Cours
Introduction à Python
4 h
6.9M
Imaginez que vous vous trouviez dans un zoo et que vous essayiez de reconnaître si un animal donné est un guépard ou un léopard. En tant qu'être humain, votre cerveau peut analyser sans effort les caractéristiques du corps et du visage pour parvenir à une conclusion valable. De la même manière, les réseaux neuronaux convolutifs (CNN) peuvent être entraînés à effectuer la même tâche de reconnaissance, quelle que soit la complexité des motifs. Cela leur confère une grande puissance dans le domaine de la vision par ordinateur.
Ce tutoriel sur les CNN conceptuels commencera par donner un aperçu de ce que sont les CNN et de leur importance dans l'apprentissage automatique. Ensuite, il vous guidera pas à pas dans l'implémentation de CNN dans TensorFlow Framework 2.
Un réseau neuronal convolutif (CNN ou ConvNet) est un algorithme d'apprentissage profond spécialement conçu pour toute tâche où la reconnaissance d'objets est cruciale, comme la classification, la détection et la segmentation d'images. De nombreuses applications réelles, telles que les voitures autonomes, les caméras de surveillance et autres, utilisent les CNN.
Plusieurs raisons expliquent l'importance des CNN, comme indiqué ci-dessous :
L'architecture des CNN tente d'imiter la structure des neurones du système visuel humain, composée de plusieurs couches, où chacune est responsable de la détection d'une caractéristique spécifique dans les données. Comme l'illustre l'image ci-dessous, le CNN typique est constitué d'une combinaison de quatre couches principales :
Comprenons le fonctionnement de chacune de ces couches à l'aide de l'exemple suivant de classification d'un chiffre manuscrit.
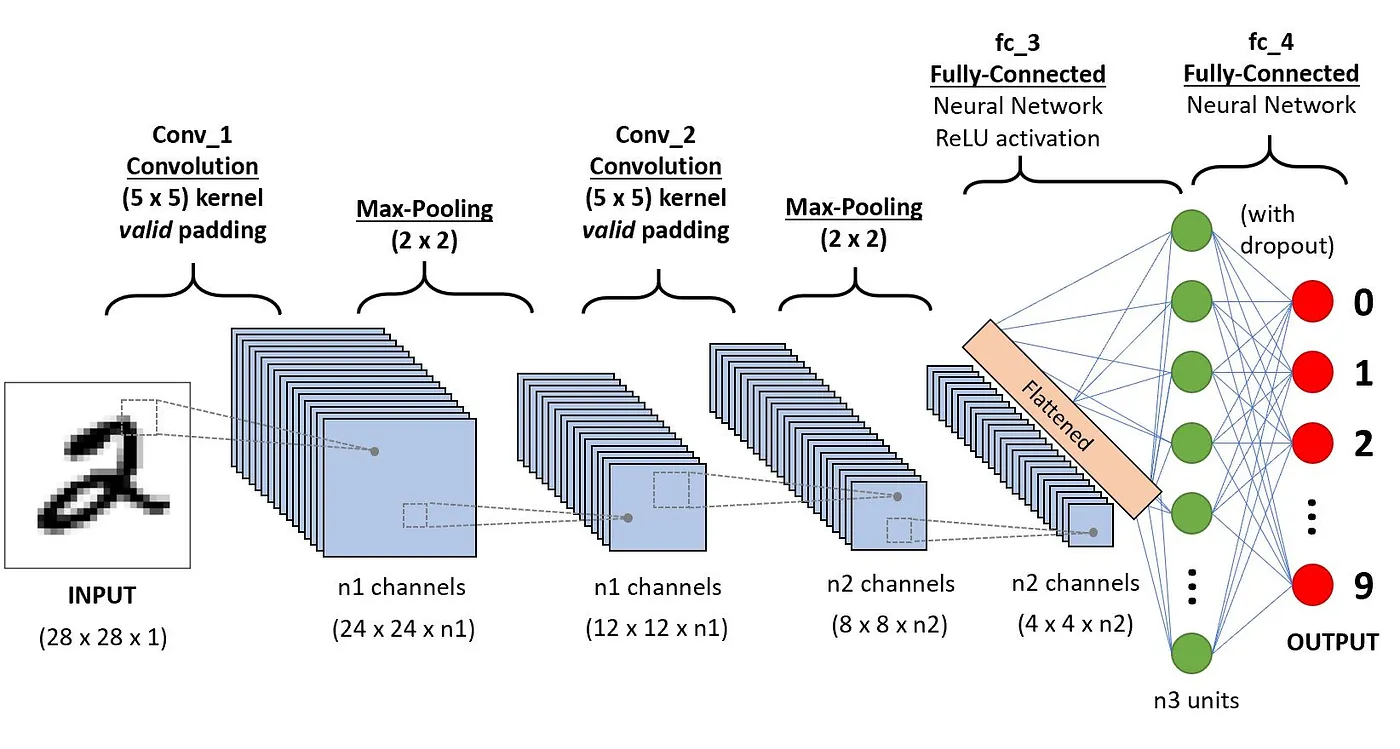
C'est le premier élément constitutif d'un CNN. Comme son nom l'indique, la principale tâche mathématique effectuée s'appelle la convolution, qui consiste à appliquer une fonction de fenêtre coulissante à une matrice de pixels représentant une image. La fonction de glissement appliquée à la matrice est appelée noyau ou filtre, les deux pouvant être utilisés de manière interchangeable.
Dans la couche de convolution, plusieurs filtres de taille égale sont appliqués, et chaque filtre est utilisé pour reconnaître un motif spécifique de l'image, comme la courbure des chiffres, les bords, la forme entière des chiffres, etc.
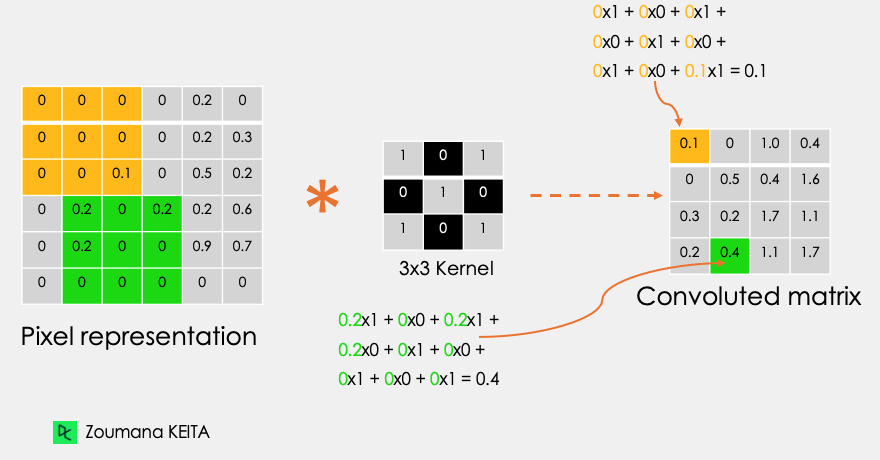
Considérons cette image 32x32 en niveaux de gris d'un chiffre écrit à la main. Les valeurs de la matrice sont données à titre d'illustration.
![]()
Considérons également le noyau utilisé pour la convolution. Il s'agit d'une matrice de dimension 3x3. Les poids de chaque élément du noyau sont représentés dans la grille. Les poids nuls sont représentés dans les grilles noires et les poids un dans les grilles blanches.
Devons-nous trouver manuellement ces poids ?
Dans la réalité, les poids des noyaux sont déterminés au cours du processus d'apprentissage du réseau neuronal.
En utilisant ces deux matrices, nous pouvons effectuer l'opération de convolution en appliquant le produit de point, et travailler comme suit :
La dimension de la matrice convoluée dépend de la taille de la fenêtre coulissante. Plus la fenêtre coulissante est grande, plus la dimension est petite.
Un autre nom associé au noyau dans la littérature est celui de détecteur de caractéristiques, car les poids peuvent être ajustés avec précision pour détecter des caractéristiques spécifiques dans l'image d'entrée.
Par exemple :
Plus le réseau comporte de couches de convolution, meilleure est la capacité de la couche à détecter des caractéristiques plus abstraites.
Une fonction d'activation ReLU est appliquée après chaque opération de convolution. Cette fonction aide le réseau à apprendre les relations non linéaires entre les caractéristiques de l'image, ce qui rend le réseau plus robuste pour l'identification de différents modèles. Elle permet également d'atténuer les problèmes de gradient de fuite.
L'objectif de la couche de mise en commun est d'extraire les caractéristiques les plus significatives de la matrice convoluée. Cela se fait en appliquant certaines opérations d'agrégation, qui réduisent la dimension de la carte des caractéristiques (matrice convoluée), réduisant ainsi la mémoire utilisée lors de l'entraînement du réseau. La mise en commun permet également d'atténuer l'ajustement excessif.
Les fonctions d'agrégation les plus courantes qui peuvent être appliquées sont les suivantes :
Vous trouverez ci-dessous une illustration de chacun des exemples précédents :
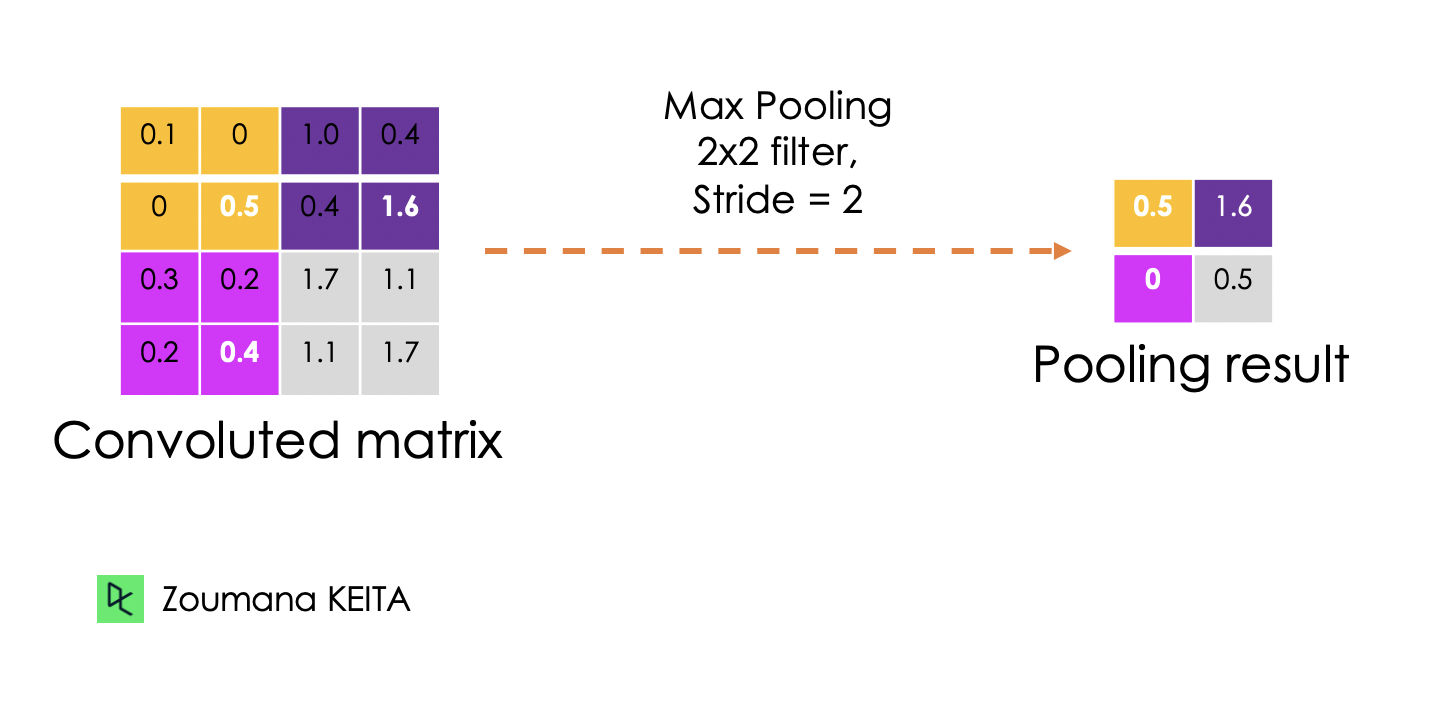
En outre, la dimension de la carte de caractéristiques diminue au fur et à mesure de l'application de la fonction de sondage.
La dernière couche de mise en commun aplatit sa carte de caractéristiques afin qu'elle puisse être traitée par la couche entièrement connectée.
Ces couches se trouvent dans la dernière couche du réseau neuronal convolutif et leurs entrées correspondent à la matrice unidimensionnelle aplatie générée par la dernière couche de mise en commun. Les fonctions d'activation ReLU leur sont appliquées pour assurer la non-linéarité.
Enfin, une couche de prédiction softmax est utilisée pour générer des valeurs de probabilité pour chacune des étiquettes de sortie possibles, et l'étiquette finale prédite est celle qui présente le score de probabilité le plus élevé.
L'exclusion est une technique de régularisation appliquée pour améliorer la capacité de généralisation des réseaux neuronaux avec un grand nombre de paramètres. Elle consiste à supprimer aléatoirement certains neurones au cours du processus de formation, ce qui oblige les neurones restants à apprendre de nouvelles caractéristiques à partir des données d'entrée.
Étant donné que la mise en œuvre technique sera effectuée à l'aide de TensorFlow 2, la section suivante vise à fournir une vue d'ensemble complète des différents composants de ce cadre pour construire efficacement des modèles d'apprentissage profond.
Google a développé TensorFlow en novembre 2015. Ils le définissent comme un cadre d'apprentissage machine open-source pour tout le monde, et ce pour plusieurs raisons.
Toutes ces fonctionnalités font de Tensorflow un bon candidat pour la construction de réseaux neuronaux.
Par ailleurs, l'installation de Tensorflow 2 est simple et peut être réalisée comme suit à l'aide du gestionnaire de paquets Python. pip comme expliqué dans la documentation officielle.
Après l'installation, nous pouvons voir que la version utilisée est la 2.9.1.
import tensorflow as tf
print("TensorFlow version:", tf.__version__)Explorons maintenant plus en détail les principaux éléments permettant de créer ces réseaux.
Nous traitons principalement des données à haute dimension lorsque nous construisons des modèles d'apprentissage automatique et d'apprentissage profond. Les tenseurs sont des tableaux multidimensionnels d'un type uniforme utilisés pour représenter différentes caractéristiques des données.
Vous trouverez ci-dessous la représentation graphique des différents types de dimensions des tenseurs.
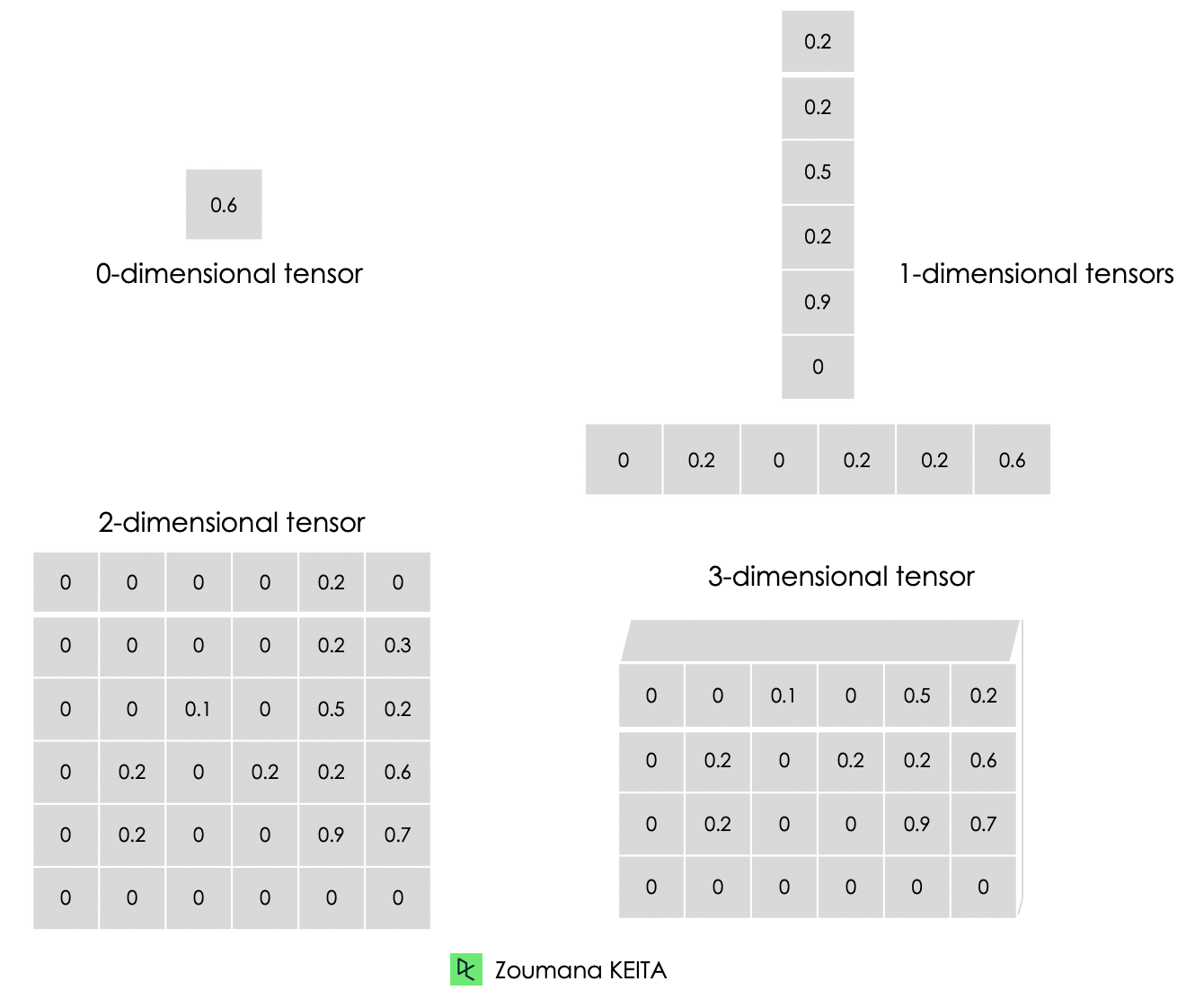
Vous trouverez ci-dessous une illustration du passage d'un zéro à un tenseur tridimensionnel. Chaque tenseur est créé à l'aide de la fonction constant() de TensorFlow.
# Zero dimensional tensor
zero_dim_tensor = tf.constant(20)
print(zero_dim_tensor)
# One dimensional tensor
one_dim_tensor = tf.constant([12, 20, 53, 26, 11, 56])
print(one_dim_tensor)
# Two dimensional tensor
two_dim_array = [[3, 6, 7, 5],
[9, 2, 3, 4],
[7, 1, 10,6],
[0, 8, 11,2]]
two_dim_tensor = tf.constant(two_dim_array)
print(two_dim_tensor)Une exécution réussie du code précédent devrait générer les résultats ci-dessous, et nous pouvons remarquer le mot-clé "tf.Tensor" pour signifier que le résultat est un tenseur. Il comporte trois paramètres :

Notre tutoriel Tensorflow pour les débutants fournit une vue d'ensemble complète de TensorFlow et enseigne comment construire et former des modèles.
De nombreuses personnes confondent les tenseurs avec les matrices. Même si ces deux objets se ressemblent, ils ont des propriétés complètement différentes. Cette section permet de mieux comprendre la différence entre les matrices et les tenseurs.
Contrairement aux matrices, les tenseurs sont mieux adaptés aux problèmes d'apprentissage profond pour les raisons suivantes :
Les constantes ne sont pas les seuls types de tenseurs. Il existe également des variables et des espaces réservés, qui sont autant d'éléments constitutifs d'un graphe de calcul.
Un graphique de calcul est essentiellement une représentation d'une séquence d'opérations et du flux de données entre elles.
Comprenons maintenant la différence entre ces types de tenseurs.
Les constantes sont des tenseurs dont les valeurs ne changent pas pendant l'exécution du graphique de calcul. Ils sont créés à l'aide de la fonction tf.constant() et sont principalement utilisés pour stocker des paramètres fixes qui ne nécessitent aucune modification au cours de l'apprentissage du modèle.
Les variables sont des tenseurs dont la valeur peut être modifiée au cours de l'exécution du graphique de calcul. Elles sont créées à l'aide de la fonctiontf.Variable(). Par exemple, dans le cas des réseaux neuronaux, les poids et les biais peuvent être définis comme des variables puisqu'ils doivent être mis à jour au cours du processus de formation.
Ils ont été utilisés dans la première version de Tensorflow comme des conteneurs vides qui n'ont pas de valeurs spécifiques. Ils ne servent qu'à inverser un point pour les données qui seront utilisées à l'avenir. Cela donne aux utilisateurs la liberté d'utiliser différents ensembles de données et différentes tailles de lots lors de l'apprentissage et de la validation des modèles.
Dans la version 2 de Tensorflow, les placeholders ont été remplacés par la fonction tf.function() qui constitue une approche plus Python et plus dynamique de l'alimentation des données dans le graphe de calcul.
Mettons en pratique tout ce que nous avons appris précédemment. Cette section illustre la mise en œuvre de bout en bout d'un réseau neuronal convolutif dans TensorFlow appliqué à l'ensemble de données CIFAR-10, qui est un ensemble de données intégré présentant les propriétés suivantes :
Le code source de l'article est disponible sur l 'espace de travail de DataCamp
Avant d'aborder la mise en œuvre technique, il convient de comprendre l'architecture globale du réseau mis en place.
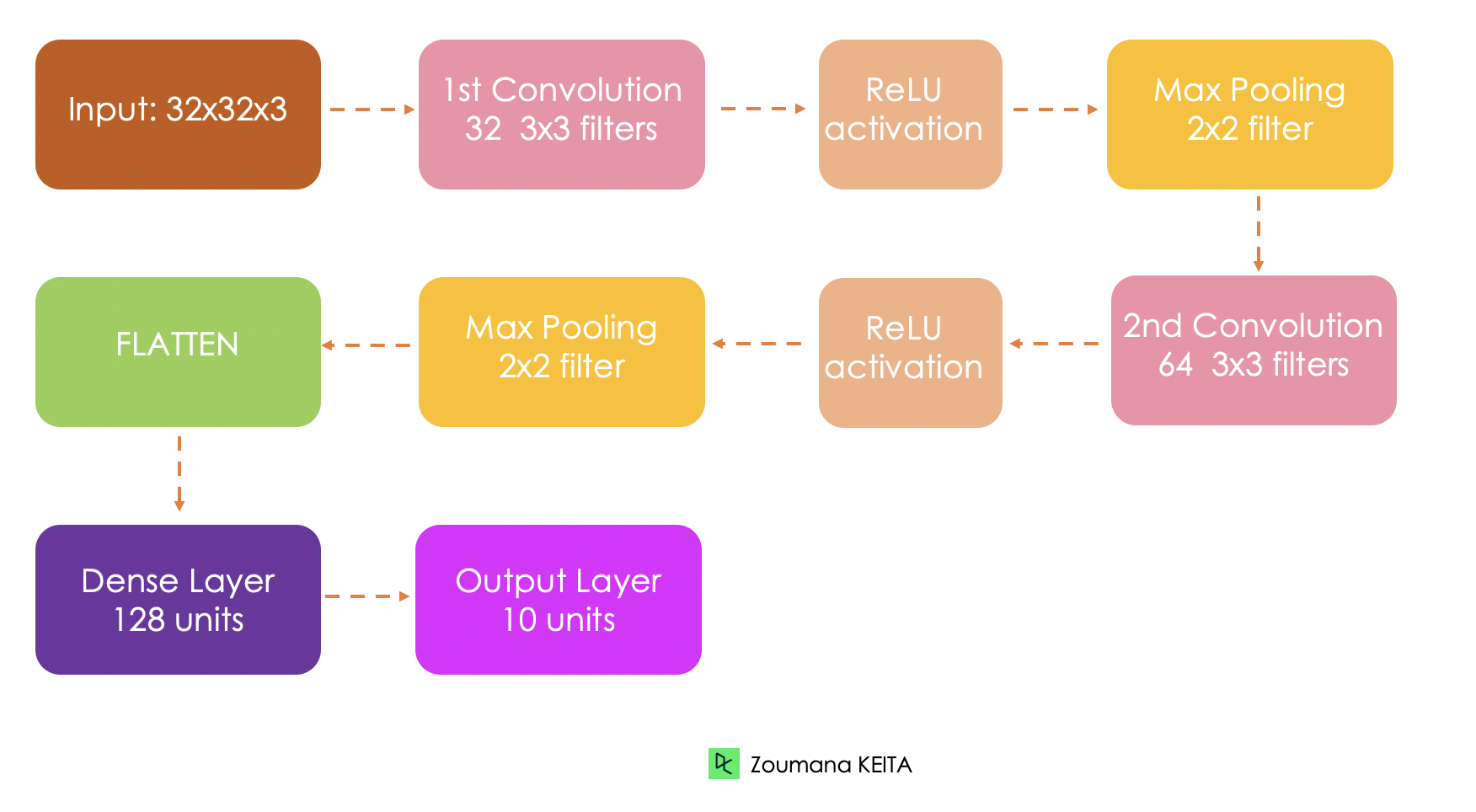
Le jeu de données intégré est chargé à partir de keras.datasets() comme suit :
(train_images, train_labels), (test_images, test_labels) = cf10.load_data()Dans cette section, nous nous concentrerons uniquement sur la présentation de quelques exemples d'images puisque nous connaissons déjà la proportion de chaque classe dans les données d'apprentissage et de test.
La fonction d'aide show_images() affiche un total de 12 images par défaut et prend trois paramètres principaux :
import matplotlib.pyplot as plt
def show_images(train_images,
class_names,
train_labels,
nb_samples = 12, nb_row = 4):
plt.figure(figsize=(12, 12))
for i in range(nb_samples):
plt.subplot(nb_row, nb_row, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i][0]])
plt.show()Nous pouvons maintenant appeler la fonction avec les paramètres requis.
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
show_images(train_images, class_names, train_labels)Une exécution réussie du code précédent génère les images ci-dessous.

Avant d'entraîner le modèle, nous devons normaliser les valeurs des pixels des données dans la même plage (par exemple, 0 à 1). Il s'agit d'une étape de prétraitement courante lorsqu'il s'agit d'images, afin de garantir l'invariance d'échelle et une convergence plus rapide lors de l'apprentissage.
max_pixel_value = 255
train_images = train_images / max_pixel_value
test_images = test_images / max_pixel_valueNous remarquons également que les étiquettes sont représentées sous forme de catégories telles que chat, cheval, oiseau, etc. Nous devons les convertir en format numérique afin qu'ils puissent être facilement traités par le réseau neuronal.
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels, len(class_names))
test_labels = to_categorical(test_labels, len(class_names))L'étape suivante consiste à mettre en œuvre l'architecture du réseau sur la base de la description précédente.
Tout d'abord, nous définissons le modèle à l'aide de la méthode Séquentielle() et chaque couche est ajoutée au modèle avec la méthode add() pour ajouter chaque couche au modèle.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Variables
INPUT_SHAPE = (32, 32, 3)
FILTER1_SIZE = 32
FILTER2_SIZE = 64
FILTER_SHAPE = (3, 3)
POOL_SHAPE = (2, 2)
FULLY_CONNECT_NUM = 128
NUM_CLASSES = len(class_names)
# Model architecture implementation
model = Sequential()
model.add(Conv2D(FILTER1_SIZE, FILTER_SHAPE, activation='relu', input_shape=INPUT_SHAPE))
model.add(MaxPooling2D(POOL_SHAPE))
model.add(Conv2D(FILTER2_SIZE, FILTER_SHAPE, activation='relu'))
model.add(MaxPooling2D(POOL_SHAPE))
model.add(Flatten())
model.add(Dense(FULLY_CONNECT_NUM, activation='relu'))
model.add(Dense(NUM_CLASSES, activation='softmax'))Après avoir appliqué la fonction summary() au modèle, nous obtenons un résumé complet de l'architecture du modèle avec des informations sur chaque couche, son type, sa forme de sortie et le nombre total de paramètres entraînables.

Toutes les ressources sont enfin disponibles pour configurer et déclencher l'entraînement du modèle. Cela se fait respectivement avec les fonctions compile() et fit() qui prennent les paramètres suivants :
from tensorflow.keras.metrics import Precision, Recall
BATCH_SIZE = 32
EPOCHS = 30
METRICS = metrics=['accuracy',
Precision(name='precision'),
Recall(name='recall')]
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics = METRICS)
# Train the model
training_history = model.fit(train_images, train_labels,
epochs=EPOCHS, batch_size=BATCH_SIZE,
validation_data=(test_images, test_labels))Après l'apprentissage du modèle, nous pouvons comparer ses performances sur les ensembles de données d'apprentissage et de test en traçant les métriques ci-dessus à l'aide de la fonction show_performance_curve() en deux dimensions.
Pour une meilleure visualisation, une ligne verticale rouge est tracée à l'intersection des valeurs de performance d'entraînement et de validation, ainsi que de la valeur optimale.
def show_performance_curve(training_result, metric, metric_label):
train_perf = training_result.history[str(metric)]
validation_perf = training_result.history['val_'+str(metric)]
intersection_idx = np.argwhere(np.isclose(train_perf,
validation_perf, atol=1e-2)).flatten()[0]
intersection_value = train_perf[intersection_idx]
plt.plot(train_perf, label=metric_label)
plt.plot(validation_perf, label = 'val_'+str(metric))
plt.axvline(x=intersection_idx, color='r', linestyle='--', label='Intersection')
plt.annotate(f'Optimal Value: {intersection_value:.4f}',
xy=(intersection_idx, intersection_value),
xycoords='data',
fontsize=10,
color='green')
plt.xlabel('Epoch')
plt.ylabel(metric_label)
plt.legend(loc='lower right')Ensuite, la fonction est appliquée à la fois pour l'exactitude et la précision du modèle.
show_performance_curve(training_history, 'accuracy', 'accuracy')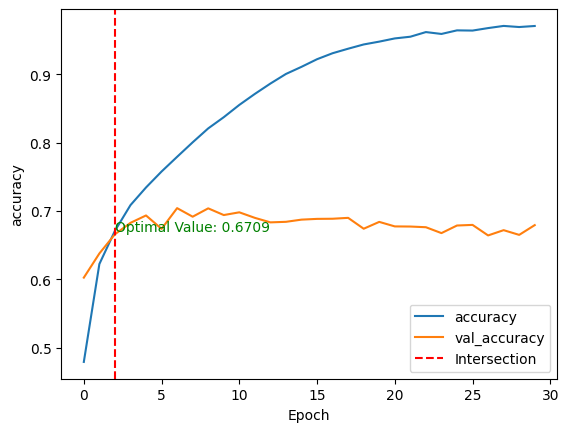
show_performance_curve(training_history, 'precision', 'precision')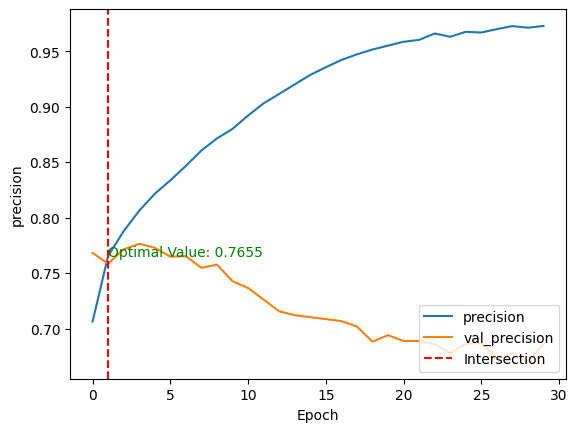
Après avoir entraîné le modèle sans aucun réglage fin ni prétraitement, nous obtenons le résultat suivant :
Ces deux mesures permettent une compréhension globale du comportement du modèle.
Et si nous voulions savoir, pour chaque classe, quelles sont celles que le modèle prédit bien et celles pour lesquelles il a des difficultés ?
Cela est possible grâce à la matrice de confusion, qui indique pour chaque classe le nombre de prédictions correctes et erronées. La mise en œuvre est présentée ci-dessous. Nous commençons par faire des prédictions sur les données de test, puis nous calculons la matrice de confusion et montrons le résultat final.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
test_predictions = model.predict(test_images)
test_predicted_labels = np.argmax(test_predictions, axis=1)
test_true_labels = np.argmax(test_labels, axis=1)
cm = confusion_matrix(test_true_labels, test_predicted_labels)
cmd = ConfusionMatrixDisplay(confusion_matrix=cm)
cmd.plot(include_values=True, cmap='viridis', ax=None, xticks_rotation='horizontal')
plt.show()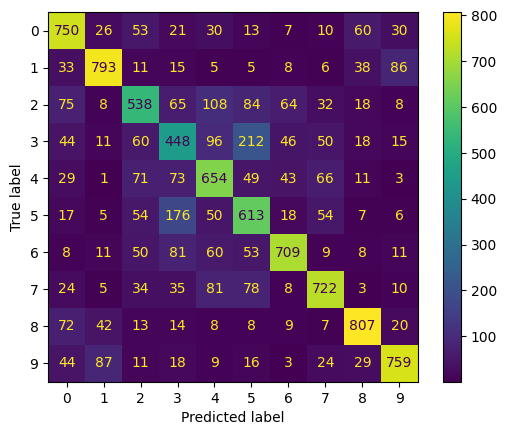
Pour en savoir plus sur les matrices de confusion, consultez notre tutoriel Comprendre les matrices de confusion en Rqui reprend le matériel du cours Machine Learning toolbox de DataCamp.
Ce modèle peut être amélioré par des tâches supplémentaires telles que :
Cet article présente une vue d'ensemble des CNN dans TensorFlow, en détaillant chaque couche de l'architecture des CNN. Il a également présenté brièvement TensorFlow et la manière dont il aide les ingénieurs et les chercheurs en apprentissage automatique à construire des réseaux neuronaux sophistiqués.
Nous avons appliqué tous ces ensembles de compétences à un scénario réel lié à une tâche de classification multiclasse.
Notre guide d'initiation à la détection d'objets pourrait constituer une excellente étape pour approfondir votre apprentissage de la vision par ordinateur. Il explore les composants clés de la détection d'objets et explique comment les mettre en œuvre dans SSD et Faster RCNN disponible dans Tensorflow.
Cours de Python
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach