
Kurs
Datenwissenschaft verstehen
2 Std.
857K
In diesem Artikel erfährst du, was kollaboratives Filtern ist, wie es funktioniert, wie es in Python implementiert wird, welche Vorteile es hat, welche Herausforderungen es gibt und welche neuen Entwicklungen es gibt.
Bei meiner Arbeit mit Empfehlungssystemen habe ich festgestellt, dass kollaboratives Filtern besonders nützlich ist, um skalierbare und personalisierte Nutzererfahrungen zu schaffen. In diesem Artikel werde ich Einblicke und Techniken vorstellen, die ich für nützlich halte.
Collaborative Filtering ist eine grundlegende Technik hinter modernen Empfehlungssystemen, die personalisierte Erlebnisse im E-Commerce, bei Streaming-Diensten und auf Social-Media-Plattformen ermöglicht, um das Nutzererlebnis durch personalisierte Empfehlungen zu verbessern.
Im Kern funktioniert es nach dem Prinzip, dass Nutzer/innen, die in der Vergangenheit ähnliche Vorlieben gezeigt haben, auch in Zukunft ähnliche Interessen haben werden. Ähnlich verhält es sich mit Artikeln, die von ähnlichen Nutzern bevorzugt werden. Mit anderen Worten:Kollaboratives Filtern beruht auf den Interaktionen der Nutzer/innen mit den Artikeln, um Empfehlungen zu generieren.
Collaborative Filtering wird in vielen Bereichen eingesetzt, um das Nutzererlebnis zu personalisieren.
Im E-Commerce setzen Plattformen wie Amazon darauf, um Produkte auf der Grundlage der Kaufhistorie und des Surfverhaltens vorzuschlagen. Streaming-Dienste wie Netflix und Spotify empfehlen Inhalte, indem sie die Seh- oder Hörgewohnheiten ähnlicher Nutzer/innen analysieren. Auf Social-Media-Plattformen wie Facebook und TikTok ermöglicht sie Freundschaftsvorschläge und auf individuelle Interessen zugeschnittene Inhalte. Im Bildungsbereich nutzen Online-Lernplattformen wie Coursera und Udemy diese Technologie, um Kurse auf der Grundlage des Engagements und der Abschlussmuster der Lernenden zu empfehlen. Auch im Gesundheitswesen wird Collaborative Filtering eingesetzt, um personalisierte Behandlungsempfehlungen zu geben, indem Patientendaten mit ähnlichen historischen Fällen verglichen werden.
Es ist hilfreich, kollaboratives Filtern und inhaltsbasiertes Filtern zu vergleichen und zu sehen, wie die beiden in hybriden Systemen integriert werden können.
Die kollaborative Filterung empfiehlt Artikel, indem sie Muster im Nutzerverhalten erkennt, z. B. Bewertungen, Käufe oder Klicks. Es stützt sich ausschließlich auf vergangene Interaktionen und Ähnlichkeiten zwischen den Nutzern, um Vorhersagen zu treffen. Die inhaltsbasierte Filterung konzentriert sich mehr auf die Merkmale der Artikel selbst, wie z. B. Genres, Produktbeschreibungen oder Schlüsselwörter, um ähnliche Artikel zu empfehlen, die einem Nutzer zuvor gefallen haben.
Hybride Systeme bringen diese beiden Aspekte zusammen. Hybride Systeme sind dafür bekannt, dass sie die Genauigkeit verbessern, denn durch die Kombination von Verhaltensdaten mit Artikelattributen können sie Einschränkungen wie das Kaltstartproblem umgehen, bei dem neue Nutzer oder Artikel wenig bis gar keine historischen Daten haben.
Beim kollaborativen Filtern werden Muster im Nutzerverhalten erkannt, um ähnliche Nutzer oder Artikel zu gruppieren und Empfehlungen zu erstellen.
Wenn du zum Beispiel häufig Actionfilme auf Netflix streamst, kann das kollaborative Filtern andere Nutzer/innen mit ähnlichen Sehgewohnheiten identifizieren und dir Filme empfehlen, die diesen Nutzer/innen gefallen haben, die du aber noch nicht gesehen hast. Dieser Prozess spiegelt die Art und Weise wider, wie Freunde Inhalte auf der Grundlage gemeinsamer Interessen empfehlen: Sie nutzen die kollektiven Vorlieben der Nutzer und nicht die Eigenschaften der Artikel.
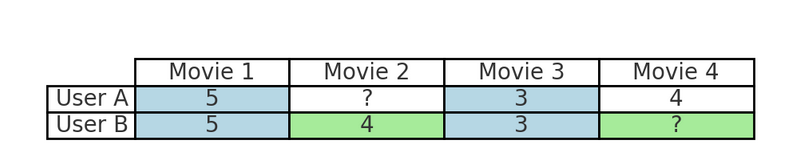
Zum Beispiel in der Tabelle oben:
Dies spiegelt die Art und Weise wider, wie Freunde Inhalte auf der Grundlage gemeinsamer Interessen empfehlen, indem sie die Vorlieben ähnlicher Nutzer/innen nutzen, anstatt das Genre, den Regisseur oder andere Merkmale des Films zu analysieren.
Algorithmen des kollaborativen Filterns erkennen und nutzen Muster in den Interaktionen zwischen Nutzern und Artikeln, um genaue Vorhersagen zu treffen. Schauen wir uns genauer an, wie diese Algorithmen technisch funktionieren.
Das System organisiert die Nutzerinteraktionen (Bewertungen, Klicks, Käufe) in einer Matrix. Die Matrix ist aufgrund der begrenzten Anzahl von Interaktionen oft spärlich. In der Regel ist diese Matrix aufgrund begrenzter Interaktionen spärlich - viele Nutzerinnen und Nutzer beschäftigen sich nur mit einem kleinen Teil der verfügbaren Artikel. Die effektive Verwaltung und Interpretation dieser spärlichen Daten ist der Schlüssel zu genauen Empfehlungen. "Ähnlichkeitsindex" ist ein Begriff, den ich sehe.
Ähnlichkeitsmaße helfen dabei zu quantifizieren, wie ähnlich sich Nutzer oder Gegenstände sind. Häufig verwendete Methoden sind:
Die Techniken des kollaborativen Filterns lassen sich grob in speicherbasierte und modellbasierte Ansätze unterteilen. Beide haben ihre Stärken, und wenn du beide verstehst, bekommst du einen Einblick, wie moderne Empfehlungssysteme aufgebaut sind.
Bei diesen Ansätzen werden die Ähnlichkeiten direkt aus den Interaktionen zwischen Nutzer und Artikel berechnet:
Diese Methoden nutzen maschinelles Lernen, um die Genauigkeit der Empfehlungen zu verbessern:
Sowohl speicher- als auch modellbasierte Methoden ergänzen sich, und viele moderne Systeme integrieren sie in hybriden Ansätzen, um ihre kombinierten Stärken zu nutzen.
Um besser zu verstehen, wie kollaboratives Filtern funktioniert, wollen wir ein itembasiertes Empfehlungssystem mit Python implementieren. In diesem Beispiel wird eine Matrix aus Benutzern und Artikeln erstellt, die Ähnlichkeit der Artikel mit Hilfe der Cosinus-Ähnlichkeit berechnet und Empfehlungen auf der Grundlage des Benutzerverhaltens erstellt.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Sample user-item interaction data
collab_filtered_data = {
'User': ['Alice', 'Alice', 'Bob', 'Bob', 'Carol', 'Carol', 'Dave', 'Dave'],
'Item': ['Item1', 'Item2', 'Item1', 'Item3', 'Item2', 'Item3', 'Item1', 'Item2'],
'Rating': [5, 3, 4, 2, 4, 5, 2, 5]
}
collab_f_df = pd.DataFrame(collab_filtered_data)
# Create user-item matrix
user_item_matrix = collab_f_df.pivot_table(index='User', columns='Item', values='Rating', fill_value=0)
# Compute item similarity using cosine similarity
item_similarity = cosine_similarity(user_item_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=user_item_matrix.columns, columns=user_item_matrix.columns)
# Recommend items similar to 'Item1'
def recommend_similar_items(item, similarity_df, top_n=3):
return similarity_df[item].sort_values(ascending=False)[1:top_n+1]
# Example recommendation
similar_items = recommend_similar_items('Item1', item_similarity_df)
print("Items similar to Item1:", similar_items)Items similar to Item1: Item
Item2 0.527046
Item3 0.221455
Name: Item1, dtype: float64Einige der Vorteile sind:
Einige der Herausforderungen sind:
In den letzten Jahren hat sich das kollaborative Filtern dank neuer KI-Technologien und hybrider Ansätze deutlich weiterentwickelt. Im Folgenden werden einige der wichtigsten Innovationen vorgestellt, die die Zukunft der Empfehlungssysteme prägen.
Hybride Empfehlungssysteme kombinieren kollaboratives Filtern und inhaltsbasiertes Filtern, um die Genauigkeit zu erhöhen und die Grenzen jedes einzelnen Ansatzes zu überwinden. Durch die Verknüpfung von Nutzerinteraktionsmustern mit Artikelattributen bieten diese Systeme robustere Empfehlungen und bewältigen gängige Probleme wie Kaltstartprobleme und spärliche Daten.
Die Fortschritte im Deep Learning haben das kollaborative Filtern deutlich verbessert, da die Modelle komplexe, nicht-lineare Beziehungen in den Interaktionen zwischen Nutzer und Artikel erfassen können. Techniken wie Neural Collaborative Filtering und Autoencoder-basierte Methoden nutzen neuronale Netze, um komplexe Verhaltensmuster aufzudecken, was zu genaueren und personalisierten Empfehlungen führt.
Die kontextbezogene kollaborative Filterung geht über die traditionelle Interaktion zwischen Nutzer und Artikel hinaus, indem sie kontextbezogene Informationen wie Tageszeit, Standort, Gerätetyp oder Aktivitätsstatus des Nutzers in den Empfehlungsprozess einbezieht. Das Ergebnis sind Empfehlungen, die nicht nur personalisiert, sondern auch für den unmittelbaren Kontext des Nutzers relevant sind, was das Nutzererlebnis und das Engagement weiter verbessert.
Reinforcement Learning optimiert die Empfehlungen dynamisch auf der Grundlage von Nutzerinteraktionen und Feedback in Echtzeit. Indem sie kontinuierlich aus den Antworten der Nutzer/innen lernen und sich anpassen, verbessern auf Reinforcement Learning basierende Empfehlungssysteme die Personalisierung und das Engagement.
Die kollaborative Filterung bleibt ein Eckpfeiler moderner Empfehlungssysteme. Auch wenn es Herausforderungen wie Kaltstart und spärliche Daten gibt, verbessern die Fortschritte bei hybriden Modellen und maschinellem Lernen die Effektivität weiter. Mit der Weiterentwicklung von Empfehlungssystemen wird das kollaborative Filtern in allen Branchen ein wichtiger Treiber für personalisierte digitale Erlebnisse bleiben. Als nächsten Schritt solltest du unseren Kurs Building Recommendation Engines in Python besuchen, um zu lernen, wie man mit Sparsamkeit umgeht und wie man mit SVD und anderen interessanten Dingen Empfehlungen erstellt.
Lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
