
Lernpfad
Deep Learning in Python
18 Std.
Optimierungsalgorithmen spielen beim Deep Learning eine entscheidende Rolle: Sie sorgen für die Feinabstimmung der Modellgewichte, um die Verlustfunktionen beim Training zu minimieren. Ein solcher Algorithmus ist der Adam-Optimierer.
Adam wurde im Deep Learning extrem populär, weil es die Vorteile von Momentum und adaptiven Lernraten kombiniert. Dadurch ist es sehr effizient für das Training tiefer neuronaler Netze. Außerdem erfordert es nur eine minimale Einstellung der Hyperparameter, was es für verschiedene Aufgaben zugänglich und effektiv macht.
Im Jahr 2017 stellten Ilya Loshchilov und Frank Hutter in ihrem Paper " Decoupled Weight Decay Regularization " eine weiterentwickelte Version des beliebten Adam-Algorithmus vor.Decoupled Weight Decay Regularization."Sie nannten ihn AdamW, der sich dadurch auszeichnet, dass er den Gewichtsverfall vom Prozess der Gradientenaktualisierung entkoppelt. Diese Trennung ist eine entscheidende Verbesserung gegenüber Adam und hilft bei einer besseren Modellverallgemeinerung.
AdamW ist in modernen Deep-Learning-Anwendungen immer wichtiger geworden, vor allem bei der Handhabung großer Modelle. Seine überragende Fähigkeit, Gewichtsaktualisierungen zu regulieren, hat dazu beigetragen, dass er für Aufgaben eingesetzt wird, die hohe Leistung und Stabilität erfordern.
In diesem Tutorial werden wir die Hauptunterschiede zwischen Adam und AdamW sowie die verschiedenen Anwendungsfälle behandeln und eine Schritt-für-Schritt-Anleitung zur Implementierung von AdamW in PyTorch.
Adam und AdamW sind beides adaptive Optimierer, die im Deep Learning weit verbreitet sind. Der große Unterschied zwischen ihnen besteht darin, wie sie die Gewichtsregulierung handhaben, was sich auf ihre Effektivität in verschiedenen Szenarien auswirkt.
Adam kombiniert zwar Momentum und adaptive Lernraten, um eine effiziente Optimierung zu ermöglichen, integriert aber die L2-Regularisierung auf eine Weise, die die Leistung beeinträchtigen kann. AdamW behebt dieses Problem, indem es den Gewichtsverfall von der Aktualisierung der Lernrate entkoppelt und so einen effektiveren Ansatz für große Modelle und eine bessere Generalisierung bietet. Die Gewichtsabnahme, eine Form der L2-Regularisierung, bestraft große Gewichte im Modell. Adam integriert den Gewichtsabbau in den Prozess der Gradientenaktualisierung, während AdamW ihn separat nach der Gradientenaktualisierung anwendet.
Hier sind einige weitere Unterschiede zwischen ihnen:
Obwohl beide Optimierer darauf ausgelegt sind, die Dynamik zu verwalten und die Lernraten dynamisch anzupassen, unterscheiden sie sich grundlegend in ihrer Behandlung des Gewichtsverfalls.
In Adam wird der Gewichtsabbau indirekt als Teil der Gradientenaktualisierung angewandt, was die Lerndynamik ungewollt verändern und den Optimierungsprozess stören kann. AdamW hingegen trennt den Gewichtsabbau vom Gradientenschritt und stellt so sicher, dass sich die Regularisierung direkt auf die Parameter auswirkt, ohne den adaptiven Lernmechanismus zu verändern.
Dieses Design führt zu einer präziseren Regularisierung und hilft den Modellen, besser zu verallgemeinern, insbesondere bei Aufgaben, die große und komplexe Datensätze umfassen. Daher haben die beiden Optimierer oft sehr unterschiedliche Anwendungsfälle.
Adam schneidet bei Aufgaben besser ab, bei denen die Regularisierung weniger wichtig ist oder bei denen die Recheneffizienz Vorrang vor der Generalisierung hat. Beispiele dafür sind:
AdamW eignet sich hervorragend für Szenarien, in denen Overfitting ein Problem darstellt und die Modellgröße beträchtlich ist. Zum Beispiel:
Aber warum sollte jemand AdamW gegenüber Adam bevorzugen? Einfach. AdamW bietet mehrere wichtige Vorteile, die seine Leistung vor allem in komplexen Modellierungsszenarien verbessern.
Sie behebt einige der Einschränkungen des Adam-Optimierers und macht ihn dadurch effektiver bei der Optimierung und trägt zu einer verbesserten Modellbildung und Robustheit bei.
Hier sind einige der wichtigsten Vorteile:
Die Stärke von AdamW liegt in seinem Ansatz zum Gewichtsabbau, der von den für Adam typischen adaptiven Gradientenaktualisierungen entkoppelt ist. Diese Anpassung stellt sicher, dass die Regularisierung direkt auf die Gewichte des Modells angewandt wird, was die Generalisierung verbessert, ohne die Dynamik der Lernrate negativ zu beeinflussen.
Der Optimierer baut auf der adaptiven Natur von Adam auf und behält die Vorteile der Schwungkraft und der Anpassung der Lernrate pro Parameter bei. Die unabhängige Anwendung von Weight Decay behebt einen der Hauptmängel von Adam: seine Tendenz, Gradientenaktualisierungen während der Regularisierung zu beeinflussen. Diese Trennung ermöglicht es AdamW, selbst bei komplexen und großen Modellen stabil zu lernen und gleichzeitig die Überanpassung in Schach zu halten.
In den folgenden Abschnitten werden wir die Theorie hinter dem Gewichtsabbau und der Regularisierung sowie die Mathematik, die dem Optimierungsprozess von AdamW zugrunde liegt, untersuchen.
Die L2-Regularisierung ist eine Technik, die eine Überanpassung verhindern soll. Dieses Ziel wird erreicht, indem die Verlustfunktion mit einem Straffaktor versehen wird, der von großen Gewichtswerten abschreckt. Mit dieser Technik lassen sich einfachere Modelle erstellen, die sich besser auf neue Daten verallgemeinern lassen.
Bei traditionellen Optimierern wie Adam wird der Gewichtsabbau als Teil der Gradientenaktualisierung angewandt, was sich unbeabsichtigt auf die Lernraten auswirkt und zu einer suboptimalen Leistung führen kann.
AdamW verbessert dies, indem es den Gewichtsverfall von der Gradientenberechnung entkoppelt. Mit anderen Worten: Anstatt den Gewichtsverfall während der Aktualisierung des Gradienten anzuwenden, behandelt AdamW ihn als separaten Schritt und wendet ihn direkt auf die Gewichte nach der Aktualisierung des Gradienten an. Dadurch wird verhindert, dass der Optimierungsprozess durch den Gewichtsverfall beeinträchtigt wird, was zu einem stabileren Training und einer besseren Generalisierung führt.
AdamW modifiziert den traditionellen Adam-Optimierer, indem es die Art und Weise ändert, wie der Gewichtsabfall angewendet wird. Die Kerngleichungen für AdamW können wie folgt dargestellt werden:
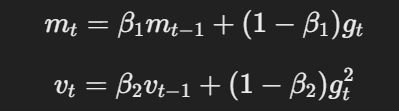
Die Gleichung für Schwung und adaptive Lernrate
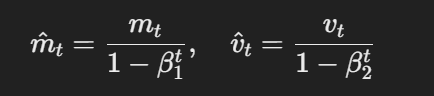
Die Formel für verzerrungskorrigierte Schätzungen
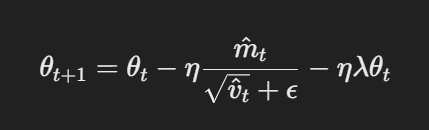
Parameteraktualisierung mit entkoppeltem Gewichtsverfall
Dabei ist η die Lernrate, λ ist der Gewichtsabnahmefaktor und θt steht für die Parameter. Dieser entkoppelte Gewichtsabfallterm λθt stellt sicher, dass die Regularisierung unabhängig von der Aktualisierung des Gradienten angewendet wird, was der entscheidende Unterschied zu Adam ist.
Implementierung von AdamW in PyTorch ist ganz einfach; dieser Abschnitt enthält eine umfassende Anleitung zur Einrichtung. Befolge diese Schritte, um zu lernen, wie du deine Modelle mit Adam Optimizer effektiv abstimmen kannst.
Hinweis: Dieses Tutorial setzt voraus, dass du PyTorch bereits installiert hast. Siehe auch die Dokumentation für weitere Hinweise.
Schritt 1: Importiere die notwendigen Bibliotheken
import torch
import torch.nn as nn
import torch.optim as optim
Import torch.nn.functional as F
Schritt 2: Definiere das Modell
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8)
x = F.relu(self.fc1(x))
x = self.fc2(x)
Schritt 3: Lege die Hyperparameter fest
learning_rate = 1e-4
weight_decay = 1e-2
num_epochs = 10 # number of epochsSchritt 4: Initialisiere den AdamW-Optimierer und lege die Verlustfunktion fest
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()Voila!
Jetzt kannst du mit dem Training deines CNN-Modells beginnen, und das werden wir im nächsten Abschnitt tun.
Oben haben wir das Modell definiert, die Hyperparameter festgelegt, den Optimierer (AdamW) initialisiert und die Verlustfunktion festgelegt.
Um das Modell zu trainieren, müssen wir noch ein paar weitere Module importieren;
from torch.utils.data import DataLoader # provides an iterable of the dataset
import torchvision
import torchvision.transforms as transformsAls Nächstes definierst du das Dataset und die Dataloader. Für dieses Beispiel verwenden wir den CIFAR-10-Datensatz:
# Define transformations for the training set
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# Load CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)Da wir unser Modell bereits definiert haben, besteht der nächste Schritt darin, die Trainingsschleife zu implementieren, um das Modell mit AdamW zu optimieren.
So sieht es aus:
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad() # Clear gradients
outputs = model(inputs) # Forward pass
loss = criterion(outputs, labels) # Calculate loss
loss.backward() # Backward pass
optimizer.step() # Update weights
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')Der letzte Schritt besteht darin, die Leistung des Modells anhand des zuvor erstellten Validierungsdatensatzes zu überprüfen.
Hier ist der Code:
model.eval() # Set the model to evaluation mode
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs) # Forward pass
_, predicted = torch.max(outputs.data, 1) # Get predicted class
total += labels.size(0) # Update total samples
correct += (predicted == labels).sum().item() # Update correct predictions
accuracy = 100 * correct / total
print(f'Validation Accuracy: {accuracy:.2f}%')Und da hast du es.
Du weißt jetzt, wie du AdamW in PyTorch implementieren kannst.
Okay, wir haben also festgestellt, dass AdamW durch sein effektiveres Management des Gewichtsverlusts als sein Vorgänger Adam an Popularität gewonnen hat.
Aber was sind die häufigsten Anwendungsfälle für diesen Optimierer?
Darauf gehen wir in diesem Abschnitt ein...
AdamW ist besonders nützlich, um große Modelle wie BERT, GPT und andere Transformatorarchitekturen zu trainieren. Solche Modelle haben in der Regel Millionen oder sogar Milliarden von Parametern, was oft bedeutet, dass sie effiziente Optimierungsalgorithmen erfordern, die komplexe Gewichtungsaktualisierungen und Generalisierungsherausforderungen bewältigen.
AdamW ist der Optimierer der Wahl bei Computer-Vision-Aufgaben mit CNNs und NLP-Aufgaben mit Transformatoren. Seine Fähigkeit, Überanpassungen zu verhindern, macht ihn ideal für Aufgaben mit großen Datensätzen und komplexen Architekturen. Durch die Entkopplung des Gewichtsverfalls vermeidet AdamW die Probleme, die Adam bei der Überregulierung von Modellen hat.
Beim Hyperparameter-Tuning werden die besten Werte für Parameter ausgewählt, die das Training eines maschinellen Lernmodells bestimmen, aber nicht aus den Daten selbst gelernt werden. Diese Parameter beeinflussen direkt, wie das Modell optimiert und konvergiert.
Die richtige Einstellung dieser Hyperparameter in AdamW ist wichtig, um ein effizientes Training zu erreichen, eine Überanpassung zu vermeiden und sicherzustellen, dass das Modell gut auf ungesehene Daten verallgemeinert.
In diesem Abschnitt erfahren wir, wie du die wichtigsten Hyperparameter von AdamW für eine optimale Leistung anpassen kannst.
Die Lernrate ist ein Hyperparameter, der bestimmt, wie stark die Modellgewichte bei jedem Trainingsschritt an den Verlustgradienten angepasst werden. Eine höhere Lernrate beschleunigt das Training, kann aber dazu führen, dass das Modell über die optimalen Gewichte hinausschießt, während eine niedrigere Rate feinere Anpassungen ermöglicht, aber das Training langsamer machen oder in lokalen Minima stecken bleiben kann.
Der Gewichtsabbau hingegen ist eine Regularisierungstechnik, die eine Überanpassung verhindert, indem sie große Gewichte im Modell bestraft. Mit Weight decay wird während des Trainings ein kleiner Abschlag proportional zur Größe der Modellgewichte hinzugefügt, um die Komplexität des Modells zu reduzieren und die Generalisierung auf neue Daten zu verbessern.
Die optimale Lernrate und den optimalen Wert für das Abklingen der Gewichte für AdamW zu wählen:
AdamW hat sich als einer der effektivsten Optimierer im Deep Learning herauskristallisiert, insbesondere für große Modelle. Das liegt an seiner Fähigkeit, den Gewichtsverfall von der Aktualisierung des Gradienten zu entkoppeln. Das Design von AdamW verbessert die Regularisierung und trägt dazu bei, dass Modelle besser verallgemeinert werden können, vor allem wenn es um komplexe Architekturen und umfangreiche Datensätze geht.
Wie in diesem Tutorial gezeigt wird, ist die Implementierung von AdamW in PyTorch ganz einfach - es sind nur ein paar Anpassungen von Adam erforderlich. Die Abstimmung der Hyperparameter ist jedoch ein entscheidender Schritt, um die Effektivität von AdamW zu maximieren. Das richtige Gleichgewicht zwischen Lernrate und Gewichtsabnahme zu finden, ist wichtig, um sicherzustellen, dass der Optimierer effizient arbeitet, ohne das Modell zu sehr oder zu wenig anzupassen.
Jetzt weißt du genug, um AdamW in deinen eigenen Modellen einzusetzen. Wenn du dich weiterbilden willst, schau dir einige dieser Ressourcen an:
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
