
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Bevor du AWS Lake Formation und AWS Glue integrierst, solltest du sicherstellen, dass du Folgendes hast:
Wenn du die Voraussetzungen hast, befolge einfach diese Schritte:
Der erste Schritt ist die Bereitstellung der AWS-Kernressourcen, die für den Aufbau eines gesicherten Data Lake benötigt werden, bevor der Integrationsprozess beginnt. Die AWS CloudFormation-Vorlage hilft bei der Organisation und Bereitstellung aller benötigten Ressourcen.
Verwende die mitgelieferte CloudFormation-Vorlage, um einen Stack in deinem AWS-Konto zu erstellen. Dieser Stack stellt wichtige Ressourcen bereit, die für die in diesem Tutorial beschriebenen Anwendungsfälle benötigt werden.
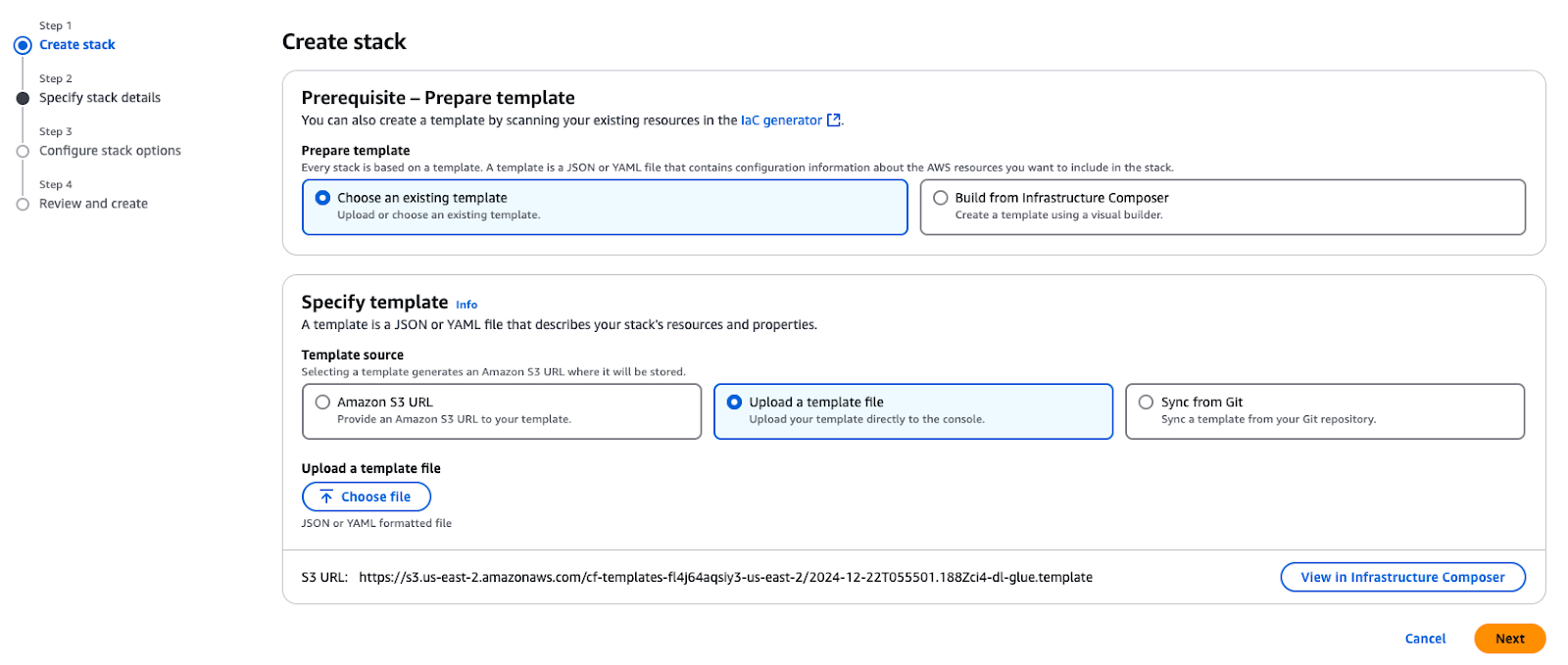
Erstellen eines Stacks in AWS CloudFormation
Wenn du den Stack bereitstellst, werden die folgenden Schlüsselressourcen in deinem AWS-Konto erstellt:
GlueServiceRole: Gewährt AWS Glue Zugriff auf S3 und Lake Formation Services.DataEngineerGlueServiceRole: Erteilt Ingenieuren die Berechtigungen für den Datenzugriff und die Datenverarbeitung.DataAdminUser und DataEngineerUser: Vorkonfigurierte IAM-Benutzer für die Erkundung und Verwaltung der Lake Formation-Sicherheit.EC2-DB-Loader) zum Vorladen und Übertragen von Beispieldaten in S3.lf-users-credentials), um die Benutzerdaten für die zuvor erstellten IAM-Benutzer sicher zu speichern.Nachdem der Stapel erstellt wurde, hast du Folgendes:
In diesem Abschnitt konfiguriert der Data Lake Administrator AWS Lake Formation so, dass es für die Personas der Datenverbraucher, einschließlich der Data Engineers, verfügbar ist. Der Verwalter wird:
Diese Konfigurationen bieten eine sichere, fein abgestufte Zugriffskontrolle und eine reibungslose Koordination mit anderen AWS-Services.
Ein Data Lake Administrator ist ein IAM-Benutzer oder eine IAM-Rolle, der/die jedem Prinzip (einschließlich sich selbst) die Berechtigung für jede Data Catalog Entität geben kann. Der Data Lake Administrator ist in der Regel der erste Benutzer, der für die Verwaltung des Datenkatalogs angelegt wird und derjenige, der administrative Rechte für den Datenkatalog erhält.
Im AWS Lake Formation Service kannst du die Eingabeaufforderung öffnen, indem du auf die Schaltfläche Administrative Rollen und Aufgaben -> Administratoren hinzufügen im Navigationsbereich klickst und dann den IAM-Benutzer lf-data-admin aus der Dropdown-Liste auswählst.
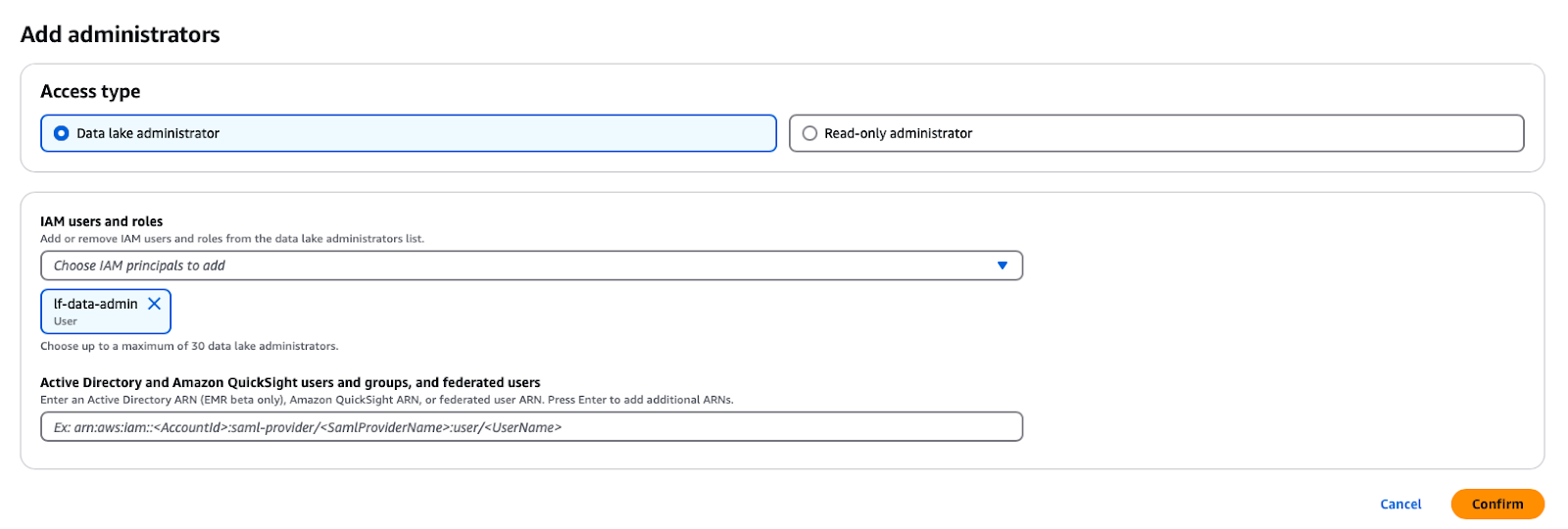
Hinzufügen eines Data Lake Administrators in AWS Lake Formation
Standardmäßig hat Lake Formation die Option "Nur IAM-Zugriffskontrolle verwenden", die ausgewählt ist, um mit dem AWS Glue Data Catalog kompatibel zu sein. Um eine fein abgestufte Zugriffskontrolle mit Lake Formation-Berechtigungen zu ermöglichen, musst du diese Einstellungen anpassen:
IAMAllowedPrincipals unter Datenbankerstellererscheint, markieren Sie die Gruppe und wählen Sie Widerrufen.Diese Schritte deaktivieren die standardmäßige IAM-Zugriffskontrolle und ermöglichen es dir, Lake Formation-Berechtigungen für mehr Sicherheit zu implementieren.
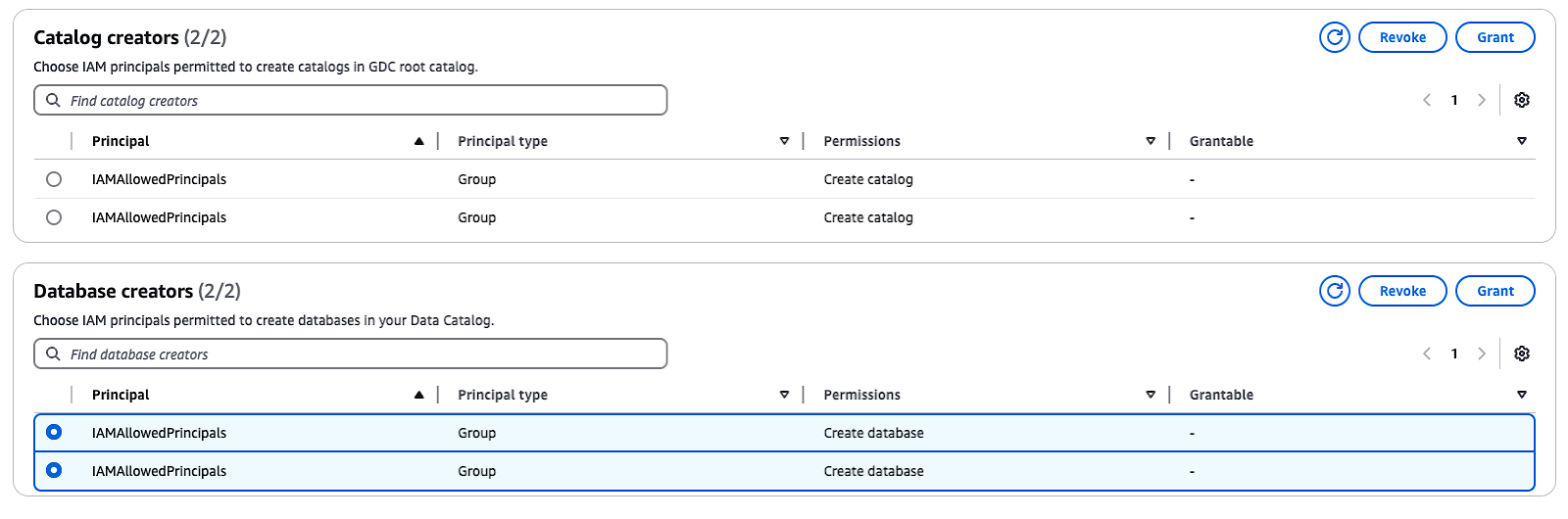
Verwalten von Katalog- und Datenbankerstellern in AWS Lake Formation
Jetzt ist es an der Zeit, den Glue Data Catalog zu nutzen.
Um eine Datenbank für die TPC-Daten zu erstellen, loggst du dich aus deiner aktuellen AWS-Sitzung aus und meldest dich wieder als Benutzer lf-data-admin an. Verwende den Anmeldelink, der in der CloudFormation-Ausgabe angegeben ist, und das Passwort, das du vom AWS Secrets Manager erhalten hast.
lf-data-lake-account-ID, wobei account-ID deine 12-stellige AWS-Kontonummer ist.Diese Datenbank wird die Grundlage für die Speicherung und Verwaltung von Metadaten für die TPC-Daten im Lake Formation Setup sein.
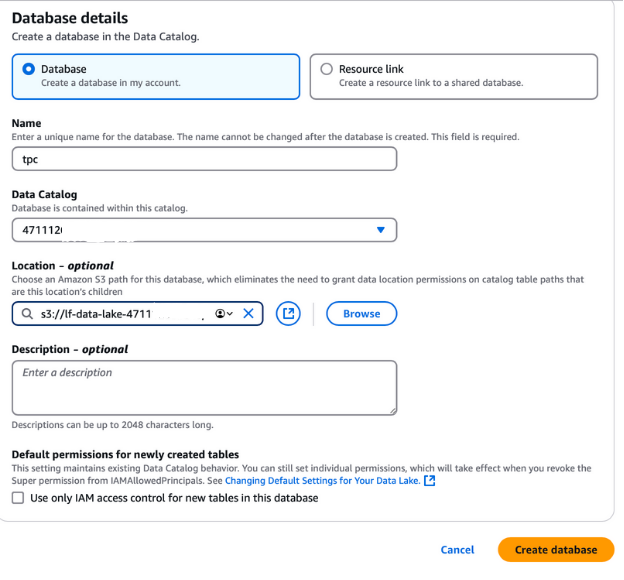
Erstellen einer Datenbank in AWS Lake Formation
Wir verwenden einen AWS Glue Crawler, um Tabellen im AWS Glue Data Catalog zu erstellen. Crawler sind die gebräuchlichste Methode, um Tabellen in AWS Glue zu erstellen, da sie mehrere Datenspeicher gleichzeitig durchsuchen und die Details der Tabellen nach dem Crawlen im Data Catalog generieren oder aktualisieren können.
Bevor du den AWS Glue Crawler startest, musst du seiner IAM-Rolle die erforderlichen Berechtigungen erteilen:
tpc Datenbank aus.LF-GlueServiceRole aus.tpc als Datenbank aus.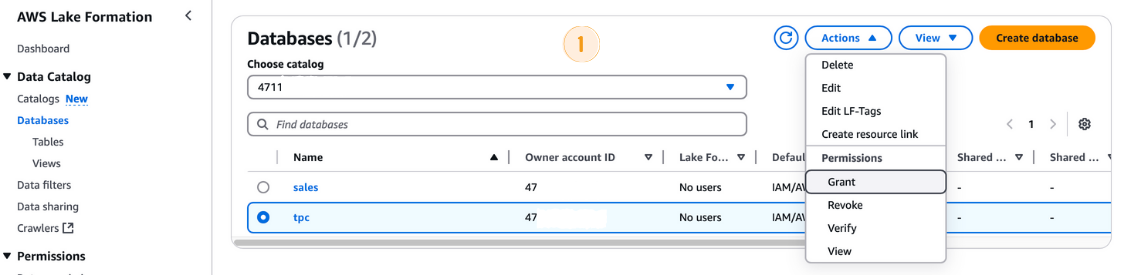
Erteilung von Genehmigungen in der AWS Lake Formation
Wenn du die Berechtigungen hast, kannst du den Crawler starten:
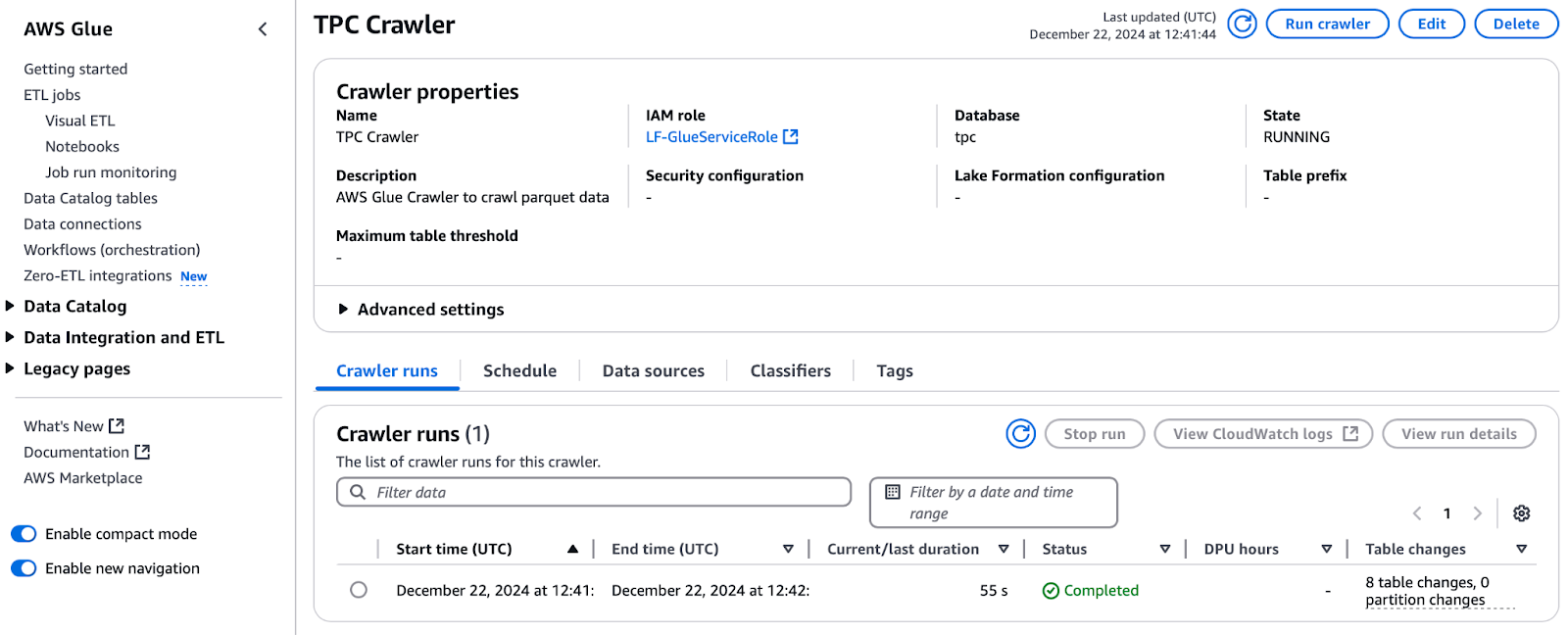
Ausführen des TPC Crawlers in AWS Glue
Du kannst diese Tabellen auch in der AWS Lake Formation Konsole unter Datenkatalog und Tabellen.
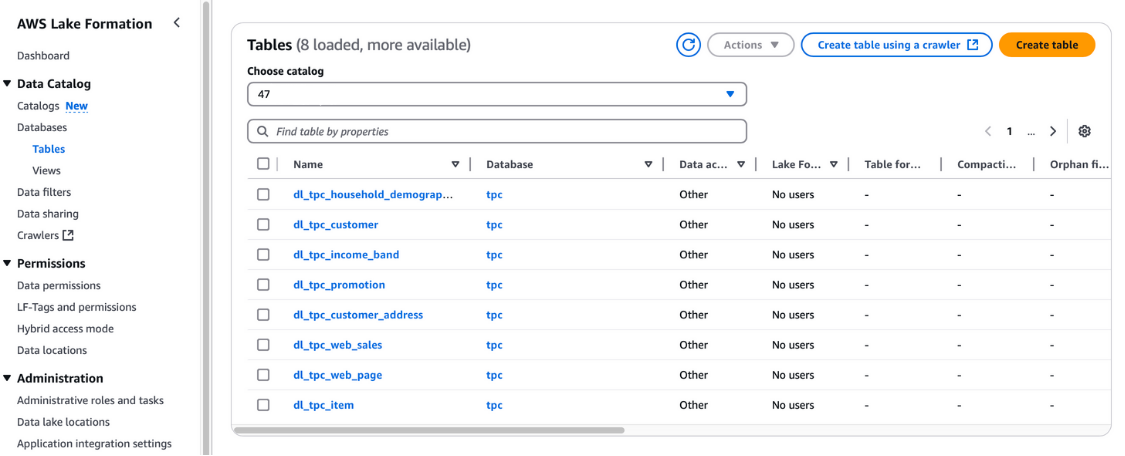
Tabellen in der AWS Lake Formation anzeigen
Du musst das S3-Bucket in AWS Lake Formation für deinen Data Lake Storage registrieren. Mit dieser Registrierung kannst du eine fein abgestufte Zugriffskontrolle für AWS Glue Data Catalog-Objekte und die im Bucket gespeicherten Daten durchsetzen.
Schritte zur Registrierung eines Data Lake-Standorts:
LF-GlueServiceRole aus, die von der CloudFormation-Vorlage erstellt wurde.Sobald du dich registriert hast, überprüfe den Standort deines Datensees, um sicherzustellen, dass er richtig konfiguriert ist. Dieser Schritt ist wichtig für eine nahtlose Datenverwaltung und Sicherheit in deinem Lake Formation Setup.
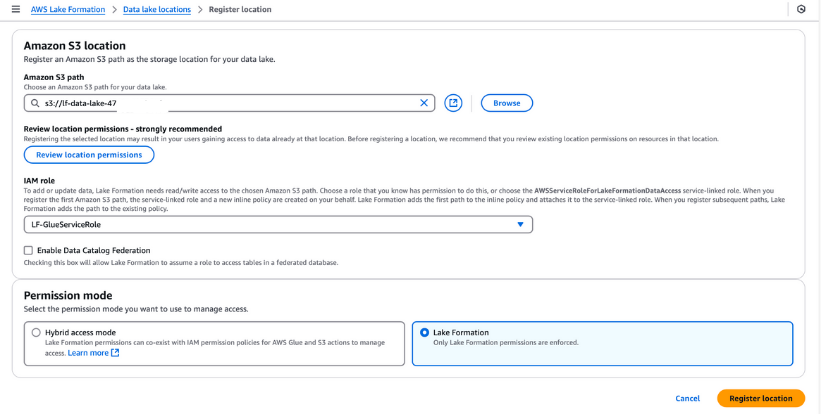
Registrierung eines Amazon S3-Standorts in AWS Lake Formation
LF-Tags können verwendet werden, um Ressourcen zu organisieren und Berechtigungen in vielen Ressourcen gleichzeitig zu setzen. Sie ermöglicht es dir, Daten mithilfe von Taxonomien zu organisieren und so komplexe Richtlinien aufzuschlüsseln und Berechtigungen effektiv zu verwalten. Das ist möglich, weil du mit LF-Tags die Richtlinie von der Ressource trennen kannst und somit Zugriffsrichtlinien einrichten kannst, noch bevor Ressourcen erstellt werden.
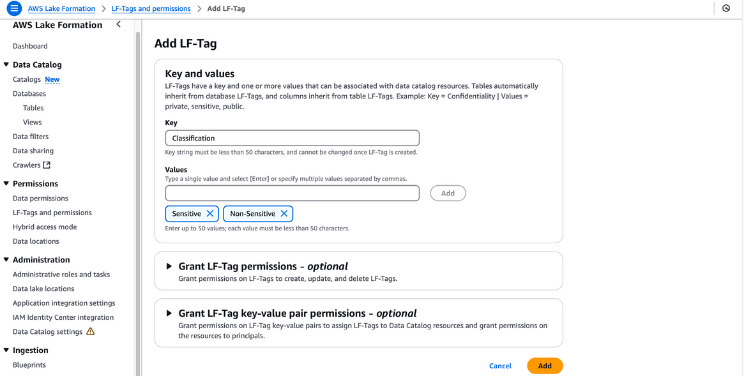
Erstellen von LF-Tags in der AWS Lake Formation
lf-data-admin über LF-Tag-Berechtigungen verfügt. Navigieren Sie zu Tabellen in der Lake Formation Konsole.dl_tpc_customer, klicken Sie auf die Aktionen Menü, und wähle Erteilen.lf-data-admin aus.tpc und die Tabelle dl_tpc_customer und erteile der TabelleAlter Rechte. Klick Grant.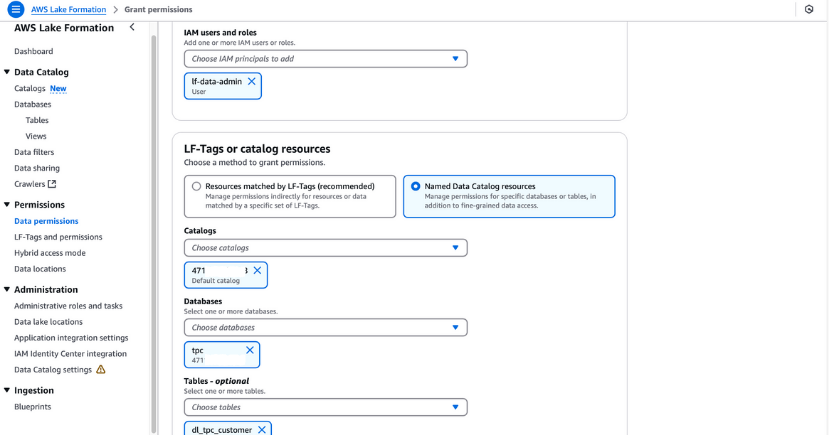
Erteilung von Genehmigungen in der AWS Lake Formation
dl_tpc_customer aus. Öffne die Details der Tabelle und wähle LF-Tags bearbeiten aus dem Aktionsmenü.c_first_name, c_last_name und c_email_address, und klicken Sie auf LF-Tags bearbeiten.Classification den Wert auf "Sensibel" und klicke auf Speichern. Speichere diese Konfiguration als neue Version.dl_tpc_household_demographics findest du unter Aktionen und wähle LF-Tags bearbeiten.Wenn du diese Schritte befolgst, kannst du deinen Datenkatalogobjekten effizient LF-Tags zuweisen und so eine sichere, feinkörnige Zugriffskontrolle in deinem Data Lake gewährleisten.
AWS Glue Studio ist eine Drag-and-Drop-Benutzeroberfläche, mit der Benutzer ETL-Aufträge für AWS Glue entwickeln, debuggen und überwachen können. Dateningenieure nutzen Glue ETL, das auf Apache Spark basiert, um in Amazon S3 gespeicherte Datensätze umzuwandeln und Daten zur Analyse in Data Lakes und Warehouses zu laden. Um den Zugang effektiv zu verwalten, wenn mehrere Teams an denselben Datensätzen arbeiten, ist es wichtig, den Zugang zu gewähren und ihn nach Rollen einzuschränken.
Befolge diese Schritte, um dem Benutzer lf-data-engineer und der entsprechenden Rolle DE-GlueServiceRole die erforderlichen Berechtigungen zu erteilen. Diese Rolle wird vom Data Engineer verwendet, um in Glue Studio-Jobs auf Tabellen des Glue Data Catalog zuzugreifen.
lf-data-admin, um dich bei der AWS Management Console anzumelden. Rufe das Passwort aus dem AWS Secrets Manager und die Anmelde-URL aus der CloudFormation-Ausgabe ab.lf-data-engineer und DE-GlueServiceRole ein.tpc.dl_tpc_household_demographics.DE-GlueServiceRole ein.tpc (lass die Tabellen nicht ausgewählt).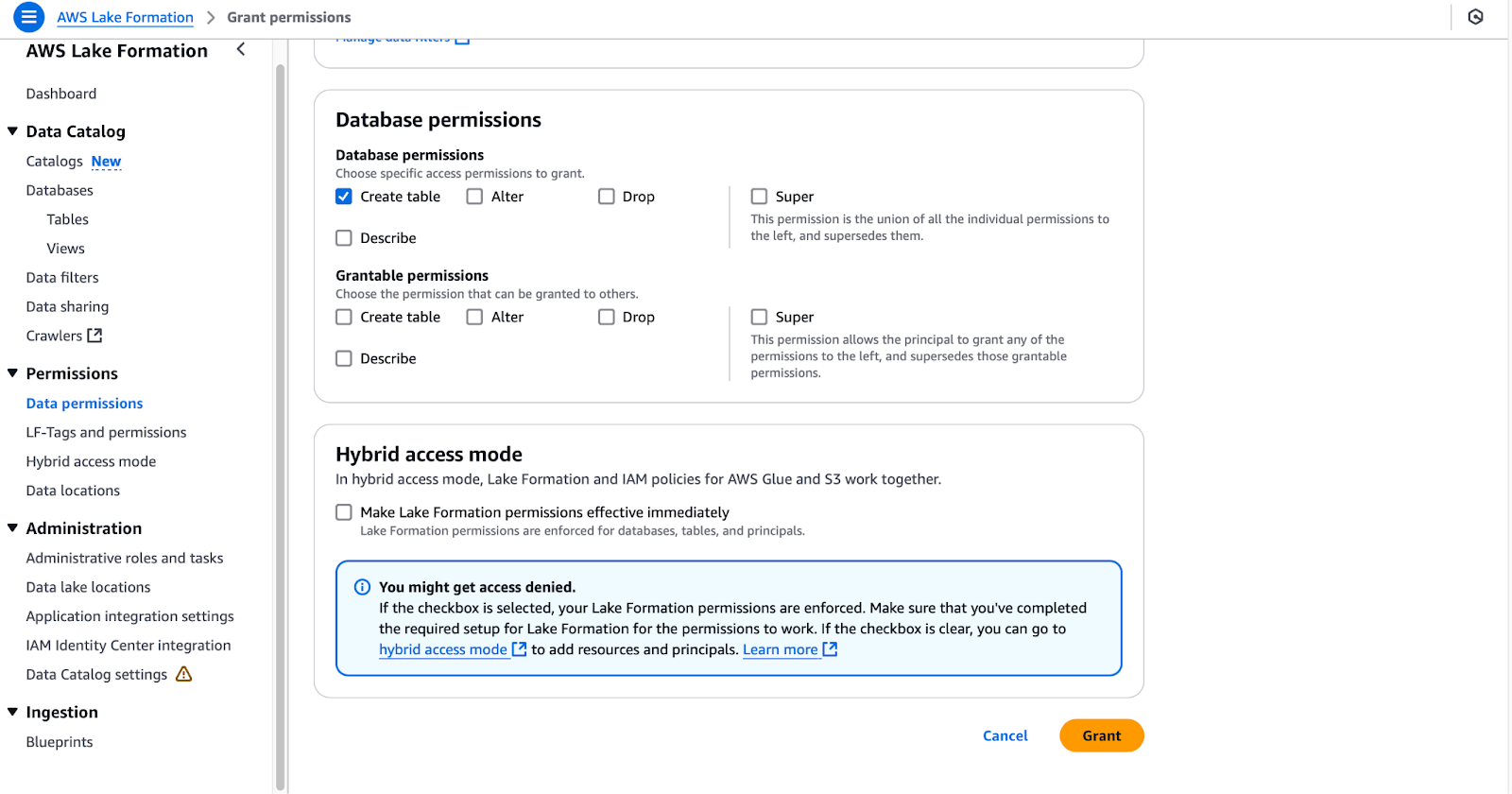
Konfigurieren von Datenbankberechtigungen in AWS Lake Formation
Mit diesen Schritten erhält der Benutzer lf-data-engineer und die Rolle DE-GlueServiceRole die nötigen Rechte, um mit den Tabellen des Glue Data Catalog zu arbeiten und Ressourcen in Glue Studio-Jobs zu verwalten. Diese Einrichtung gewährleistet einen sicheren, rollenbasierten Zugang zu deinem Data Lake.
In diesem Abschnitt werden wir einen ETL-Auftrag in AWS Glue Studio mit SQL Transform erstellen.
lf-data-engineer an:
lf-data-engineer, um dich bei der AWS Management Console anzumelden. Rufe das Passwort aus dem AWS Secrets Manager und der Anmelde-URL ab, die in der CloudFormation-Ausgabe angegeben ist.LF_GlueStudio um, damit er leicht identifiziert werden kann.DE-GlueServiceRole.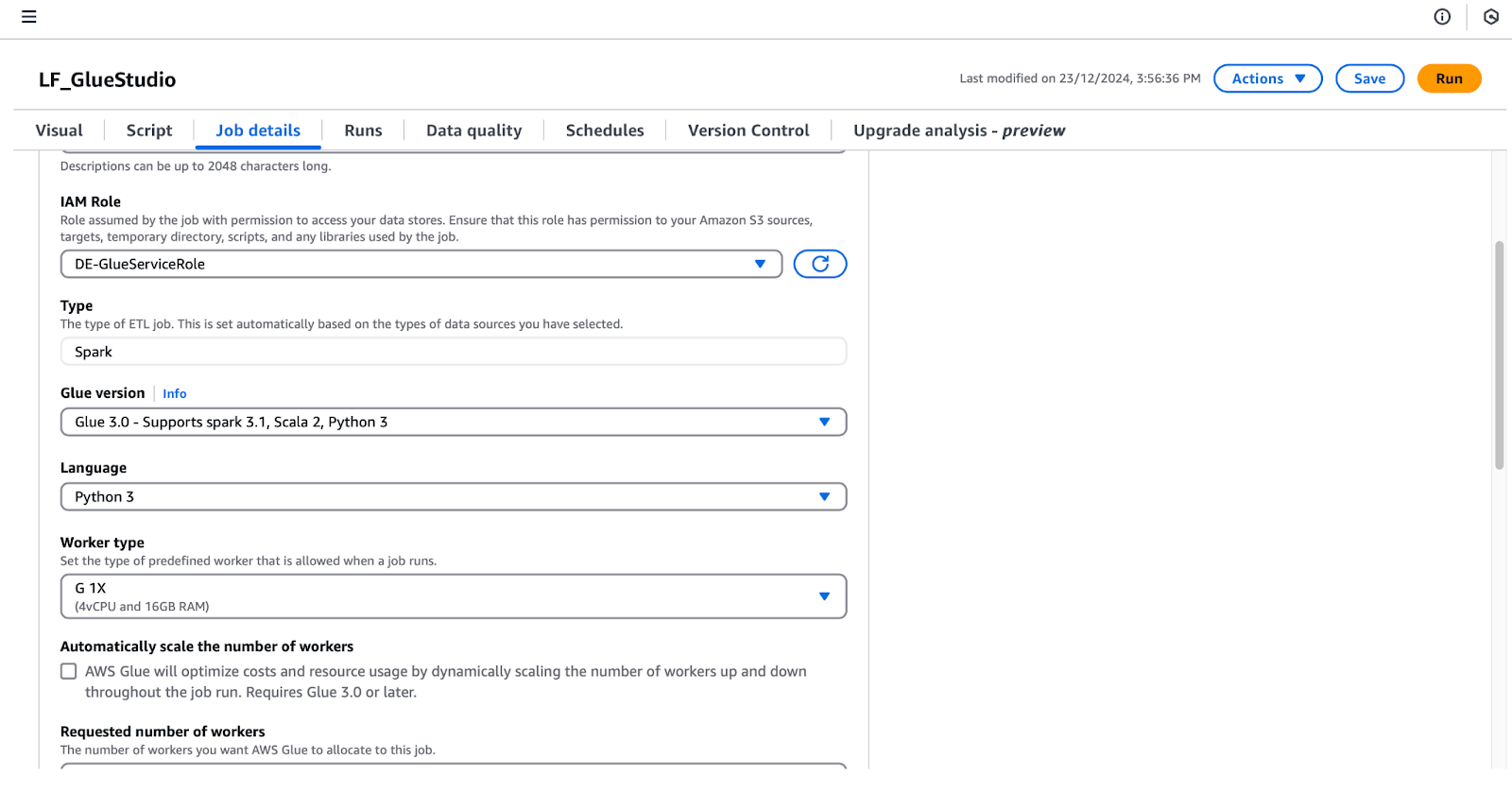
Konfigurieren von Auftragsdetails in AWS Glue Studio
tpc.dl_tpc_household_demographics. (Hinweis: Der Benutzer lf-data-admin hat nur die Berechtigung lf-data-engineer Select für diese Tabelle erteilt. Andere Tabellen werden in der Auswahlliste nicht angezeigt).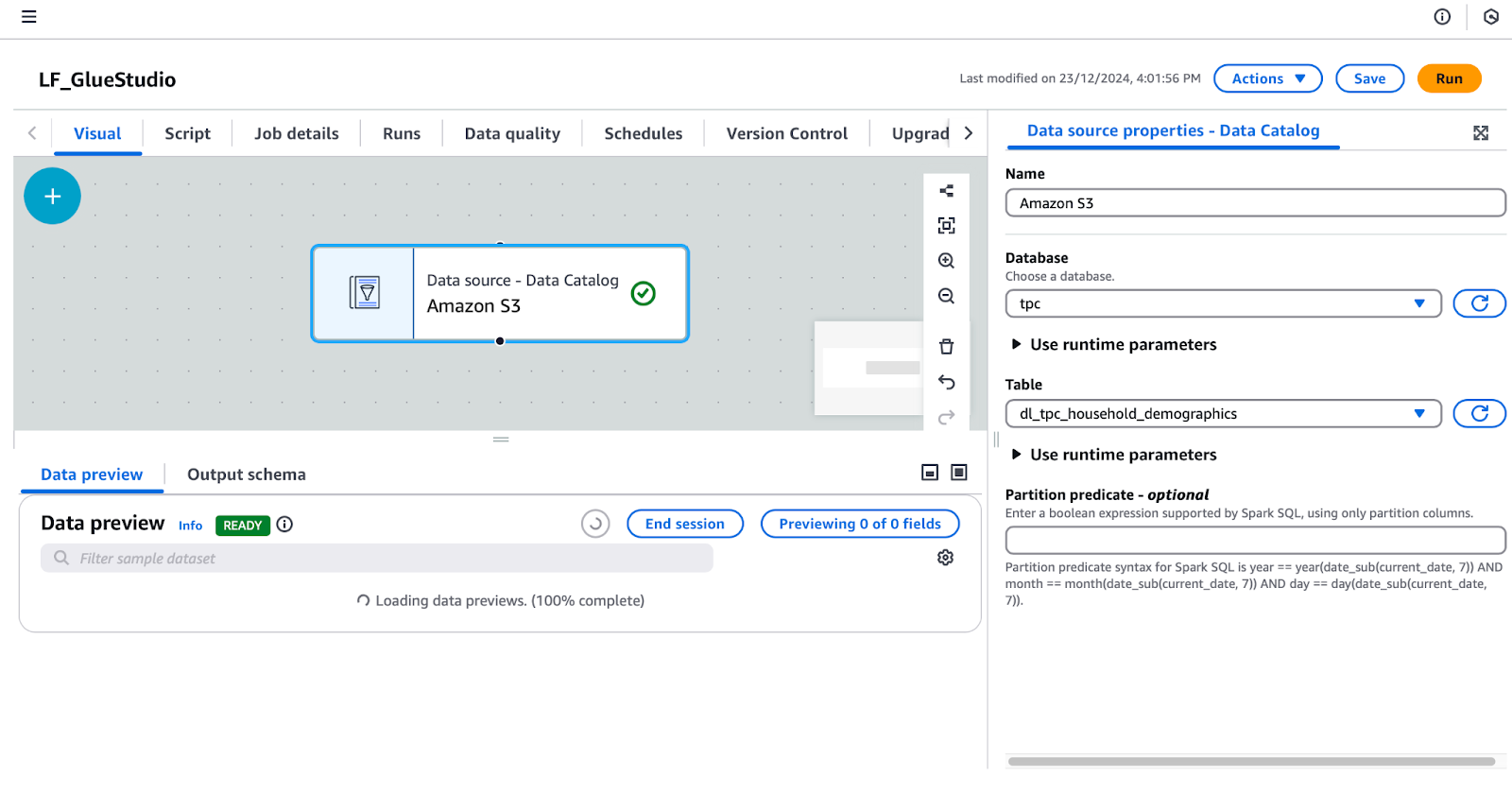
Konfigurieren einer Datenquelle in AWS Glue Studio
/* Select all records where buy potential is between 0 and 500 */
SELECT *
FROM myDataSource
WHERE hd_buy_potential = '0-500';hd_dep_count und hd_vehicle_count. Klicke auf anwenden..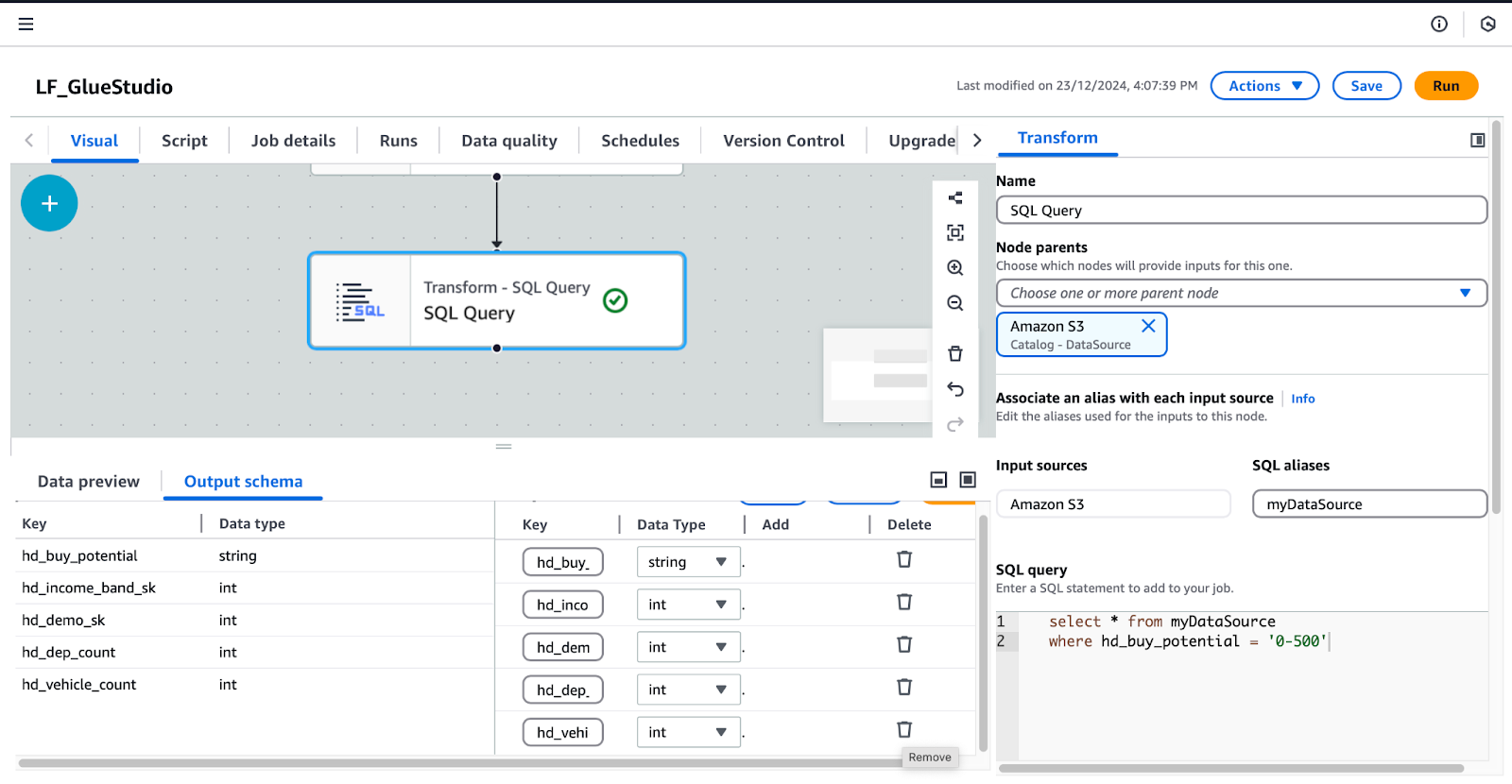
Konfigurieren von SQL Query Transform in AWS Glue Studio
s3:///gluestudio/curated/ ein. (Ersetze tpc .dl_tpc_household_demographics_below500.Wenn du diese Schritte befolgst, erstellst du einen voll funktionsfähigen Glue Studio ETL-Job, der Daten umwandelt und die Ergebnisse in einen kuratierten S3-Ordner schreibt, während der Glue Data Catalog aktualisiert wird.
Um die in Lake Formation erteilten Berechtigungen zu bestätigen, führen Sie die folgenden Schritte aus, während Sie als Benutzer lf-data-engineer eingeloggt sind (wie im Abschnitt Glue Studio Aufträge erstellen Abschnitt beschrieben):
LF_GlueStudio Job aus: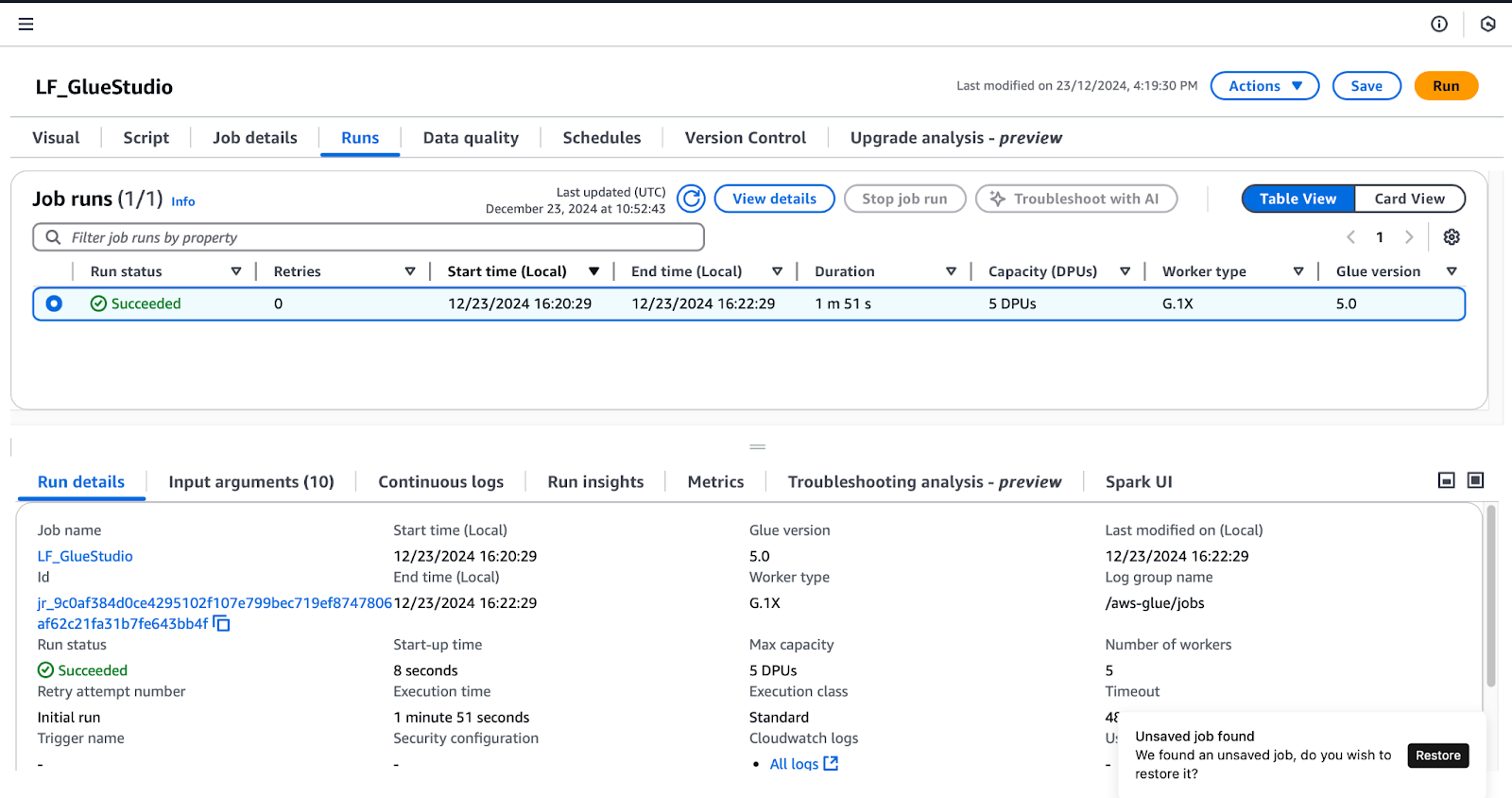
Überwachung von Auftragsläufen in AWS Glue Studio
curated in deinem S3-Bucket, um die Ausgabedateien zu überprüfen. Diese Dateien sollten im Parquet-Format sein, wie bei der Auftragserstellung konfiguriert.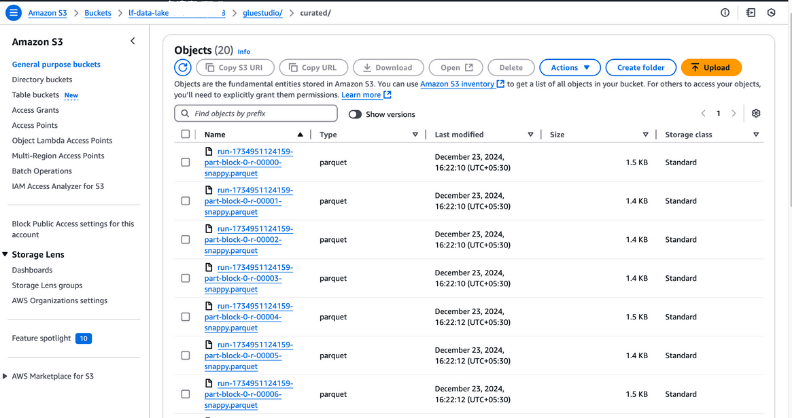
Anzeige der Ausgabedateien in Amazon S3
Anzeigen von Datenbanktabellen in AWS Glue
Bei der Integration von AWS Lake Formation und AWS Glue können die folgenden Best Practices die Datensicherheit verbessern, den Betrieb rationalisieren und die Leistung optimieren. Hier erfährst du, wie du das Beste aus diesen Diensten machen kannst:

Log-Ereignisse für TPC Crawler in AWS CloudWatch

Überwachung von AWS Glue Studio Auftragsmetriken
Die Implementierung von AWS Lake Formation und AWS Glue hilft dem Unternehmen, Daten zu organisieren, zu schützen und zu verarbeiten. Mit den umfassenden Sicherheitsmaßnahmen von Lake Formation und der Automatisierung von Glue kannst du deine ETL-Prozesse optimieren, alle Richtlinien zur Data Governance einhalten und den Nutzern, einschließlich Data Engineers und Data Scientists, einen einfachen Zugang zu den Daten bieten.
Zu den Vorteilen gehören:
Wenn du dein Verständnis von Datenintegration vertiefst, ist es wichtig, dass du dein Wissen durch praktische Kenntnisse ergänzt. Wenn du zum Beispiel Datenpipelines mit ETL und ELT in Python beherrschst, kannst du deine Daten effizient verarbeiten und umwandeln. Ebenso wird ein solides Verständnis von Datenmanagementkonzepten die Strukturierung und Handhabung von Datensätzen verbessern. Und um sicherzustellen, dass deine Ergebnisse verlässlich sind, musst du die Grundsätze verstehen, die im Kurs Einführung in die Datenqualität vermittelt werden.
Lerne mehr über AWS mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.