
Curso
Introdução à ciência de dados
2 h
856.8K
Este artigo explorará o que é filtragem colaborativa, como ela funciona, sua implementação em Python, vantagens, desafios comuns e avanços recentes.
Em minha experiência de trabalho com sistemas de recomendação, descobri que a filtragem colaborativa é particularmente útil na criação de experiências de usuário dimensionáveis e personalizadas. Ao longo deste artigo, compartilharei percepções e técnicas que considero benéficas.
A filtragem colaborativa é uma técnica fundamental por trás dos sistemas de recomendação modernos, que impulsiona experiências personalizadas em comércio eletrônico, serviços de streaming e plataformas de mídia social para aprimorar a experiência do usuário por meio de recomendações personalizadas.
Em sua essência, ele opera com base no princípio de que os usuários que exibiram preferências semelhantes no passado provavelmente terão interesses semelhantes no futuro. Da mesma forma, os itens que recebem envolvimento de usuários semelhantes provavelmente serão preferidos por usuários com gostos semelhantes. Em outras palavras,a filtragem colaborativa se baseia nas interações do usuário com os itens para gerar recomendações.
A filtragem colaborativa é amplamente usada em vários domínios para personalizar as experiências do usuário.
No comércio eletrônico, plataformas como a Amazon contam com ele para sugerir produtos com base no histórico de compras e no comportamento de navegação. Os serviços de streaming, como Netflix e Spotify, recomendam conteúdo analisando os hábitos de visualização ou audição de usuários semelhantes. Em plataformas de mídia social, como o Facebook e o TikTok, ele possibilita sugestões de amigos e feeds de conteúdo adaptados a interesses individuais. Na educação, plataformas de aprendizagem on-line como Coursera e Udemy usam esse recurso para recomendar cursos com base no envolvimento do aluno e nos padrões de conclusão. Mesmo na área da saúde, a filtragem colaborativa está sendo usada para fornecer recomendações de tratamento personalizadas, comparando os dados do paciente com casos históricos semelhantes.
É útil comparar a filtragem colaborativa com a filtragem baseada em conteúdo e ver como as duas podem ser integradas em sistemas híbridos.
A filtragem colaborativa recomenda itens ao identificar padrões no comportamento do usuário, como classificações, compras ou cliques. Ele se baseia apenas em interações passadas e semelhanças entre usuários para fazer previsões. A filtragem baseada em conteúdo concentra-se mais nas características dos próprios itens, como gêneros, descrições de produtos ou palavras-chave, para recomendar itens semelhantes aos que um usuário já gostou antes.
Os sistemas híbridos reúnem esses dois aspectos. Sabe-se que os sistemas híbridos aumentam a precisão porque, ao combinar dados comportamentais com atributos de itens, eles abordam limitações como o problema da partida a frio, em que novos usuários ou itens têm pouco ou nenhum dado histórico.
A filtragem colaborativa funciona identificando padrões no comportamento do usuário para agrupar usuários ou itens semelhantes e gerar recomendações.
Por exemplo, se você costuma assistir a filmes de ação na Netflix, a filtragem colaborativa identificará outros usuários com hábitos de visualização semelhantes e recomendará filmes que esses usuários gostaram, mas que você ainda não viu. Esse processo reflete a forma como os amigos recomendam conteúdo com base em interesses compartilhados - aproveitando as preferências coletivas do usuário em vez das características do item.
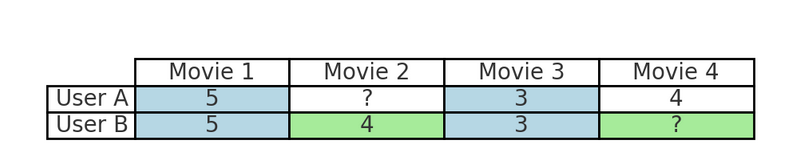
Por exemplo, na tabela acima:
Isso reflete a forma como os amigos recomendam conteúdo com base em interesses compartilhados, aproveitando as preferências de usuários semelhantes em vez de analisar o gênero, o diretor ou outros recursos do filme.
Os algoritmos de filtragem colaborativa identificam e exploram padrões nas interações usuário-item para fazer previsões precisas. Vamos nos aprofundar em como esses algoritmos funcionam tecnicamente.
O sistema organiza as interações do usuário (classificações, cliques, compras) em uma matriz. A matriz geralmente é esparsa devido ao número limitado de interações. Normalmente, essa matriz é esparsa devido a interações limitadas - muitos usuários se envolvem com apenas uma pequena fração dos itens disponíveis. Gerenciar e interpretar esses dados esparsos de forma eficaz é fundamental para recomendações precisas. "Índice de similaridade" é um termo que vejo.
As medidas de similaridade ajudam a quantificar a semelhança entre usuários ou itens. Os métodos comumente usados são:
As técnicas de filtragem colaborativa podem ser amplamente categorizadas em abordagens baseadas em memória e em modelos. Cada um deles tem seus pontos fortes, e a compreensão de ambos fornece informações sobre como os sistemas de recomendação modernos são criados.
Essas abordagens calculam diretamente as semelhanças a partir das interações usuário-item:
Esses métodos usam o machine learning para aumentar a precisão das recomendações:
Os métodos baseados em memória e em modelos são complementares, e muitos sistemas modernos os integram em abordagens híbridas para aproveitar seus pontos fortes combinados.
Para que você entenda melhor como funciona a filtragem colaborativa, vamos implementar um sistema de recomendação baseado em itens usando Python. Esse exemplo cria uma matriz de item de usuário, calcula as semelhanças de item usando a semelhança de cosseno e gera recomendações com base no comportamento do usuário.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Sample user-item interaction data
collab_filtered_data = {
'User': ['Alice', 'Alice', 'Bob', 'Bob', 'Carol', 'Carol', 'Dave', 'Dave'],
'Item': ['Item1', 'Item2', 'Item1', 'Item3', 'Item2', 'Item3', 'Item1', 'Item2'],
'Rating': [5, 3, 4, 2, 4, 5, 2, 5]
}
collab_f_df = pd.DataFrame(collab_filtered_data)
# Create user-item matrix
user_item_matrix = collab_f_df.pivot_table(index='User', columns='Item', values='Rating', fill_value=0)
# Compute item similarity using cosine similarity
item_similarity = cosine_similarity(user_item_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=user_item_matrix.columns, columns=user_item_matrix.columns)
# Recommend items similar to 'Item1'
def recommend_similar_items(item, similarity_df, top_n=3):
return similarity_df[item].sort_values(ascending=False)[1:top_n+1]
# Example recommendation
similar_items = recommend_similar_items('Item1', item_similarity_df)
print("Items similar to Item1:", similar_items)Items similar to Item1: Item
Item2 0.527046
Item3 0.221455
Name: Item1, dtype: float64Algumas das vantagens são:
Alguns dos desafios incluem:
Nos últimos anos, a filtragem colaborativa evoluiu significativamente graças às tecnologias emergentes de IA e às abordagens híbridas. A seguir, você encontrará algumas das inovações mais impactantes que estão moldando o futuro dos sistemas de recomendação.
Os sistemas de recomendação híbridos combinam a filtragem colaborativa e a filtragem baseada em conteúdo para aumentar a precisão e lidar com as limitações de cada abordagem individualmente. Ao mesclar os padrões de interação do usuário com os atributos do item, esses sistemas fornecem recomendações mais robustas, abordando de forma eficaz desafios comuns, como problemas de cold-start e escassez de dados.
Os avanços na aprendizagem profunda melhoraram significativamente a filtragem colaborativa, permitindo que os modelos capturem relações complexas e não lineares nas interações usuário-item. Técnicas como a filtragem colaborativa neural e os métodos baseados em autoencoder utilizam redes neurais para descobrir padrões de comportamento complexos, o que resulta em recomendações mais precisas e personalizadas.
A filtragem colaborativa com reconhecimento de contexto vai além das interações tradicionais entre usuário e item, incorporando informações contextuais - como hora do dia, local, tipo de dispositivo ou estado de atividade do usuário - ao processo de recomendação. Isso resulta em recomendações que não são apenas personalizadas, mas também relevantes para o contexto imediato do usuário, aprimorando ainda mais a experiência e o envolvimento do usuário.
O aprendizado por reforço otimiza dinamicamente as recomendações com base nas interações e no feedback do usuário em tempo real. Ao aprender e adaptar-se continuamente às respostas do usuário, os recomendadores baseados em aprendizagem por reforço melhoram a personalização e o envolvimento.
A filtragem colaborativa continua sendo a base dos sistemas de recomendação modernos. Embora apresente desafios como a partida a frio e a escassez de dados, os avanços nos modelos híbridos e no machine learning continuam a melhorar sua eficácia. À medida que os sistemas de recomendação evoluem, a filtragem colaborativa continuará sendo um dos principais impulsionadores de experiências digitais personalizadas em todos os setores. Como próxima etapa, experimente fazer nosso curso Building Recommendation Engines in Python para saber como lidar com a esparsidade e aprender a fazer recomendações com SVD e outras coisas interessantes.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Javier Canales Luna
13 min
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Joleen Bothma
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
