
Programa
Profissional de nuvem da AWS (CLF-C02)
10 h
Antes de integrar o AWS Lake Formation e o AWS Glue, verifique se você tem o seguinte:
Quando você tiver os pré-requisitos, basta seguir estas etapas:
A primeira etapa é implantar os principais recursos do AWS necessários para criar um data lake seguro antes de iniciar o processo de integração. O modelo do AWS CloudFormation ajuda a organizar e implementar todos os recursos necessários.
Use o modelo CloudFormation fornecido para criar uma pilha em sua conta do AWS. Essa pilha fornece os recursos essenciais necessários para os casos de uso descritos neste tutorial.
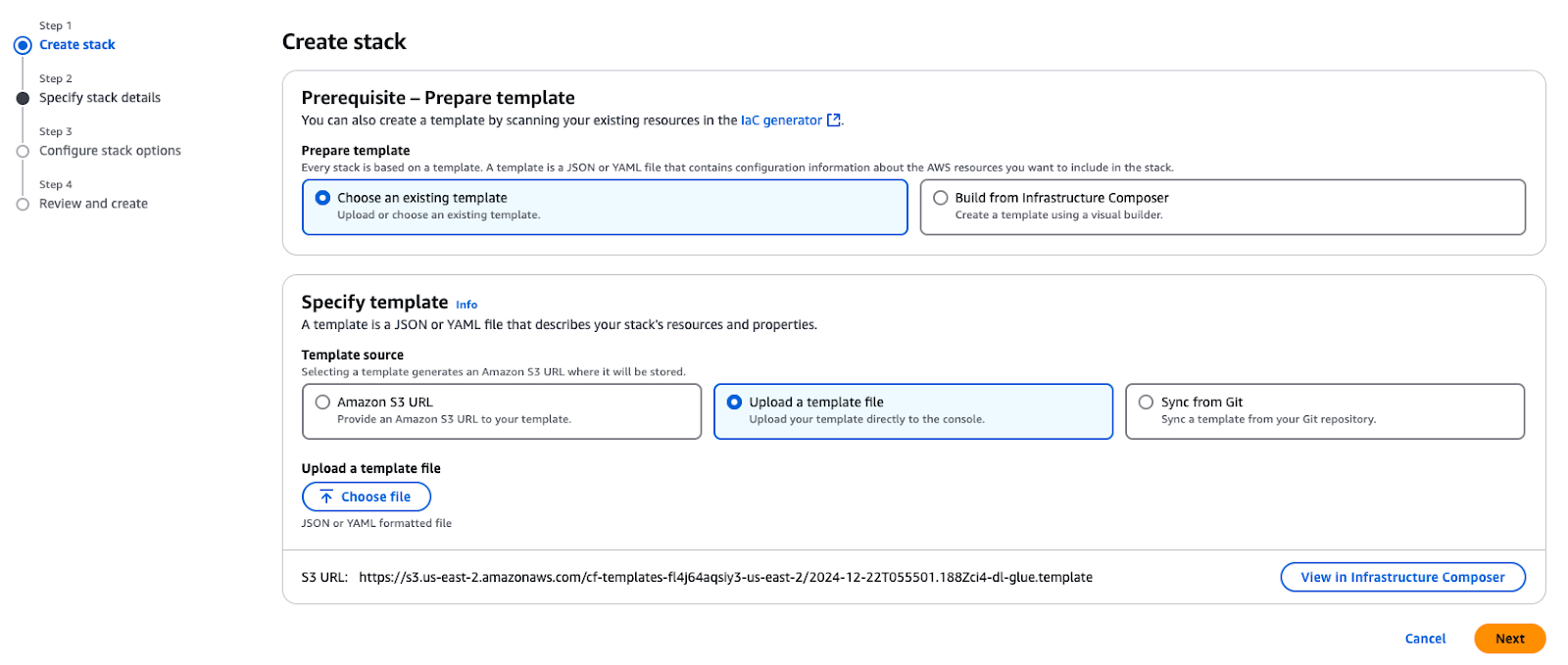
Criando uma pilha no AWS CloudFormation
Após a implantação da pilha, os seguintes recursos principais serão criados em sua conta do AWS:
GlueServiceRole: Concede ao AWS Glue acesso aos serviços S3 e Lake Formation.DataEngineerGlueServiceRole: Fornece aos engenheiros permissões para acesso e processamento de dados.DataAdminUser e DataEngineerUser: Usuários IAM pré-configurados para explorar e gerenciar a segurança do Lake Formation.EC2-DB-Loader) para pré-carregamento e transferência de dados de amostra para o S3.lf-users-credentials) para armazenar com segurança as credenciais de usuário para os usuários IAM pré-criados.Depois que a pilha for criada, você terá o seguinte:
Nesta seção, o administrador do Data Lake configurará o AWS Lake Formation para torná-lo disponível para personas de consumidores de dados, incluindo os engenheiros de dados. O administrador irá:
Essas configurações fornecem controle de acesso seguro e refinado e coordenação suave com outros serviços da AWS.
Um administrador do Data Lake é um usuário ou função de gerenciamento de identidade e acesso (IAM) que pode conceder permissão a qualquer princípio (incluindo ele próprio) em qualquer entidade do Data Catalog. O administrador do Data Lake geralmente é o primeiro usuário criado para gerenciar o Data Catalog e, normalmente, é o usuário que recebe privilégios administrativos para o Data Catalog.
No serviço AWS Lake Formation, você pode abrir o prompt clicando na guia Funções e tarefas administrativas -> Adicionar administradores no botão do painel de navegação e, em seguida, selecionando o usuário IAM lf-data-admin na lista suspensa.
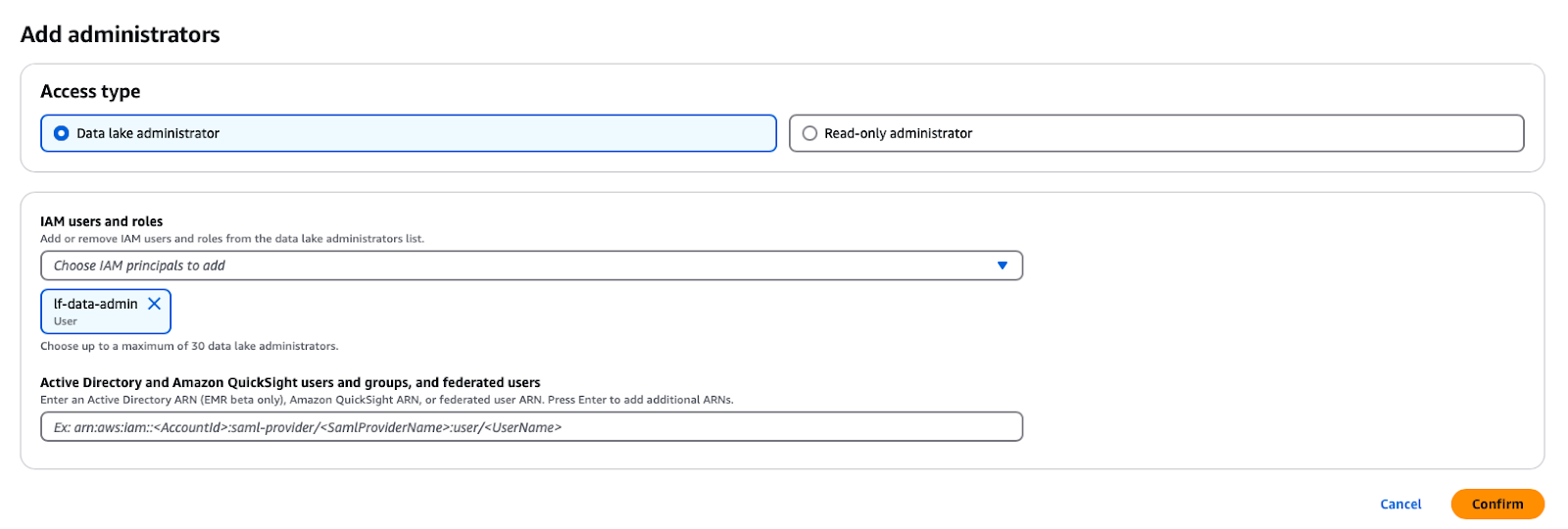
Como adicionar um administrador de data lake no AWS Lake Formation
Por padrão, o Lake Formation tem a opção "Use only IAM access control" (Usar somente controle de acesso IAM), que é selecionada para ser compatível com o AWS Glue Data Catalog. Para ativar o controle de acesso refinado com permissões do Lake Formation, você precisa ajustar essas configurações:
IAMAllowedPrincipals aparecer em Criadores de banco de dadosselecione o grupo e escolha Revogar.Essas etapas desativarão o controle de acesso padrão do IAM e permitirão que você implemente as permissões do Lake Formation para aumentar a segurança.
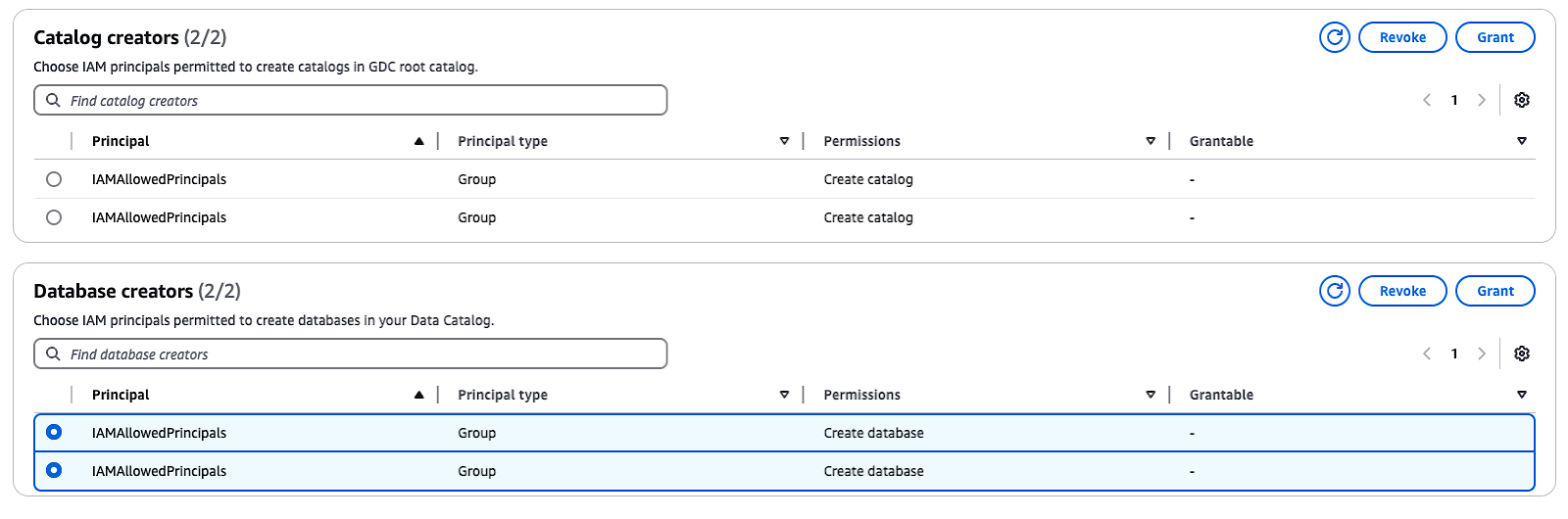
Gerenciando criadores de catálogos e bancos de dados no AWS Lake Formation
Agora, é hora de você usar o Glue Data Catalog.
Para criar um banco de dados para os dados do TPC, faça logout da sua sessão atual do AWS e faça login novamente como o usuário lf-data-admin. Use o link de login fornecido na saída do CloudFormation e a senha recuperada do AWS Secrets Manager.
lf-data-lake-account-ID, em que account-ID é o número da sua conta AWS de 12 dígitos.Esse banco de dados será a base para armazenar e gerenciar metadados para os dados de TPC na configuração da Formação do Lago.
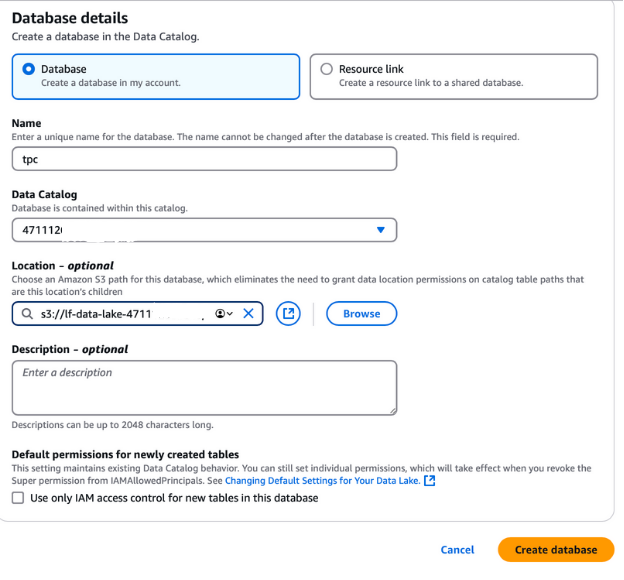
Criação de um banco de dados no AWS Lake Formation
Usamos um AWS Glue Crawler para criar tabelas no AWS Glue Data Catalog. Os rastreadores são a maneira mais comum de criar tabelas no AWS Glue, pois eles podem fazer a varredura em vários armazenamentos de dados de uma só vez e gerar ou atualizar os detalhes das tabelas no catálogo de dados após a conclusão do rastreamento.
Antes de executar o AWS Glue Crawler, você precisa conceder as permissões necessárias à sua função IAM:
tpc banco de dados.LF-GlueServiceRole.tpc como o banco de dados.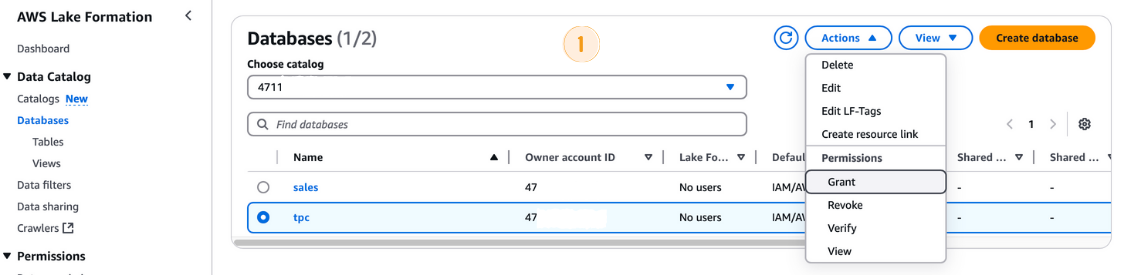
Concessão de permissões na AWS Lake Formation
Com as permissões concedidas, prossiga para executar o rastreador:
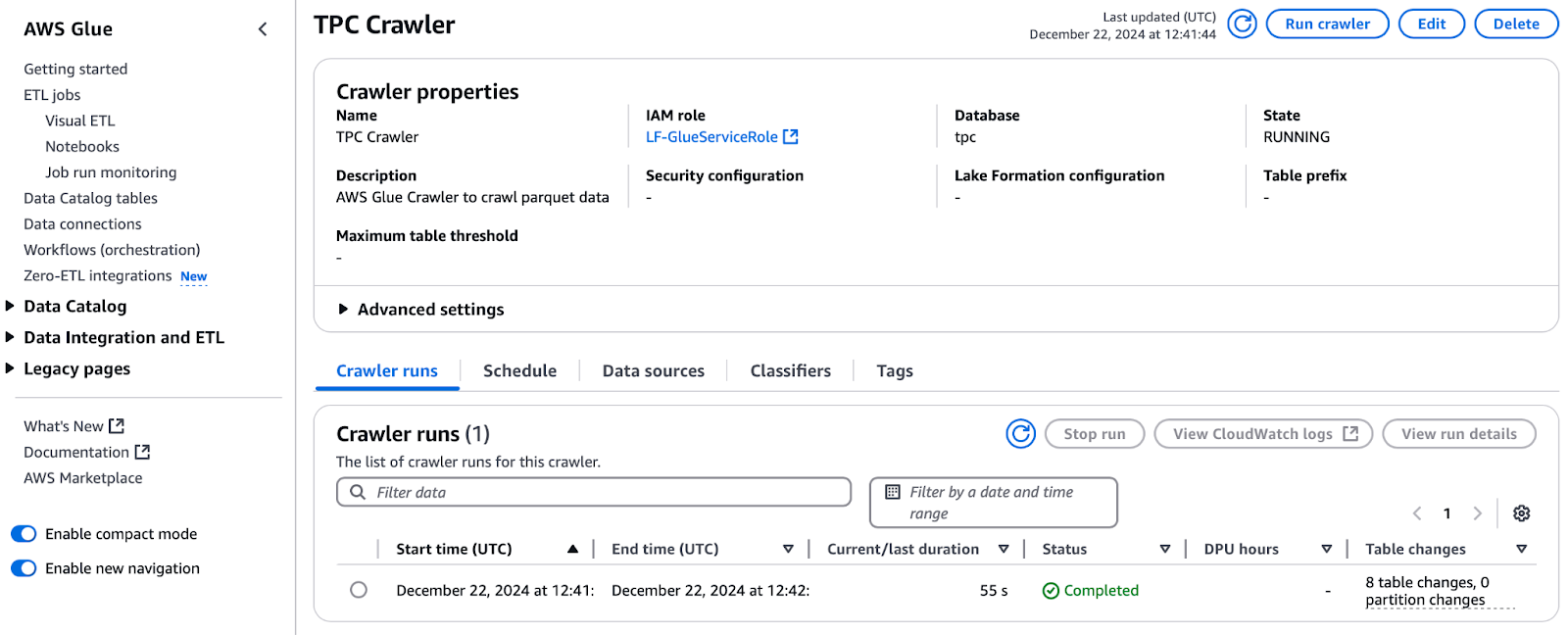
Executando o rastreador TPC no AWS Glue
Você também pode verificar essas tabelas no console do AWS Lake Formation em Catálogo de dados e Tabelas.
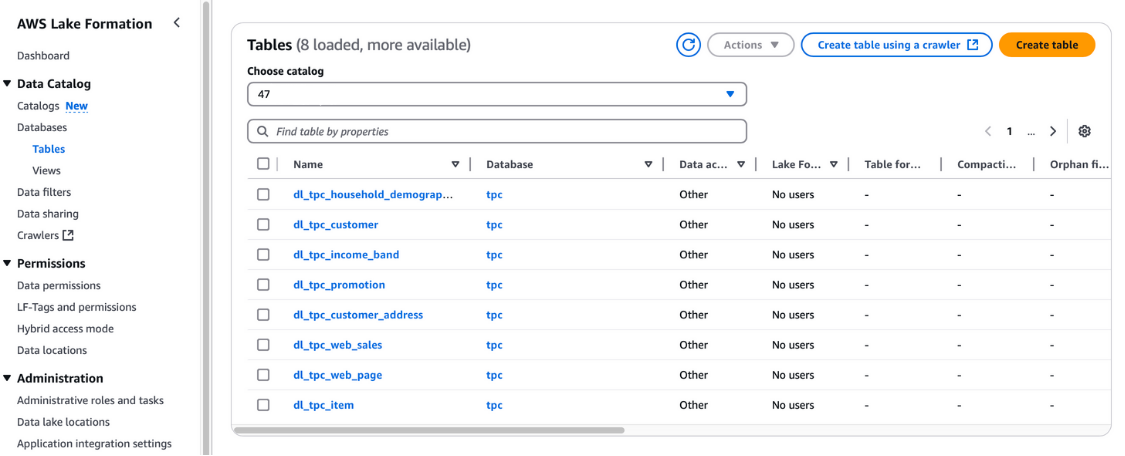
Exibição de tabelas na AWS Lake Formation
Você deve registrar o bucket S3 no AWS Lake Formation para o armazenamento do seu data lake. Esse registro permite que você imponha um controle de acesso refinado aos objetos do AWS Glue Data Catalog e aos dados subjacentes armazenados no bucket.
Etapas para registrar um local do Data Lake:
LF-GlueServiceRole criado pelo modelo do CloudFormation.Depois de registrado, verifique o local do data lake para garantir que ele esteja configurado corretamente. Essa etapa é essencial para o gerenciamento de dados e a segurança contínuos em sua configuração do Lake Formation.
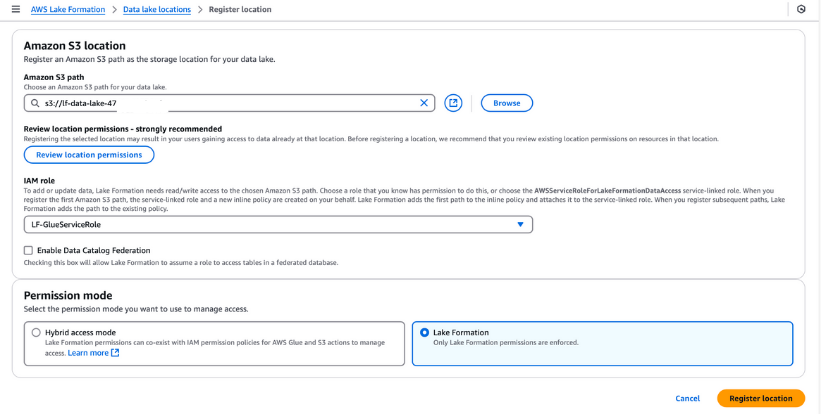
Registro de um local do Amazon S3 no AWS Lake Formation
Os LF-Tags podem ser usados para organizar recursos e definir permissões em muitos recursos de uma só vez. Ele permite que você organize os dados usando taxonomias e, dessa forma, divida políticas complexas e gerencie permissões de forma eficaz. Isso é possível porque, com os LF-Tags, você pode separar a política do recurso e, portanto, pode configurar políticas de acesso antes mesmo de os recursos serem criados.
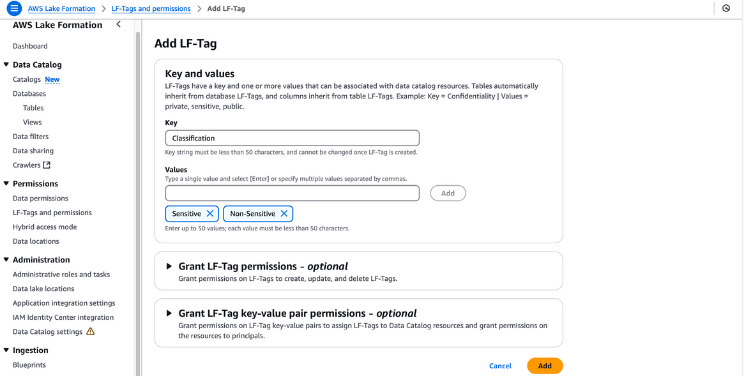
Criação de LF-Tags no AWS Lake Formation
lf-data-admin tenha permissões de LF-Tag. Navegue até Tabelas no console Lake Formation.dl_tpc_customer, clique no botão ações e escolha Conceder.lf-data-admin.tpc e a tabela dl_tpc_customer, concedendo a você as permissões da tabelaAlter. Clique em Conceder.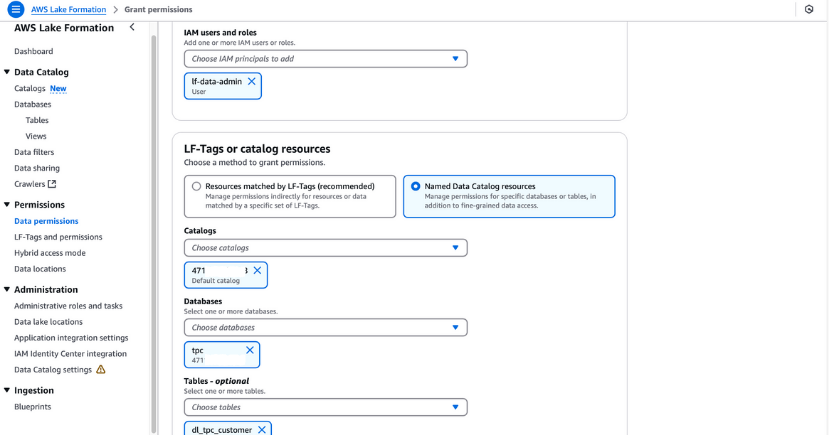
Concessão de permissões na AWS Lake Formation
dl_tpc_customer. Abra os detalhes da tabela e selecione Editar LF-Tags no menu de ações.c_first_name, c_last_name e c_email_address e clique em Editar LF-Tags.Classification, altere o valor para "Sensitive" (Sensível) e clique em Save. Salve essa configuração como uma nova versão.dl_tpc_household_demographics, vá para Ações e selecione Editar LF-Tags.Seguindo essas etapas, você pode atribuir LF-Tags com eficiência aos seus objetos do Data Catalog, garantindo um controle de acesso seguro e refinado em todo o seu data lake.
O AWS Glue Studio é uma interface de usuário de arrastar e soltar que ajuda os usuários a desenvolver, depurar e monitorar trabalhos de ETL para o AWS Glue. Os engenheiros de dados utilizam o Glue ETL, baseado no Apache Spark, para transformar conjuntos de dados armazenados no Amazon S3 e carregar dados em data lakes e warehouses para análise. Para administrar efetivamente o acesso quando várias equipes colaboram nos mesmos conjuntos de dados, é importante fornecer acesso e restringi-lo de acordo com as funções.
Siga estas etapas para conceder as permissões necessárias ao usuário lf-data-engineer e à função DE-GlueServiceRole correspondente. Essa função é usada pelo engenheiro de dados para acessar as tabelas do Glue Data Catalog nos trabalhos do Glue Studio.
lf-data-admin para fazer login no Console de gerenciamento do AWS. Recupere a senha do AWS Secrets Manager e o URL de login da saída do CloudFormation.lf-data-engineer e DE-GlueServiceRole.tpc.dl_tpc_household_demographics.DE-GlueServiceRole.tpc (deixe as tabelas desmarcadas).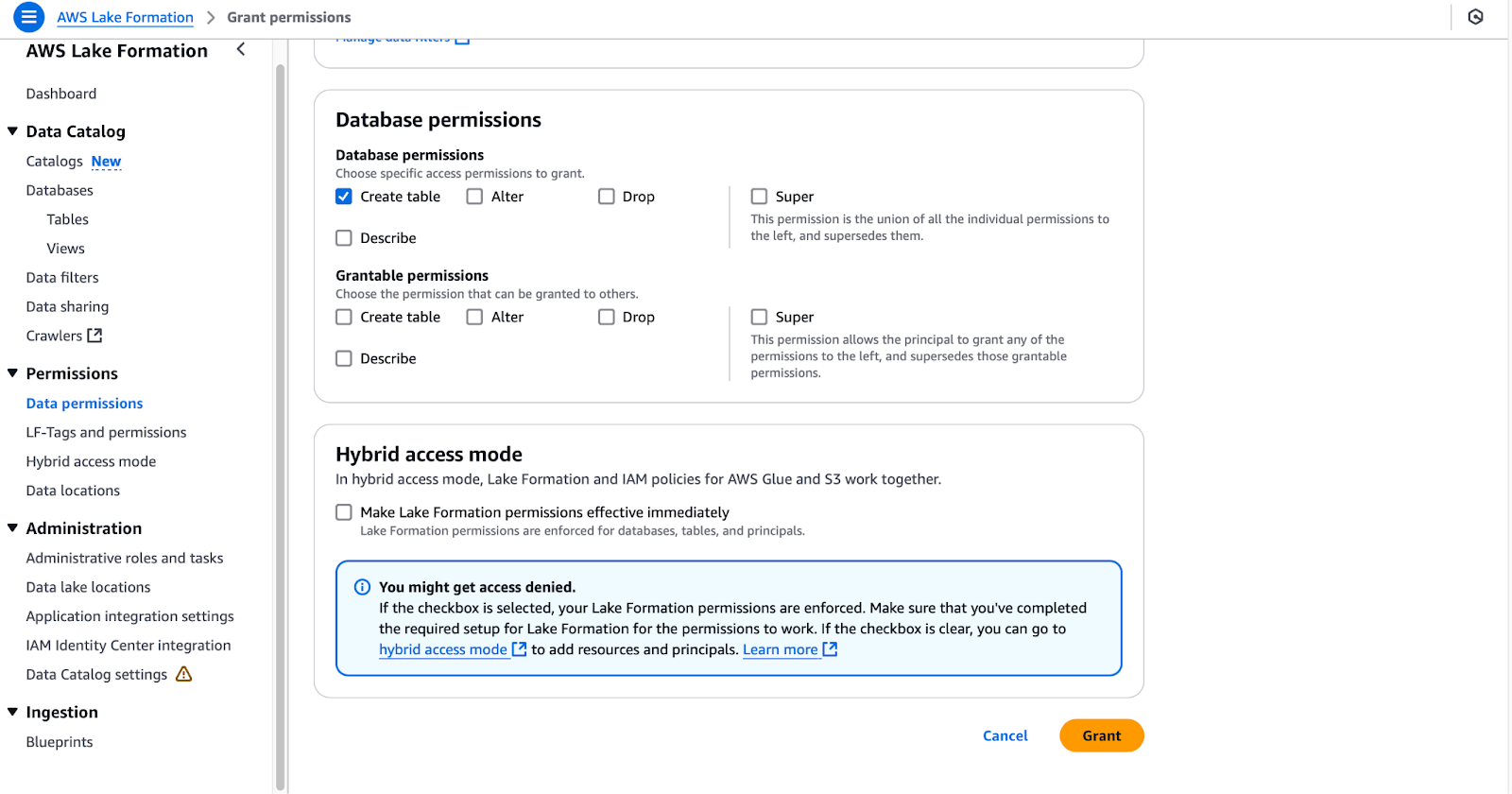
Configuração de permissões de banco de dados no AWS Lake Formation
A conclusão dessas etapas dará ao usuário lf-data-engineer e à função DE-GlueServiceRole as permissões necessárias para trabalhar com as tabelas do Glue Data Catalog e gerenciar recursos nos trabalhos do Glue Studio. Essa configuração garante o acesso seguro e baseado em funções ao seu data lake.
Nesta seção, criaremos um trabalho de ETL no AWS Glue Studio usando o SQL Transform.
lf-data-engineer:
lf-data-engineer para fazer login no Console de gerenciamento do AWS. Recupere a senha do AWS Secrets Manager e o URL de login fornecido pela saída do CloudFormation.LF_GlueStudio para que ele possa ser identificado facilmente.DE-GlueServiceRole.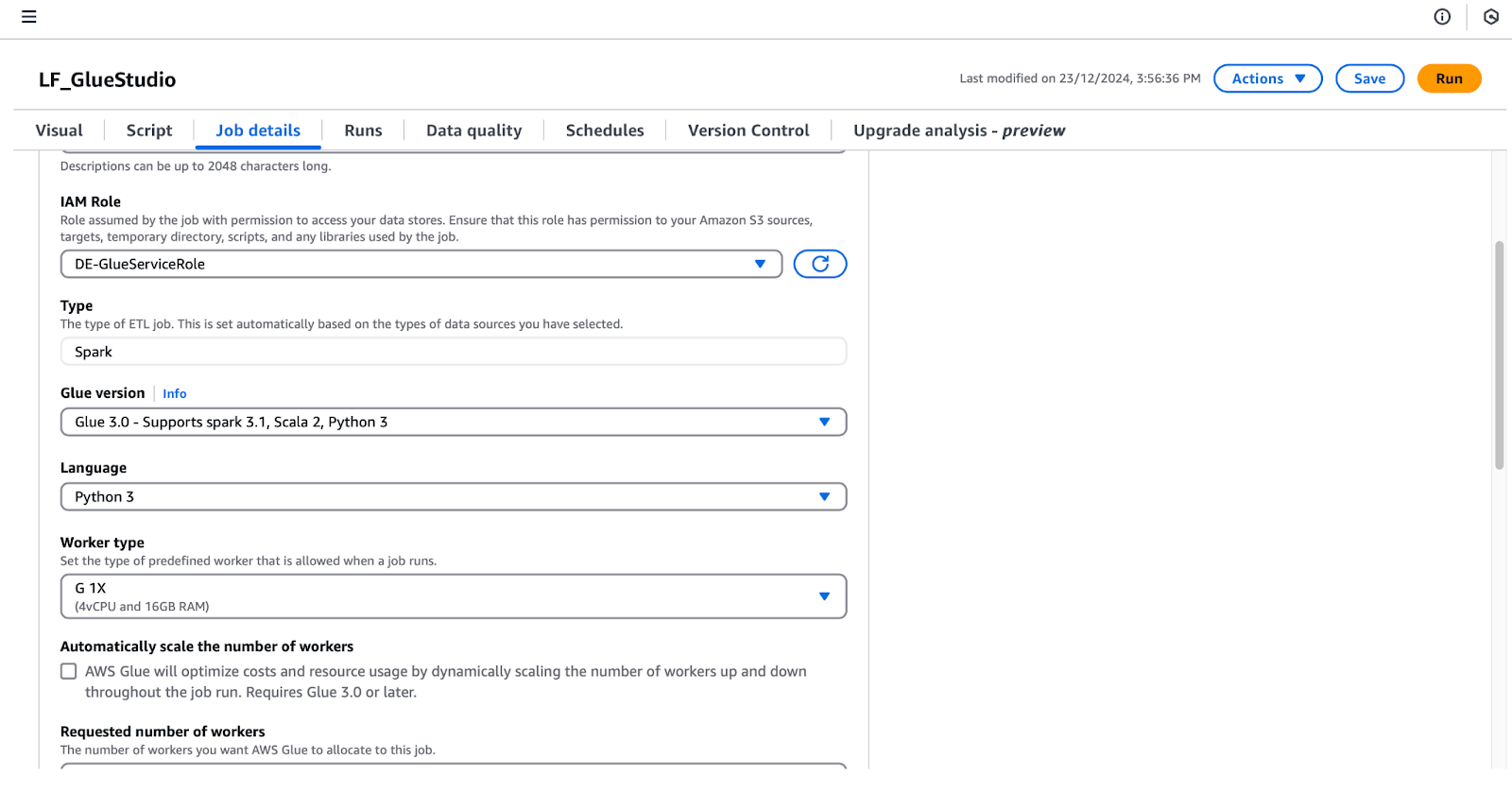
Configuração dos detalhes do trabalho no AWS Glue Studio
tpc.dl_tpc_household_demographics. (Nota: O usuário lf-data-admin concedeu apenas a permissão lf-data-engineer Select nessa tabela. Outras tabelas não aparecerão no menu suspenso).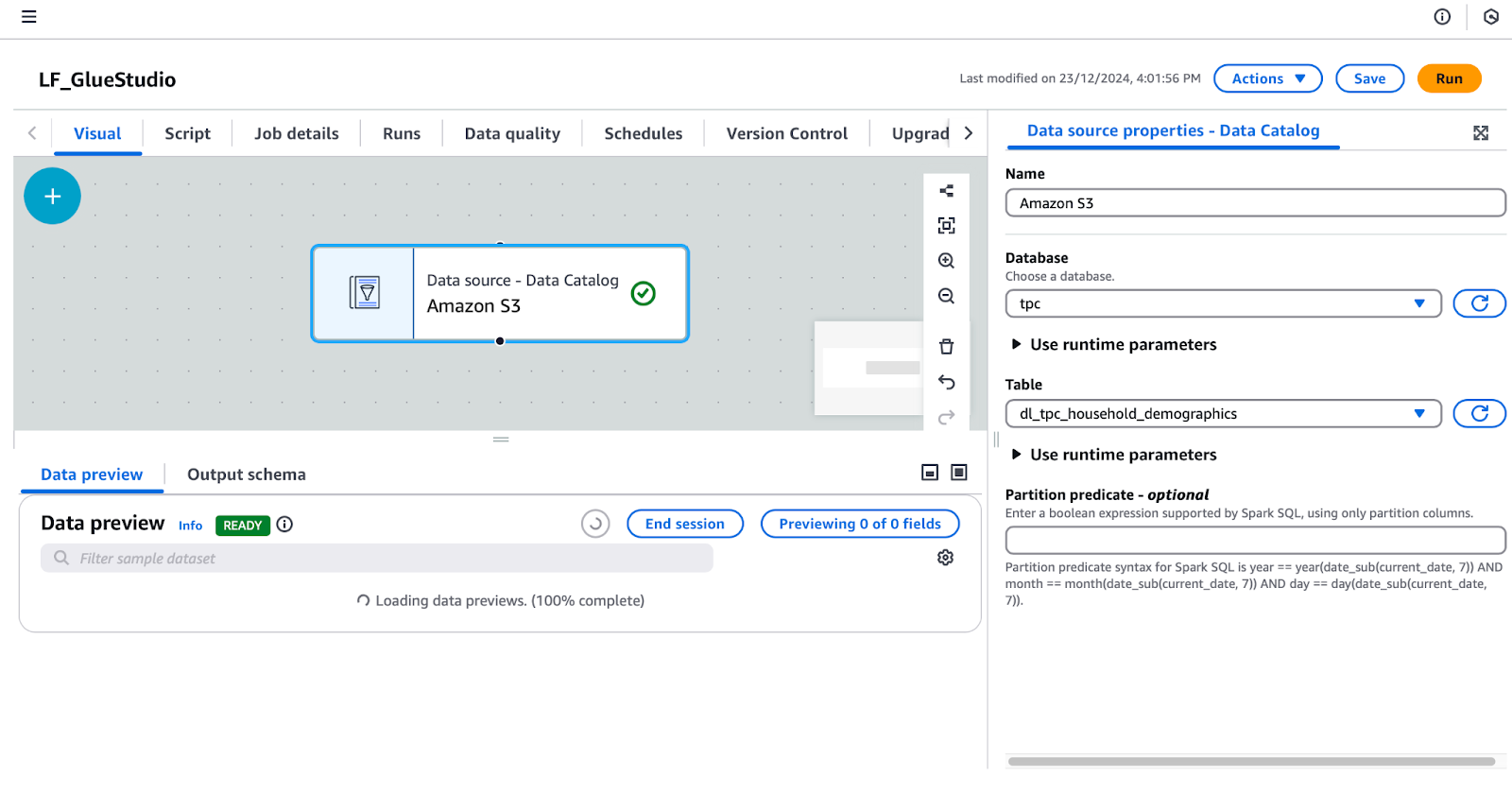
Configuração de uma fonte de dados no AWS Glue Studio
/* Select all records where buy potential is between 0 and 500 */
SELECT *
FROM myDataSource
WHERE hd_buy_potential = '0-500';hd_dep_count e hd_vehicle_count. Clique em Aplicar.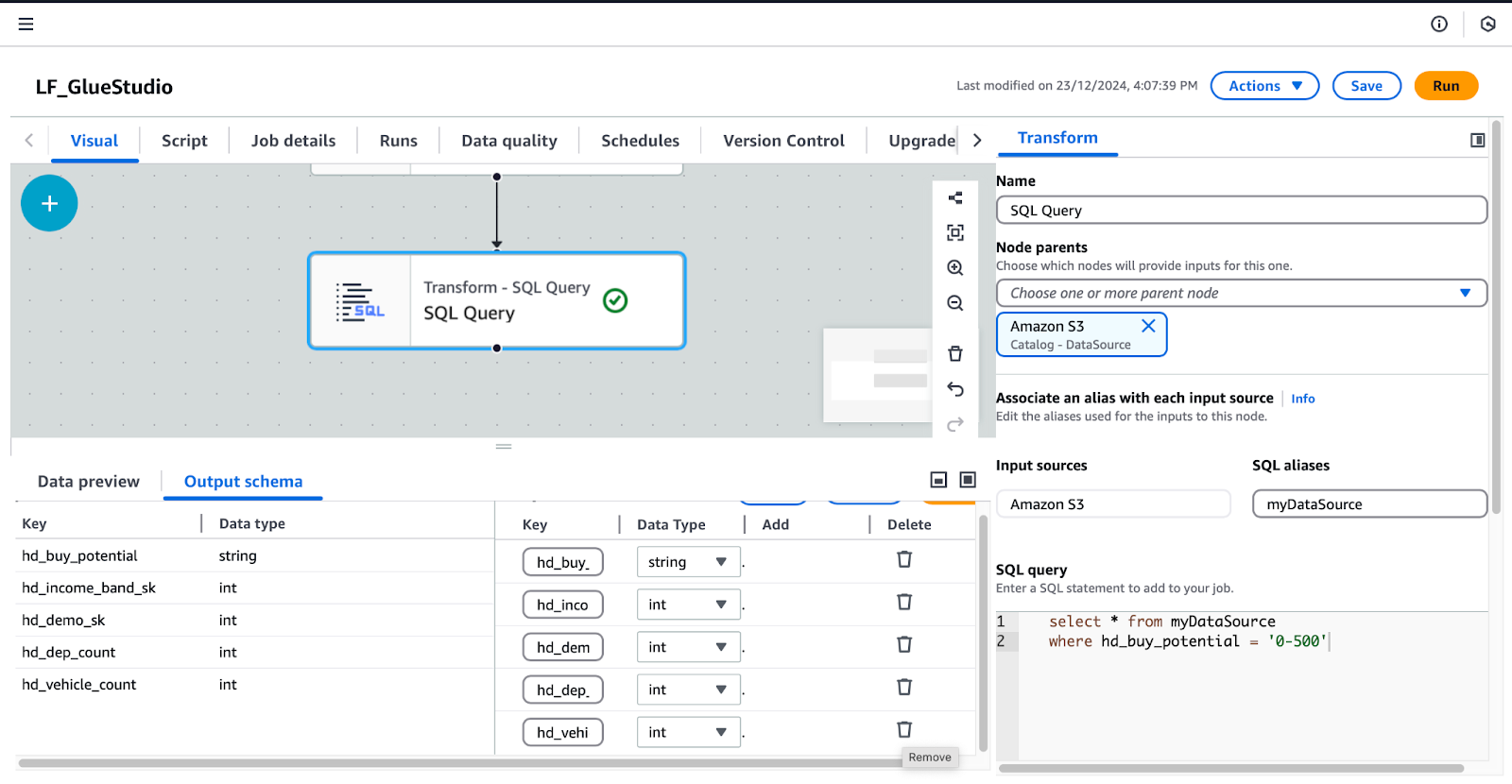
Configuração da transformação de consulta SQL no AWS Glue Studio
s3:///gluestudio/curated/. (Substitua tpc .dl_tpc_household_demographics_below500.Seguindo essas etapas, você criará um trabalho de ETL do Glue Studio totalmente funcional que transforma dados e grava os resultados em uma pasta S3 selecionada enquanto atualiza o Glue Data Catalog.
Para confirmar as permissões concedidas no Lake Formation, siga estas etapas enquanto estiver conectado como o usuário lf-data-engineer (conforme detalhado em Criar trabalhos do Glue Studio ):
LF_GlueStudio: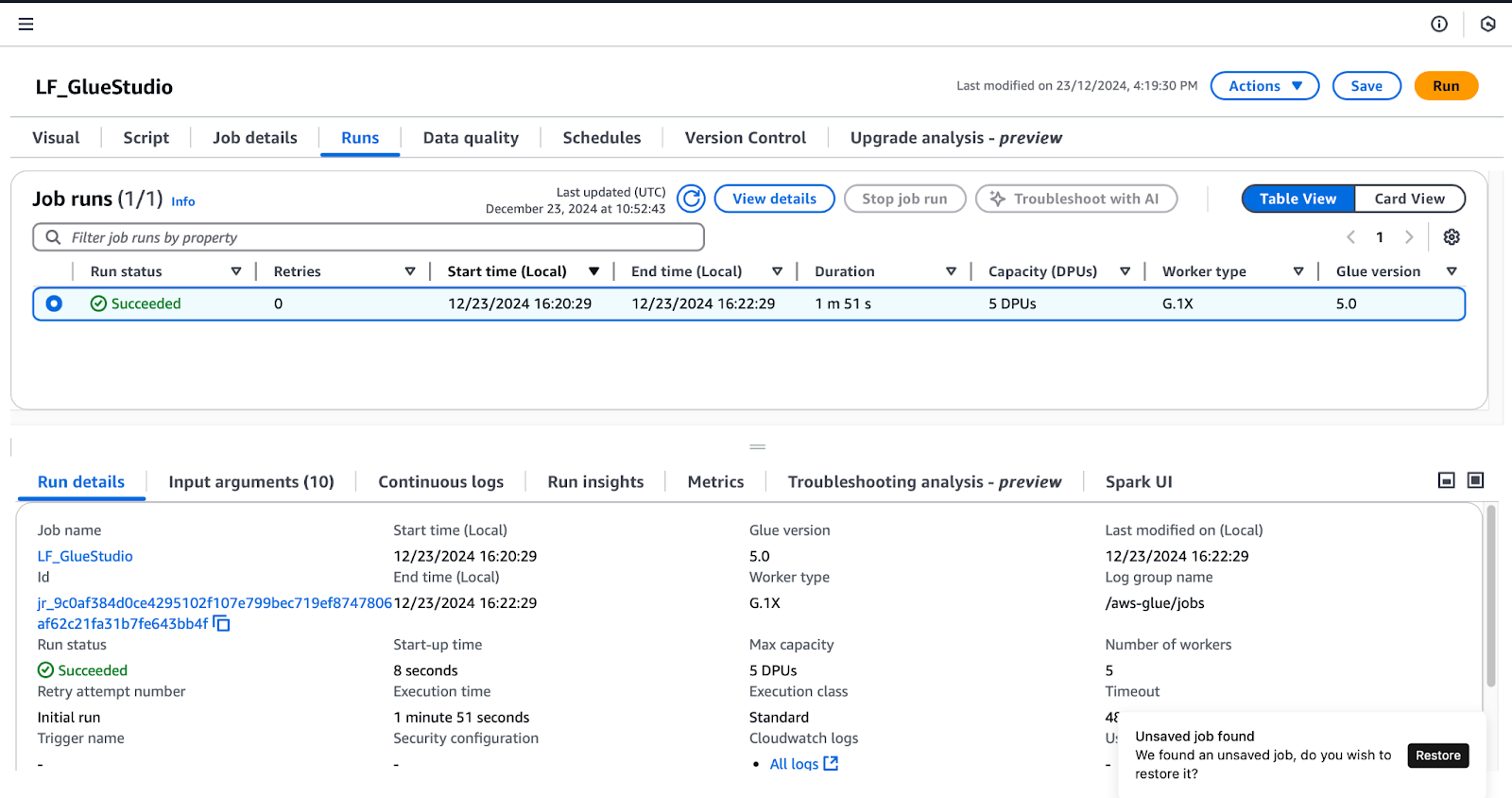
Monitoramento de execuções de trabalho no AWS Glue Studio
curated no seu bucket S3 para verificar os arquivos de saída. Esses arquivos devem estar no formato Parquet, conforme configurado durante a criação do trabalho.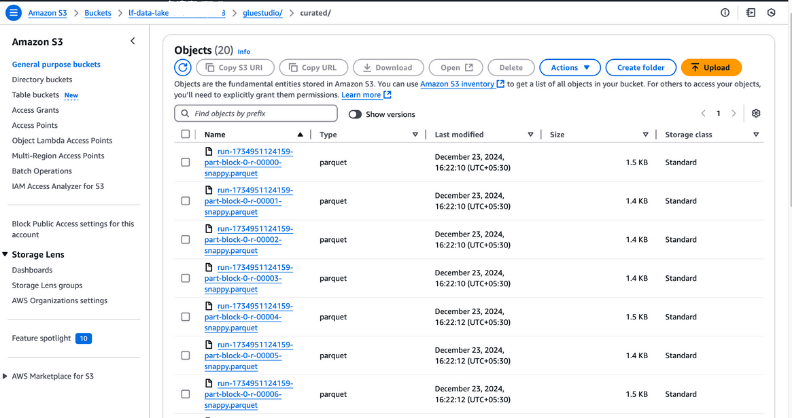
Visualização de arquivos de saída no Amazon S3
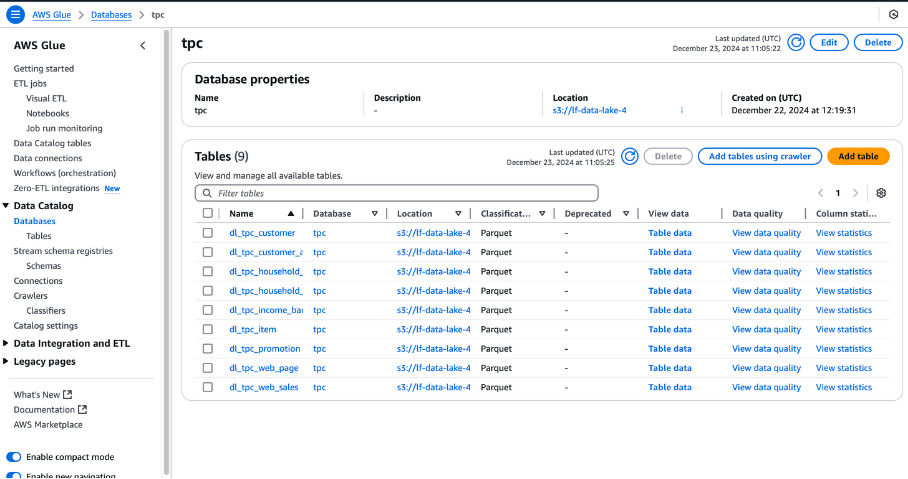
Visualização de tabelas de banco de dados no AWS Glue
Ao integrar o AWS Lake Formation e o AWS Glue, você pode aprimorar a segurança dos dados, simplificar as operações e otimizar o desempenho seguindo as práticas recomendadas. Veja como você pode aproveitar ao máximo esses serviços:

Eventos de registro do TPC Crawler no AWS CloudWatch

Monitoramento das métricas de trabalho do AWS Glue Studio
A implementação do AWS Lake Formation e do AWS Glue ajuda a organização a organizar, proteger e processar dados. Usando as amplas medidas de segurança do Lake Formation e a automação do Glue, você pode otimizar seus processos de ETL, atender a todas as políticas relacionadas à governança de dados e fornecer acesso fácil aos dados para os usuários, incluindo engenheiros e cientistas de dados.
Os benefícios incluem:
À medida que você aprofunda seu conhecimento sobre integração de dados, é essencial complementar seu aprendizado com conhecimento prático. Por exemplo, o domínio de pipelines de dados com ETL e ELT em Python pode aumentar sua capacidade de processar e transformar dados com eficiência. Da mesma forma, uma sólida compreensão dos conceitos de gerenciamento de dados aprimorará a forma como você estrutura e manipula os conjuntos de dados. E para garantir que seus resultados sejam confiáveis, é essencial que você compreenda os princípios ensinados no curso Introdução à qualidade dos dados.
Saiba mais sobre a AWS com estes cursos!
Programa
Curso
Curso
blog
Srujana Maddula
13 min
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Tim Lu