Capacidades de Torchat
Torchchat ofrece cuatro funcionalidades principales:
- Ejecutar LLMs utilizando Python con PyTorch.
- Operar modelos autónomos en una aplicación de escritorio o servidor sin Python.
- Ejecutar modelos en un dispositivo móvil.
- Evaluar el rendimiento de un modelo.
Ejecuta LLMs usando Python con PyTorch
Este modo permite ejecutar un LLM en una máquina que tenga Python y PyTorch instalados. Podemos interactuar con el modelo directamente en el terminal o configurando un servidor con una API REST. En este artículo nos centraremos en la configuración.
Modelos autónomos operativos
Torchchat utiliza AOT Inductor (Ahead-of-Time Inductor) para crear un ejecutable autocontenido y distribuible para los programas de inferencia de PyTorch, concretamente en forma de biblioteca dinámica sin dependencia de Python y PyTorch.
Este enfoque responde a la necesidad de desplegar modelos en un entorno de producción en el que se requiere estabilidad en el tiempo de ejecución del modelo frente a actualizaciones y cambios en el entorno de servicio, garantizando que los modelos sigan siendo operativos sin necesidad de recompilación.
AOT Inductor se centra en optimizar el despliegue de modelos, permitiendo formatos de distribución eficientes y binarios, rápidos de cargar y listos para ejecutar, abordando las limitaciones y la sobrecarga asociadas a formatos de texto como TorchScript. Aprovecha las técnicas de generación y optimización de código para el rendimiento tanto de la CPU como de la GPU, con el objetivo de reducir la sobrecarga y mejorar la velocidad de ejecución.
Ejecutar en dispositivos móviles
Para la ejecución en dispositivos móviles, Torchchat aprovecha ExecuTorch. Al igual que AOT Inductor, ExecuTorch optimiza el modelo para su ejecución en un dispositivo móvil o integrado. Produce un artefacto PTE que pueda utilizarse posteriormente para ejecutar el modelo.
Evaluar un modelo
El modo de evaluación de Torchchat puede utilizarse para evaluar el rendimiento de un LLM en varias tareas disponibles en lm_eval. Se trata de una característica importante para las personas que investigan y desean evaluar sus nuevos modelos en puntos de referencia de uso común.
Por qué usar Torchat
Ejecutar un LLM localmente en lugar de depender de una API en la nube de terceros, como la API de Open AI presenta una variedad de casos de uso y ventajas, que se adaptan a diferentes necesidades y escenarios.
- Aplicaciones sensibles a la privacidad: Para los sectores que manejan datos sensibles, como el sanitario, el financiero y el jurídico, ejecutar los LLM localmente garantiza que la información confidencial no salga de la infraestructura de la organización, cumpliendo la normativa de protección de datos.
- Aplicaciones en tiempo real: Las aplicaciones que requieren respuestas de baja latencia, como los chatbots interactivos, la generación de contenidos en tiempo real y los sistemas de monitorización en directo, pueden beneficiarse de ejecutar los LLM localmente, eliminando la latencia introducida por la transmisión de red hacia y desde una API en la nube.
- Escenarios sin conexión o de baja conectividad: En entornos con poca o ninguna conexión a Internet, el despliegue local permite el uso de aplicaciones LLM, como la investigación de campo, la educación a distancia y los sistemas de entretenimiento en vuelo.
- Control y optimización de costes: Para casos de gran volumen o de uso continuo, la implantación local puede ser más rentable, evitando los modelos de precios por petición de las API en la nube y aprovechando potencialmente los recursos informáticos existentes.
Si te interesa saber más sobre cómo ejecutar un modelo de IA localmente en un dispositivo en lugar de en la nube, te recomiendo esta entrada del blog sobre IA Edge.
Configuración local con Python
Vamos a configurar Torchchat localmente paso a paso. Empezaremos clonando el repositorio Torcchat.
Clona o descarga el código
El primer paso para configurar Torchchat localmente es clonar el repositorio de Torchat. Tener Git instalado, podemos clonar el repositorio abriendo un terminal y ejecutando el comando
git clone git@github.com:pytorch/torchchat.gitAlternativamente, podemos descargar el repositorio utilizando la interfaz de Github.
Instalación
Vamos a suponer que Python 3.10 ya está instalado. Para obtener una guía sobre cómo instalar Python, consulta este artículo.
Para instalar Torchat, abre un terminal en la carpeta Torchat. Empezamos creando un entorno virtual:
python -m venv .venvEn pocas palabras, un entorno virtual es un directorio autónomo para un proyecto, que contiene sus directorios de instalación de bibliotecas Python, paquetes y, a veces, incluso una versión específica del propio Python. Esto garantiza que cada proyecto tenga exactamente las versiones del software que necesita para funcionar, sin interferencias de otros proyectos y sus requisitos.
Con el entorno virtual creado, tenemos que activarlo. Podemos hacerlo con el comando
source .venv/bin/activatePor último, tenemos que configurar el entorno instalando todas las dependencias necesarias para que funcione Torchchat. Torchchat proporciona un script de instalación, install_requirements.sh, que podemos ejecutar con el comando:
./install_requirements.shTorchchat debería estar ahora instalado y listo para ser utilizado. Podemos verificar la instalación listando los comandos Torchat disponiblesasí:
python torchchat.py --helpUsar Torchat localmente con Python
Con Torchat instalado, podemos empezar a ejecutar LLMs en nuestra máquina local.
Listado de todos los modelos admitidos
TorchChat admite una amplia gama de LLM. Podemos listar los modelos compatibles utilizando el comando list:
python torchchat.py listLa página lista completa de modelos se puede encontrar en su repositorio de GitHub.
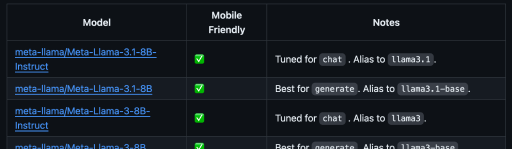
La sección "Notas" proporciona información útil sobre el modelo, como el mejor caso de uso y el alias del modelo utilizado para especificar el modelo cuando se utilizan comandos de Torchchat.
Descargar un modelo
Torchchat utiliza Hugging Face como canal de distribución de los modelos. Hugging Face es una plataforma colaborativa con herramientas que permiten a cualquiera crear, entrenar y desplegar modelos de PLN y ML utilizando código de fuente abierta. Para saber más sobre ello, consulta esta entrada del blog sobre Qué es la Cara de Abrazo.
Antes de descargar un modelo, necesitamos
- Instala la interfaz de línea de comandos Cara Abrazada
- Crear una cuenta en Hugging Face
- Crear un token de acceso
- Conéctate utilizando la interfaz de línea de comandos de hugging face
Para instalar la interfaz de línea de comandos de Cara Abrazada, utilizamos pip:
pip install huggingface_hubA continuación, podemos navegar hasta la Cara Abrazada para crear una cuenta. Después de crear una cuenta, podemos hacer un token de acceso visitando la configuración del perfil:
En el perfil, podemos abrir el menú "Fichas de acceso" para crear una nueva ficha:
En cuanto a los permisos del token, los permisos de lectura son suficientes para este artículo. Ten en cuenta que cuando se crea el token, tenemos que copiarlo en el portapapeles porque no podremos volver a verlo más adelante.
Utilizando el token, podemos iniciar sesión con el siguiente comando:
huggingface-cli loginUna vez iniciada la sesión, podemos descargar un modelo utilizando el comando download. Ten en cuenta que algunos de estos modelos pueden ser bastante grandes, así que asegúrate de que tienes suficiente espacio en disco. A título ilustrativo, utilizaremos el modelo stories15M, un modelo de generación de pequeñas historias. Este es un buen modelo para empezar porque se descarga rápidamente y no requiere permisos especiales.
Para descargarlo, lo hacemos:
python torchchat.py download stories15MEjecutar un modelo
Después de descargar el modelo, podemos utilizar los comandos chat o generate. Para generar texto, tenemos que proporcionar un indicador utilizando el argumento --prompt. He aquí un ejemplo:
python torchchat.py generate stories15M --prompt “Once upon a time”El comando anterior indicará a Torchchat que genere texto utilizando el modelo stories15M con el prompt ”Once upon a time”.
Para ejecutar el modelo en modo chat, utilizamos el comando chat sin símbolo del sistema.
python torchchat.py chat stories15M El comando chat iniciará un chat interactivo en el terminal donde podremos charlar con el LLM. Ten en cuenta que algunos de los modelos son más adecuados para ser utilizados con el modo generate, mientras que otros son más adecuados para el modo chat. Esta información está disponible en la sección "Notas" de la documentación del modelo.
Solicitar acceso a un modelo
Algunos modelos como llama3 requieren un acceso especial para ser descargados. Si intentamos descargar un modelo de este tipo, obtendremos un mensaje de error:
Access to model meta-llama/Meta-Llama-3-8B-Instruct is restricted and you are not in the authorized list. Visit https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct to ask for access.Podemos solicitar el acceso siguiendo la URL indicada en el mensaje de error. Tenemos que rellenar un breve formulario con información personal y aceptar las condiciones del servicio. Recibirás un correo electrónico cuando se te conceda el acceso.
Uso avanzado
Torchchat proporciona algunas opciones adicionales a la hora de ejecutar LLMs localmente, permitiendo adaptarlos a nuestras necesidades y hardware. Exploremos algunas de estas opciones.
Control de la precisión
Los LLM dependen en gran medida de la multiplicación matricial, que implica multiplicar muchos números de coma flotante. Varios tipos de datos para representar en el ordenador números de coma flotante con distinta precisión.
Una mayor precisión puede garantizar que los matices captados durante el entrenamiento se representen fielmente durante la inferencia, especialmente en tareas complejas o de comprensión lingüística matizada. Sin embargo, utilizar números de alta precisión puede ralentizar considerablemente la inferencia. El tipo de datos adecuado depende del equilibrio entre velocidad y precisión.
Para establecer el tipo de datos al ejecutar el LLM, podemos utilizar el parámetro --dtype, por ejemplo:
python torchchat.py chat --dtype fast stories15MCompilación Just-In-Time
La bandera --compile permite la compilación Just-In-Time (JIT) del modelo. JIT se refiere a una técnica utilizada para optimizar el rendimiento de la inferencia compilando dinámicamente partes del modelo en código a nivel de máquina en tiempo de ejecución, en lugar de interpretarlas cada vez que se ejecutan. Este enfoque puede mejorar significativamente la eficacia y la velocidad de los modelos que se ejecutan en diversas plataformas de hardware.
Utilizar JIT conllevará tiempos de inicio más elevados debido al paso de compilación adicional, pero la inferencia se ejecutará más rápido. Así es como utilizaríamos chat junto con JIT:
python torchchat.py chat --compile stories15MTen en cuenta que esta opción puede no ser compatible con todos los tipos de hardware. En este caso, Torchchat ignorará el paso de compilación y ejecutará el LLM sin él.
Cuantización
Cuantización es una técnica utilizada para reducir el tamaño del modelo y aumentar su velocidad de inferencia sin comprometer significativamente su rendimiento o precisión. Esto es especialmente importante para desplegar LLM en dispositivos periféricos o en entornos donde los recursos informáticos, la memoria y el ancho de banda son limitados.
En pocas palabras, la cuantización consiste en convertir los pesos y las activaciones de una red neuronal de una representación en coma flotante (normalmente flotantes de 32 bits) a representaciones de bits inferiores, como enteros de 16 bits, enteros de 8 bits o incluso representaciones binarias en algunos casos.
Esto es diferente de ajustar la precisión con --dtype. La cuantificación actúa directamente sobre los pesos del modelo, creando un modelo más pequeño, mientras que el tipo de datos especifica el tipo de datos utilizados en los cálculos de inferencia.
Utilizar la cuantización en Torchchat requiere un archivo de configuración JSON y se puede utilizar así:
python torchchat.py chat --quantize config.json stories15MPara más detalles sobre el formato del archivo de configuración config.json o sobre cómo funciona la cuantización en Torchchat, consulta su página de documentación sobre la cuantización.
Especificación del dispositivo
Podemos especificar el dispositivo utilizado para ejecutar el LLM utilizando la opción --device. Por ejemplo, para ejecutarlo en CUDA, utilizaríamos:
python torchchat.py chat --device cuda stories15MConclusión
Torchchat es un gran paso en la democratización de la inferencia LLM. Facilita a cualquiera la ejecución eficaz de LLM en una amplia gama de dispositivos.
Torchchat ofrece muchas más capacidades que las que hemos presentado en este artículo. Hemos proporcionado las explicaciones necesarias para que cualquiera pueda empezar a ejecutar LLM localmente en su ordenador utilizando Python y PyTorch. Te animo encarecidamente a que sigas explorando Torchchat.


