Course
Understanding Modern Data Architecture
2 hr
22.4K
With the features we just mentioned in mind, here’s a concise overview of the advantages of Athena:
|
Benefit |
Feature |
Description |
|
Cost Efficiency |
Pay-per-query model |
Only pay for the data your queries interact with; no upfront costs or complex licenses; cost optimization is possible with partitioning, data compression, and columnar formats. |
|
Ease of Use |
Serverless & Standard SQL |
No need to set up or manage infrastructure; users can start querying data within minutes using familiar SQL syntax, making it accessible and straightforward to use. |
|
Flexibility |
Multi-format support |
It supports a wide range of data formats (e.g., CSV, JSON, Parquet), allowing users to query data in its native format directly from S3 without requiring ETL processes. |
|
Quick Insights |
Rapid analysis & direct S3 queries |
It enables immediate data analysis with serverless architecture, allowing for quick extraction of insights directly from data stored in S3 and reducing the time-to-value for data-driven decisions. |
We have defined Athena and mentioned its features and benefits, but what is it used for? In this section, we will review some of the most popular use cases.
Amazon Athena is frequently used for log analysis, particularly for querying and analyzing logs stored in Amazon S3. Organizations often generate massive volumes of log data from various sources, such as application logs, server logs, and access logs.
By storing these logs in S3 and querying them using Athena, users can quickly identify trends, diagnose issues, and monitor system performance without needing a complex setup.
Athena’s serverless architecture and support for standard SQL make it an excellent tool for ad-hoc data exploration. Whether you’re a data scientist, analyst, or engineer, Athena lets you quickly query data stored in S3 without loading it into a traditional database.
As organizations increasingly adopt data lakes to store vast amounts of raw and processed data, Athena serves as a powerful query engine for these data lakes. It allows users to perform analytics directly on data stored in S3, making it an integral part of a modern data lake architecture.
Athena is also commonly used as part of a business intelligence (BI) stack, where it integrates with BI tools like Amazon QuickSight to enable data visualization and reporting. By querying data in S3 with Athena and visualizing it in QuickSight, organizations can create interactive dashboards and reports for decision-making.
If you’re familiar with Amazon Redshift, you may wonder how it differs from Athena.
While both Athena and Redshift deal with datasets, their goals are different. Redshift’s primary use case is data warehousing and regular analytics involving big data. AWS Athena is focused on allowing users to perform ad hoc analysis on data stored in S3.
Here’s a detailed comparison of Athena vs Redshift:
|
Criteria |
Amazon Athena |
Amazon Redshift |
|
Architecture |
Serverless query service; runs SQL queries directly on data stored in Amazon S3 with automatic scaling; no infrastructure management. |
Fully managed data warehouse; requires a data warehouse cluster with dedicated infrastructure; can scale based on needs. The Redshift Serverless option is available. |
|
Use Cases |
It is ideal for ad-hoc querying and analytics on S3 data and for scenarios prioritizing flexibility and cost-efficiency without data transformation. |
Suited for complex, large-scale analytics and reporting; ideal for structured data requiring frequent querying and transformations. |
|
Cost Structure |
Pay-per-query model: charges based on data scanned by queries, making it cost-effective for intermittent or varying workloads. |
Pricing is based on cluster size and usage; reserved instance pricing is available for predictable, high-volume queries. |
|
Performance |
Dependent on data size and format; optimized by partitioning and compression; best for smaller, less complex queries. |
High performance for complex queries; uses columnar storage, parallel processing, and advanced optimization for intensive workloads. |
|
Data Integration |
Directly queries data in S3 without needing transformation or loading; supports various formats and extensible connectors, including Redshift. |
It requires data to be loaded into the warehouse, integrates with AWS services, and supports various data ingestion methods but reads only from its stored data. |
It’s time to get hands-on, set up Athena, and run some queries!
Using AWS Athena requires an AWS account. If you don't have one, you must create one. To do so, follow the instructions in the AWS set-up guide.
While there is no free tier for AWS Athena, you should be able to run 2-3 small test queries (~10MB in size) to understand how the system works. Follow the instructions on the portal and verify your identity. Then log in to your AWS account.
Like all Amazon AWS products, Athena utilizes IAM (identity and access management) policies for permissions. You will be the root user for your account and should have the permissions necessary to run Athena queries on your own S3 buckets.
You can manage IAM permissions by searching for the IAM service in the top search bar in your AWS home dashboard and utilizing this complete IAM guide. The AWS documentation also provides more information on Athena's specific setup.
Before running queries, we need to set up an S3 bucket to store our data.
Amazon S3 stands for Simple Storage Service and is a critical component of how AWS manages storage and data within the cloud environment. Following this well-written guide on creating Amazon S3 buckets, we can create the storage environment for our data and queries.
In short, you will look for the S3 service in the search bar to get to the S3 homepage:
You will see a “Create Bucket” button on the right sidebar on the homepage. Following the instructions on this page, you will create a bucket that will allow your Athena service to store query results.
I will create a bucket called “athenadatacampguide” using all other default options. Because buckets must be globally unique across AWS, you must choose another name for this tutorial.
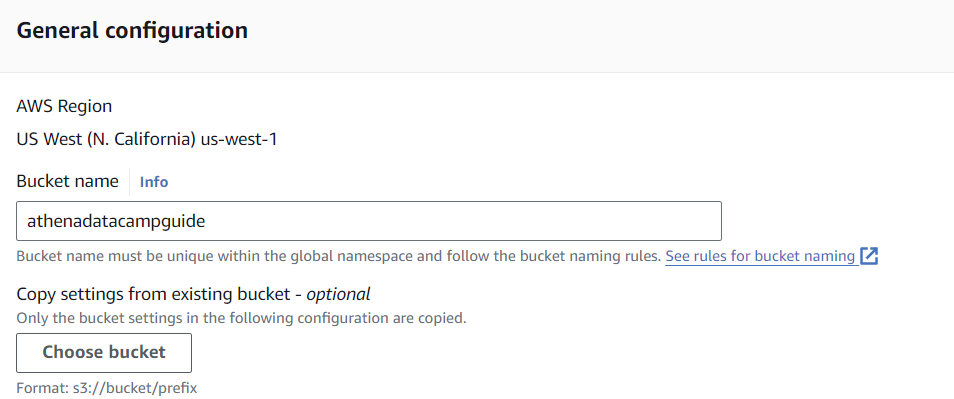
Now, we need to connect this bucket to Athena. I will go to the Athena console and click “Edit Settings” in the small notification bar near the top.

I will then select the bucket I just created. To find your bucket, use the “Browse S3” button on the right or type the name prefixed by “s3://.”
Once the bucket is selected, click “Save” and return it to the Editor by clicking on it in the top toolbar.

AWS Athena organizes data hierarchically. It utilizes “data catalogs,” a group of databases also known as schema.
The actual tables we query are within the databases. To create a new data catalog, you could use Amazon Lambda and connect to an external data source. The data catalog can then be saved as either a Lambda, Hive, or Glue data catalog.
The default on AWS is to use the Glue service as the central data catalog repository. We will focus on building a database that will hold our tables for querying.
In the Editor, go to the Query Editor pane. This is where we will write our queries to create databases, query tables, and run analytics.
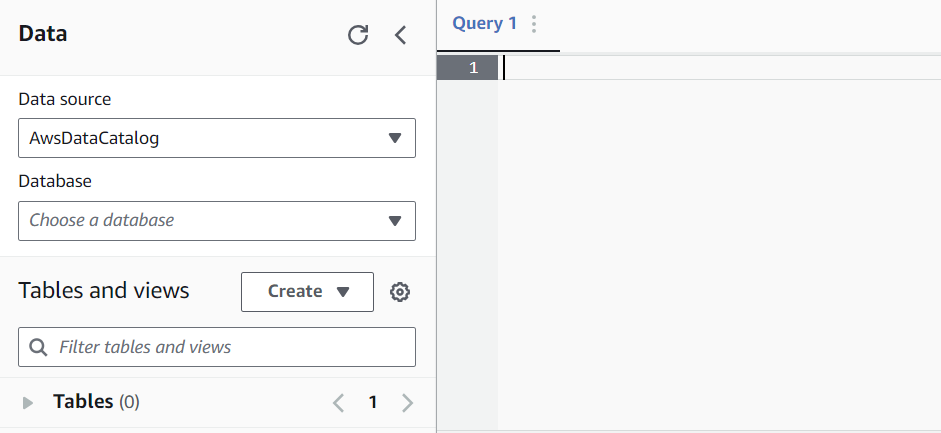
To create our first database, we will run the following query:
CREATE DATABASE mydatabaseRunning this query will allow you to select a database from the dropdown below “Database” on the left sidebar.
Now that we have a database, we will focus on creating a table so we have something to query!
Getting data into your database will differ slightly based on your AWS setup. You can utilize data stored in a data warehouse like Redshift or streaming data utilizing AWS Kinesis and Lambda to generate tabular data.
Today, we will use sample data from sample AWS Cloudfront Logs. Because of the data complexity, part of the creation process uses RegEx groups to parse URl data into columns.
Using the following SQL, we can create a table. Note: below, replace “myregion” with your AWS region.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
Date DATE,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
os STRING,
Browser STRING,
BrowserVersion STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)If the table appears on the left sidebar, you are ready to get started querying!
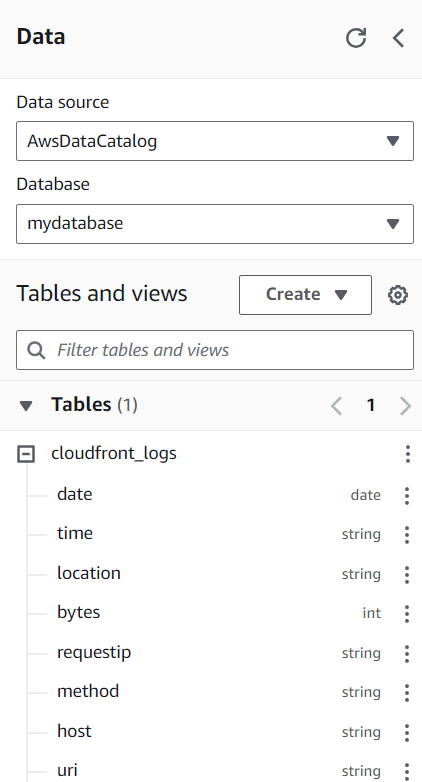
Writing queries in Athena is similar to writing queries in traditional SQL. You simply write and submit the query to Athena, and the desired results are returned.
One best practice is to write your FROM statements with the following syntax: “DataSource”.”database”.”table”. That way, there is never any confusion about where the data is coming from.
Let’s try a simple SELECT statement to get us started.
SELECT *
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
LIMIT 10This should return a table with 10 results. Athena allows you to copy or download the results. At the same time, these results are saved to the S3 bucket you connected to your Athena service.
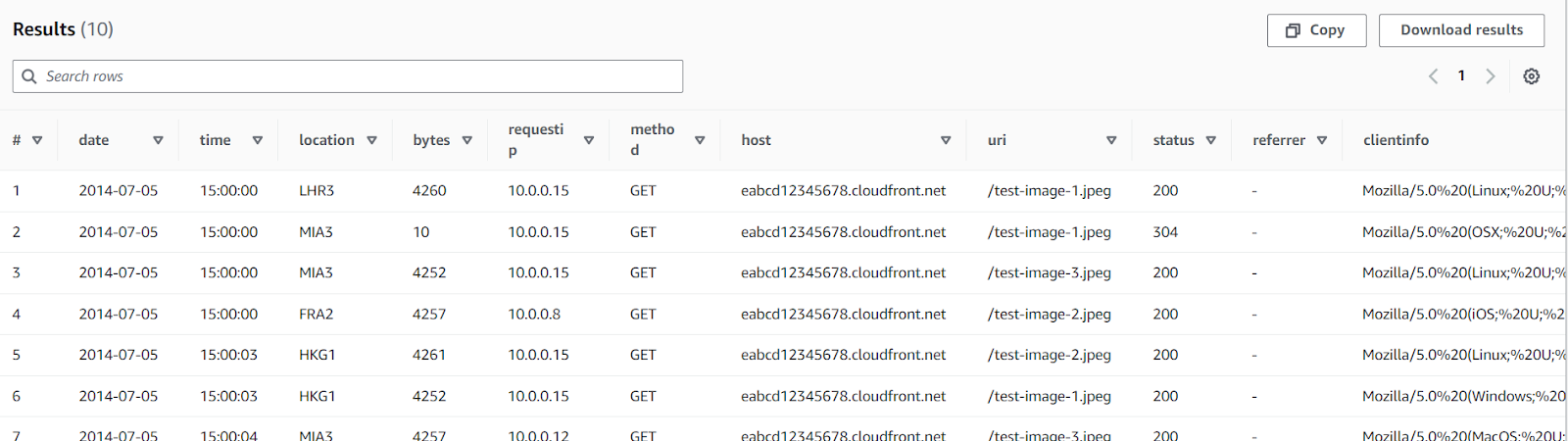
We can even write simple GROUP BY queries. This one, in particular, lets us know how many requestip (not necessarily unique) were involved with specific HTTP methods.
SELECT
method,
COUNT(requestip)
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
GROUP BY 1A great way to utilize Athena is for more complex queries like window functions. Because of Athena’s optimization, we can perform complicated computations more quickly.
For instance, we can use Athena to generate the ROW NUMBER() for each record partitioned by their region and date organized by time descending. We can then pick the most recent record for each region and date using a WHERE filter to pick the first row.
SELECT *
FROM (
SELECT
location,
date,
time,
ROW_NUMBER() OVER(PARTITION BY location, date ORDER BY time DESC) row_num
FROM "AwsDataCatalog"."mydatabase"."cloudfront_logs"
)
WHERE row_num = 1
This is just the beginning with Athena. You can continue to write any query you think will allow you to leverage Athena’s capabilities.
AWS Athena requires a series of best practices like any other data processing tool. These practices will not only make your life easier but also improve its performance.
Additionally, since AWS is a cloud-based service and users are charged based on various storage and computational factors, these practices can lead to significant cost savings!
Various data formats are more handy to utilize in AWS Athena. Since Athena pulls from an S3 bucket, choosing a data format that is easy to read and is compressed will improve performance and cost.
Raw data stored in CSV may be the most straightforward but inefficient. Storing our data in a compressed format like Parquet or ORC format will save on data read costs.
An additional benefit of Parquet and ORC is their columnar-based compression. Athena’s optimizer allows it to look only for particular data columns instead of working through the entire table to perform calculations.
Partitioning data means regularly splitting up a dataset based on a particular key, such as a date. For example, we may have daily partitions where the data is set up to be automatically divided and stored by days.
When our data is partitioned, the SQL engine can perform better optimization by looking at relevant partitions. This leads to a direct improvement in reducing the amount of scanned data, reducing overall cost.
While some complexity is expected when performing data analysis, optimizing queries can help reduce computational time and cost. Some of the costs are not directly from Athena but from other services that AWS Athena utilizes.
The main component of Athena’s cost is scanning and processing data, but you may incur costs from S3 if you save huge results. We can also improve query performance and reduce costs by ensuring queries are optimized following the usual SQL best practices.
For instance, all of the following will help with optimization:
SELECT * where possibleLIMIT when testing queriesThese best practices will improve query performance and reduce cost!
AWS Athena can connect to Amazon CloudWatch to store query metrics. We can discover inefficient queries or problems by looking at query performance logs.
As mentioned, AWS Athena integrates with several other AWS services, enhancing its data cataloging, visualization, processing, and warehousing capabilities.
Below is how Athena works with services like AWS Glue, Amazon QuickSight, AWS Lambda, and Amazon Redshift.
When integrated with AWS Athena, AWS Glue is a central metadata repository that automatically catalogs data in Amazon S3. This integration eliminates the need for manual schema definitions, streamlining data querying in Athena.
Glue also provides ETL capabilities, transforming and preparing data for optimal querying in Athena by automating tasks like data compression, partitioning, and format conversion, ensuring efficient and effective data processing.
Amazon QuickSight integrates with AWS Athena to turn query results into interactive dashboards and reports. This connection allows you to visualize data directly from Athena queries, enabling quick and easy creation of visual insights.
QuickSight supports features like automated data refreshes and advanced analytics, making it a powerful tool for exploring and presenting data.
AWS Lambda automates data processing workflows with Athena in a serverless environment. Lambda functions can trigger Athena queries in response to events, such as new data in S3, enabling real-time processing.
Lambda can also automate subsequent actions based on query results, creating scalable, event-driven workflows without manual intervention.
While Athena is ideal for ad-hoc S3 data querying, Amazon Redshift offers a robust, structured, and complex analytics solution. You can use Athena for quick analysis of raw data and Redshift for more intensive, high-performance queries.
The integration allows data movement between S3 and Redshift, leveraging the strengths of both services for a comprehensive analytics solution.
AWS Athena is a powerful query engine built right into the AWS ecosystem. By allowing users to quickly access data stored in S3 buckets while saving query results to S3 buckets, AWS Athena empowers users to dive into their data more flexibly. It reaps the benefits of other AWS services, such as being serverless, scalable, and straightforward.
If you want to learn more about AWS, DataCamp offers various resources:
Learn more about AWS and data engineering with these courses!
Course
Course
Course
Tutorial
Joleen Bothma
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
DataCamp Team
code-along
Kelsey McNeillie