Curso
Introdução ao Python
4 h
6.9M
Imagine estar em um zoológico tentando reconhecer se um determinado animal é um guepardo ou um leopardo. Como ser humano, seu cérebro pode analisar sem esforço as características corporais e faciais para chegar a uma conclusão válida. Da mesma forma, as redes neurais convolucionais (CNNs) podem ser treinadas para executar a mesma tarefa de reconhecimento, independentemente da complexidade dos padrões. Isso os torna poderosos no campo da visão computacional.
Este tutorial conceitual sobre CNN começará com uma visão geral do que são as CNNs e sua importância no aprendizado de máquina. Em seguida, você será guiado por uma implementação passo a passo da CNN no TensorFlow Framework 2.
Uma rede neural convolucional (CNN ou ConvNet) é um algoritmo de aprendizagem profunda projetado especificamente para qualquer tarefa em que o reconhecimento de objetos seja crucial, como classificação, detecção e segmentação de imagens. Muitos aplicativos da vida real, como carros autônomos, câmeras de vigilância e outros, usam CNNs.
Esses são vários motivos pelos quais as CNNs são importantes, conforme destacado abaixo:
A arquitetura das CNNs tenta imitar a estrutura dos neurônios no sistema visual humano, composta de várias camadas, em que cada uma é responsável pela detecção de um recurso específico nos dados. Conforme ilustrado na imagem abaixo, a CNN típica é feita de uma combinação de quatro camadas principais:
Vamos entender como cada uma dessas camadas funciona usando o seguinte exemplo de classificação do dígito escrito à mão.
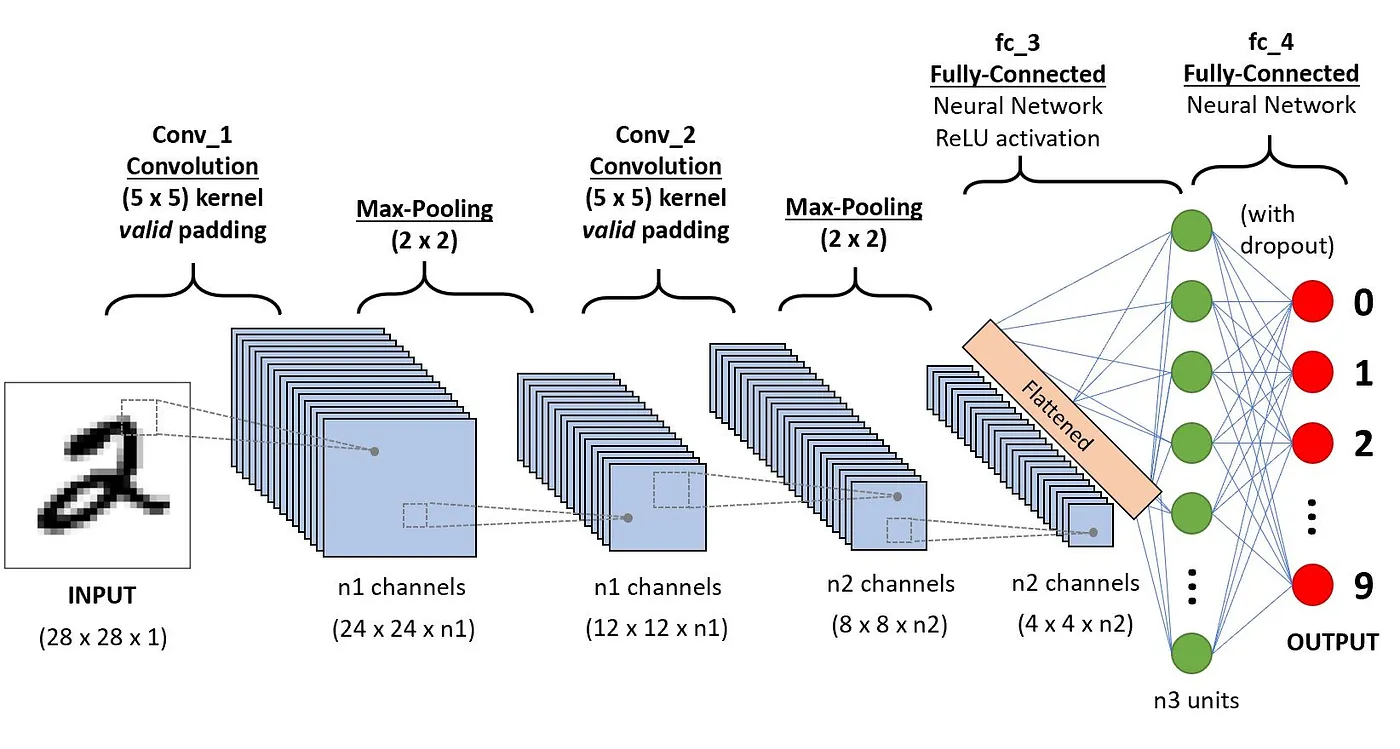
Esse é o primeiro bloco de construção de uma CNN. Como o nome sugere, a principal tarefa matemática realizada é chamada de convolução, que é a aplicação de uma função de janela deslizante a uma matriz de pixels que representa uma imagem. A função deslizante aplicada à matriz é chamada de kernel ou filtro, e ambos podem ser usados de forma intercambiável.
Na camada de convolução, são aplicados vários filtros de tamanho igual, e cada filtro é usado para reconhecer um padrão específico da imagem, como a curvatura dos dígitos, as bordas, a forma completa dos dígitos e muito mais.
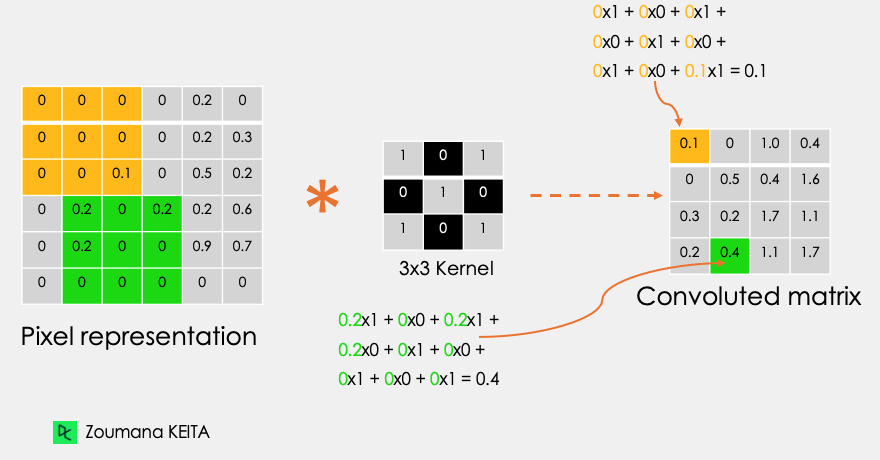
Vamos considerar esta imagem em escala de cinza 32x32 de um dígito manuscrito. Os valores na matriz são fornecidos para fins ilustrativos.
![]()
Além disso, vamos considerar o kernel usado para a convolução. É uma matriz com uma dimensão de 3x3. Os pesos de cada elemento do kernel são representados na grade. Os pesos zero são representados nas grades pretas e os pesos um na grade branca.
Você precisa encontrar esses pesos manualmente?
Na vida real, os pesos dos núcleos são determinados durante o processo de treinamento da rede neural.
Usando essas duas matrizes, podemos realizar a operação de convolução aplicando o produto escalar e trabalhar da seguinte forma:
A dimensão da matriz convoluta depende do tamanho da janela deslizante. Quanto maior a janela deslizante, menor a dimensão.
Outro nome associado ao kernel na literatura é detector de recursos, pois os pesos podem ser ajustados para detectar recursos específicos na imagem de entrada.
Por exemplo:
Quanto mais camadas de convolução a rede tiver, melhor será a camada na detecção de recursos mais abstratos.
Uma função de ativação ReLU é aplicada após cada operação de convolução. Essa função ajuda a rede a aprender relações não lineares entre os recursos da imagem, o que torna a rede mais robusta para identificar diferentes padrões. Isso também ajuda a atenuar os problemas de gradiente decrescente.
O objetivo da camada de agrupamento é extrair os recursos mais significativos da matriz convoluta. Isso é feito por meio da aplicação de algumas operações de agregação, o que reduz a dimensão do mapa de recursos (matriz convoluta) e, portanto, reduz a memória usada no treinamento da rede. O agrupamento também é relevante para atenuar o ajuste excessivo.
As funções de agregação mais comuns que podem ser aplicadas são:
Abaixo você encontra uma ilustração de cada um dos exemplos anteriores:
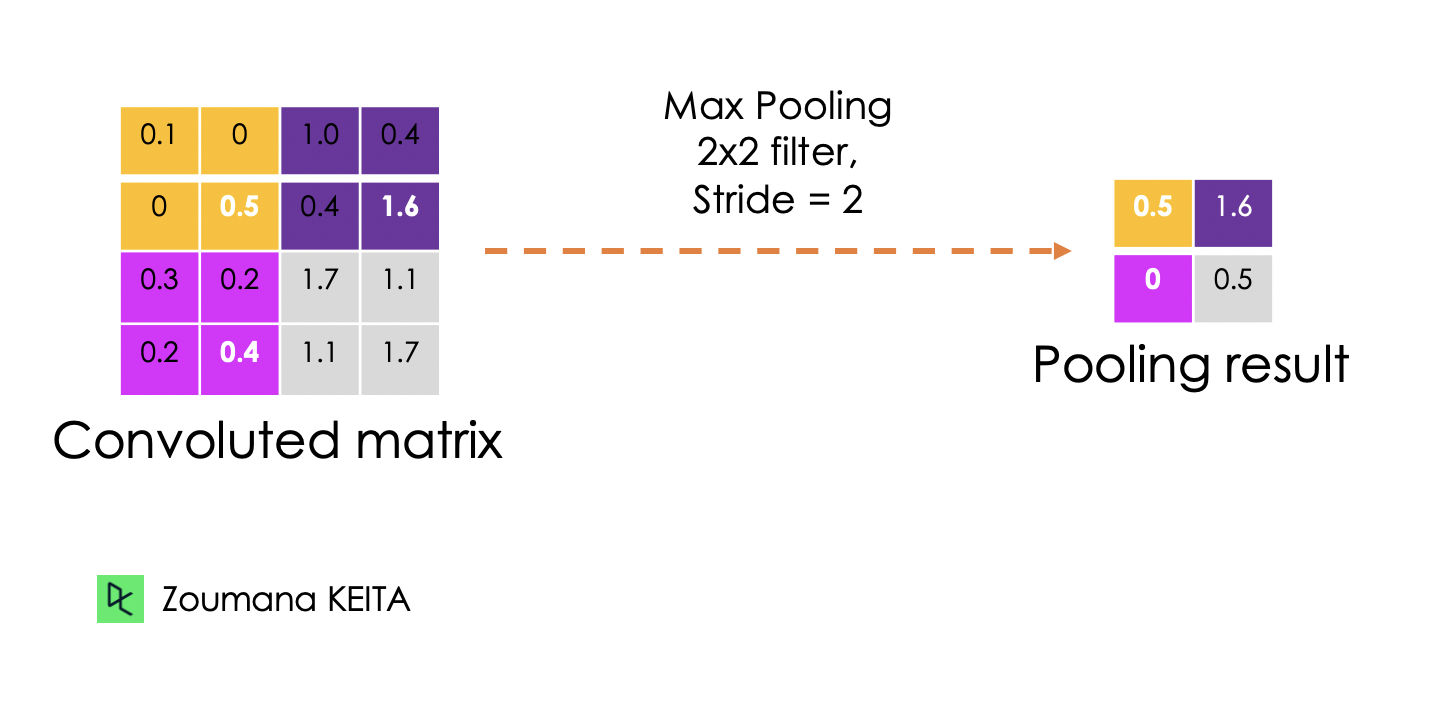
Além disso, a dimensão do mapa de recursos fica menor à medida que a função de sondagem é aplicada.
A última camada de agrupamento achata seu mapa de recursos para que ele possa ser processado pela camada totalmente conectada.
Essas camadas estão na última camada da rede neural convolucional, e suas entradas correspondem à matriz unidimensional achatada gerada pela última camada de agrupamento. As funções de ativação do ReLU são aplicadas a eles para obter a não linearidade.
Por fim, uma camada de previsão softmax é usada para gerar valores de probabilidade para cada um dos possíveis rótulos de saída, e o rótulo final previsto é aquele com a maior pontuação de probabilidade.
O abandono é uma técnica de regularização aplicada para melhorar a capacidade de generalização das redes neurais com um grande número de parâmetros. Consiste em descartar aleatoriamente alguns neurônios durante o processo de treinamento, o que força os neurônios restantes a aprender novos recursos com os dados de entrada.
Como a implementação técnica será realizada usando o TensorFlow 2, a próxima seção tem como objetivo fornecer uma visão geral completa dos diferentes componentes dessa estrutura para criar modelos de aprendizagem profunda com eficiência.
O Google desenvolveu o TensorFlow em novembro de 2015. Eles o definem como uma estrutura de aprendizado de máquina de código aberto para todos, por vários motivos.
Todas essas funcionalidades tornam o Tensorflow um bom candidato para a criação de redes neurais.
Além disso, a instalação do Tensorflow 2 é simples e pode ser feita da seguinte forma, usando o gerenciador de pacotes Python pip conforme explicado na documentação oficial.
Após a instalação, podemos ver que a versão que está sendo usada é a 2.9.1
import tensorflow as tf
print("TensorFlow version:", tf.__version__)Agora, vamos explorar melhor os principais componentes para criar essas redes.
Lidamos principalmente com dados de alta dimensão ao criar modelos de aprendizado de máquina e aprendizado profundo. Os tensores são matrizes multidimensionais com um tipo uniforme usado para representar diferentes recursos dos dados.
Abaixo está a representação gráfica dos diferentes tipos de dimensões dos tensores.
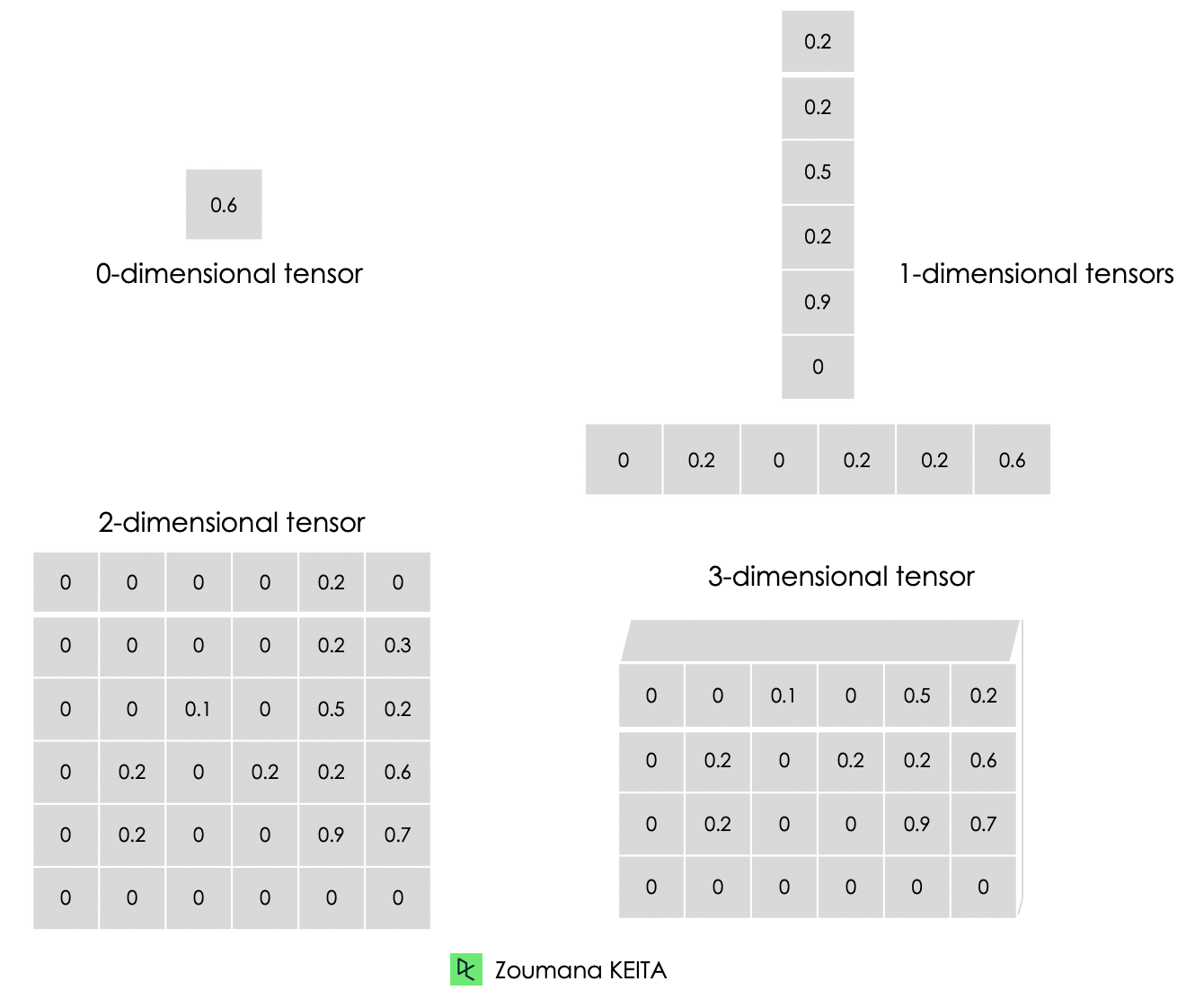
Abaixo você encontra uma ilustração de um zero para um tensor tridimensional. Cada tensor é criado usando a função constant() do TensorFlow.
# Zero dimensional tensor
zero_dim_tensor = tf.constant(20)
print(zero_dim_tensor)
# One dimensional tensor
one_dim_tensor = tf.constant([12, 20, 53, 26, 11, 56])
print(one_dim_tensor)
# Two dimensional tensor
two_dim_array = [[3, 6, 7, 5],
[9, 2, 3, 4],
[7, 1, 10,6],
[0, 8, 11,2]]
two_dim_tensor = tf.constant(two_dim_array)
print(two_dim_tensor)Uma execução bem-sucedida do código anterior deve gerar os resultados abaixo, e podemos observar a palavra-chave "tf.Tensor" para indicar que o resultado é um tensor. Ele tem três parâmetros:

Nosso tutorial do Tensorflow para iniciantes oferece uma visão geral completa do TensorFlow e ensina como criar e treinar modelos.
Muitas pessoas confundem tensores com matrizes. Embora esses dois objetos pareçam semelhantes, eles têm propriedades completamente diferentes. Esta seção fornece uma melhor compreensão da diferença entre matrizes e tensores.
Ao contrário das matrizes, os tensores são mais adequados para problemas de aprendizagem profunda pelos seguintes motivos:
As constantes não são os únicos tipos de tensores. Há também variáveis e espaços reservados, que são todos blocos de construção de um gráfico computacional.
Um gráfico computacional é basicamente uma representação de uma sequência de operações e do fluxo de dados entre elas.
Agora, vamos entender a diferença entre esses tipos de tensores.
Constantes são tensores cujos valores não mudam durante a execução do gráfico computacional. Eles são criados usando a função tf.constant() e são usados principalmente para armazenar parâmetros fixos que não exigem nenhuma alteração durante o treinamento do modelo.
As variáveis são tensores cujo valor pode ser alterado durante a execução do gráfico computacional e são criadas usando a funçãotf.Variable(). Por exemplo, no caso das redes neurais, os pesos e as tendências podem ser definidos como variáveis, pois precisam ser atualizados durante o processo de treinamento.
Eles foram usados na primeira versão do Tensorflow como contêineres vazios que não têm valores específicos. Eles são usados apenas para reverter um ponto para os dados a serem usados no futuro. Isso dá aos usuários a liberdade de usar diferentes conjuntos de dados e tamanhos de lote durante o treinamento e a validação do modelo.
Na versão 2 do Tensorflow, os espaços reservados foram substituídos pela função tf.function() que é uma abordagem mais pitônica e dinâmica para alimentar dados no gráfico computacional.
Vamos colocar em prática tudo o que aprendemos anteriormente. Esta seção ilustrará a implementação de ponta a ponta de uma rede neural convolucional no TensorFlow aplicada ao conjunto de dados CIFAR-10, que é um conjunto de dados incorporado com as seguintes propriedades:
O código-fonte do artigo está disponível no espaço de trabalho da DataCamp
Antes de entrar na implementação técnica, vamos primeiro entender a arquitetura geral da rede que está sendo implementada.
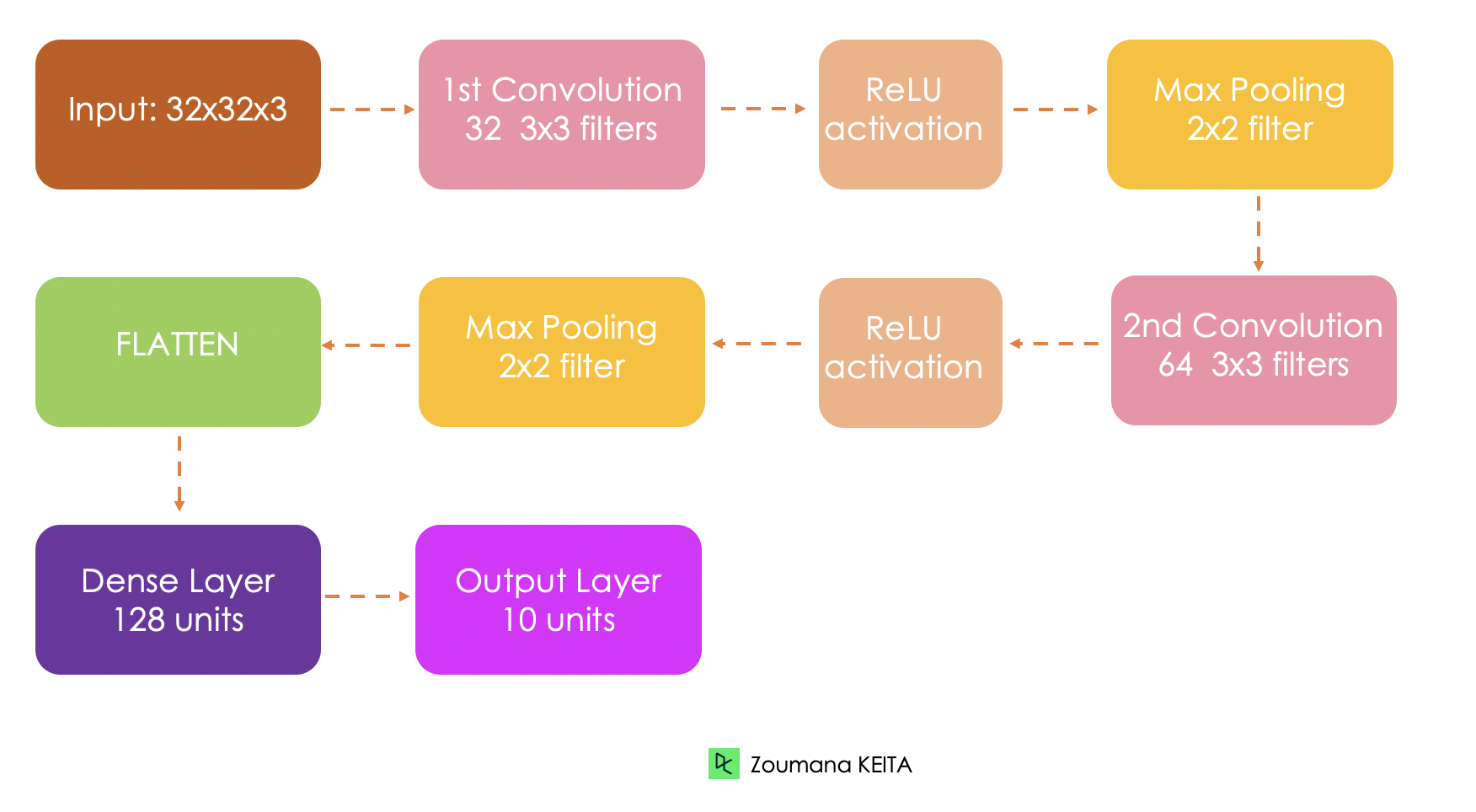
O conjunto de dados incorporado é carregado a partir do keras.datasets() da seguinte forma:
(train_images, train_labels), (test_images, test_labels) = cf10.load_data()Nesta seção, vamos nos concentrar apenas em mostrar algumas imagens de amostra, pois já sabemos a proporção de cada classe nos dados de treinamento e de teste.
A função auxiliar show_images() mostra um total de 12 imagens por padrão e usa três parâmetros principais:
import matplotlib.pyplot as plt
def show_images(train_images,
class_names,
train_labels,
nb_samples = 12, nb_row = 4):
plt.figure(figsize=(12, 12))
for i in range(nb_samples):
plt.subplot(nb_row, nb_row, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i][0]])
plt.show()Agora, podemos chamar a função com os parâmetros necessários.
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
show_images(train_images, class_names, train_labels)Uma execução bem-sucedida do código anterior gera as imagens abaixo.

Antes de treinar o modelo, precisamos normalizar os valores de pixel dos dados no mesmo intervalo (por exemplo, de 0 a 1). Essa é uma etapa comum de pré-processamento ao lidar com imagens para garantir a invariância de escala e uma convergência mais rápida durante o treinamento.
max_pixel_value = 255
train_images = train_images / max_pixel_value
test_images = test_images / max_pixel_valueAlém disso, notamos que os rótulos são representados em um formato categórico, como gato, cavalo, pássaro e assim por diante. Precisamos convertê-los em um formato numérico para que possam ser facilmente processados pela rede neural.
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels, len(class_names))
test_labels = to_categorical(test_labels, len(class_names))A próxima etapa é implementar a arquitetura da rede com base na descrição anterior.
Primeiro, definimos o modelo usando a função Sequential() e cada camada é adicionada ao modelo com a função add() e cada camada é adicionada ao modelo com a função add().
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Variables
INPUT_SHAPE = (32, 32, 3)
FILTER1_SIZE = 32
FILTER2_SIZE = 64
FILTER_SHAPE = (3, 3)
POOL_SHAPE = (2, 2)
FULLY_CONNECT_NUM = 128
NUM_CLASSES = len(class_names)
# Model architecture implementation
model = Sequential()
model.add(Conv2D(FILTER1_SIZE, FILTER_SHAPE, activation='relu', input_shape=INPUT_SHAPE))
model.add(MaxPooling2D(POOL_SHAPE))
model.add(Conv2D(FILTER2_SIZE, FILTER_SHAPE, activation='relu'))
model.add(MaxPooling2D(POOL_SHAPE))
model.add(Flatten())
model.add(Dense(FULLY_CONNECT_NUM, activation='relu'))
model.add(Dense(NUM_CLASSES, activation='softmax'))Depois de aplicar a função summary() ao modelo, obtemos um resumo abrangente da arquitetura do modelo com informações sobre cada camada, seu tipo, forma de saída e o número total de parâmetros treináveis.

Todos os recursos estão finalmente disponíveis para configurar e acionar o treinamento do modelo. Isso é feito respectivamente com as funções compile() e fit(), que recebem os seguintes parâmetros :
from tensorflow.keras.metrics import Precision, Recall
BATCH_SIZE = 32
EPOCHS = 30
METRICS = metrics=['accuracy',
Precision(name='precision'),
Recall(name='recall')]
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics = METRICS)
# Train the model
training_history = model.fit(train_images, train_labels,
epochs=EPOCHS, batch_size=BATCH_SIZE,
validation_data=(test_images, test_labels))Após o treinamento do modelo, podemos comparar seu desempenho nos conjuntos de dados de treinamento e de teste, plotando as métricas acima usando o método show_performance_curve() em duas dimensões.
Para melhor visualização, uma linha vermelha vertical é desenhada através da interseção dos valores de desempenho de treinamento e validação, juntamente com o valor ideal.
def show_performance_curve(training_result, metric, metric_label):
train_perf = training_result.history[str(metric)]
validation_perf = training_result.history['val_'+str(metric)]
intersection_idx = np.argwhere(np.isclose(train_perf,
validation_perf, atol=1e-2)).flatten()[0]
intersection_value = train_perf[intersection_idx]
plt.plot(train_perf, label=metric_label)
plt.plot(validation_perf, label = 'val_'+str(metric))
plt.axvline(x=intersection_idx, color='r', linestyle='--', label='Intersection')
plt.annotate(f'Optimal Value: {intersection_value:.4f}',
xy=(intersection_idx, intersection_value),
xycoords='data',
fontsize=10,
color='green')
plt.xlabel('Epoch')
plt.ylabel(metric_label)
plt.legend(loc='lower right')Em seguida, a função é aplicada tanto para a exatidão quanto para a precisão do modelo.
show_performance_curve(training_history, 'accuracy', 'accuracy')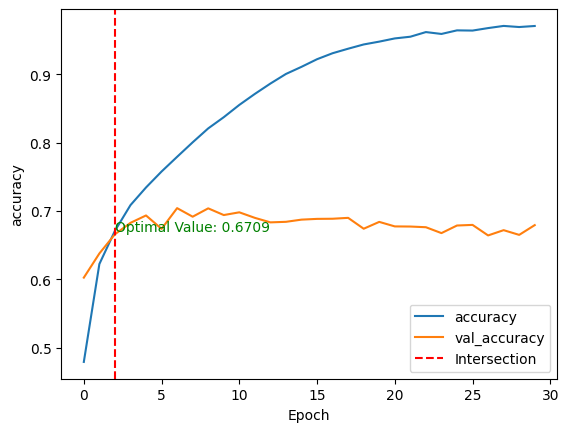
show_performance_curve(training_history, 'precision', 'precision')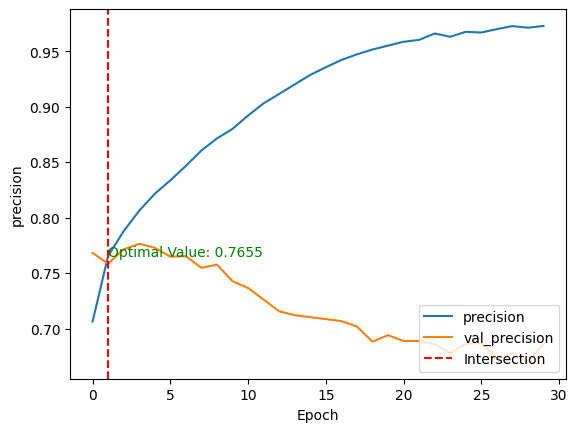
Depois de treinar o modelo sem nenhum ajuste fino e pré-processamento, obtemos o resultado final:
Essas duas métricas fornecem uma compreensão global do comportamento do modelo.
E se quisermos saber, para cada classe, quais são as classes que o modelo é bom em prever e aquelas em que o modelo tem dificuldades?
Isso pode ser obtido com a matriz de confusão, que mostra para cada classe o número de previsões corretas e erradas. A implementação é apresentada a seguir. Começamos fazendo previsões sobre os dados de teste, depois calculamos a matriz de confusão e mostramos o resultado final.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
test_predictions = model.predict(test_images)
test_predicted_labels = np.argmax(test_predictions, axis=1)
test_true_labels = np.argmax(test_labels, axis=1)
cm = confusion_matrix(test_true_labels, test_predicted_labels)
cmd = ConfusionMatrixDisplay(confusion_matrix=cm)
cmd.plot(include_values=True, cmap='viridis', ax=None, xticks_rotation='horizontal')
plt.show()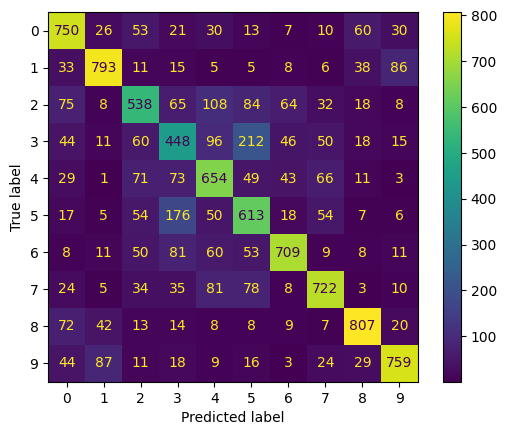
Saiba mais sobre a matriz de confusão em nosso tutorial Entendendo a matriz de confusão em Rque utiliza o material do curso Caixa de ferramentas de aprendizado de máquina do DataCamp.
Esse modelo pode ser aprimorado com tarefas adicionais, como:
Este artigo abordou uma visão geral completa das CNNs no TensorFlow, fornecendo detalhes sobre cada camada da arquitetura das CNNs. Além disso, ele fez uma breve introdução ao TensorFlow e como ele ajuda os engenheiros e pesquisadores de aprendizado de máquina a criar redes neurais sofisticadas.
Aplicamos todos esses conjuntos de habilidades a um cenário do mundo real relacionado a uma tarefa de classificação multiclasse.
Nosso guia para iniciantes em detecção de objetos pode ser um ótimo próximo passo para você aprender mais sobre visão computacional. Ele explora os principais componentes da detecção de objetos e explica como implementar o SSD e o RCNN mais rápido disponíveis no Tensorflow.
Cursos de Python
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Bharath K
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan



