Curso
Introducción a Python
4 h
6.9M
Imagina que estás en un zoo intentando reconocer si un determinado animal es un guepardo o un leopardo. Como humano, tu cerebro puede analizar sin esfuerzo los rasgos corporales y faciales para llegar a una conclusión válida. Del mismo modo, las Redes Neuronales Convolucionales (CNN) pueden entrenarse para realizar la misma tarea de reconocimiento, independientemente de la complejidad de los patrones. Esto las hace potentes en el campo de la visión por ordenador.
Este tutorial conceptual sobre las CNN comenzará proporcionando una visión general de lo que son las CNN y de su importancia en el aprendizaje automático. A continuación, te guiará paso a paso en la implementación de CNN en TensorFlow Framework 2.
Una Red Neuronal Convolucional (CNN o ConvNet) es un algoritmo de aprendizaje profundo diseñado específicamente para cualquier tarea en la que el reconocimiento de objetos sea crucial, como la clasificación, detección y segmentación de imágenes. Muchas aplicaciones de la vida real, como los coches autoconducidos, las cámaras de vigilancia, etc., utilizan CNN.
Hay varias razones por las que las CNN son importantes, como se destaca a continuación:
La arquitectura de las CNN intenta imitar la estructura de las neuronas del sistema visual humano, compuestas por múltiples capas, en las que cada una es responsable de detectar una característica específica en los datos. Como se ilustra en la imagen siguiente, la CNN típica está formada por una combinación de cuatro capas principales:
Comprendamos cómo funciona cada una de estas capas utilizando el siguiente ejemplo de clasificación del dígito manuscrito.
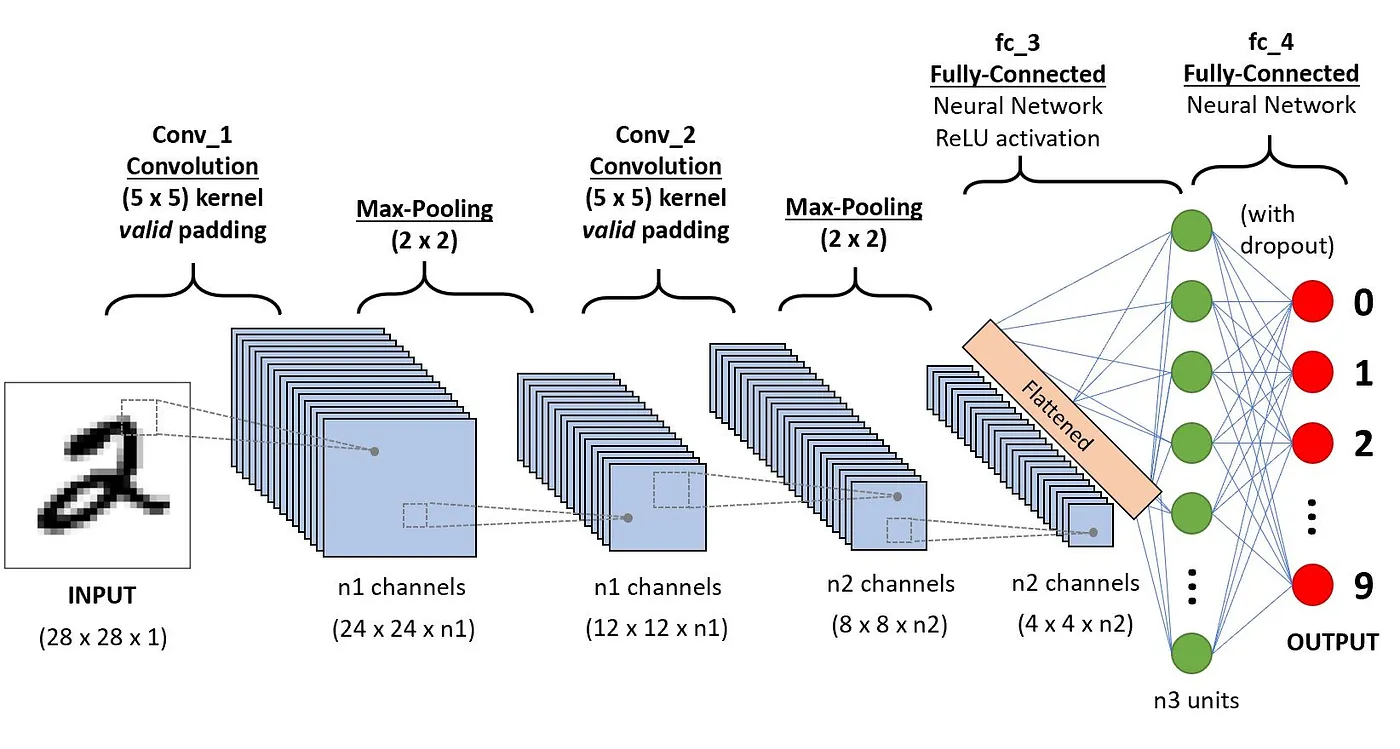
Este es el primer bloque de construcción de una CNN. Como su nombre indica, la principal tarea matemática que se realiza se llama convolución, que es la aplicación de una función de ventana deslizante a una matriz de píxeles que representa una imagen. La función de deslizamiento aplicada a la matriz se denomina núcleo o filtro, y ambos pueden utilizarse indistintamente.
En la capa de convolución, se aplican varios filtros de igual tamaño, y cada filtro se utiliza para reconocer un patrón específico de la imagen, como la curvatura de los dígitos, los bordes, la forma completa de los dígitos, etc.
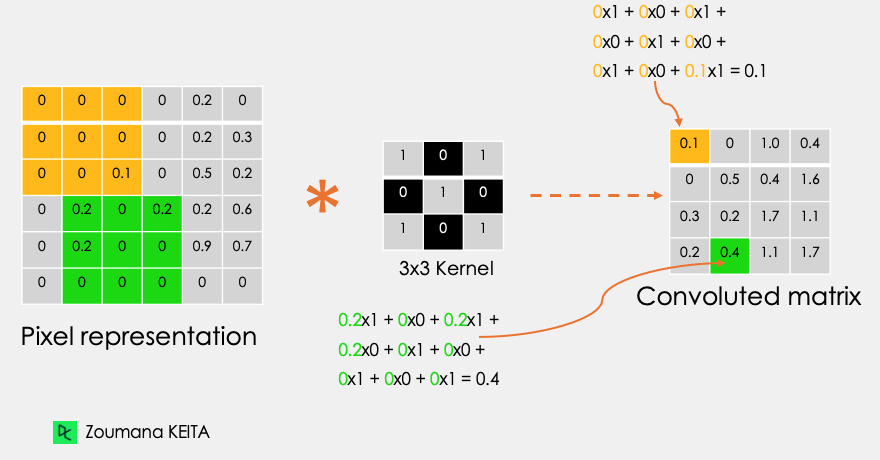
Consideremos esta imagen en escala de grises de 32x32 de un dígito manuscrito. Los valores de la matriz se dan a título ilustrativo.
![]()
Además, consideremos el núcleo utilizado para la convolución. Es una matriz de dimensión 3x3. Los pesos de cada elemento del núcleo se representan en la cuadrícula. Los pesos cero se representan en las cuadrículas negras y los unos en la cuadrícula blanca.
¿Tenemos que encontrar manualmente estos pesos?
En la vida real, los pesos de los núcleos se determinan durante el proceso de entrenamiento de la red neuronal.
Utilizando estas dos matrices, podemos realizar la operación de convolución tomando aplicando el producto punto, y trabajar de la siguiente manera:
La dimensión de la matriz convoluta depende del tamaño de la ventana deslizante. Cuanto mayor sea la ventana deslizante, menor será la dimensión.
Otro nombre asociado al núcleo en la literatura es detector de rasgos, porque los pesos pueden ajustarse con precisión para detectar rasgos específicos en la imagen de entrada.
Por ejemplo:
Cuantas más capas de convolución tenga la red, mejor será la capa para detectar rasgos más abstractos.
Se aplica una función de activación ReLU después de cada operación de convolución. Esta función ayuda a la red a aprender relaciones no lineales entre las características de la imagen, lo que la hace más robusta para identificar distintos patrones. También ayuda a mitigar los problemas de gradiente evanescente.
El objetivo de la capa de agrupación es extraer los rasgos más significativos de la matriz convoluta. Esto se hace aplicando algunas operaciones de agregación, que reducen la dimensión del mapa de características (matriz convoluta), reduciendo así la memoria utilizada durante el entrenamiento de la red. La agrupación también es relevante para mitigar el sobreajuste.
Las funciones de agregación más comunes que pueden aplicarse son:
A continuación se ilustra cada uno de los ejemplos anteriores:
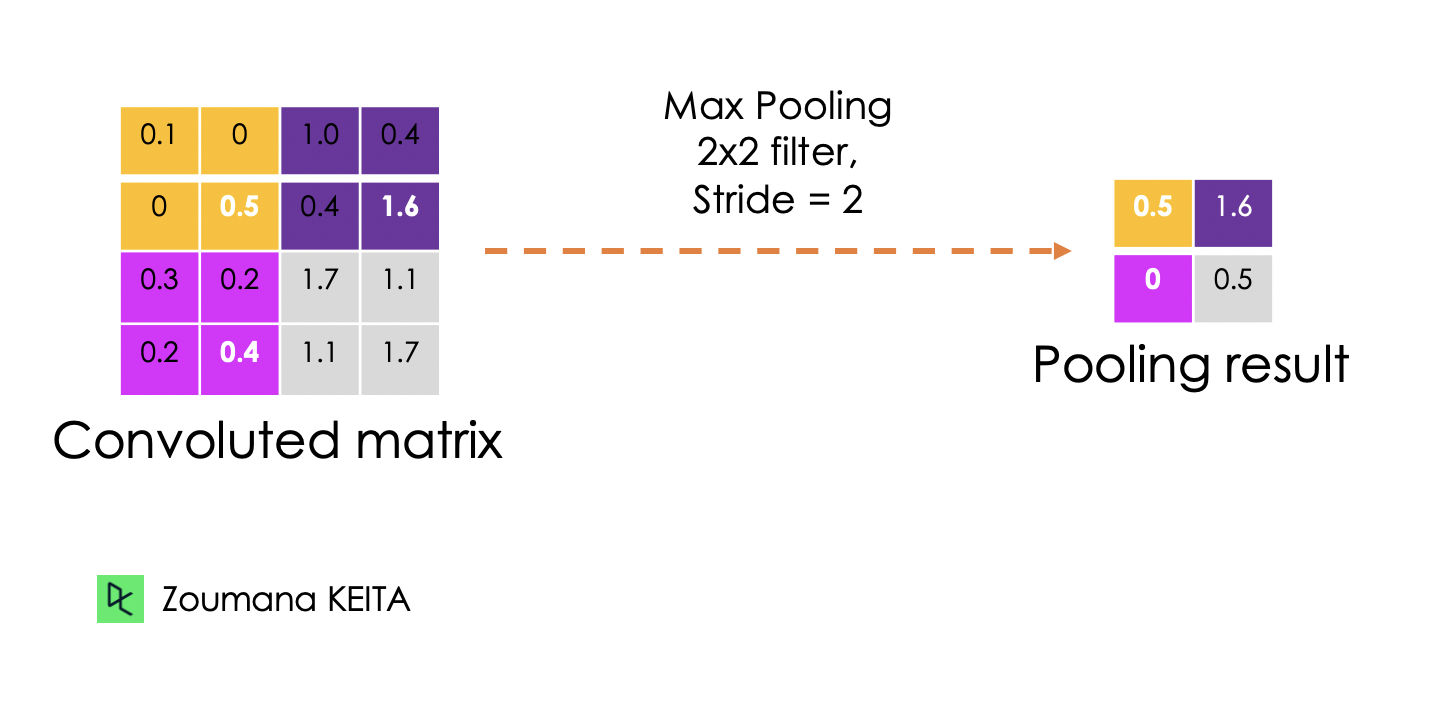
Además, la dimensión del mapa de características se reduce a medida que se aplica la función de sondeo.
La última capa de agrupación aplana su mapa de características para que pueda ser procesado por la capa totalmente conectada.
Estas capas están en la última capa de la red neuronal convolucional, y sus entradas corresponden a la matriz unidimensional aplanada generada por la última capa de agrupamiento. Se les aplican funciones de activación ReLU para la no linealidad.
Por último, se utiliza una capa de predicción softmax para generar valores de probabilidad para cada una de las posibles etiquetas de salida, y la etiqueta final predicha es la que tiene la puntuación de probabilidad más alta.
El Dropout es una técnica de regularización que se aplica para mejorar la capacidad de generalización de las redes neuronales con un gran número de parámetros. Consiste en descartar aleatoriamente algunas neuronas durante el proceso de entrenamiento, lo que obliga a las neuronas restantes a aprender nuevas características a partir de los datos de entrada.
Dado que la implementación técnica se realizará utilizando TensorFlow 2, la siguiente sección tiene como objetivo proporcionar una visión completa de los diferentes componentes de este marco para construir eficientemente modelos de aprendizaje profundo.
Google desarrolló TensorFlow en noviembre de 2015. Lo definen como un marco de aprendizaje automático de código abierto para todos por varias razones.
Todas estas funcionalidades hacen de Tensorflow un buen candidato para construir redes neuronales.
Además, la instalación de Tensorflow 2 es sencilla y puede realizarse de la siguiente manera utilizando el gestor de paquetes de Python pip como se explica en la documentación oficial.
Tras la instalación, podemos ver que la versión utilizada es la 2.9.1
import tensorflow as tf
print("TensorFlow version:", tf.__version__)Ahora, vamos a explorar más a fondo los componentes principales para crear esas redes.
Cuando construimos modelos de aprendizaje automático y aprendizaje profundo, nos enfrentamos principalmente a datos de alta dimensión. Los tensores son matrices multidimensionales con un tipo uniforme que se utilizan para representar distintas características de los datos.
A continuación se muestra la representación gráfica de los distintos tipos de dimensiones de los tensores.
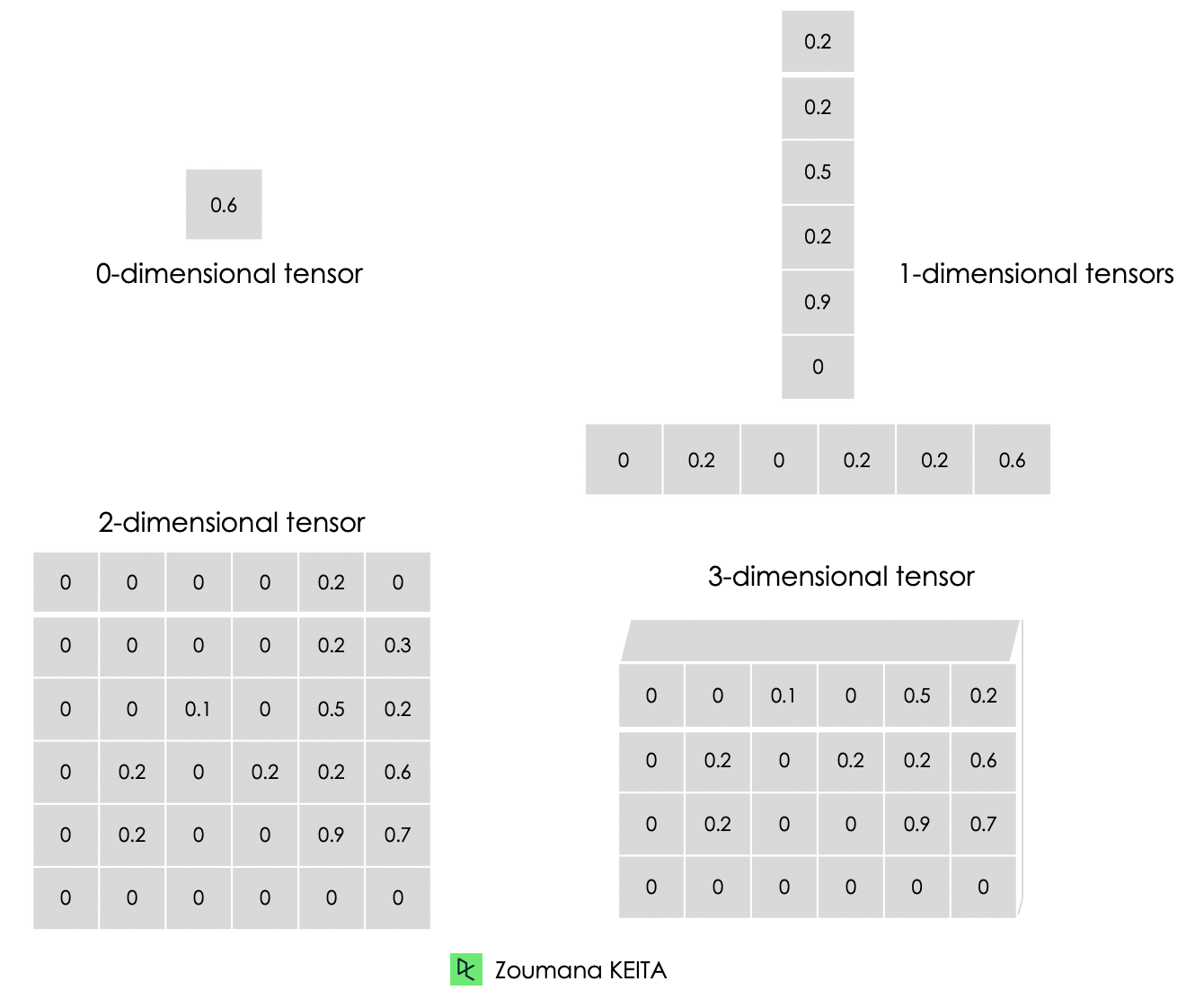
A continuación se muestra una ilustración de un cero a un tensor tridimensional. Cada tensor se crea utilizando la función constant() de TensorFlow.
# Zero dimensional tensor
zero_dim_tensor = tf.constant(20)
print(zero_dim_tensor)
# One dimensional tensor
one_dim_tensor = tf.constant([12, 20, 53, 26, 11, 56])
print(one_dim_tensor)
# Two dimensional tensor
two_dim_array = [[3, 6, 7, 5],
[9, 2, 3, 4],
[7, 1, 10,6],
[0, 8, 11,2]]
two_dim_tensor = tf.constant(two_dim_array)
print(two_dim_tensor)Una ejecución correcta del código anterior debería generar los resultados que aparecen a continuación, y podemos observar la palabra clave "tf.Tensor" para significar que el resultado es un tensor. Tiene tres parámetros:

Nuestro Tutorial de Tensorflow para principiantes proporciona una visión completa de TensorFlow y enseña a construir y entrenar modelos.
Mucha gente confunde los tensores con las matrices. Aunque estos dos objetos se parecen, tienen propiedades completamente distintas. Esta sección permite comprender mejor la diferencia entre matrices y tensores.
A diferencia de las matrices, los tensores son más adecuados para los problemas de aprendizaje profundo por las siguientes razones:
Las constantes no son los únicos tipos de tensores. También hay variables y marcadores de posición, que son los componentes básicos de un grafo computacional.
Un grafo computacional es básicamente y una representación de una secuencia de operaciones y del flujo de datos entre ellas.
Ahora, entendamos la diferencia entre estos tipos de tensores.
Las constantes son tensores cuyos valores no cambian durante la ejecución del gráfico de cálculo. Se crean utilizando la función tf.constant() y se utilizan principalmente para almacenar parámetros fijos que no requieren ningún cambio durante el entrenamiento del modelo.
Las variables son tensores cuyo valor puede modificarse durante la ejecución del gráfico de cálculo y se crean mediante la funcióntf.Variable(). Por ejemplo, en el caso de las redes neuronales, los pesos y los sesgos pueden definirse como variables, ya que deben actualizarse durante el proceso de entrenamiento.
Se utilizaron en la primera versión de Tensorflow como contenedores vacíos que no tienen valores específicos. Sólo se utilizan para invertir un lugar para los datos que se utilizarán en el futuro. Esto da a los usuarios la libertad de utilizar diferentes conjuntos de datos y tamaños de lote durante el entrenamiento y la validación del modelo.
En la versión 2 de Tensorflow, los marcadores de posición se han sustituido por la función tf.function() que es un enfoque más pitónico y dinámico para introducir datos en el grafo computacional.
Pongamos en práctica todo lo que hemos aprendido anteriormente. Esta sección ilustrará la implementación de extremo a extremo de una red neuronal convolucional en TensorFlow aplicada al conjunto de datos CIFAR-10, que es un conjunto de datos incorporado con las siguientes propiedades:
El código fuente del artículo está disponible en el espacio de trabajo de DataCamp
Antes de entrar en la implementación técnica, entendamos primero la arquitectura general de la red que se está implementando.
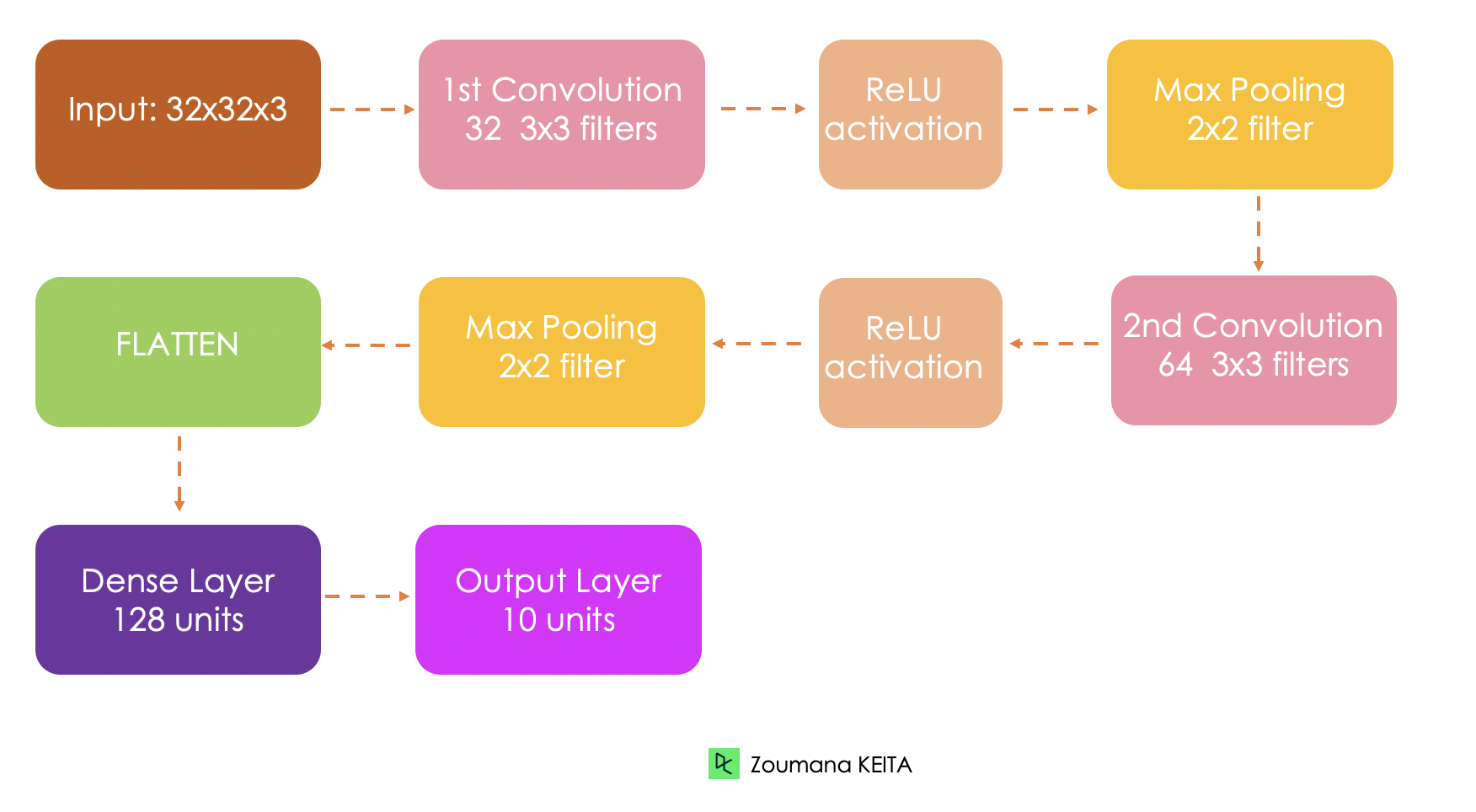
El conjunto de datos incorporado se carga desde keras.datasets() del siguiente modo
(train_images, train_labels), (test_images, test_labels) = cf10.load_data()En esta sección, nos centraremos únicamente en mostrar algunas imágenes de muestra, puesto que ya conocemos la proporción de cada clase tanto en los datos de entrenamiento como en los de prueba.
La función de ayuda show_images() muestra por defecto un total de 12 imágenes y toma tres parámetros principales:
import matplotlib.pyplot as plt
def show_images(train_images,
class_names,
train_labels,
nb_samples = 12, nb_row = 4):
plt.figure(figsize=(12, 12))
for i in range(nb_samples):
plt.subplot(nb_row, nb_row, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i][0]])
plt.show()Ahora, podemos llamar a la función con los parámetros necesarios.
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
show_images(train_images, class_names, train_labels)Una ejecución correcta del código anterior genera las imágenes siguientes.

Antes de entrenar el modelo, tenemos que normalizar los valores de los píxeles de los datos en el mismo rango (por ejemplo, de 0 a 1). Se trata de un paso de preprocesamiento habitual cuando se trabaja con imágenes, para garantizar la invariabilidad de escala y una convergencia más rápida durante el entrenamiento.
max_pixel_value = 255
train_images = train_images / max_pixel_value
test_images = test_images / max_pixel_valueAdemás, observamos que las etiquetas se representan en un formato categórico como gato, caballo, pájaro, etc. Necesitamos convertirlos a un formato numérico para que puedan ser procesados fácilmente por la red neuronal.
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels, len(class_names))
test_labels = to_categorical(test_labels, len(class_names))El siguiente paso es poner en práctica la arquitectura de la red basándonos en la descripción anterior.
En primer lugar, definimos el modelo utilizando la función Secuencial() y cada capa se añade al modelo con la función añadir() .
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Variables
INPUT_SHAPE = (32, 32, 3)
FILTER1_SIZE = 32
FILTER2_SIZE = 64
FILTER_SHAPE = (3, 3)
POOL_SHAPE = (2, 2)
FULLY_CONNECT_NUM = 128
NUM_CLASSES = len(class_names)
# Model architecture implementation
model = Sequential()
model.add(Conv2D(FILTER1_SIZE, FILTER_SHAPE, activation='relu', input_shape=INPUT_SHAPE))
model.add(MaxPooling2D(POOL_SHAPE))
model.add(Conv2D(FILTER2_SIZE, FILTER_SHAPE, activation='relu'))
model.add(MaxPooling2D(POOL_SHAPE))
model.add(Flatten())
model.add(Dense(FULLY_CONNECT_NUM, activation='relu'))
model.add(Dense(NUM_CLASSES, activation='softmax'))Tras aplicar la función summary() al modelo, obtenemos un resumen completo de la arquitectura del modelo con información sobre cada capa, su tipo, la forma de salida y el número total de parámetros entrenables.

Todos los recursos están finalmente disponibles para configurar y activar el entrenamiento del modelo. Esto se hace, respectivamente, con las funciones compile() y fit(), que toman los siguientes parámetros :
from tensorflow.keras.metrics import Precision, Recall
BATCH_SIZE = 32
EPOCHS = 30
METRICS = metrics=['accuracy',
Precision(name='precision'),
Recall(name='recall')]
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics = METRICS)
# Train the model
training_history = model.fit(train_images, train_labels,
epochs=EPOCHS, batch_size=BATCH_SIZE,
validation_data=(test_images, test_labels))Tras el entrenamiento del modelo, podemos comparar su rendimiento en los conjuntos de datos de entrenamiento y de prueba trazando las métricas anteriores mediante la función mostrar_curva_de_rendimiento() en dos dimensiones.
Para una mejor visualización, se traza una línea roja vertical a través de la intersección de los valores de rendimiento de entrenamiento y validación, junto con el valor óptimo.
def show_performance_curve(training_result, metric, metric_label):
train_perf = training_result.history[str(metric)]
validation_perf = training_result.history['val_'+str(metric)]
intersection_idx = np.argwhere(np.isclose(train_perf,
validation_perf, atol=1e-2)).flatten()[0]
intersection_value = train_perf[intersection_idx]
plt.plot(train_perf, label=metric_label)
plt.plot(validation_perf, label = 'val_'+str(metric))
plt.axvline(x=intersection_idx, color='r', linestyle='--', label='Intersection')
plt.annotate(f'Optimal Value: {intersection_value:.4f}',
xy=(intersection_idx, intersection_value),
xycoords='data',
fontsize=10,
color='green')
plt.xlabel('Epoch')
plt.ylabel(metric_label)
plt.legend(loc='lower right')A continuación, se aplica la función tanto para la exactitud como para la precisión del modelo.
show_performance_curve(training_history, 'accuracy', 'accuracy')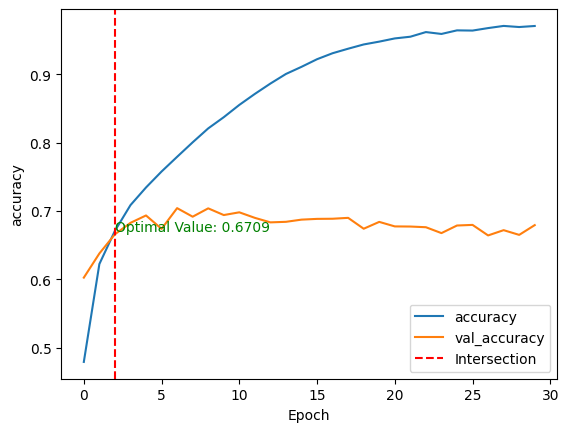
show_performance_curve(training_history, 'precision', 'precision')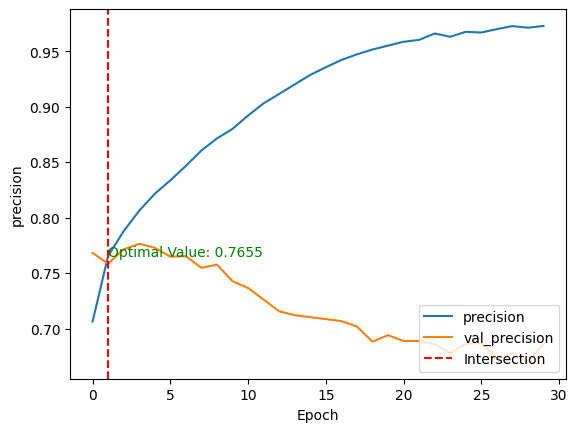
Tras entrenar el modelo sin ningún ajuste fino ni preprocesamiento, obtenemos:
Estas dos métricas proporcionan una comprensión global del comportamiento del modelo.
¿Y si queremos saber, para cada clase, cuáles son las que el modelo predice bien y aquellas con las que tiene dificultades?
Esto se puede conseguir a partir de la matriz de confusión, que muestra para cada clase el número de predicciones correctas y erróneas. La puesta en práctica se indica a continuación. Empezamos haciendo predicciones sobre los datos de prueba, luego calculamos la matriz de confusión y mostramos el resultado final.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
test_predictions = model.predict(test_images)
test_predicted_labels = np.argmax(test_predictions, axis=1)
test_true_labels = np.argmax(test_labels, axis=1)
cm = confusion_matrix(test_true_labels, test_predicted_labels)
cmd = ConfusionMatrixDisplay(confusion_matrix=cm)
cmd.plot(include_values=True, cmap='viridis', ax=None, xticks_rotation='horizontal')
plt.show()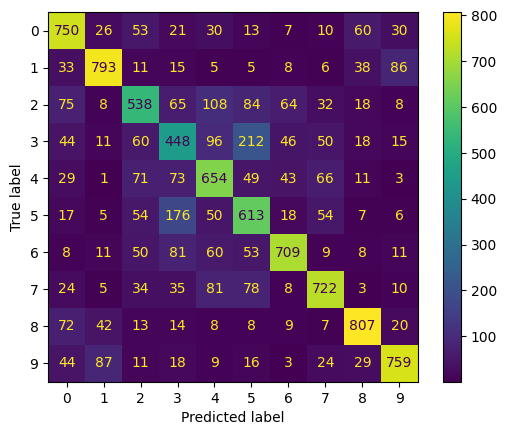
Aprende más sobre la matriz de confusión en nuestro tutorial Comprender la matriz de confusión en Rque toma material del curso Machine Learning toolbox de DataCamp.
Este modelo puede mejorarse con tareas adicionales como:
Este artículo ha cubierto una visión completa de las CNN en TensorFlow, proporcionando detalles sobre cada capa de la arquitectura de las CNN. Además, hizo una breve introducción a TensorFlow y cómo ayuda a los ingenieros e investigadores de aprendizaje automático a construir redes neuronales sofisticadas.
Aplicamos todos estos conjuntos de habilidades a un escenario del mundo real relacionado con una tarea de clasificación multiclase.
Nuestra guía para principiantes sobre la detección de objetos puede ser un gran paso para avanzar en tu aprendizaje de la visión por ordenador. Explora los componentes clave en la detección de objetos y explica cómo implementarlos en SSD y Faster RCNN disponibles en Tensorflow.
Cursos de Python
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Bharath K
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan



