
Cours
Comprendre la science des données
2 h
857K
Cet article explorera ce qu'est le filtrage collaboratif, son fonctionnement, sa mise en œuvre dans Python, ses avantages, les défis courants et les avancées récentes.
Dans mon expérience des systèmes de recommandation, j'ai trouvé le filtrage collaboratif particulièrement utile pour créer des expériences utilisateur évolutives et personnalisées. Tout au long de cet article, je vous ferai part des idées et des techniques que j'ai trouvées bénéfiques.
Le filtrage collaboratif est une technique fondamentale des systèmes de recommandation modernes, qui alimente les expériences personnalisées dans le commerce électronique, les services de streaming et les plateformes de médias sociaux afin d'améliorer l'expérience de l'utilisateur grâce à des recommandations personnalisées.
Il repose sur le principe selon lequel les utilisateurs qui ont manifesté des préférences similaires dans le passé auront probablement des intérêts similaires à l'avenir. De la même manière, les éléments qui reçoivent un engagement de la part d'utilisateurs similaires sont susceptibles d'être préférés par des utilisateurs ayant des goûts similaires. En d'autres termes, lefiltrage collaboratif s'appuie sur les interactions de l'utilisateur avec les éléments pour générer des recommandations .
Le filtrage collaboratif est largement utilisé dans divers domaines pour personnaliser les expériences des utilisateurs.
Dans le domaine du commerce électronique, des plateformes comme Amazon s'appuient sur cette technologie pour suggérer des produits en fonction de l'historique des achats et du comportement de navigation. Les services de streaming tels que Netflix et Spotify recommandent des contenus en analysant les habitudes de visionnage ou d'écoute d'utilisateurs similaires. Sur les plateformes de médias sociaux comme Facebook et TikTok, il permet de suggérer des amis et des contenus adaptés aux centres d'intérêt de chacun. Dans le domaine de l'éducation, des plateformes d'apprentissage en ligne comme Coursera et Udemy l'utilisent pour recommander des cours en fonction de l'engagement de l'apprenant et de ses habitudes d'achèvement. Même dans le domaine des soins de santé, le filtrage collaboratif est utilisé pour fournir des recommandations de traitement personnalisées en comparant les données du patient à des cas historiques similaires.
Il est utile de comparer le filtrage collaboratif et le filtrage basé sur le contenu, et de voir comment les deux peuvent être intégrés dans des systèmes hybrides.
Le filtrage collaboratif recommande des éléments en identifiant des modèles dans le comportement des utilisateurs, tels que les évaluations, les achats ou les clics. Il s'appuie uniquement sur les interactions passées et les similitudes entre les utilisateurs pour faire des prédictions. Le filtrage basé sur le contenu se concentre davantage sur les caractéristiques des articles eux-mêmes, tels que les genres, les descriptions de produits ou les mots-clés, afin de recommander des articles similaires à ceux que l'utilisateur a déjà aimés.
Les systèmes hybrides combinent les deux. Les systèmes hybrides sont connus pour améliorer la précision car, en combinant les données comportementales avec les attributs des articles, ils répondent à des limitations telles que le problème du démarrage à froid, où les nouveaux utilisateurs ou articles n'ont que peu ou pas de données historiques.
Le filtrage collaboratif permet d'identifier des modèles dans le comportement des utilisateurs afin de regrouper des utilisateurs ou des éléments similaires et de générer des recommandations.
Par exemple, si vous regardez souvent des films d'action sur Netflix, le filtrage collaboratif identifiera d'autres utilisateurs ayant des habitudes de visionnage similaires et vous recommandera des films que ces utilisateurs ont appréciés mais que vous n'avez pas encore vus. Ce processus reflète la manière dont les amis recommandent des contenus sur la base d'intérêts communs, en tirant parti des préférences collectives des utilisateurs plutôt que des caractéristiques des articles.
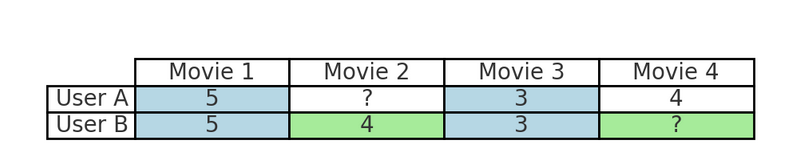
Par exemple, dans le tableau ci-dessus :
Cela reflète la manière dont les amis recommandent des contenus en fonction d'intérêts communs, en s'appuyant sur les préférences d'utilisateurs similaires plutôt qu'en analysant le genre, le réalisateur ou d'autres caractéristiques du film.
Les algorithmes de filtrage collaboratif identifient et exploitent les modèles d'interaction entre l'utilisateur et l'article pour faire des prédictions précises. Voyons plus en détail le fonctionnement technique de ces algorithmes.
Le système organise les interactions des utilisateurs (évaluations, clics, achats) dans une matrice. La matrice est souvent peu dense en raison du nombre limité d'interactions. En règle générale, cette matrice est peu dense en raison d'interactions limitées : de nombreux utilisateurs ne s'intéressent qu'à une petite partie des éléments disponibles. La gestion et l'interprétation efficaces de ces données éparses sont essentielles à la formulation de recommandations précises. "L'indice de similarité est un terme que je vois.
Les mesures de similarité permettent de quantifier le degré de ressemblance entre des utilisateurs ou des éléments. Les méthodes les plus couramment utilisées sont les suivantes :
Les techniques de filtrage collaboratif peuvent être classées en deux grandes catégories : les approches basées sur la mémoire et les approches basées sur un modèle. Chacune a ses points forts, et leur compréhension permet de comprendre comment les systèmes de recommandation modernes sont construits.
Ces approches calculent directement les similitudes à partir des interactions entre l'utilisateur et l'article :
Ces méthodes utilisent l'apprentissage automatique pour améliorer la précision des recommandations :
Les méthodes basées sur la mémoire et les méthodes basées sur le modèle sont complémentaires, et de nombreux systèmes modernes les intègrent dans des approches hybrides afin de tirer parti de leurs forces combinées.
Pour mieux comprendre le fonctionnement du filtrage collaboratif, mettons en œuvre un système de recommandation basé sur les articles à l'aide de Python. Cet exemple crée une matrice utilisateur-élément, calcule les similarités entre les éléments à l'aide de la similarité cosinusoïdale et génère des recommandations basées sur le comportement de l'utilisateur.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Sample user-item interaction data
collab_filtered_data = {
'User': ['Alice', 'Alice', 'Bob', 'Bob', 'Carol', 'Carol', 'Dave', 'Dave'],
'Item': ['Item1', 'Item2', 'Item1', 'Item3', 'Item2', 'Item3', 'Item1', 'Item2'],
'Rating': [5, 3, 4, 2, 4, 5, 2, 5]
}
collab_f_df = pd.DataFrame(collab_filtered_data)
# Create user-item matrix
user_item_matrix = collab_f_df.pivot_table(index='User', columns='Item', values='Rating', fill_value=0)
# Compute item similarity using cosine similarity
item_similarity = cosine_similarity(user_item_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=user_item_matrix.columns, columns=user_item_matrix.columns)
# Recommend items similar to 'Item1'
def recommend_similar_items(item, similarity_df, top_n=3):
return similarity_df[item].sort_values(ascending=False)[1:top_n+1]
# Example recommendation
similar_items = recommend_similar_items('Item1', item_similarity_df)
print("Items similar to Item1:", similar_items)Items similar to Item1: Item
Item2 0.527046
Item3 0.221455
Name: Item1, dtype: float64Voici quelques-uns de ses avantages :
Voici quelques-uns des défis à relever :
Ces dernières années, le filtrage collaboratif a considérablement évolué grâce aux technologies émergentes de l'IA et aux approches hybrides. Vous trouverez ci-dessous quelques-unes des innovations les plus marquantes qui façonnent l'avenir des systèmes de recommandation.
Les systèmes de recommandation hybrides combinent le filtrage collaboratif et le filtrage basé sur le contenu afin d'améliorer la précision et de remédier aux limites de chaque approche. En fusionnant les modèles d'interaction de l'utilisateur avec les attributs de l'article, ces systèmes fournissent des recommandations plus robustes, en relevant efficacement des défis communs tels que les problèmes de démarrage à froid et la rareté des données.
Les progrès de l'apprentissage profond ont considérablement amélioré le filtrage collaboratif en permettant aux modèles de capturer des relations complexes et non linéaires dans les interactions entre l'utilisateur et l'article. Des techniques telles que le filtrage collaboratif neuronal et les méthodes basées sur l'autoencodage utilisent des réseaux neuronaux pour découvrir des modèles comportementaux complexes, ce qui permet d'obtenir des recommandations plus précises et plus personnalisées.
Le filtrage collaboratif tenant compte du contexte va au-delà des interactions traditionnelles entre l'utilisateur et l'article en incorporant des informations contextuelles - telles que l'heure, la localisation, le type d'appareil ou l'état d'activité de l'utilisateur - dans le processus de recommandation. Il en résulte des recommandations qui sont non seulement personnalisées, mais aussi pertinentes par rapport au contexte immédiat de l'utilisateur, ce qui améliore encore l'expérience et l'engagement de ce dernier.
L'apprentissage par renforcement optimise dynamiquement les recommandations en fonction des interactions et du retour d'information de l'utilisateur en temps réel. En apprenant continuellement et en s'adaptant aux réponses des utilisateurs, les recommandeurs basés sur l'apprentissage par renforcement améliorent la personnalisation et l'engagement.
Le filtrage collaboratif reste la pierre angulaire des systèmes de recommandation modernes. Bien qu'elle présente des difficultés telles que le démarrage à froid et la rareté des données, les progrès réalisés dans le domaine des modèles hybrides et de l'apprentissage automatique continuent d'en améliorer l'efficacité. Alors que les systèmes de recommandation évoluent, le filtrage collaboratif restera un élément clé des expériences numériques personnalisées dans tous les secteurs d'activité. Pour l'étape suivante, essayez de suivre notre cours Construire des moteurs de recommandation en Python pour apprendre à gérer la rareté et apprendre à faire des recommandations avec SVD et d'autres choses intéressantes.
Apprenez avec DataCamp
Cours
Cours
Cours