
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
Avant d'intégrer AWS Lake Formation et AWS Glue, assurez-vous que vous disposez des éléments suivants :
Une fois que vous disposez des conditions préalables, il vous suffit de suivre les étapes suivantes :
La première étape consiste à déployer les ressources AWS de base nécessaires pour construire un lac de données sécurisé avant de commencer le processus d'intégration. Le modèle AWS CloudFormation permet d'organiser et de déployer toutes les ressources nécessaires.
Utilisez le modèle CloudFormation fourni pour créer une pile dans votre compte AWS. Cette pile fournit les ressources essentielles requises pour les cas d'utilisation décrits dans ce tutoriel.
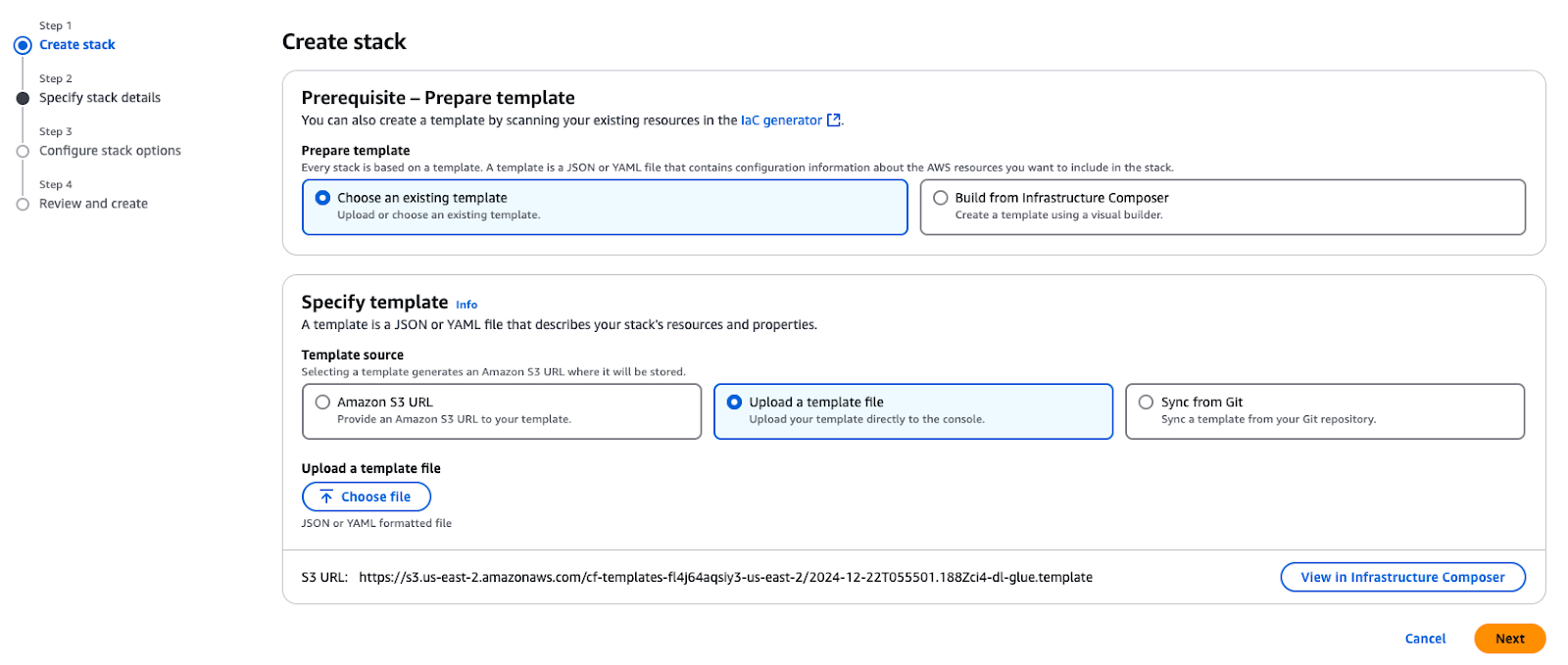
Création d'une pile dans AWS CloudFormation
Lors du déploiement de la pile, les ressources clés suivantes seront créées dans votre compte AWS :
GlueServiceRole: Permet à AWS Glue d'accéder aux services S3 et Lake Formation.DataEngineerGlueServiceRole: Fournit aux ingénieurs des autorisations pour l'accès et le traitement des données.DataAdminUser et DataEngineerUser: Utilisateurs IAM préconfigurés pour explorer et gérer la sécurité de Lake Formation.EC2-DB-Loader) pour le préchargement et le transfert des données de l'échantillon dans S3.lf-users-credentials) pour stocker en toute sécurité les informations d'identification des utilisateurs IAM précréés.Une fois la pile créée, vous disposerez des éléments suivants :
Dans cette section, l'administrateur du lac de données configurera AWS Lake Formation afin de le rendre disponible pour les personas de consommateurs de données, y compris les ingénieurs de données. L'administrateur devra :
Ces configurations permettent un contrôle d'accès sécurisé et précis, ainsi qu'une coordination harmonieuse avec d'autres services AWS.
Un administrateur de lac de données est un utilisateur ou un rôle de gestion des identités et des accès (IAM) qui peut donner à n'importe quel principe (y compris lui-même) une permission sur n'importe quelle entité du catalogue de données. L'administrateur du lac de données est généralement le premier utilisateur créé pour gérer le catalogue de données et c'est généralement l'utilisateur qui se voit accorder des privilèges administratifs pour le catalogue de données.
Dans le service AWS Lake Formation, vous pouvez ouvrir l'invite en cliquant sur le bouton Rôles et tâches administratives -> Ajouter des administrateurs dans le panneau de navigation, puis en sélectionnant l'utilisateur IAM lf-data-admin dans la liste déroulante.
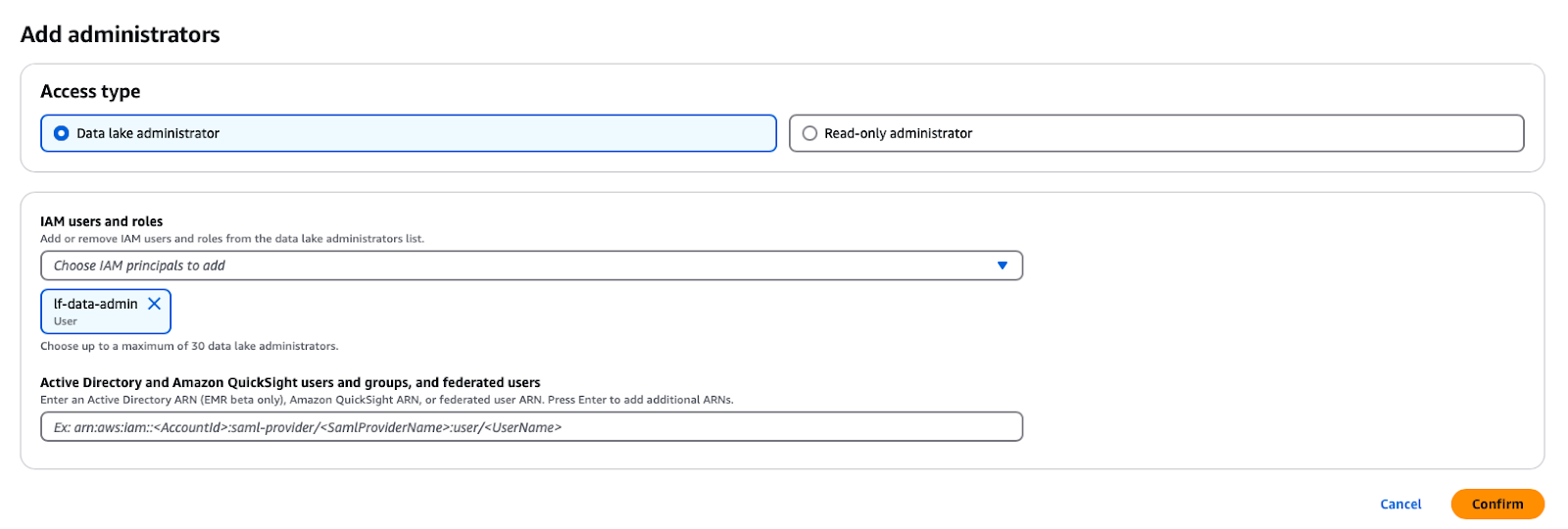
Ajout d'un administrateur de lac de données dans AWS Lake Formation
Par défaut, Lake Formation dispose de l'option "Utiliser uniquement le contrôle d'accès IAM", qui est sélectionnée pour être compatible avec le catalogue de données AWS Glue. Pour permettre un contrôle d'accès précis avec les autorisations de la formation en lac, vous devez ajuster ces paramètres :
IAMAllowedPrincipals apparaît sous Créateurs de base de donnéessélectionnez le groupe et choisissez Révoquer.Ces étapes désactiveront le contrôle d'accès IAM par défaut et vous permettront de mettre en œuvre les autorisations de Lake Formation pour une sécurité accrue.
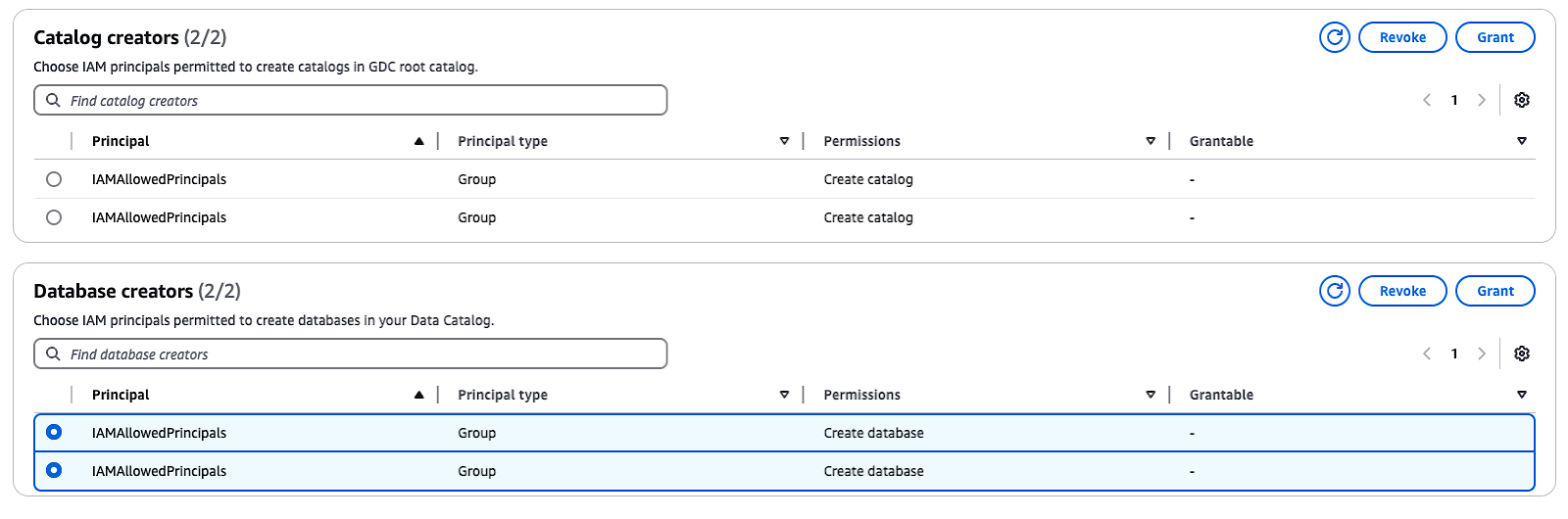
Gestion des créateurs de catalogues et de bases de données dans AWS Lake Formation
Il est maintenant temps d'utiliser le catalogue de données Glue.
Pour créer une base de données pour les données PTC, déconnectez-vous de votre session AWS actuelle et reconnectez-vous en tant qu'utilisateur lf-data-admin. Utilisez le lien de connexion fourni dans la sortie CloudFormation et le mot de passe récupéré dans AWS Secrets Manager.
lf-data-lake-account-ID, où account-ID est votre numéro de compte AWS à 12 chiffres.Cette base de données servira de fondement au stockage et à la gestion des métadonnées pour les données du PTC dans la configuration de la formation lacustre.
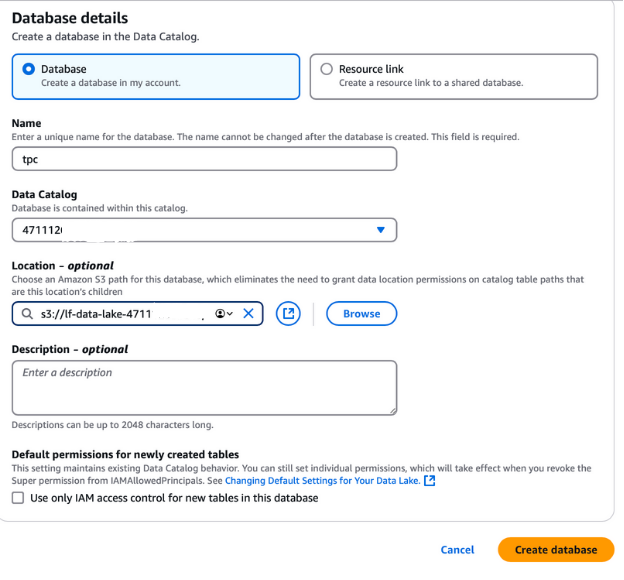
Création d'une base de données dans AWS Lake Formation
Nous utilisons un crawler AWS Glue pour créer des tableaux dans le catalogue de données AWS Glue. Les crawlers sont le moyen le plus courant de créer des tableaux dans AWS Glue, car ils peuvent parcourir plusieurs magasins de données à la fois et générer ou mettre à jour les détails des tableaux dans le catalogue de données une fois le crawl effectué.
Avant d'exécuter AWS Glue Crawler, vous devez accorder les autorisations nécessaires à son rôle IAM :
tpc base de données.LF-GlueServiceRole.tpc comme base de données.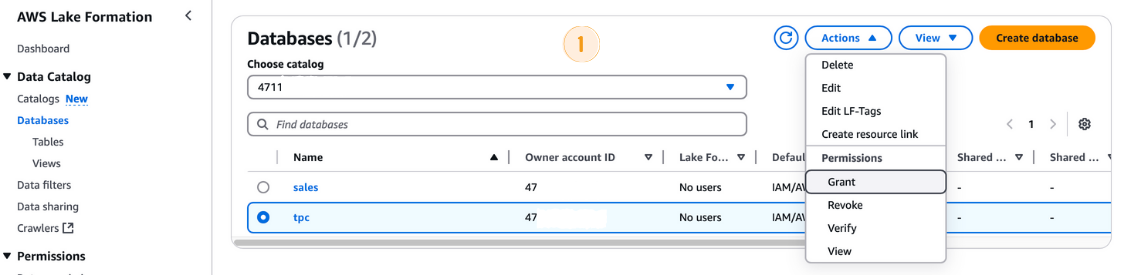
Octroi de permissions dans la formation AWS Lake
Une fois les autorisations accordées, procédez à l'exécution du crawler :
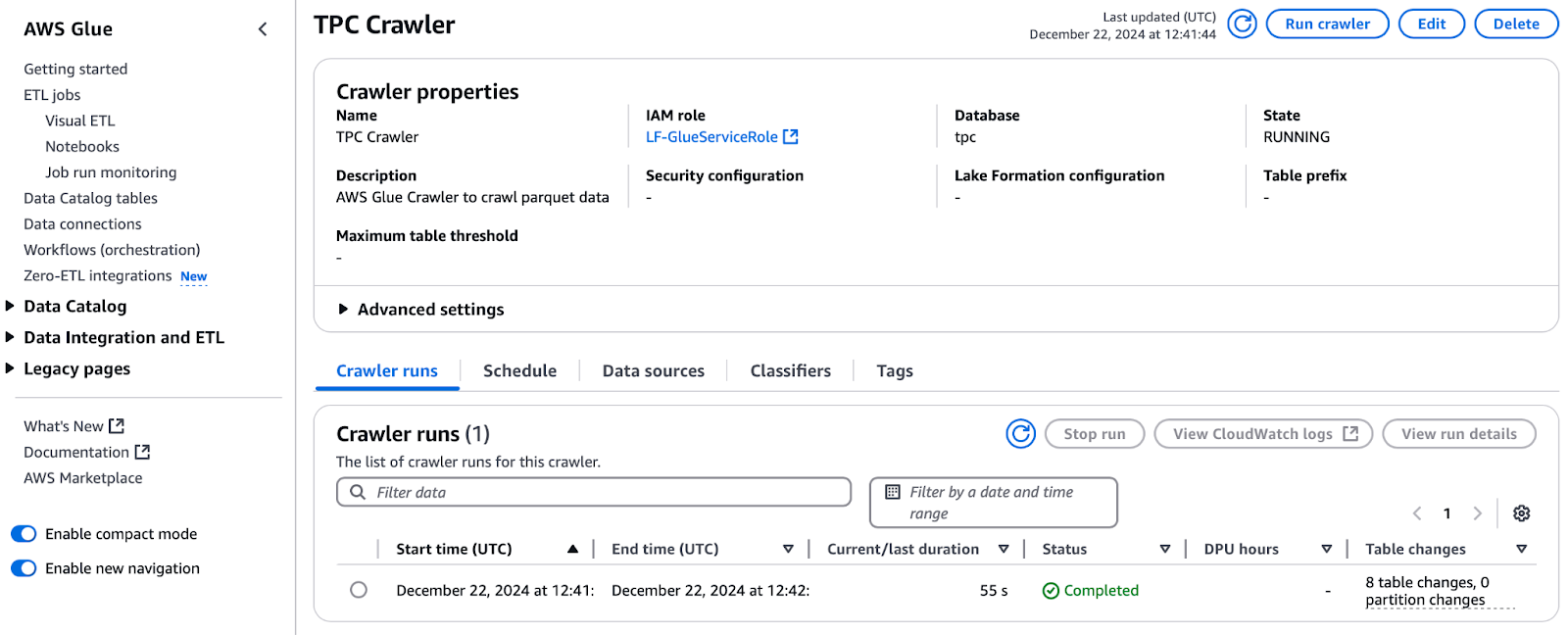
Exécuter le Crawler TPC dans AWS Glue
Vous pouvez également vérifier ces tableaux dans la console AWS Lake Formation, à la rubrique Catalogue de données et Tableaux.
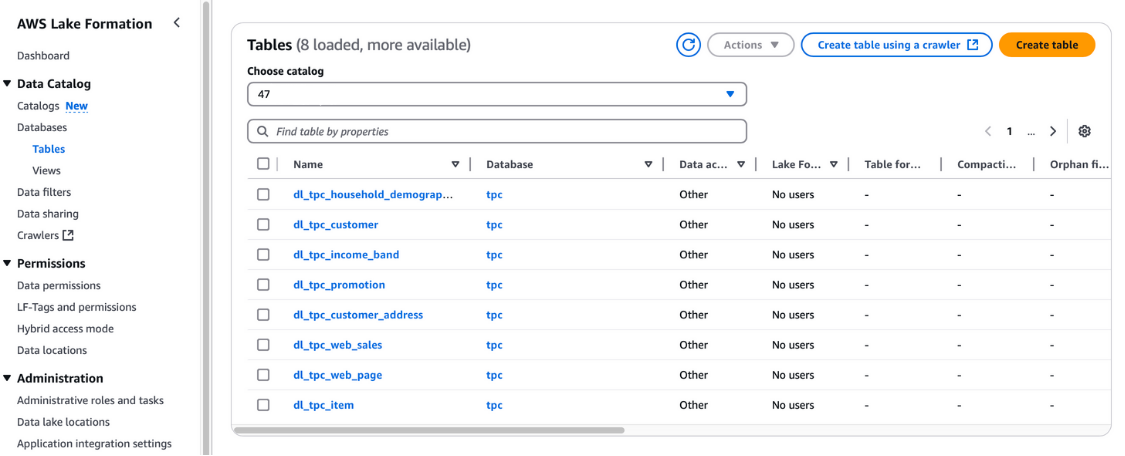
Visualisation des tableaux dans la formation du lac AWS
Vous devez enregistrer le seau S3 dans AWS Lake Formation pour votre stockage dans le lac de données. Cet enregistrement vous permet d'appliquer un contrôle d'accès précis aux objets du catalogue de données AWS Glue et aux données sous-jacentes stockées dans le seau.
Marche à suivre pour enregistrer un site Data Lake :
LF-GlueServiceRole créé par le modèle CloudFormation.Une fois enregistré, vérifiez l'emplacement de votre lac de données pour vous assurer qu'il est correctement configuré. Cette étape est essentielle pour une gestion des données et une sécurité sans faille dans votre configuration de Lake Formation.
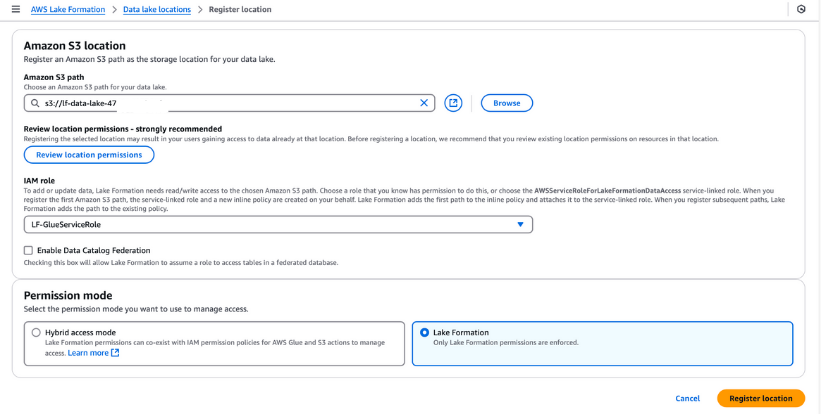
Enregistrement d'un emplacement Amazon S3 dans AWS Lake Formation
Les étiquettes LF peuvent être utilisées pour organiser les ressources et définir les autorisations dans de nombreuses ressources à la fois. Il vous permet d'organiser les données à l'aide de taxonomies, de décomposer des politiques complexes et de gérer les autorisations de manière efficace. Cela est possible parce qu'avec les balises LF, vous pouvez séparer la politique de la ressource et, par conséquent, vous pouvez mettre en place des politiques d'accès avant même que les ressources ne soient créées.
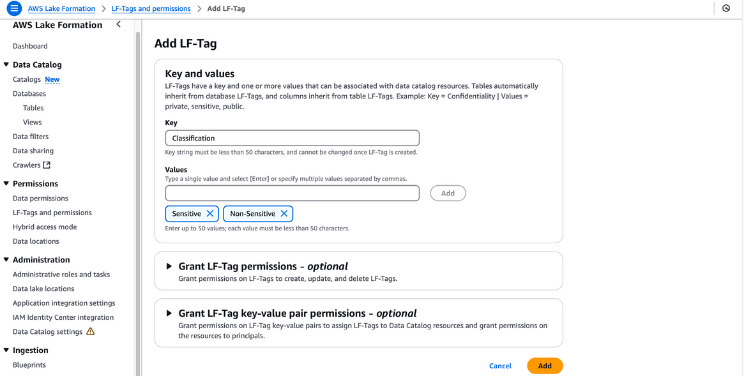
Création de balises LF dans la formation des lacs AWS
lf-data-admin dispose des autorisations LF-Tag. Naviguez vers Tableaux dans la console Formation lacustre.dl_tpc_customer, cliquez sur le bouton actions et choisissez Accorder.lf-data-admin.tpc et le tableau dl_tpc_customer, en accordant les droits d'accès au tableauAlter. Cliquez Accorder.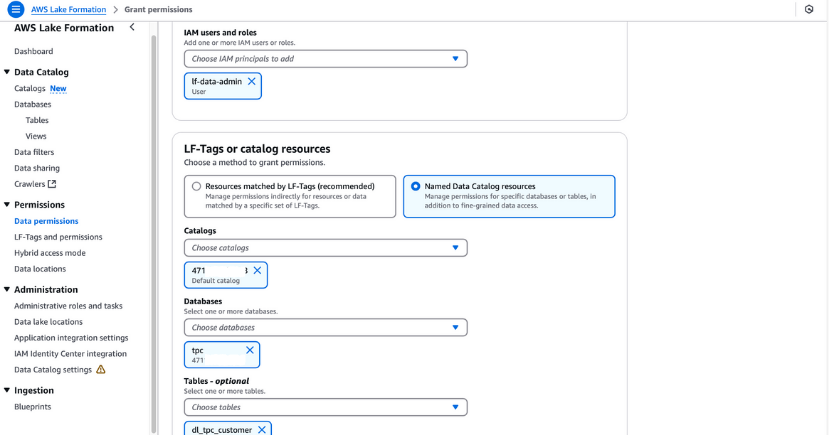
Octroi de permissions dans la formation AWS Lake
dl_tpc_customer. Ouvrez les détails du tableau et sélectionnez Éditer les balises LF dans le menu des actions.c_first_name, c_last_name, et c_email_address, et cliquez sur Modifier les balises LF.Classification, changez la valeur en "Sensitive" et cliquez sur Save. Enregistrez cette configuration en tant que nouvelle version.dl_tpc_household_demographics, rendez-vous à l'adresse suivante Actions et choisissez Modifier les balises LF.En suivant ces étapes, vous pouvez assigner efficacement des LF-Tags à vos objets de catalogue de données, garantissant ainsi un contrôle d'accès sécurisé et précis à travers votre lac de données.
AWS Glue Studio est une interface utilisateur par glisser-déposer qui aide les utilisateurs à développer, déboguer et surveiller les tâches ETL pour AWS Glue. Les ingénieurs de données s'appuient sur Glue ETL, basé sur Apache Spark, pour transformer les ensembles de données stockés dans Amazon S3 et charger les données dans les lacs de données et les entrepôts à des fins d'analyse. Pour gérer efficacement l'accès lorsque plusieurs équipes collaborent sur les mêmes ensembles de données, il est important de fournir l'accès et de le restreindre en fonction des rôles.
Suivez ces étapes pour accorder les autorisations nécessaires à l'utilisateur lf-data-engineer et au rôle DE-GlueServiceRole correspondant. Ce rôle est utilisé par l'ingénieur des données pour accéder aux tableaux du catalogue de données Glue dans les travaux de Glue Studio.
lf-data-admin pour vous connecter à la console de gestion AWS. Récupérez le mot de passe depuis AWS Secrets Manager et l'URL de connexion depuis la sortie de CloudFormation.lf-data-engineer et DE-GlueServiceRole.tpc.dl_tpc_household_demographics.DE-GlueServiceRole.tpc (ne sélectionnez pas les tableaux).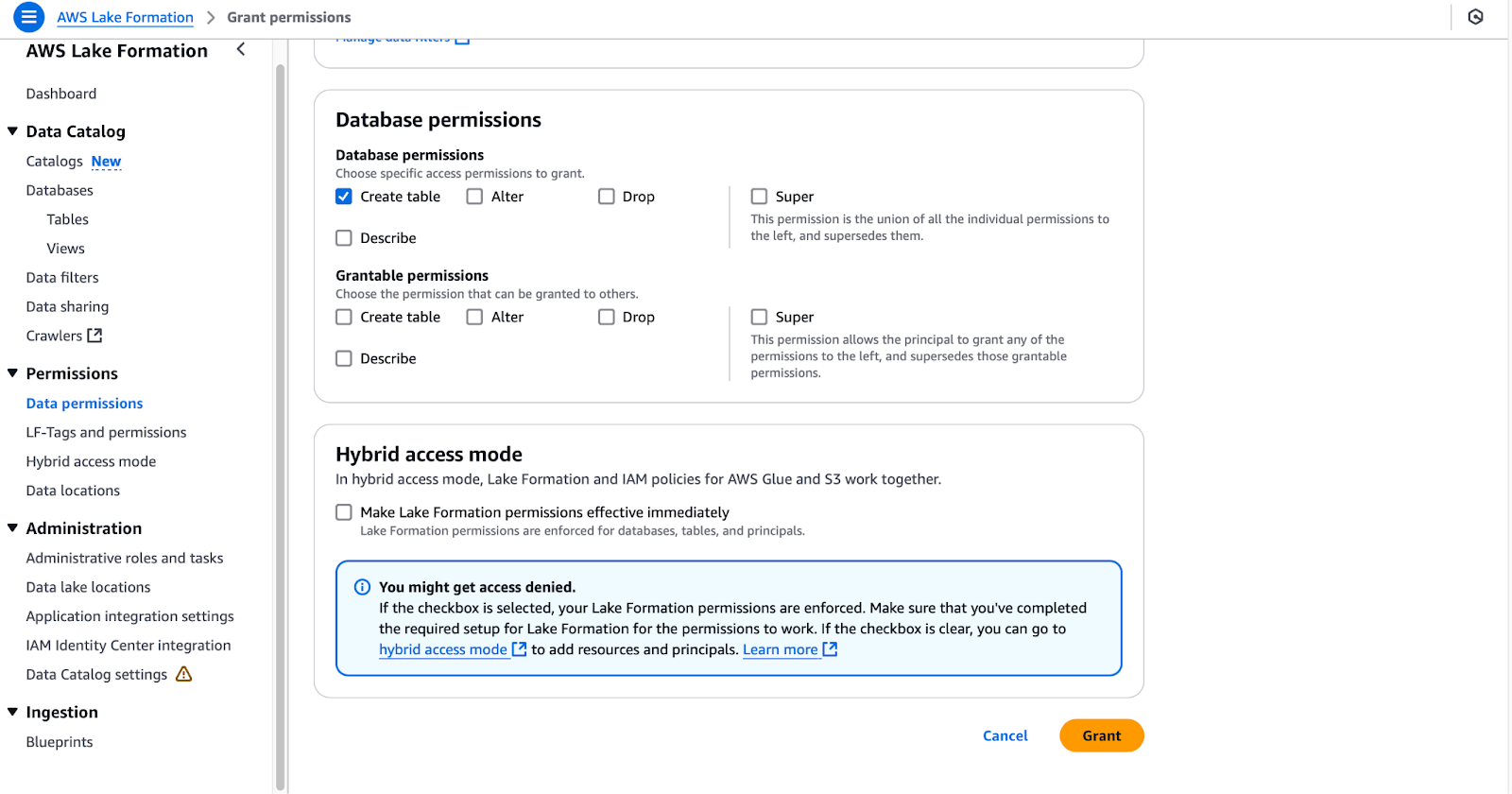
Configuration des autorisations de base de données dans AWS Lake Formation
En suivant ces étapes, l'utilisateur lf-data-engineer et le rôle DE-GlueServiceRole obtiendront les autorisations nécessaires pour travailler avec les tableaux du catalogue de données Glue et gérer les ressources dans les travaux de Glue Studio. Cette configuration garantit un accès sécurisé et basé sur les rôles à votre lac de données.
Dans cette section, nous allons créer un travail ETL dans AWS Glue Studio en utilisant SQL Transform.
lf-data-engineer:
lf-data-engineer pour vous connecter à la console de gestion AWS. Récupérez le mot de passe depuis AWS Secrets Manager et l'URL de connexion fournie par la sortie CloudFormation.LF_GlueStudio afin de pouvoir l'identifier facilement.DE-GlueServiceRole.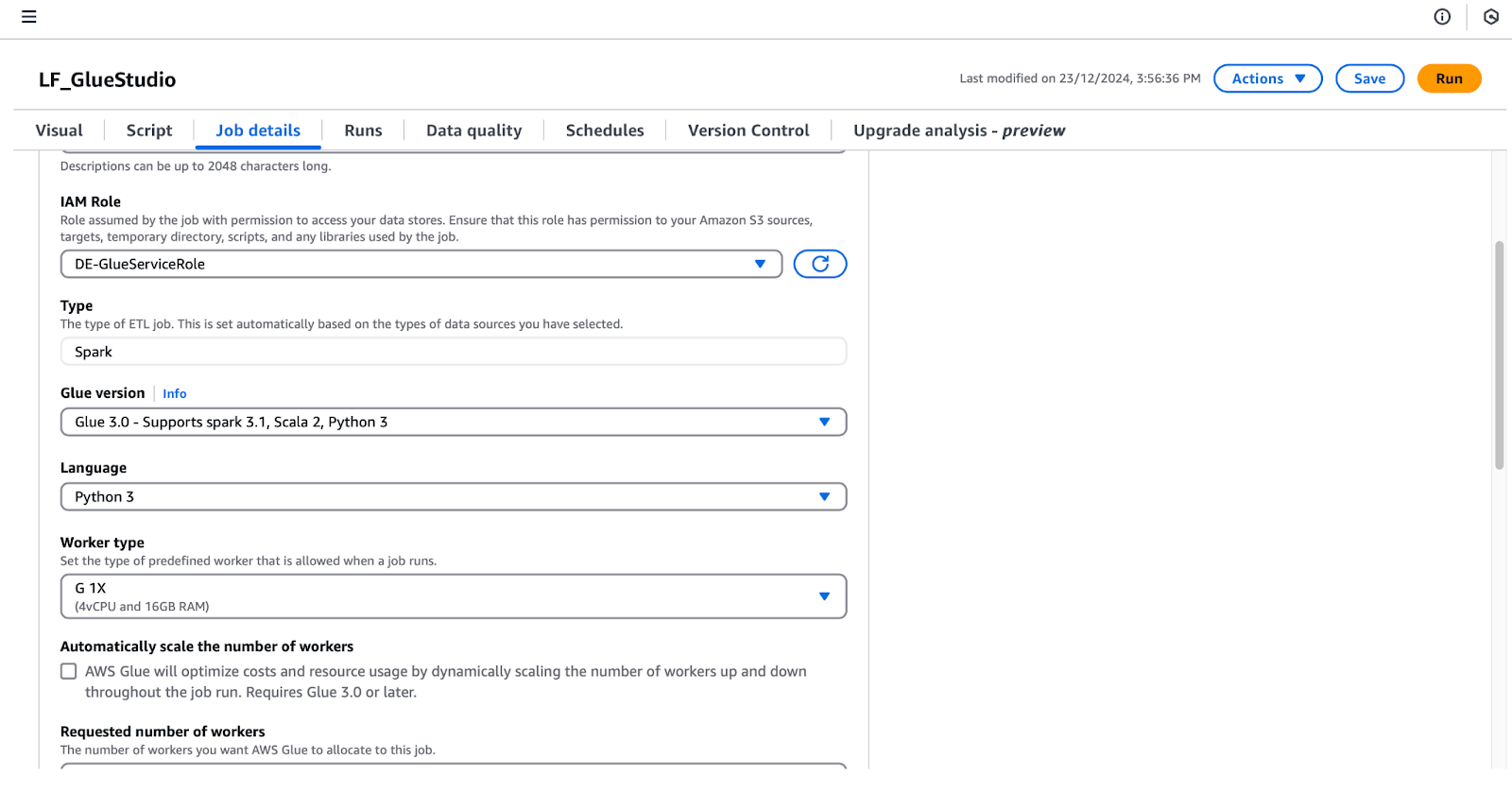
Configurer les détails d'un travail dans AWS Glue Studio
tpc.dl_tpc_household_demographics. (Note : L'utilisateur lf-data-admin n'a accordé à lf-data-engineer que l'autorisation Select sur ce tableau. Les autres tableaux n'apparaîtront pas dans la liste déroulante).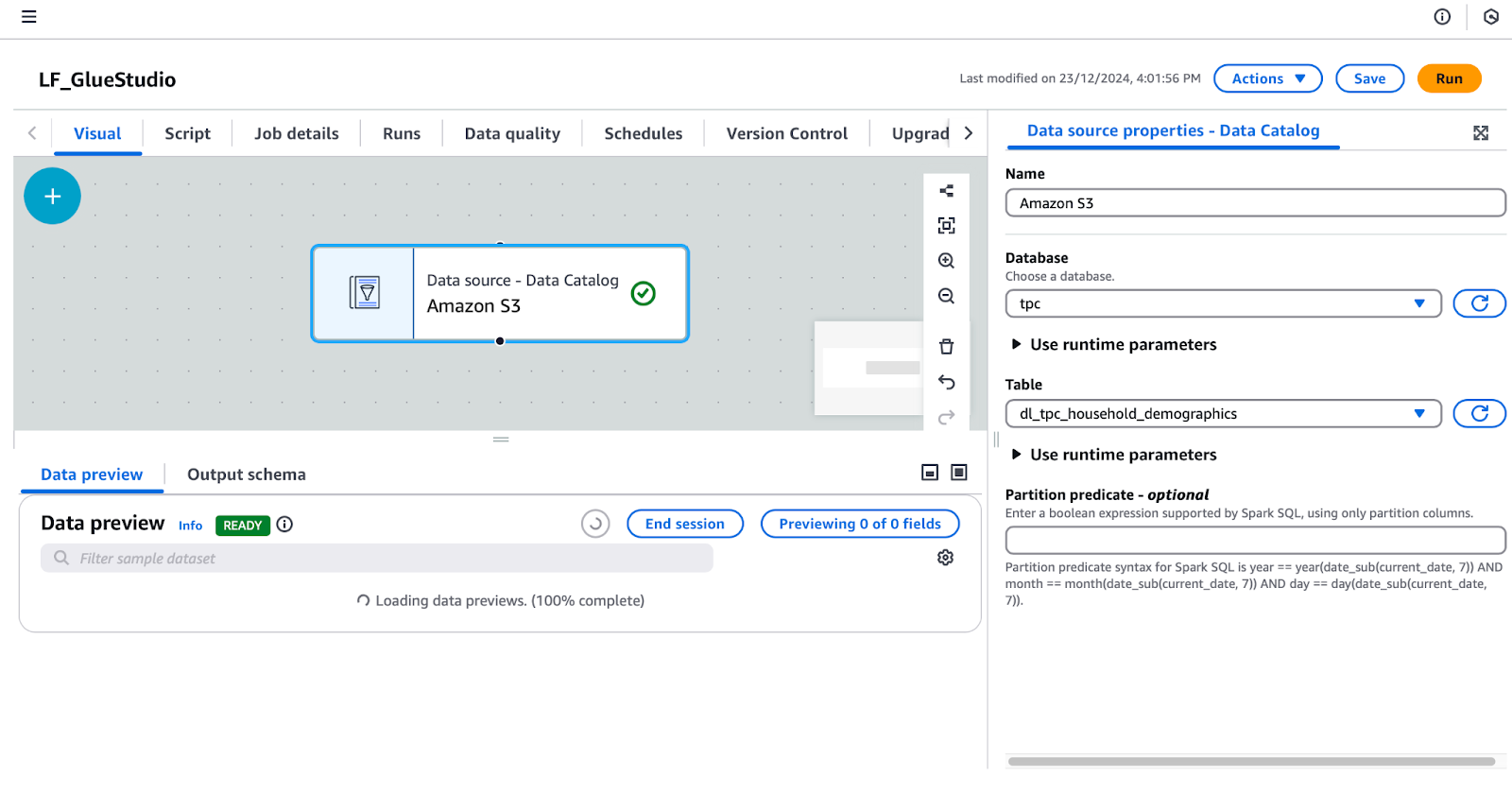
Configurer une source de données dans AWS Glue Studio
/* Select all records where buy potential is between 0 and 500 */
SELECT *
FROM myDataSource
WHERE hd_buy_potential = '0-500';hd_dep_count et hd_vehicle_count. Cliquez Appliquer.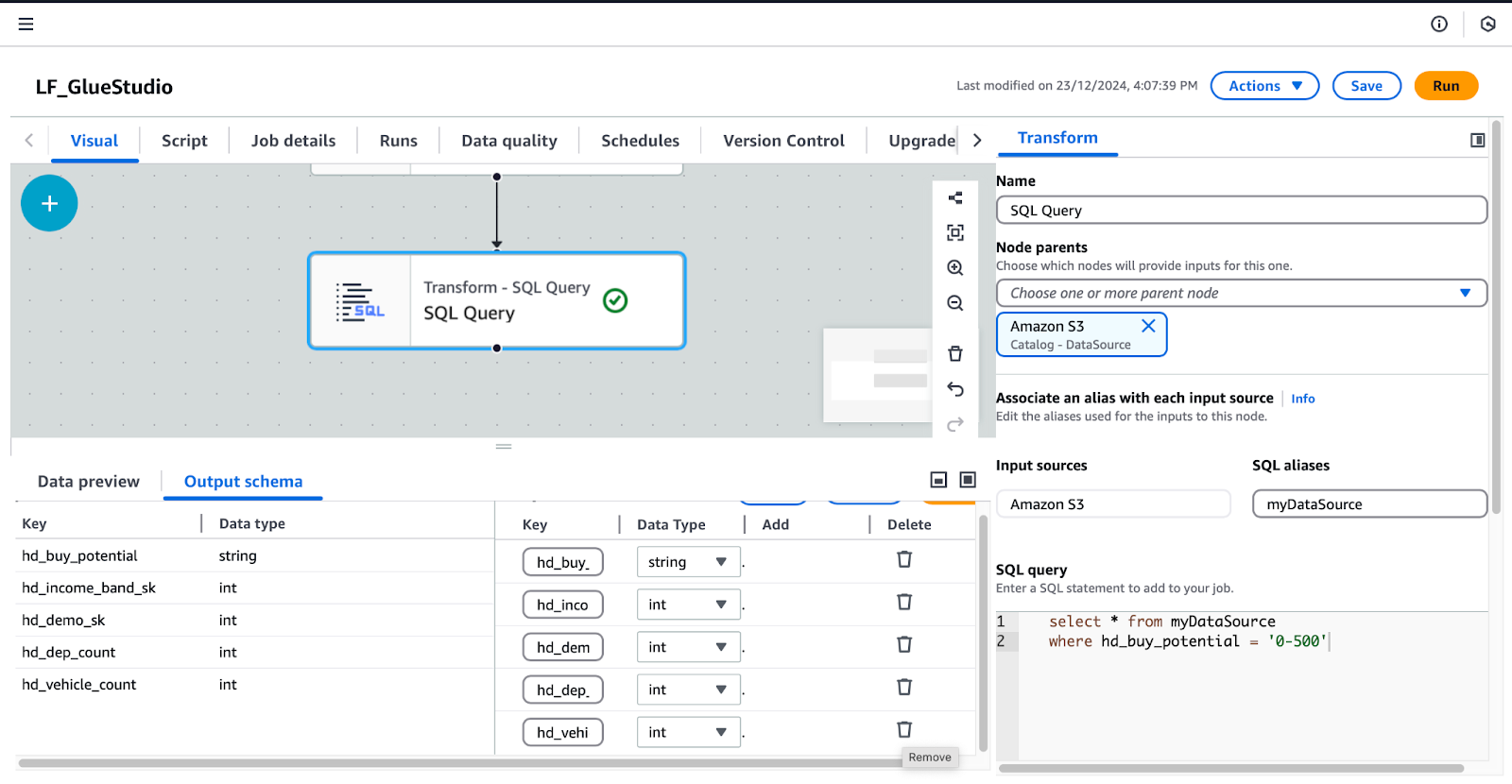
Configuration de la transformation des requêtes SQL dans AWS Glue Studio
s3:///gluestudio/curated/. (Remplacez tpc .dl_tpc_household_demographics_below500.En suivant ces étapes, vous créerez une tâche ETL Glue Studio entièrement fonctionnelle qui transforme les données et écrit les résultats dans un dossier S3 curaté tout en mettant à jour le Glue Data Catalog.
Pour confirmer les autorisations accordées dans Lake Formation, suivez les étapes suivantes en vous connectant en tant qu'utilisateur lf-data-engineer (comme indiqué dans la section Créer des postes dans Glue Studio ) :
LF_GlueStudio: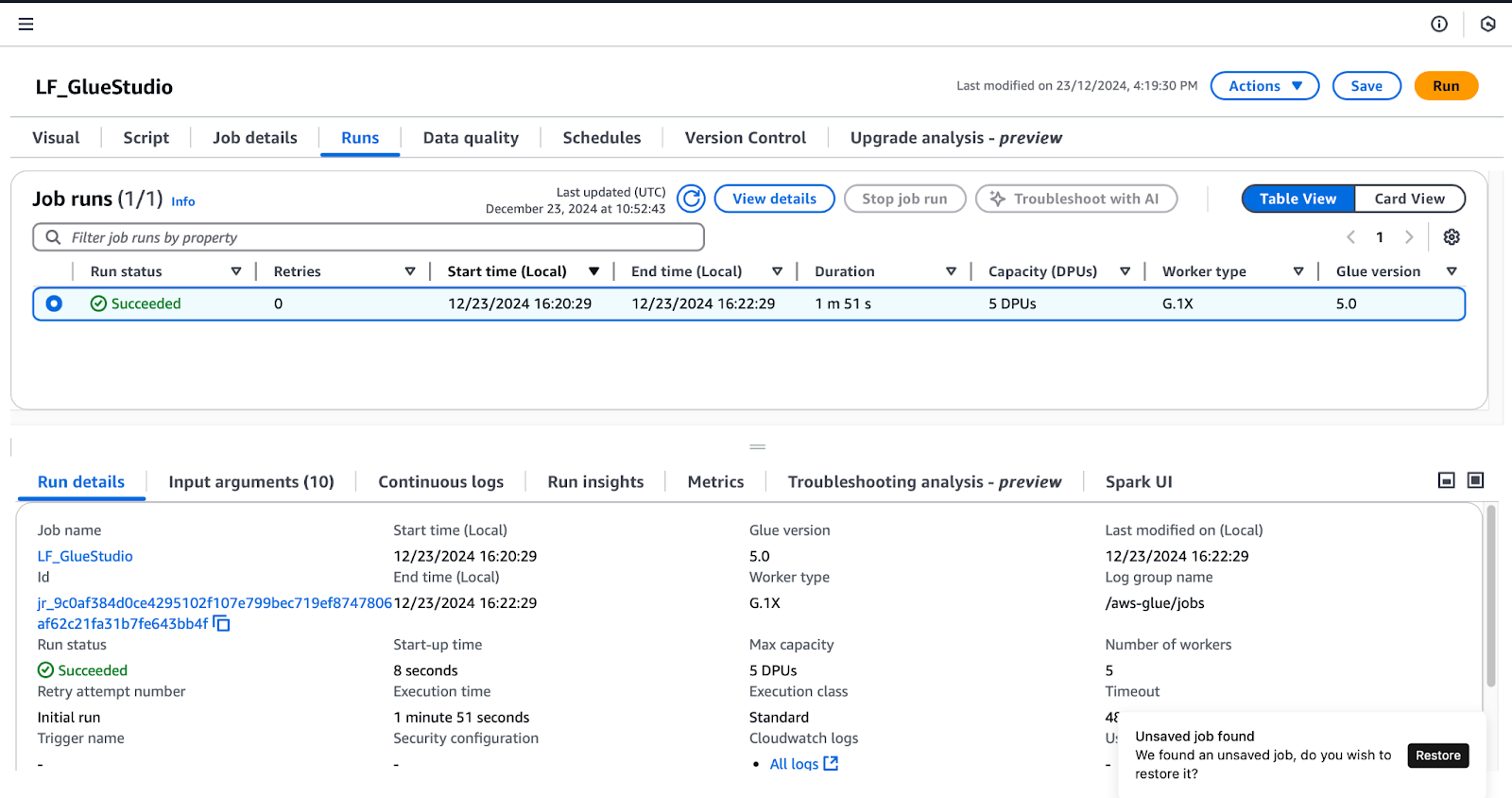
Contrôler l'exécution des tâches dans AWS Glue Studio
curated dans votre panier S3 pour vérifier les fichiers de sortie. Ces fichiers doivent être au format Parquet, tel qu'il a été configuré lors de la création du travail.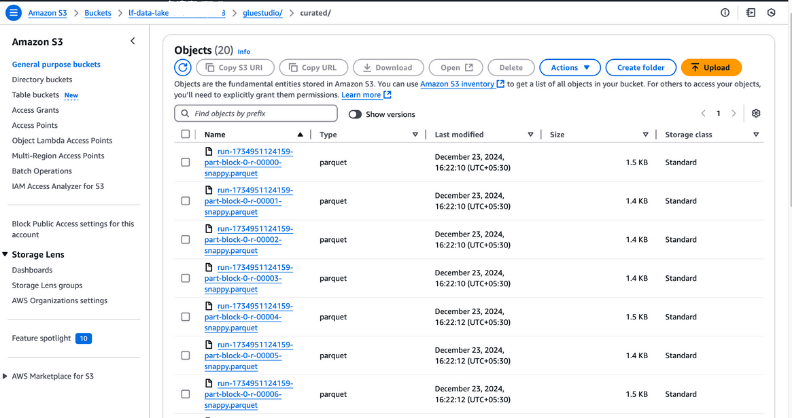
Visualisation des fichiers de sortie sur Amazon S3
Visualisation des tableaux d'une base de données dans AWS Glue
Lors de l'intégration d'AWS Lake Formation et d'AWS Glue, le respect des meilleures pratiques permet de renforcer la sécurité des données, de rationaliser les opérations et d'optimiser les performances. Voici comment vous pouvez tirer le meilleur parti de ces services :

Événements du journal pour TPC Crawler dans AWS CloudWatch

Surveillance des paramètres de travail de AWS Glue Studio
La mise en œuvre d'AWS Lake Formation et d'AWS Glue permet à l'organisation d'organiser, de sauvegarder et de traiter les données. Grâce aux mesures de sécurité étendues de Lake Formation et à l'automatisation de Glue, vous pouvez optimiser vos processus ETL, respecter toutes les politiques relatives à la gouvernance des données et fournir un accès facile aux données pour les utilisateurs, y compris les ingénieurs et les scientifiques des données.
Les avantages comprennent
Au fur et à mesure que vous approfondissez votre compréhension de l'intégration des données, il est essentiel de compléter votre apprentissage par des connaissances pratiques. Par exemple, la maîtrise des pipelines de données avec ETL et ELT en Python peut élever votre capacité à traiter et transformer efficacement les données. De même, une bonne maîtrise des concepts de gestion des données vous permettra d'améliorer la façon dont vous structurez et traitez les ensembles de données. Pour garantir la fiabilité de vos résultats, il est indispensable de comprendre les principes enseignés dans le cours Introduction à la qualité des données.
Apprenez-en plus sur AWS grâce à ces cours !
Cursus
Cours
Cours