
Course
Understanding Data Science
2 hr
856.8K
This article will explore what collaborative filtering is, how it operates, its implementation in Python, advantages, common challenges, and recent advancements.
In my experience working with recommendation systems, I've found collaborative filtering particularly useful in creating scalable and personalized user experiences. Throughout this article, I'll share insights and techniques that I've found beneficial.
Collaborative filtering is a fundamental technique behind modern recommendation systems, powering personalized experiences across e-commerce, streaming services, and social media platforms to enhance user experience through personalized recommendations.
At its core, it operates on the principle that users who have exhibited similar preferences in the past will likely have similar interests in the future. Similarly, items that receive engagement from similar users are likely to be preferred by users with similar tastes. In other words, collaborative filtering relies on user interactions with items to generate recommendations.
Collaborative filtering is widely used across various domains to personalize user experiences.
In e-commerce, platforms like Amazon rely on it to suggest products based on purchase history and browsing behavior. Streaming services such as Netflix and Spotify recommend content by analyzing viewing or listening habits of similar users. On social media platforms like Facebook and TikTok, it powers friend suggestions and content feeds tailored to individual interests. In education, online learning platforms like Coursera and Udemy use it to recommend courses based on learner engagement and completion patterns. Even in healthcare, collaborative filtering is being used to provide personalized treatment recommendations by comparing patient data to similar historical cases.
It’s helpful to compare collaborative filtering and content-based filtering, and see how the two can be integrated in hybrid systems.
Collaborative filtering recommends items by identifying patterns in user behavior, such as ratings, purchases, or clicks. It relies solely on past interactions and similarities between users to make predictions. Content-based filtering focuses more on the characteristics of the items themselves, such as genres, product descriptions, or keywords, to recommend similar items to those a user has liked before.
Hybrid systems bring these two together. Hybrid systems are known to improve accuracy because, by combining behavioral data with item attributes, they address limitations like the cold-start problem, where new users or items have little to no historical data.
Collaborative filtering works by identifying patterns in user behavior to group similar users or items and generate recommendations.
For example, if you frequently stream action movies on Netflix, collaborative filtering will identify other users with similar viewing habits and recommend movies that those users enjoyed but you haven’t seen yet. This process mirrors how friends recommend content based on shared interests—leveraging collective user preferences rather than item characteristics.
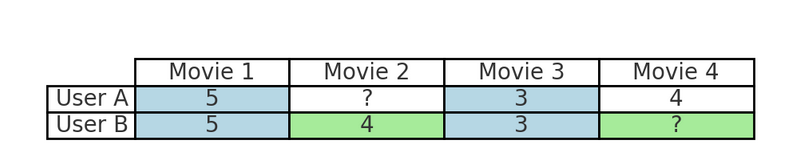
For instance, in the table above:
This mirrors how friends recommend content based on shared interests, leveraging the preferences of similar users rather than analyzing the movie’s genre, director, or other features.
Collaborative filtering algorithms identify and exploit patterns within user-item interactions to make accurate predictions. Let's dive deeper into how these algorithms technically function.
The system organizes user interactions (ratings, clicks, purchases) into a matrix. The matrix is often sparse due to the limited number of interactions. Typically, this matrix is sparse due to limited interactions—many users engage with only a small fraction of available items. Managing and interpreting this sparse data effectively is key to accurate recommendations. “Similarity index” is a term I see.
Similarity measures help quantify how alike users or items are. Commonly used methods are:
Collaborative filtering techniques can be broadly categorized into memory-based and model-based approaches. Each has its strengths, and understanding both provides insight into how modern recommender systems are built.
These approaches directly compute similarities from user-item interactions:
These methods use machine learning to enhance recommendation accuracy:
Both memory-based and model-based methods are complementary, and many modern systems integrate them into hybrid approaches to leverage their combined strengths.
To better understand how collaborative filtering works, let's implement an item-based recommendation system using Python. This example creates a user-item matrix, computes item similarities using cosine similarity, and generates recommendations based on user behavior.
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# Sample user-item interaction data
collab_filtered_data = {
'User': ['Alice', 'Alice', 'Bob', 'Bob', 'Carol', 'Carol', 'Dave', 'Dave'],
'Item': ['Item1', 'Item2', 'Item1', 'Item3', 'Item2', 'Item3', 'Item1', 'Item2'],
'Rating': [5, 3, 4, 2, 4, 5, 2, 5]
}
collab_f_df = pd.DataFrame(collab_filtered_data)
# Create user-item matrix
user_item_matrix = collab_f_df.pivot_table(index='User', columns='Item', values='Rating', fill_value=0)
# Compute item similarity using cosine similarity
item_similarity = cosine_similarity(user_item_matrix.T)
item_similarity_df = pd.DataFrame(item_similarity, index=user_item_matrix.columns, columns=user_item_matrix.columns)
# Recommend items similar to 'Item1'
def recommend_similar_items(item, similarity_df, top_n=3):
return similarity_df[item].sort_values(ascending=False)[1:top_n+1]
# Example recommendation
similar_items = recommend_similar_items('Item1', item_similarity_df)
print("Items similar to Item1:", similar_items)Items similar to Item1: Item
Item2 0.527046
Item3 0.221455
Name: Item1, dtype: float64Some of the advantages are:
Some of the challenges include:
In recent years, collaborative filtering has evolved significantly thanks to emerging AI technologies and hybrid approaches. Below are some of the most impactful innovations shaping the future of recommendation systems.
Hybrid recommendation systems combine collaborative filtering and content-based filtering to enhance accuracy and address the limitations of each approach individually. By merging user interaction patterns with item attributes, these systems provide more robust recommendations, effectively addressing common challenges such as cold-start issues and data sparsity.
Advancements in deep learning have significantly improved collaborative filtering by enabling models to capture complex, non-linear relationships in user-item interactions. Techniques like Neural Collaborative Filtering and autoencoder-based methods utilize neural networks to uncover intricate behavioral patterns, leading to more accurate and personalized recommendations.
Context-aware collaborative filtering goes beyond traditional user-item interactions by incorporating contextual information—such as time of day, location, device type, or user activity state—into the recommendation process. This results in recommendations that are not only personalized but also relevant to the user's immediate context, further enhancing user experience and engagement.
Reinforcement learning dynamically optimizes recommendations based on real-time user interactions and feedback. By continually learning and adapting from user responses, reinforcement learning-based recommenders improve personalization and engagement.
Collaborative filtering remains a cornerstone of modern recommendation systems. While it presents challenges like cold start and data sparsity, advancements in hybrid models and machine learning continue to improve its effectiveness. As recommendation systems evolve, collaborative filtering will remain a key driver of personalized digital experiences across industries. As a next step, try taking our Building Recommendation Engines in Python course to learn how to deal with sparsity and learn about making recommendations with SVD and other interesting things.
Learn with DataCamp
Course
Course
Course
blog
Vinod Chugani
10 min
Tutorial
Aditya Sharma
Tutorial
Avinash Navlani
Tutorial
Srujana Maddula
Tutorial
Sayak Paul
Tutorial
Amberle McKee
