
Curso
Comprender la ciencia de datos
2 h
856.8K
Este artículo explorará qué es el filtrado colaborativo, cómo funciona, su implementación en Python, ventajas, retos comunes y avances recientes.
En mi experiencia trabajando con sistemas de recomendación, he descubierto que el filtrado colaborativo es especialmente útil para crear experiencias de usuario escalables y personalizadas. A lo largo de este artículo, compartiré ideas y técnicas que me han resultado beneficiosas.
El filtrado colaborativo es una técnica fundamental de los modernos sistemas de recomendación, que potencia las experiencias personalizadas en el comercio electrónico, los servicios de streaming y las plataformas de redes sociales para mejorar la experiencia del usuario mediante recomendaciones personalizadas.
En esencia, se basa en el principio de que los usuarios que han mostrado preferencias similares en el pasado probablemente tendrán intereses similares en el futuro. Del mismo modo, es probable que los artículos que reciben el compromiso de usuarios similares sean preferidos por usuarios con gustos similares. En otras palabras,el filtrado colaborativo se basa en las interacciones de los usuarios con los elementos para generar recomendaciones.
El filtrado colaborativo se utiliza ampliamente en diversos ámbitos para personalizar las experiencias de los usuarios.
En el comercio electrónico, plataformas como Amazon confían en ella para sugerir productos basándose en el historial de compras y el comportamiento de navegación. Los servicios de streaming como Netflix y Spotify recomiendan contenidos analizando los hábitos de visualización o escucha de usuarios similares. En plataformas de redes sociales como Facebook y TikTok, potencia las sugerencias de amigos y los contenidos adaptados a los intereses individuales. En educación, las plataformas de aprendizaje en línea como Coursera y Udemy lo utilizan para recomendar cursos basados en el compromiso del alumno y en sus patrones de finalización. Incluso en la asistencia sanitaria, se está utilizando el filtrado colaborativo para proporcionar recomendaciones de tratamiento personalizadas comparando los datos del paciente con casos históricos similares.
Es útil comparar el filtrado colaborativo y el filtrado basado en contenidos, y ver cómo pueden integrarse ambos en sistemas híbridos.
El filtrado colaborativo recomienda artículos identificando patrones en el comportamiento de los usuarios, como valoraciones, compras o clics. Se basa únicamente en interacciones pasadas y similitudes entre usuarios para hacer predicciones. El filtrado basado en el contenido se centra más en las características de los propios artículos, como géneros, descripciones de productos o palabras clave, para recomendar artículos similares a los que le han gustado antes a un usuario.
Los sistemas híbridos reúnen ambas cosas. Se sabe que los sistemas híbridos mejoran la precisión porque, al combinar los datos de comportamiento con los atributos de los artículos, abordan limitaciones como el problema del arranque en frío, en el que los nuevos usuarios o artículos tienen pocos o ningún dato histórico.
El filtrado colaborativo funciona identificando patrones en el comportamiento de los usuarios para agrupar usuarios o elementos similares y generar recomendaciones.
Por ejemplo, si sueles ver películas de acción en Netflix, el filtrado colaborativo identificará a otros usuarios con hábitos de visionado similares y te recomendará películas que esos usuarios disfrutaron pero que tú aún no has visto. Este proceso refleja la forma en que los amigos recomiendan contenidos basándose en intereses compartidos, aprovechando las preferencias colectivas de los usuarios en lugar de las características de los artículos.
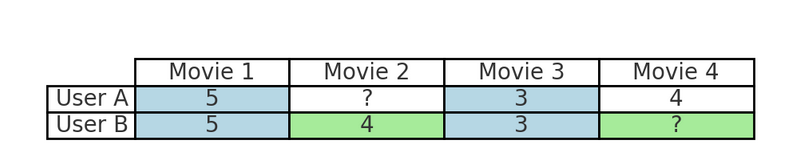
Por ejemplo, en la tabla anterior:
Esto refleja cómo los amigos recomiendan contenidos basándose en intereses compartidos, aprovechando las preferencias de usuarios similares en lugar de analizar el género, el director u otras características de la película.
Los algoritmos de filtrado colaborativo identifican y explotan patrones dentro de las interacciones usuario-artículo para hacer predicciones precisas. Profundicemos en cómo funcionan técnicamente estos algoritmos.
El sistema organiza las interacciones de los usuarios (valoraciones, clics, compras) en una matriz. La matriz suele ser dispersa debido al número limitado de interacciones. Normalmente, esta matriz es dispersa debido a las interacciones limitadas: muchos usuarios sólo interactúan con una pequeña fracción de los elementos disponibles. Gestionar e interpretar eficazmente estos escasos datos es clave para hacer recomendaciones precisas. "Índice de similitud" es un término que veo.
Las medidas de similitud ayudan a cuantificar lo parecidos que son los usuarios o los objetos. Los métodos más utilizados son:
Las técnicas de filtrado colaborativo pueden clasificarse a grandes rasgos en enfoques basados en la memoria y enfoques basados en modelos. Cada uno tiene sus puntos fuertes, y entenderlos a ambos permite comprender cómo se construyen los sistemas de recomendación modernos.
Estos enfoques calculan directamente las similitudes a partir de las interacciones usuario-artículo:
Estos métodos utilizan el aprendizaje automático para mejorar la precisión de las recomendaciones:
Tanto los métodos basados en la memoria como los basados en modelos son complementarios, y muchos sistemas modernos los integran en enfoques híbridos para aprovechar sus puntos fuertes combinados.
Para entender mejor cómo funciona el filtrado colaborativo, vamos a implementar un sistema de recomendación basado en elementos utilizando Python. Este ejemplo crea una matriz usuario-artículo, calcula las similitudes de los artículos utilizando la similitud del coseno y genera recomendaciones basadas en el comportamiento del usuario.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Sample user-item interaction data
collab_filtered_data = {
'User': ['Alice', 'Alice', 'Bob', 'Bob', 'Carol', 'Carol', 'Dave', 'Dave'],
'Item': ['Item1', 'Item2', 'Item1', 'Item3', 'Item2', 'Item3', 'Item1', 'Item2'],
'Rating': [5, 3, 4, 2, 4, 5, 2, 5]
}
collab_f_df = pd.DataFrame(collab_filtered_data)
# Create user-item matrix
user_item_matrix = collab_f_df.pivot_table(index='User', columns='Item', values='Rating', fill_value=0)
# Compute item similarity using cosine similarity
item_similarity = cosine_similarity(user_item_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=user_item_matrix.columns, columns=user_item_matrix.columns)
# Recommend items similar to 'Item1'
def recommend_similar_items(item, similarity_df, top_n=3):
return similarity_df[item].sort_values(ascending=False)[1:top_n+1]
# Example recommendation
similar_items = recommend_similar_items('Item1', item_similarity_df)
print("Items similar to Item1:", similar_items)Items similar to Item1: Item
Item2 0.527046
Item3 0.221455
Name: Item1, dtype: float64Algunas de las ventajas son:
Algunos de los retos son
En los últimos años, el filtrado colaborativo ha evolucionado significativamente gracias a las nuevas tecnologías de IA y a los enfoques híbridos. A continuación figuran algunas de las innovaciones más impactantes que configuran el futuro de los sistemas de recomendación.
Los sistemas de recomendación híbridos combinan el filtrado colaborativo y el filtrado basado en el contenido para mejorar la precisión y abordar las limitaciones de cada enfoque por separado. Al fusionar los patrones de interacción del usuario con los atributos de los artículos, estos sistemas proporcionan recomendaciones más sólidas, abordando eficazmente retos comunes como los problemas de arranque en frío y la escasez de datos.
Los avances en el aprendizaje profundo han mejorado significativamente el filtrado colaborativo al permitir que los modelos capten relaciones complejas y no lineales en las interacciones usuario-artículo. Técnicas como el Filtrado Neuronal Colaborativo y los métodos basados en autocodificadores utilizan redes neuronales para descubrir intrincados patrones de comportamiento, lo que conduce a recomendaciones más precisas y personalizadas.
El filtrado colaborativo consciente del contexto va más allá de las interacciones tradicionales usuario-artículo al incorporar información contextual -como la hora del día, la ubicación, el tipo de dispositivo o el estado de actividad del usuario- al proceso de recomendación. El resultado son recomendaciones no sólo personalizadas, sino también relevantes para el contexto inmediato del usuario, lo que mejora aún más la experiencia y el compromiso del usuario.
El aprendizaje por refuerzo optimiza dinámicamente las recomendaciones basándose en las interacciones y opiniones del usuario en tiempo real. Al aprender y adaptarse continuamente de las respuestas de los usuarios, los recomendadores basados en el aprendizaje por refuerzo mejoran la personalización y el compromiso.
El filtrado colaborativo sigue siendo la piedra angular de los sistemas de recomendación modernos. Aunque presenta retos como el arranque en frío y la escasez de datos, los avances en los modelos híbridos y el aprendizaje automático siguen mejorando su eficacia. A medida que evolucionen los sistemas de recomendación, el filtrado colaborativo seguirá siendo un impulsor clave de las experiencias digitales personalizadas en todos los sectores. Como siguiente paso, prueba a seguir nuestro curso Construir motores de recomendación en Python para aprender a tratar la dispersión y aprender a hacer recomendaciones con SVD y otras cosas interesantes.
Aprende con DataCamp
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Duong Vu
Tutorial
Moez Ali
Tutorial
Nadia mhadhbi
Tutorial
Kurtis Pykes
Tutorial
Bekhruz Tuychiev
