essencial para garantir que o otimizador funcione de forma eficiente, sem que o modelo seja superajustado ou subajustado.
Agora você sabe o suficiente para implementar o AdamW em seus próprios modelos. Para continuar seu aprendizado, confira alguns desses recursos:
Principais cursos da DataCamp
Programa
Curso
Curso
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
