
programa
Profesional de AWS Cloud (CLF-C02)
10 h
Antes de integrar AWS Formación de Lagos y AWS Glue, asegúrate de que tienes lo siguiente:
Una vez que tengas los requisitos previos, sólo tienes que seguir estos pasos:
El primer paso es desplegar los recursos básicos de AWS necesarios para construir un lago de datos seguro antes de iniciar el proceso de integración. La plantilla de AWS CloudFormation ayuda a organizar e implementar todos los recursos necesarios.
Utiliza la plantilla de CloudFormation proporcionada para crear una pila en tu cuenta de AWS. Esta pila proporciona los recursos esenciales necesarios para los casos de uso descritos en este tutorial.
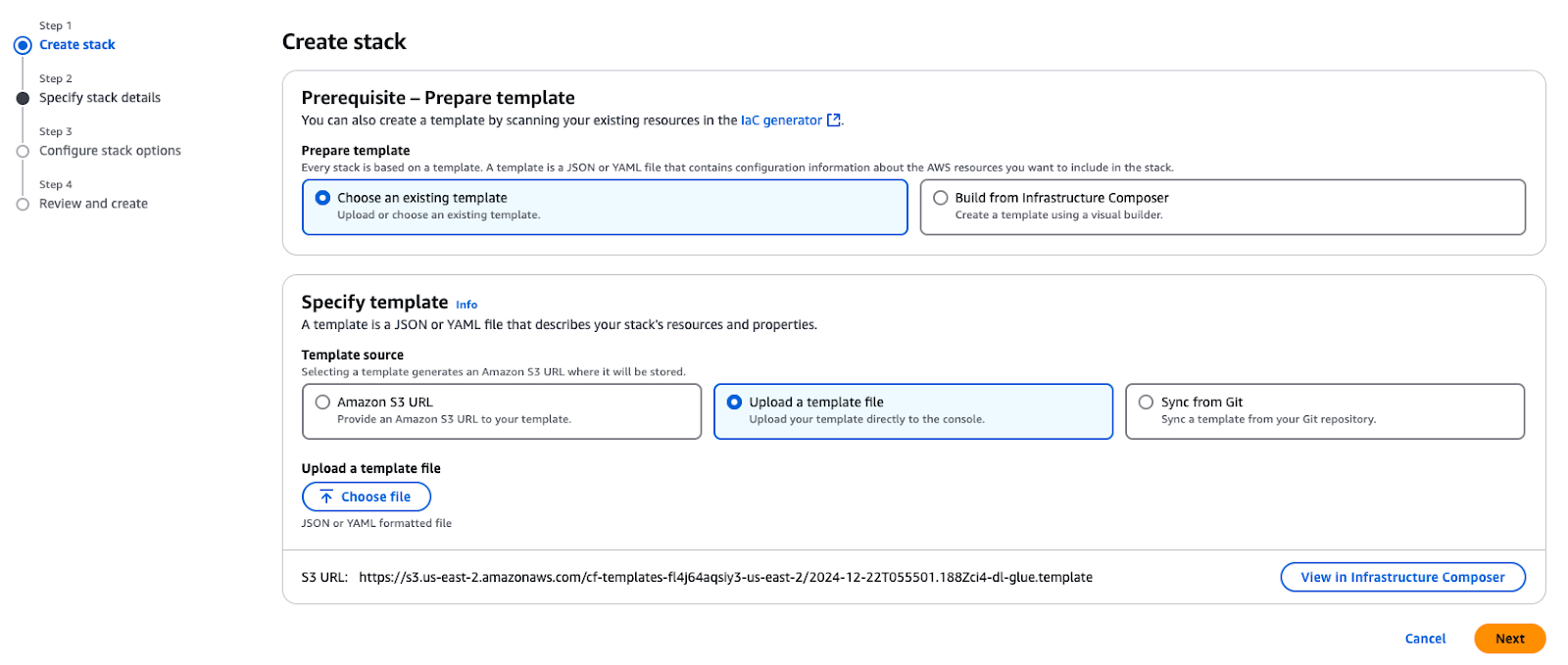
Crear una pila en AWS CloudFormation
Al desplegar la pila, se crearán los siguientes recursos clave en tu cuenta de AWS:
GlueServiceRole: Concede a AWS Glue acceso a los servicios S3 y Lake Formation.DataEngineerGlueServiceRole: Proporciona a los ingenieros permisos para acceder a los datos y procesarlos.DataAdminUser y DataEngineerUser: Usuarios IAM preconfigurados para explorar y gestionar la seguridad de Lake Formation.EC2-DB-Loader) para precargar y transferir datos de muestra a S3.lf-users-credentials) para almacenar de forma segura las credenciales de usuario de los usuarios IAM precreados.Una vez creada la pila, tendrás lo siguiente:
En esta sección, el Administrador del Lago de Datos configurará la Formación del Lago de AWS para que esté disponible para las personas consumidoras de datos, incluidos los ingenieros de datos. El administrador lo hará:
Estas configuraciones proporcionan un control de acceso seguro y detallado y una coordinación fluida con otros servicios de AWS.
Un Administrador del Lago de Datos es un usuario o rol de Gestión de Identidades y Accesos (IAM) que puede dar permiso a cualquier principio (incluido él mismo) sobre cualquier entidad del Catálogo de Datos. El Administrador del Lago de Datos suele ser el primer usuario creado para gestionar el Catálogo de Datos y suele ser el usuario al que se le conceden privilegios administrativos para el Catálogo de Datos.
En el servicio AWS Formación de Lagos, puedes abrir la consulta haciendo clic en el botón Funciones y tareas administrativas -> Añadir Administradores en el botón del panel de navegación y, a continuación, seleccionando el usuario IAM lf-data-admin de la lista desplegable.
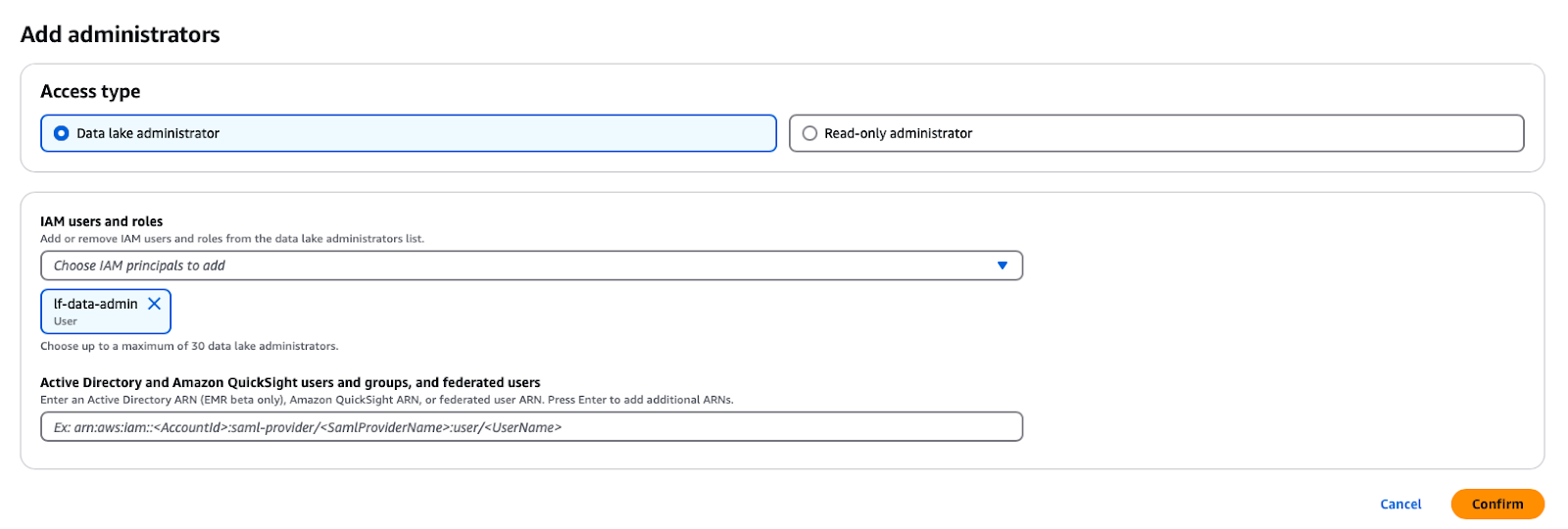
Añadir un administrador de lago de datos en la formación de lago de AWS
Por defecto, Lake Formation tiene la opción "Utilizar sólo control de acceso IAM", que se selecciona para que sea compatible con el Catálogo de Datos de AWS Glue. Para activar el control de acceso de grano fino con los permisos de Formación de Lagos, debes ajustar estas opciones:
IAMAllowedPrincipals aparece en Creadores de bases de datosselecciona el grupo y elige Revocar.Estos pasos desactivarán el control de acceso IAM por defecto y te permitirán implementar los permisos de Formación de Lagos para mejorar la seguridad.
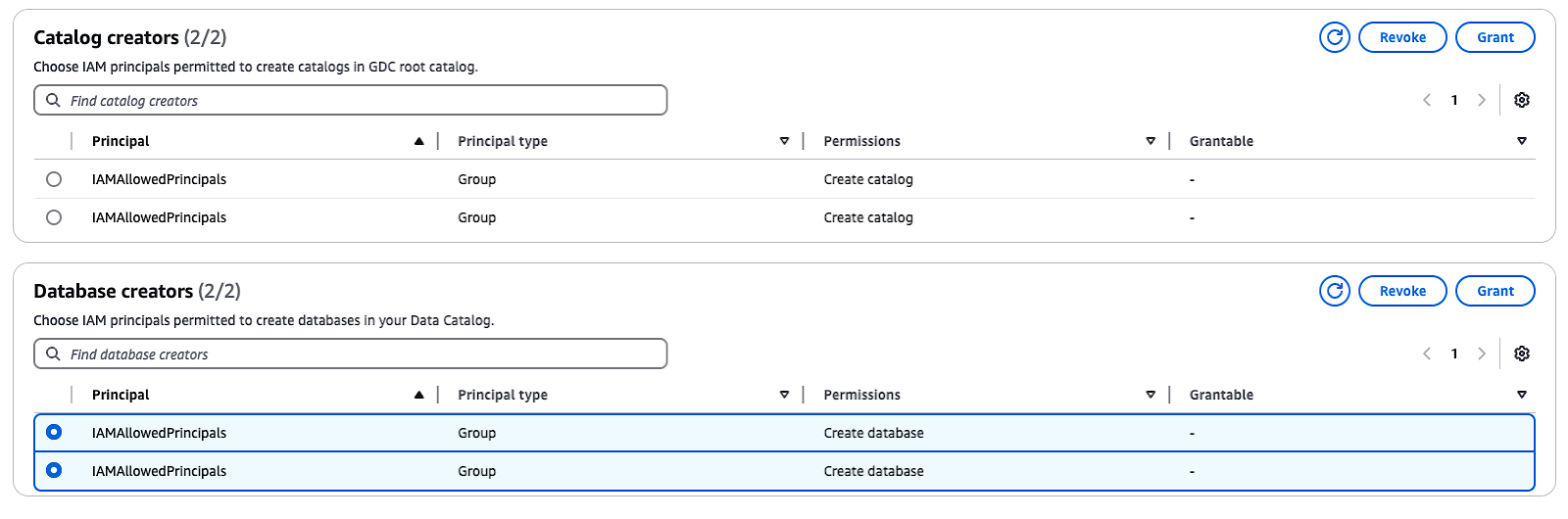
Administrar creadores de catálogos y bases de datos en AWS Formación del Lago
Ahora, es el momento de poner en práctica el Catálogo de Datos Pegados.
Para crear una base de datos para los datos de la TPC, cierra la sesión actual de AWS y vuelve a entrar como usuario de lf-data-admin. Utiliza el enlace de inicio de sesión proporcionado en la salida de CloudFormation y la contraseña recuperada de AWS Secrets Manager.
lf-data-lake-account-ID, donde account-ID es tu número de cuenta de AWS de 12 dígitos.Esta base de datos será la base para almacenar y gestionar los metadatos de los datos de la TPC en la configuración de la Formación del Lago.
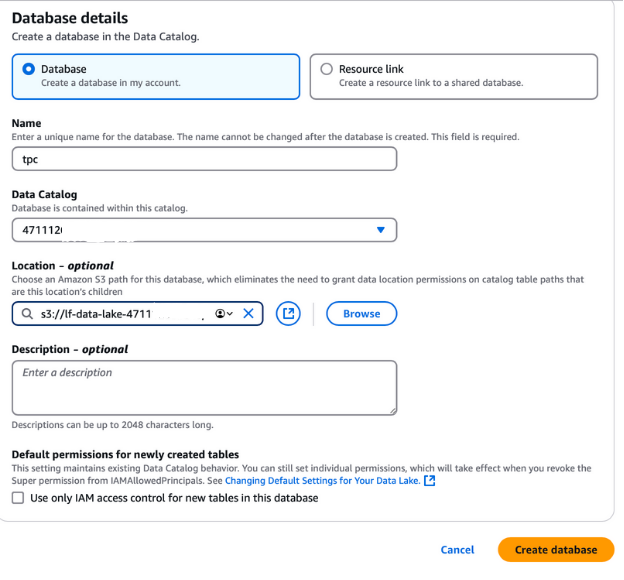
Crear una base de datos en AWS Formación del Lago
Utilizamos un AWS Glue Crawler para crear tablas en el Catálogo de Datos de AWS Glue. Los rastreadores son la forma más común de crear tablas en AWS Glue, ya que pueden escanear varios almacenes de datos a la vez y generar o actualizar los detalles de las tablas en el Catálogo de Datos una vez realizado el rastreo.
Antes de ejecutar el AWS Glue Crawler, tienes que conceder los permisos necesarios a su rol IAM:
tpc base de datos.LF-GlueServiceRole.tpc como base de datos.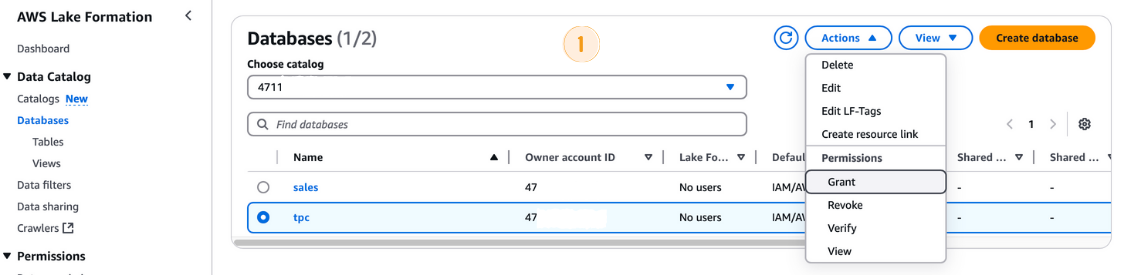
Concesión de permisos en la Formación del Lago AWS
Con los permisos concedidos, procede a ejecutar el rastreador:
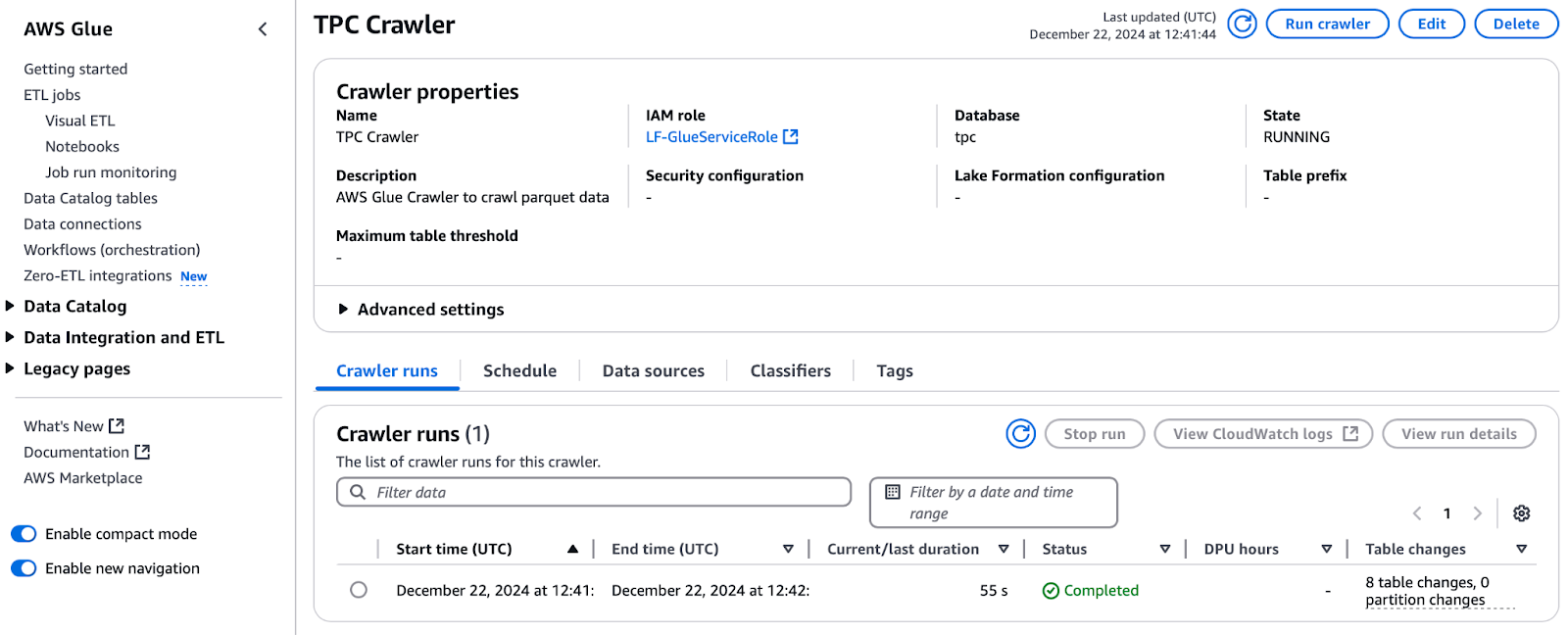
Ejecutar el rastreador TPC en AWS Glue
También puedes verificar estas tablas en la consola de AWS Formación del Lago en Catálogo de datos y Tablas.
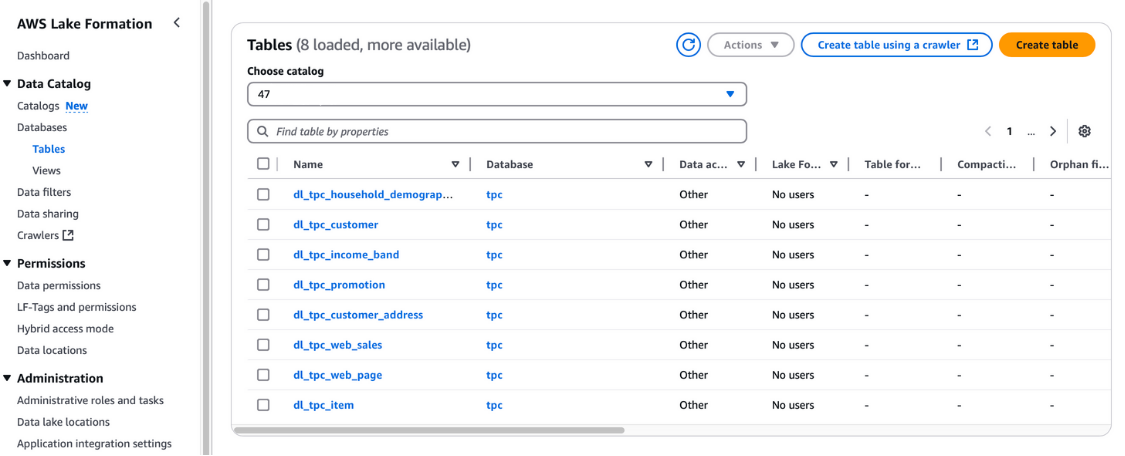
Visualización de las mesas en la Formación del Lago AWS
Debes registrar el bucket S3 en AWS Formación del Lago para el almacenamiento de tu lago de datos. Este registro te permite aplicar un control de acceso detallado a los objetos del Catálogo de Datos de AWS Glue y a los datos subyacentes almacenados en el bucket.
Pasos para registrar una ubicación de Lago de Datos:
LF-GlueServiceRole creado por la plantilla CloudFormation.Una vez registrado, comprueba la ubicación de tu lago de datos para asegurarte de que está correctamente configurado. Este paso es esencial para una gestión de datos y una seguridad sin fisuras en tu configuración de Formación del Lago.
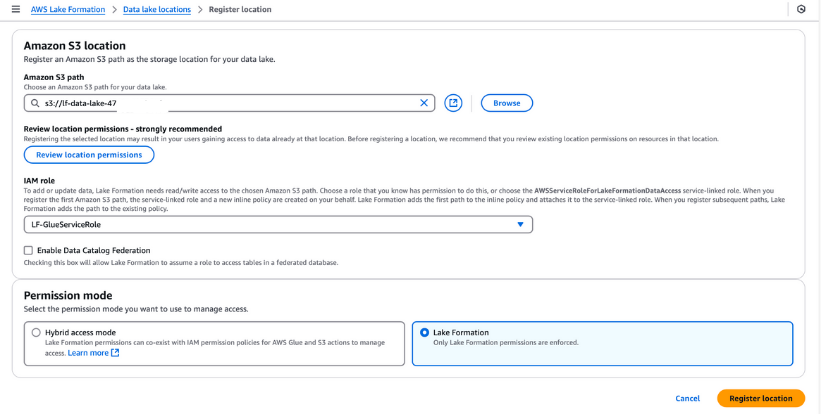
Registrar una ubicación de Amazon S3 en AWS Formación de Lagos
Las etiquetas LF se pueden utilizar para organizar recursos y establecer permisos en muchos recursos a la vez. Te permite organizar los datos mediante taxonomías y, así, desglosar políticas complejas y gestionar los permisos con eficacia. Esto es posible porque con las etiquetas LF puedes separar la política del recurso y, por tanto, puedes establecer políticas de acceso incluso antes de que se creen los recursos.
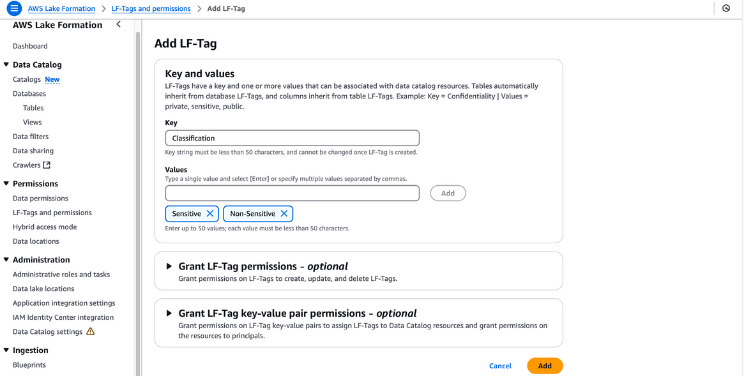
Creación de etiquetas LF en la formación de lagos AWS
lf-data-admin tiene permisos LF-Tag. Navega hasta Tablas en la consola Formación del Lago.dl_tpc_customer, haz clic en acciones y elige Conceder.lf-data-admin.tpc y la tabla dl_tpc_customer, concediendo permisos a la tablaAlter. Haz clic en Concede.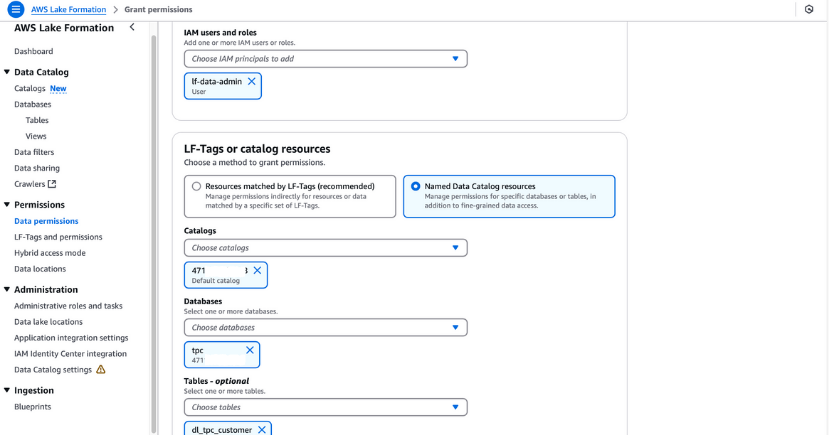
Concesión de permisos en la Formación del Lago AWS
dl_tpc_customer. Abre los detalles de la tabla y selecciona Editar etiquetas LF en el menú de acciones.c_first_name, c_last_name, y c_email_address, y haz clic en Editar etiquetas LF.Classification, cambia el valor a "Sensible" y haz clic en Guardar. Guarda esta configuración como una nueva versión.dl_tpc_household_demographics, ve a Acciones y selecciona Editar etiquetas LF.Siguiendo estos pasos, puedes asignar eficazmente etiquetas LF a tus objetos del Catálogo de Datos, garantizando un control de acceso seguro y detallado en todo tu lago de datos.
AWS Glue Studio es una interfaz de usuario de arrastrar y soltar que ayuda a los usuarios a desarrollar, depurar y monitorizar trabajos ETL para AWS Glue. Los ingenieros de datos aprovechan Glue ETL, basado en Apache Spark, para transformar conjuntos de datos almacenados en Amazon S3 y cargar datos en lagos de datos y almacenes para su análisis. Para administrar eficazmente el acceso cuando varios equipos colaboran en los mismos conjuntos de datos, es importante facilitar el acceso y restringirlo según las funciones.
Sigue estos pasos para conceder los permisos necesarios al usuario lf-data-engineer y al rol correspondiente DE-GlueServiceRole. Este rol lo utiliza el ingeniero de datos para acceder a las tablas del Catálogo de Datos Glue en los trabajos de Glue Studio.
lf-data-admin para acceder a la consola de administración de AWS. Recupera la contraseña de AWS Secrets Manager y la URL de inicio de sesión de la salida de CloudFormation.lf-data-engineer y DE-GlueServiceRole.tpc.dl_tpc_household_demographics.DE-GlueServiceRole.tpc (deja las tablas sin seleccionar).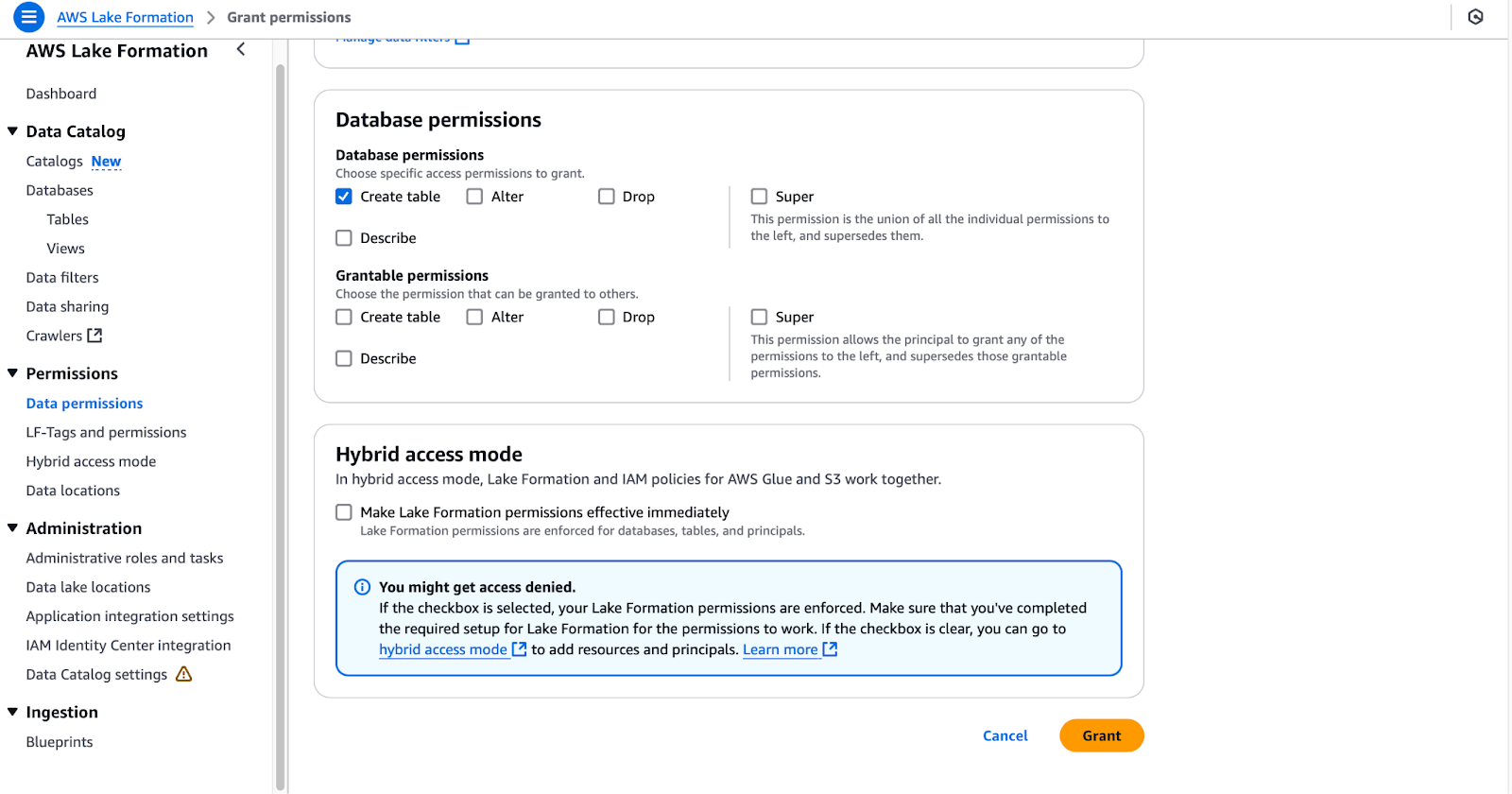
Configurar los permisos de la base de datos en AWS Formación de Lagos
Completar estos pasos dará al usuario lf-data-engineer y al rol DE-GlueServiceRole los permisos necesarios para trabajar con las tablas del Catálogo de Datos Glue y gestionar los recursos en los trabajos de Glue Studio. Esta configuración garantiza un acceso seguro y basado en roles a tu lago de datos.
En esta sección, crearemos un trabajo ETL en AWS Glue Studio utilizando la Transformación SQL.
lf-data-engineer:
lf-data-engineer para acceder a la consola de administración de AWS. Recupera la contraseña de AWS Secrets Manager y la URL de inicio de sesión proporcionada por la salida de CloudFormation.LF_GlueStudio para poder identificarlo fácilmente.DE-GlueServiceRole.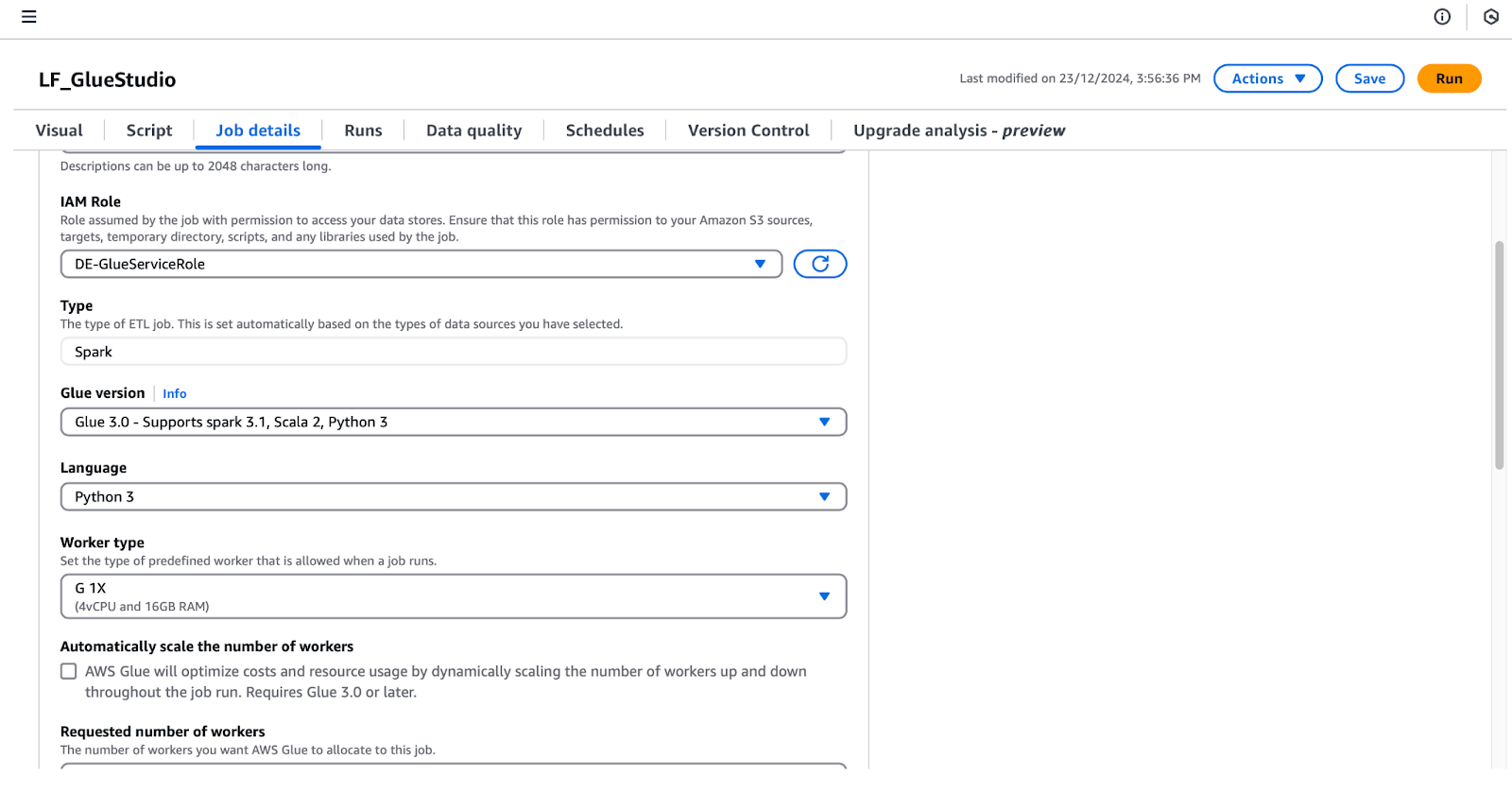
Configurar los detalles del trabajo en AWS Glue Studio
tpc.dl_tpc_household_demographics. (Nota: El usuario lf-data-admin sólo tiene concedido el permiso lf-data-engineer Seleccionar en esta tabla. Las demás tablas no aparecerán en el desplegable).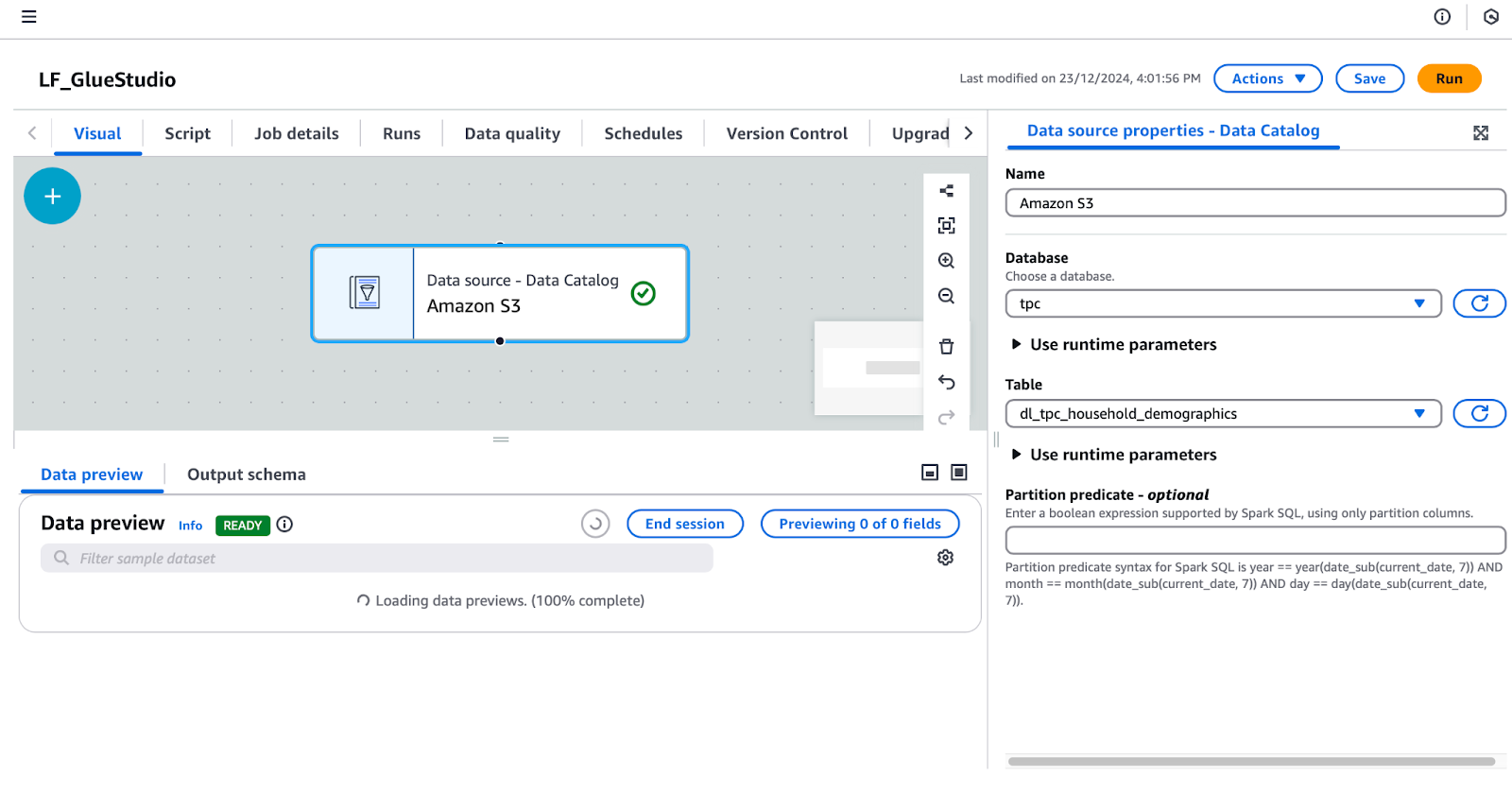
Configurar una fuente de datos en AWS Glue Studio
/* Select all records where buy potential is between 0 and 500 */
SELECT *
FROM myDataSource
WHERE hd_buy_potential = '0-500';hd_dep_count y hd_vehicle_count. Haz clic en Aplica.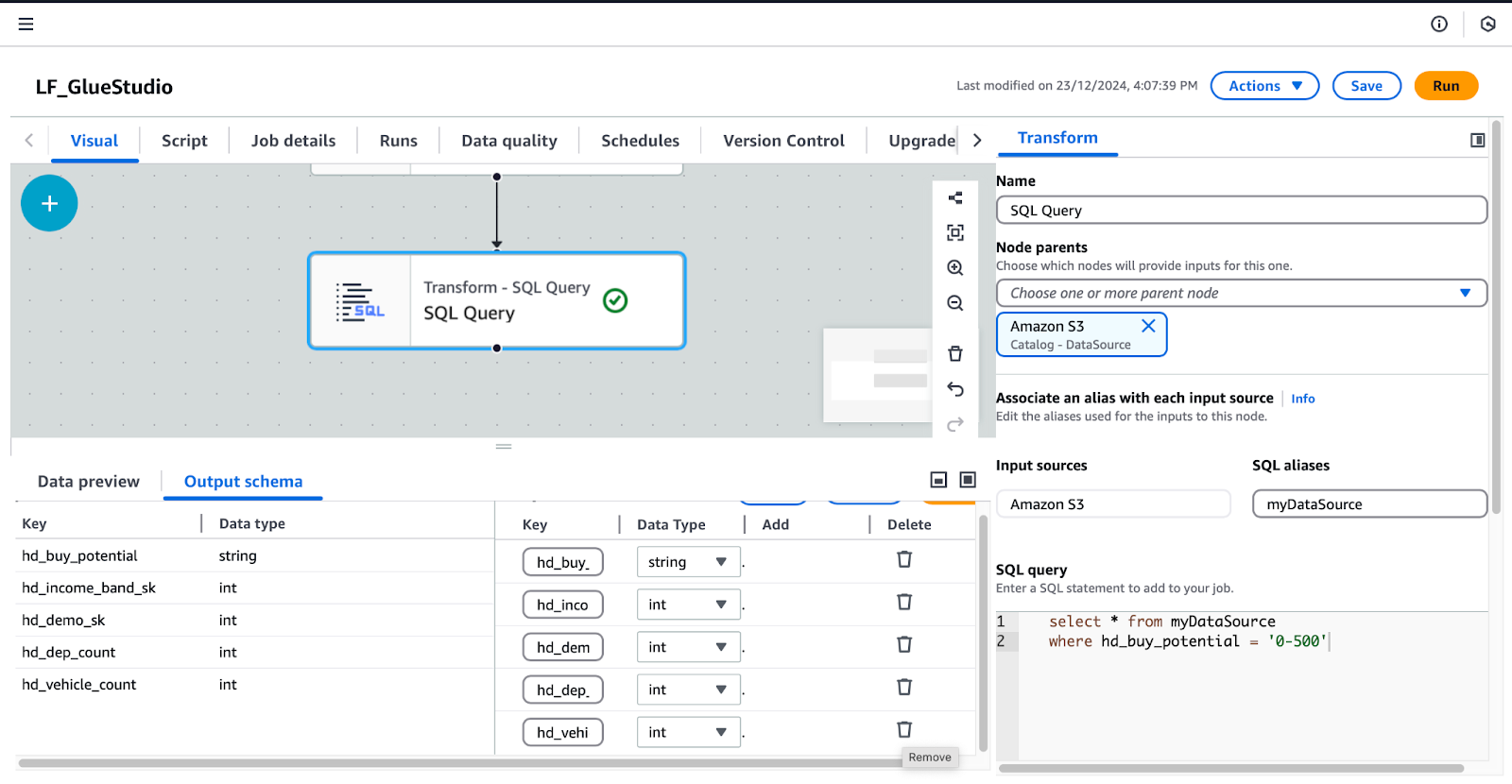
Configuración de la transformación de consultas SQL en AWS Glue Studio
s3:///gluestudio/curated/. (Sustituye tpc .dl_tpc_household_demographics_below500.Siguiendo estos pasos, crearás un trabajo ETL de Glue Studio totalmente funcional que transforme los datos y escriba los resultados en una carpeta S3 curada, al tiempo que actualiza el Catálogo de Datos de Glue.
Para confirmar los permisos concedidos en Lake Formation, sigue estos pasos mientras estás conectado como usuario de lf-data-engineer (como se detalla en la sección Crear trabajos de Glue Studio ):
LF_GlueStudio: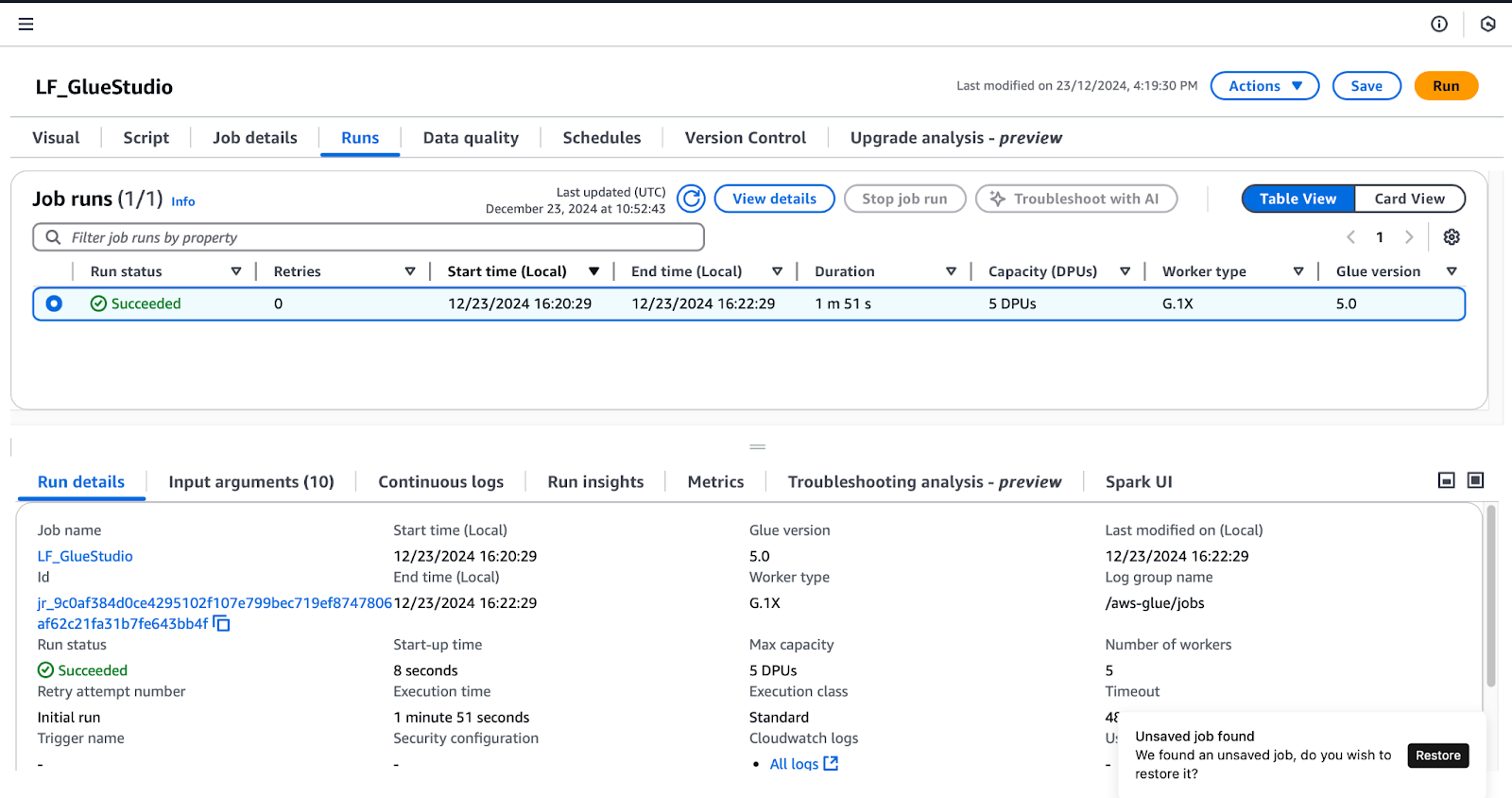
Monitorización de la ejecución de trabajos en AWS Glue Studio
curated de tu bucket S3 para comprobar los archivos de salida. Estos archivos deben estar en formato Parquet, tal y como se configuró durante la creación del trabajo.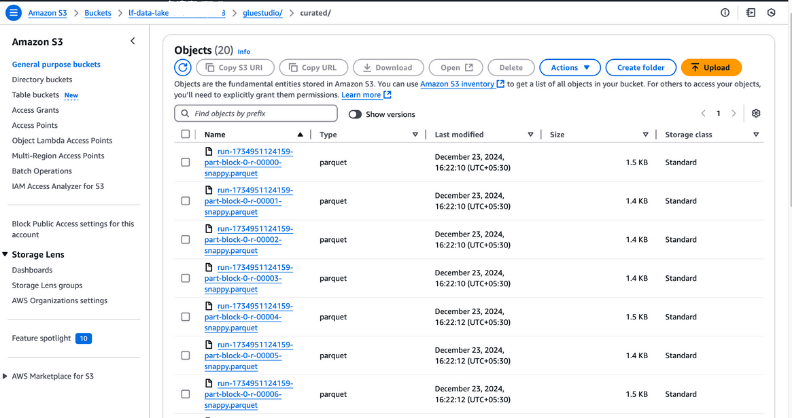
Ver archivos de salida en Amazon S3
Ver tablas de bases de datos en AWS Glue
Al integrar AWS Lake Formation y AWS Glue, seguir las mejores prácticas puede mejorar la seguridad de los datos, agilizar las operaciones y optimizar el rendimiento. A continuación te explicamos cómo puedes aprovechar al máximo estos servicios:

Registrar eventos para TPC Crawler en AWS CloudWatch

Monitorización de las métricas de trabajo de AWS Glue Studio
La implementación de AWS Lake Formation y AWS Glue ayuda a la organización a organizar, salvaguardar y procesar los datos. Utilizando las amplias medidas de seguridad de Lake Formation y la automatización de Glue, puedes optimizar tus procesos ETL, cumplir todas las políticas relativas a la gobernanza de datos y facilitar el acceso a los datos a los usuarios, incluidos los ingenieros y científicos de datos.
Los beneficios incluyen:
A medida que profundices en tu comprensión de la integración de datos, es esencial que complementes tu aprendizaje con conocimientos prácticos. Por ejemplo, dominar las canalizaciones de datos con ETL y ELT en Python puede elevar tu capacidad de procesar y transformar datos con eficacia. Del mismo modo, una sólida comprensión de los Conceptos de Gestión de Datos mejorará tu forma de estructurar y manejar los conjuntos de datos. Y para asegurarte de que tus resultados son fiables, es imprescindible comprender los principios que se enseñan en el curso Introducción a la Calidad de los Datos.
Aprende más sobre AWS con estos cursos
programa
Curso
Curso
blog
Joleen Bothma
12 min
blog
Srujana Maddula
13 min
Tutorial
Tim Lu
Tutorial
Moez Ali
Tutorial
Anneleen Rummens